In a previous blog, we described a novel way for software QA for refactored code already running in production inspired by the Scientist approach GitHub published in 2016. In this blog we explain how we implemented this QA method for testing AWS Lambda functions and our experiences with that.
The end goal of the Scientist approach is to release refactored functionality with confidence. Confidence, as explained in that other post, is gained by running both the current version of functionality (the “control”) and a new implementation (the “candidate”) in production, sending production traffic to both. In this setup, the “control” response is returned to the client so that the original requestor does not notice an experiment runs in the background. By comparing responses of control and candidates (with respect to their functionality but also taking performance, memory usage, etc. into account) you can make a well-informed decision whether to promote the candidate to the new production version.
GitHub’s implementation of the Scientist approach was developed in Ruby and there are alternative implementations for many other languages. An alternative for applying the Scientist approach to AWS Lambdas or other serverless platforms was missing. Enter Serverless Scientist, an implementation of Scientist for AWS Lambdas. As the name suggests, we envision to also implement this for other serverless implementations like Google Functions and Microsoft Azure Functions.
Requirements for Serverless Scientist
The description in the previous blog translates into a couple of capabilities for a Serverless Scientist implementation. It needs to support the following:
- Run experiments: run controls and (possibly multiple) candidates using production traffic in a production environment.
- Compare results of control and candidate, to draw conclusions on the quality of a candidate.
- Easily route traffic to single or multiple candidates without downtime.
- No noticeable impact for end-consumers when invoking an experiment, adding or removing candidates in an experiment, or improving a candidate implementation.
- No changes required in control in order to enable testing via experiments.
- No persistent effect from candidates in production data (i.e., candidates must not update production data).
BTW, On “No change required in control", as explained, this is where some other methods fail.”
Serverless Scientist implementation
For full details on the implementation of the Serverless Scientist refer to the code repository. The diagram below illustrates the setup of the Serverless Scientist. The Serverless Scientist is placed between the client and the “control” function and consists of two Lambda functions. The “Scientist” Lambda function is responsible for receiving requests from the client, forwarding them to the control and returning the response back to the client as soon as possible. (Refer to this blog to learn how we minimized the latency added by the Scientist.) In addition, the Lambda function stores results of the control invocation in DynamoDB, and asynchronously invokes the Experimentor Lambda function. To know which experiments to run and where to find the control and candidates the Scientist Lambda function relies on a YAML file in an AWS S3 bucket.
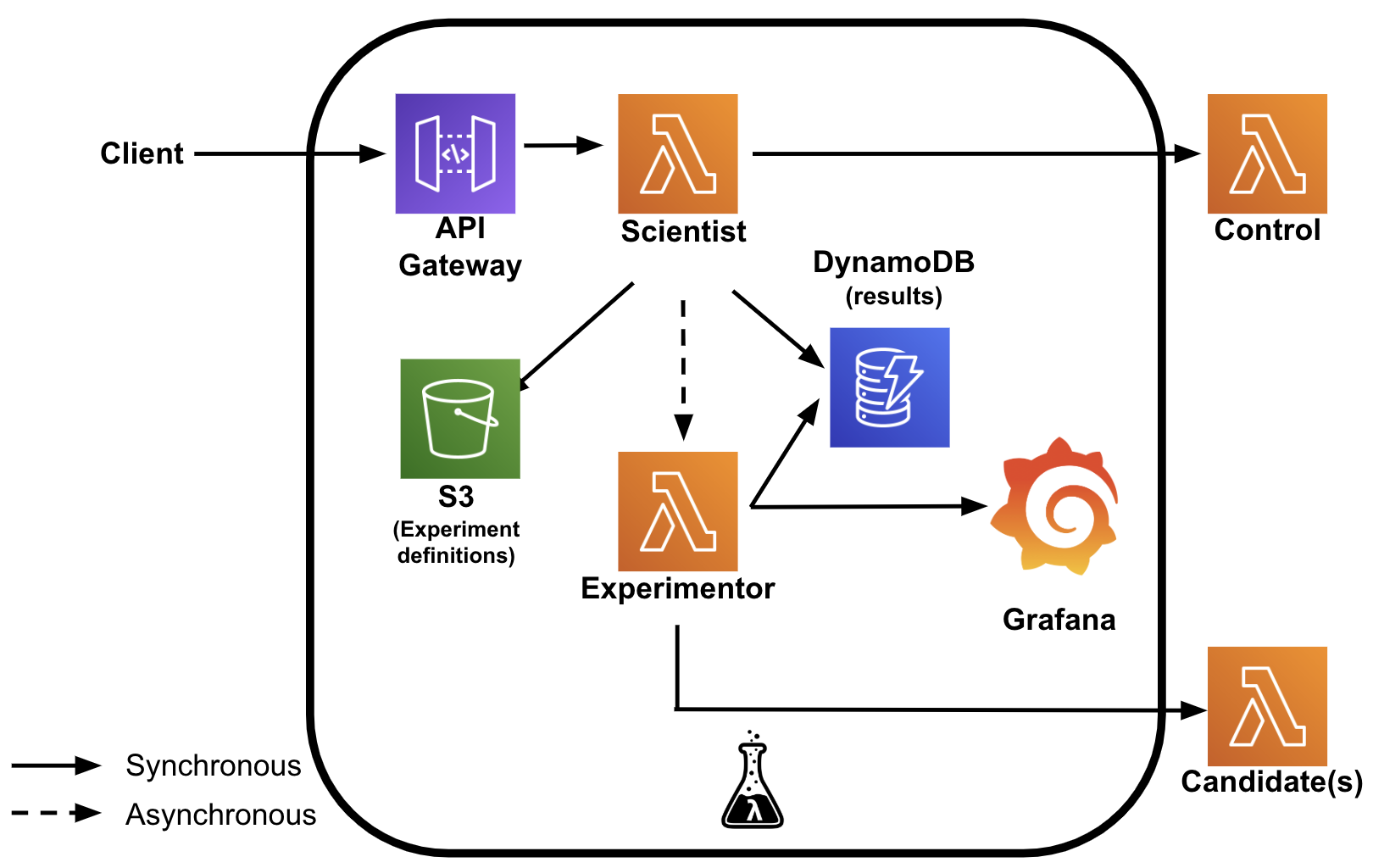
The Experimentor Lambda function invokes all candidates, compares their responses with the control responses and stores the results in a DynamoDB data store. The Experimentor also makes the results of the comparisons available in Grafana. In the Grafana dashboard, you can see the results of comparing the control and candidate(s) on aspects like:
- response status codes, response body, and headers;
- response times and memory usage.
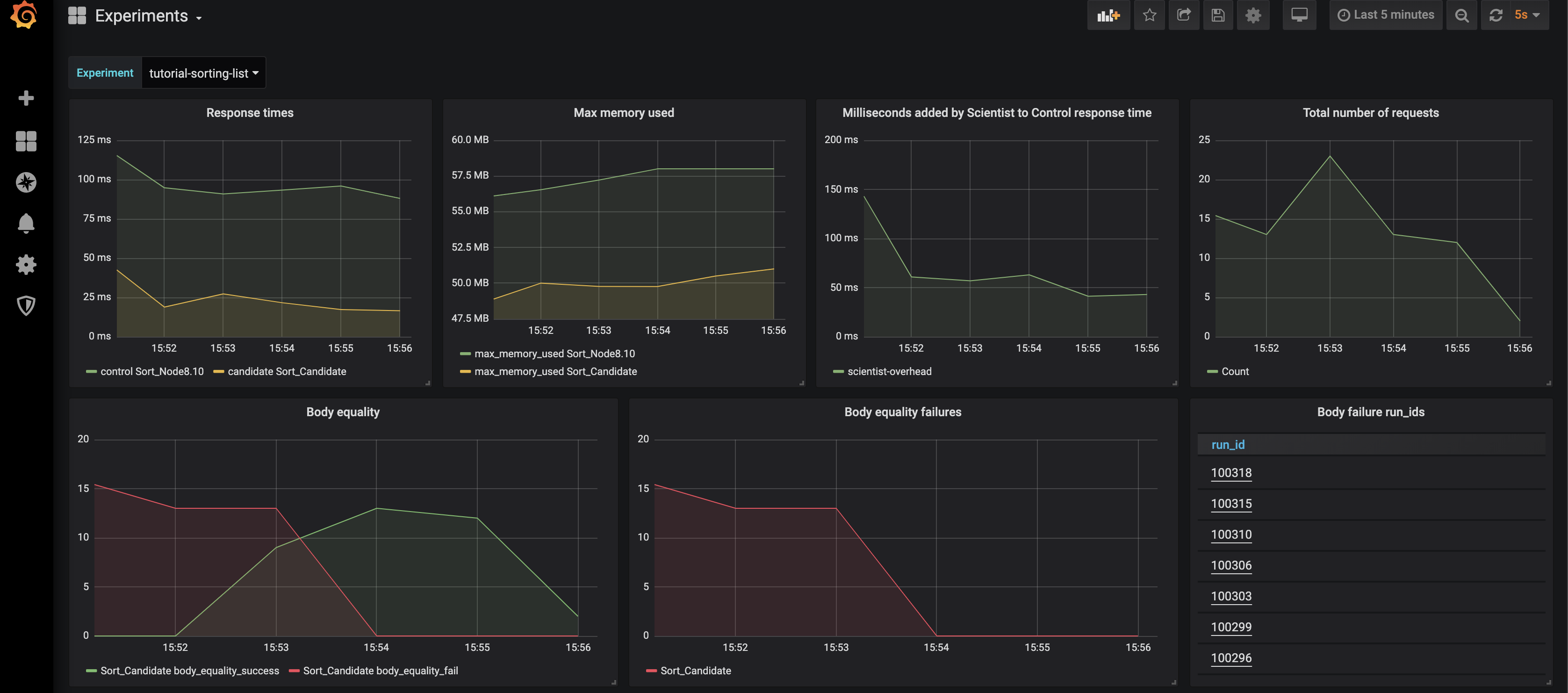
The screenshot below is an example of the dashboard. In the top row, it provides insight into response times and memory usage of control and candidates, the latency added by the scientist and the total number of requests. The 2nd row shows the results of comparing the response body of the candidate(s) against the control. On the far right are the IDs of experiment runs with failures. Clicking on these will take you to a page that shows the difference between control and response. As you can see around 15:54 a new version was deployed which resolved an error. Not shown in this screenshot, but present in the dashboard, are comparisons for HTTP headers and response codes.
Learnings
So, what did we learn when using the Serverless Scientist:
- When switching the implementation language for a Lambda function we noticed an unexpected difference between languages: the round() function in Python3 behaves differently than round() in Python2.7 and Javascript for numbers ending on .5.
- It is important to compare the intended result (the response semantics) and not the literal result (its syntax). For example:
{"first": 1, "second": 2}and{"second": 2, "first": 1}are semantically the same, but differ when comparing them literally. - We were able to iterate quickly with new candidate versions without impacting the clients at all. The Grafana dashboard proved to be really valuable here.
- Since we were routing real production traffic to the candidates, we did not have to generate test cases ourselves. Edge cases which we certainly would not have identified ourselves surfaced and could be resolved.
Of course, the (Serverless) Scientist approach is not a silver bullet. There are numerous situations where it is less applicable, for example, when:
- the interface of the candidate is not backwards compatible with the control;
- there is limited production traffic (in which case the coverage of functionality will be low);
- there is no control to compare against (e.g., it is the first implementation of the function);
- performance requirements do not allow for some additional latency by invoking an experiment. In our measurements, putting the Serverless Scientist between client and control does add ~50 milliseconds extra latency to the control responses. This may not be acceptable in all situations;
- control (and candidate) writes persistent changes to a data store. This adds additional complexity in synchronizing data stores, as you definitely do not want candidates to update the production data store.
What’s next?
But even with the above limitations, the use of Serverless Scientist proved to be useful for us while refactoring the /whereis #everybody?, and we plan to extend the functionality of the Serverless Scientist. Some of our ideas for that are:
- more fine-grained compare functions - the ability to compare different response formats like plain text, HTML output, JSON objects, PDF files, and images;
- distribute traffic over candidates - the ability to increase and decrease the percentage of production traffic that will be sent to a candidate function;
- easier management of experiments - a nice UI to create, update and terminate experiments, with the experiment data in a database instead of a YAML file in an AWS S3 bucket;
- support for generic API testing;
- custom metrics reporting endpoints;
- better UI for comparing results;
- support for other FaaS platforms like Google Functions and Microsoft Azure Functions.
Feel free to use Serverless Scientist for your projects and let us know your experiences.
Written by
Gero Vermaas
Our Ideas
Explore More Blogs




Contact