Blog
Run Large Language Models locally with Ollama and Open WebUI

What Are Ollama and Open WebUI?
Ollama is a platform for running large language models locally on your computer, while Open WebUI is a web-based interface that simplifies interacting with those models. Together, they allow users to deploy, manage, and use AI models privately, helping organizations maintain data sovereignty, improve security, and reduce dependence on cloud-hosted AI services.
Large Language Models (LLMs) like ChatGPT are amazing. But most big companies will always run their LLMs on the cloud. And the cloud is simply someone else's computer! What if you want to run your own LLMs, on your own computer?
You can! Let's get started.
What is Ollama?
Ollama is a tool that allows you to run Large Language Models locally. It can be used to download models and interact with them in a simple text-based user interface (TUI). Ollama can run in the background to provide LLM interfaces to other tools.
Install Ollama
You can install Ollama by going to their download page.
Or, on Mac, you can install it via Homebrew.
To install Ollama, run the following command in your terminal:brew install --cask ollama
Then, start the Ollama app.
Now, you can run Ollama commands by typing ollama in your terminal.
Talk to an LLM with Ollama
Let's try out Google's Gemma2. We choose the 2B version due to its small size. This will make it a quick download and it will run fast, compared to bigger models.
Run the following command to download Gemma2:2b:ollama pull gemma2:2b
Once the download finishes, we can start chatting with Gemma2:ollama run gemma2:2b >>> Hi Hello! How can I help you today?
Nice, you're talking to an LLM which runs on your own computer! If you want to try other models, you can find available models at the Ollama library.
Ollama's chat interface is fine for testing, but overall it's pretty limited. Let's do something about that!
Open WebUI
Open WebUI is a web interface that can connect to LLM services such as Ollama (and also OpenAI). It has UI that is inspired by the interface of ChatGPT.
Install Open WebUI
Note that this installation requires Docker.
We can download, install and run Open WebUI with one Docker command:docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
Here's what the commands mean:docker run: Run Open WebUI in a Docker container.-d: run in the background.-p 3000:8080: Mount local port 3000 to container port 8080.--add-host: Make sure Docker can talk to Ollama.-v mount a shared volume, so our data is stored, even when the container stops.--restart: Always run in the background.--name: Name of the container.
ghcr.io/open-webui/open-webui:main: The container we run.
Open WebUI will now be available at http://localhost:3000/.
Set up Open WebUI
Open http://localhost:3000/ in your browser.
Open WebUI requires a signup, so you can become the admin. Don't worry, your data stays in your computer!
Here's what Open WebUI says in their FAQ:
Q: Why am I asked to sign up? Where are my data being sent to?
A: We require you to sign up to become the admin user for enhanced security. This ensures that if the Open WebUI is ever exposed to external access, your data remains secure. It's important to note that everything is kept local. We do not collect your data. When you sign up, all information stays within your server and never leaves your device. Your privacy and security are our top priorities, ensuring that your data remains under your control at all times.
Most likely, you won't need to login anymore after this. Don't forget to save your password somewhere safe!
Talk to an LLM with Open WebUI
Once signed up, you can start chatting with gemma2:2b. If it is not automatically selected, click on "Select a model" and choose gemma2:2b.
At the bottom of the screen, click on "Send a message" and start chatting!
The interface is fairly straightforward and requires little explanation. But there are some cool things you can do.
Cool features
Run Multiple LLMs on the same prompt
Click the plus icon (next to your selected model) and add another model. You can now compare LLMs side by side!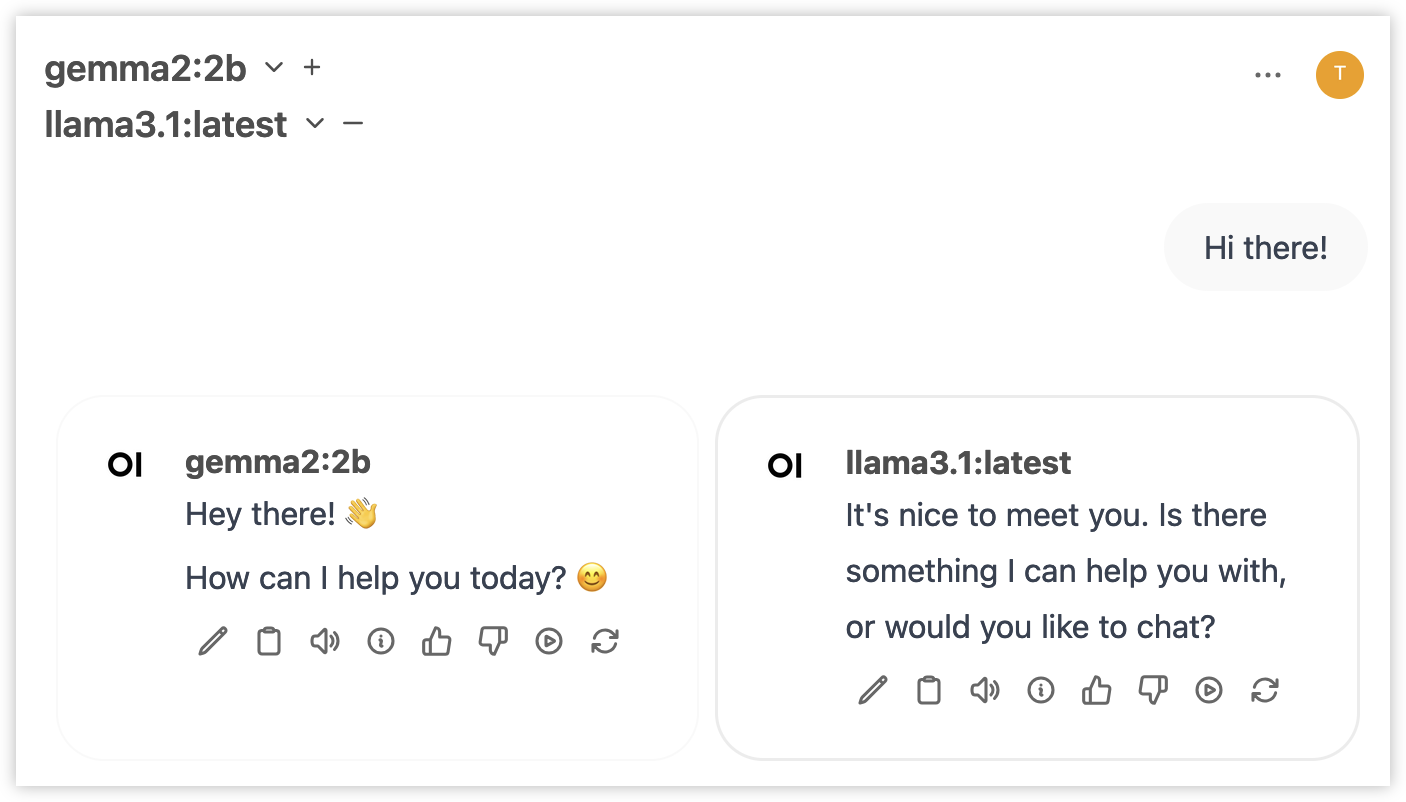
Add content from a file
Left of where you send your message, click the plus icon (+). Select "Upload Files" and pick a file. Now, you can ask questions about the file contents. Note that it doesn't always work perfectly, so try to be specific and reference the file.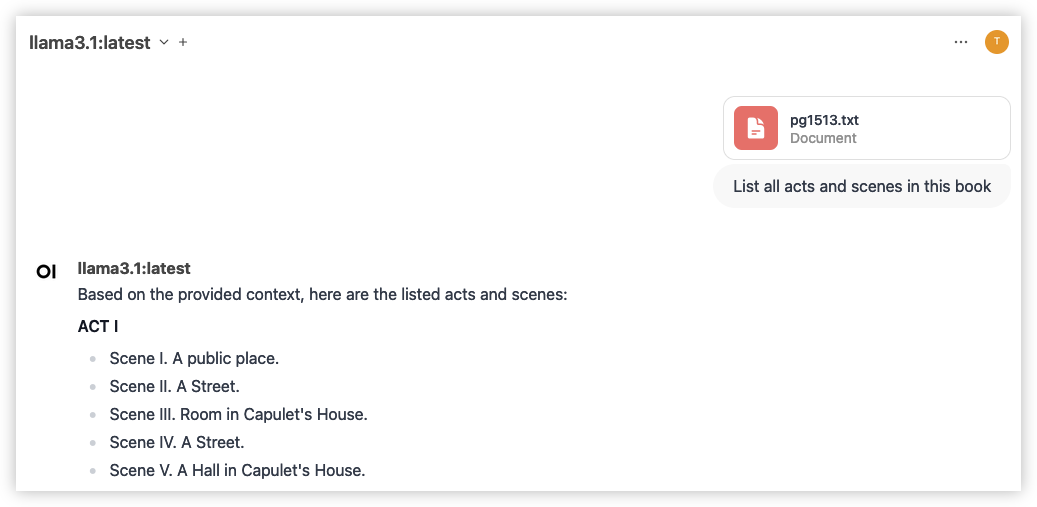
This example uses the free ebook Romeo and Juliet by William Shakespeare
Add web content
We can add web data by placing a # and pasting a URL. Make sure to press Enter. This will add the web contents as a document.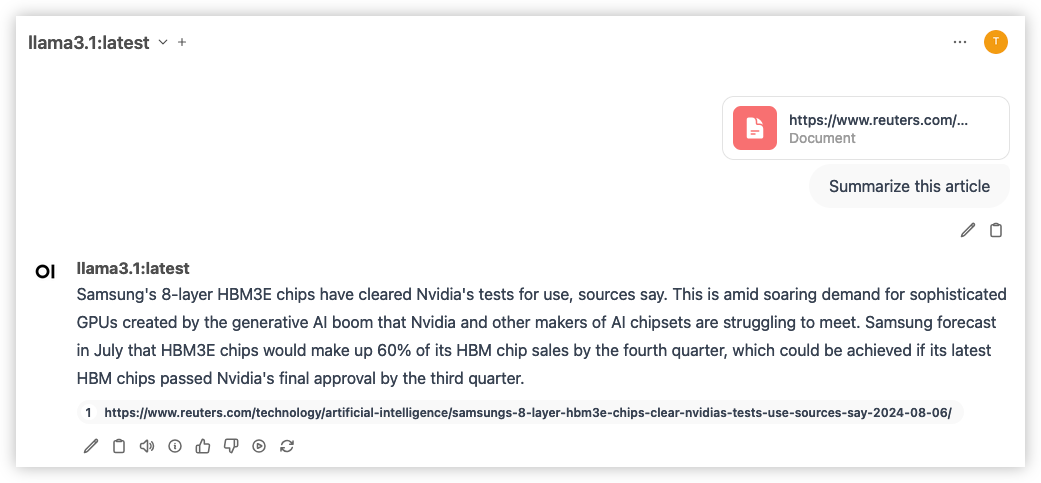
Run code directly
If you ask your LLM to create code and it provides a code block, you can click "Run" on the top right of the code block. This will run the code and provide the output below the code block.
Of course, review the code before running to make sure it does not do anything you do not want!
There are many more features in Open WebUI, which you can explore here.
Conclusion
That's it! You're running Large Language Models locally with Ollama and Open WebUI. You can chat privately, use different models and more!
Written by
Timo Uelen
Timo Uelen is a Machine Learning Engineer at Xebia.
Our Ideas
Explore More Blogs

Feeling behind AI? Start here.
A lot of people in tech feel one step behind the AI conversation. This post helps close that gap, from LLM basics to AI agents.
Giorgia Corrado



Contact