Blog
Resolving Re-Used Business Keys in Data Vault 2.0 with the Business Vault

Introduction
In the world of data modeling, one of the challenges organizations face is managing tables with business keys (BKs) that are re-used over time. This issue typically occurs when a company, for technical limitations in the source system, reuses primary keys or "unique identifiers" over time. This practice can lead to ambiguity, especially when historical data is needed for analytical purposes. This blog post explores how to use Data Vault 2.0 to resolve re-used BKs by leveraging the Business Vault.
Understanding the Data Vault 2.0 Architecture
Data Vault 2.0 is often seen as a modeling technique, but it's a full solution that covers methodology, architecture, implementation, and modeling.
Let’s have a look at the below architecture:
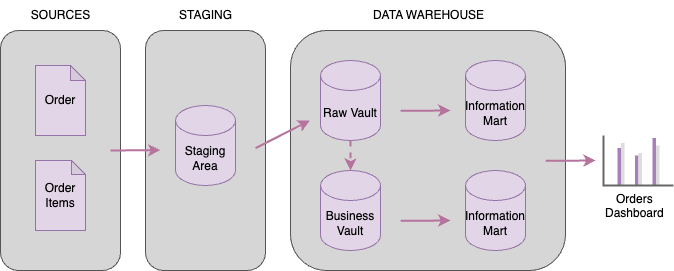
- The first step is to extract the data from the source systems and load the data in its raw format into a Staging Area.
- Next you can apply hard rules if necessary, such as data type changes.
- Then you load the data into the Raw Vault and model the data into Hubs, Links, Satellites etc.
- If you need to apply business logic to your data across more than one use case, you can extend the Raw Vault by creating a Business Vault.
- The last step is to build the Information Marts (IMs) to be used for reporting/dashboarding purposes. The IM tables or views are built using the Raw Vault/Business Vault and can be modeled using Kimball dimensional modeling for example. Check this other blog as reference: https://xebia.com/blog/kimball-dimensional-modelling/.
Let's check an example
Suppose we are an e-commerce business, and we want to analyze our orders information. The order code is re-used over time. In this scenario, we typically have one source table for the order header, and another for the order items.
order header:
| order_code | order_date | customer _code | ship_to_city |
| 1111 | 10/10/2024 | A | Almere |
| 1112 | 11/10/2024 | B | Amsterdam |
| 1111 | 12/11/2024 | D | Breda |
order items:
| order_code | line_code | item_code | quantity | amount |
| 1111 | 1 | AB | 1 | 32 |
| 1111 | 2 | BC | 2 | 34.99 |
| 1111 | 3 | DF | 10 | 56 |
| 1112 | 1 | BC | 5 | 70 |
| 1112 | 2 | XS | 1 | 5 |
| 1111 | 1 | DE | 20 | 251.95 |
The expectation of the Business Intelligence (BI) team is that they should have two Information Mart tables, one for the order header and another one for the order items, and they need to be able to join them for reporting purposes. They also want to keep track of the full historical changes.
To determine which order items are linked to each order header, we would typically check the foreign key to order_code in the order items table, allowing us to reconstruct the complete order.
However, if we examine the order header table closely, we notice that the order_code "1111" was reused on a different date. This introduces the complexity of determining which item codes are associated with each order_code over time.
The logical solution in this case is to create a primary key (PK) in the order header table that uniquely identifies each order over time. This same value should be inserted as a foreign key (FK) in the order items table. By including the order_date as part of the primary key, we can ensure uniqueness and achieve a table with the expected results, as shown below:
im_order_header:
| pk_order_code | order_code | order_date | customer_code | ship_to_city |
| 1111 || 10/10/2024 | 1111 | 10/10/2024 | A | Almere |
| 1112 || 11/10/2024 | 1112 | 11/10/2024 | B | Amsterdam |
| 1111 || 12/11/2024 | 1111 | 12/11/2024 | D | Breda |
im_order_items:
| pk_order_line_code | fk_order_code | order_code | line_code | Item_code | quantity | amount |
| 1111 || 10/10/2024 || 1 | 1111 || 10/10/2024 | 1111 | 1 | AB | 1 | 32 |
| 1111 || 10/10/2024 || 2 | 1111 || 10/10/2024 | 1111 | 2 | BC | 2 | 34.99 |
| 1111 || 10/10/2024 || 3 | 1111 || 10/10/2024 | 1111 | 3 | DF | 10 | 56 |
| 1112 || 11/10/2024 || 1 | 1112 || 11/10/2024 | 1112 | 1 | BC | 5 | 70 |
| 1112 || 11/10/2024 || 2 | 1112 || 11/10/2024 | 1112 | 2 | XS | 1 | 5 |
| 1111 || 12/11/2024 || 1 | 1111 || 12/11/2024 | 1111 | 1 | DE | 20 | 251.95 |
In the next sections, we cover how you can use Data Vault 2.0 to obtain this output.
The Raw Vault
Let’s assume that your data is already extracted and available in the Staging Area. Next step is to load the data into the Raw Vault. In this blog, we will not cover the details about the different structures that can be created in the Data Warehouse following the Data Vault 2.0 principles, such as hubs, links, and satellites. Below, you can find one possible solution to model the order data.
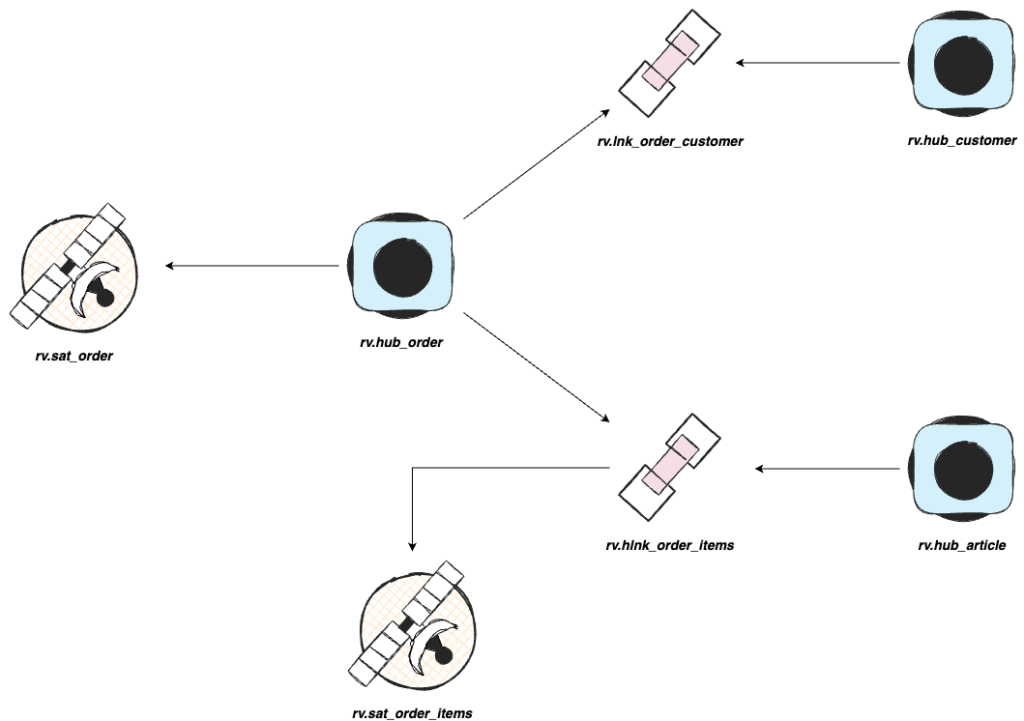
After creating your satellites, you will see the information below. In Data Vault 2.0, best practices recommend using Hash Keys (HK) to uniquely identify records and ensure consistent joins between tables. Hash Keys provide better performance during joins compared to text-based data types.
rv_sat__order_header:
| hk_order | order_code | order_date | customer_code | ship_to_city | load_date | end_date |
| MD5(1111) | 1111 | 10/10/2024 | A | Almere | 10/10/2024 | 12/11/2024 |
| MD5(1112) | 1112 | 11/10/2024 | B | Amsterdam | 11/10/2024 | NULL |
| MD5(1111) | 1111 | 12/11/2024 | D | Breda | 12/11/2024 | NULL |
rv_sat__order_items:
| hk_order | hk_order_line | order_code | line_code | item_code | quantity | amount | load_date | end_date |
| MD5(1111) | MD5(1111 || 1) | 1111 | 1 | AB | 1 | 32 | 10/10/2024 | 12/11/2024 |
| MD5(1111) | MD5(1111 || 2) | 1111 | 2 | BC | 2 | 34.99 | 10/10/2024 | 12/11/2024 |
| MD5(1111) | MD5(1111 || 3) | 1111 | 3 | DF | 10 | 56 | 10/10/2024 | 12/11/2024 |
| MD5(1112) | MD5(1112 || 1) | 1112 | 1 | BC | 5 | 70 | 11/10/2024 | NULL |
| MD5(1112) | MD5(1112 || 2) | 1112 | 2 | XS | 1 | 5 | 11/10/2024 | NULL |
| MD5(1111) | MD5(1111 || 1) | 1111 | 1 | DE | 20 | 251.95 | 12/11/2024 | NULL |
So now, we need to consider the following:
- The same order code is only active once in the satellite (with end_date equal to NULL).
- If you use these satellites to create your Information Marts tables or views, it’s essential to include only the active records and exclude historical data. Failing to filter for active records will result in non-unique primary keys, making it impossible to join the header and items models correctly.
The business requires analyzing historical data to make informed decisions. Looking at the expected result, we can see that making the primary key unique involves applying business logic. Both tables need to use a combination of order_code and order_date as the unique identifier. However, the raw data for order items lacks any date information. In this scenario, we have the following possibilities:
- Ask the data provider to include the date information in the order items source table. This can be very time-consuming and sometimes not possible.
- After you load the data to the raw vault, create business logic to include the order code + order date combination into the item's information. This can be done by leveraging the Business Vault.
- Joining the header and items table before loading the data into the Raw Vault is not an option, because it would violate the Data Vault 2.0 standards that in the Staging Layer you only should apply hard rules.
- Joining the header and items data after loading the data into the Raw Vault in the Information Mart is also not ideal because it adds complexity and redundancy to the reporting layer. The business logic to combine order code + order date would need to be recreated for every use case, leading to inconsistencies.
The Business Vault
The Business Vault is an extension of the Raw Vault, particularly useful when you need to apply business logic that is needed for several use cases. It needs to be implemented in a way where you will have the same surrogate key for both the order header and the order items.
bv__order_header:
The bv__order_header is an extension of the rv_sat__order_header. To create it, you need to generate a surrogate key and recalculate the end_date based on the previous load_date value for each surrogate key. This approach allows you to handle cases where two order_code values, such as "1111", are valid simultaneously. Below is an example of the code and how the Business Vault order header table would look:
with
unique_key as (
select
order_code,
order_date,
concat (bk_order_code, ' || ', order_date) as bk_order_code,
customer_code,
ship_to_city,
load_date
from
rv_sat__order_header
),
end_date_calculation as (
select
*,
lead (load_date) over (
partition by
bk_order_code
order by
load_date
) as end_date
from
unique_key
)
select
bk_order_code,
order_date,
customer_code,
ship_to_city,
load_date,
coalesce(end_date, '9999-12-31') as end_date
from
end_date_calculation
| order_code | order_date | bk_order_code | customer_code | ship_to_city | load_date | end_date |
| 1111 | 10/10/2024 | 1111 || 10/10/2024 | B | Almere | 10/10/2024 | 11/10/2024 |
| 1111 | 10/10/2024 | 1111 || 10/10/2024 | A | Almere | 11/10/2024 | 31/12/9999 |
| 1112 | 11/10/2024 | 1112 || 11/10/2024 | B | Amsterdam | 11/10/2024 | 12/10/2024 |
| 1112 | 11/10/2024 | 1112 || 11/10/2024 | B | Amsterdam | 12/10/2024 | 31/12/9999 |
| 1111 | 12/11/2024 | 1111 || 12/11/2024 | D | Breda | 12/11/2024 | 31/12/9999 |
bv__order_items:
A similar logic applies for creating the business vault table for rv_sat__order_items, but first you need to add the same surrogate key from the business vault order header that was previously created. Again, a code example and how the Business Vault order items table would look like:
with
sat_order_items as (
select
order_code,
line_code,
item_code,
quantity,
amount,
load_date
from
rv_sat__order_items
),
bv_order_header as (
select
*
from
bv__order_header
),
add_unique_key as (
select
sat_order_items.*,
bv_order_header.bk_order_code,
concat (
bv_order_header.bk_order_code,
"||",
sat_order_items.line_code
) as bk_order_line_code
from
sat_order_items
left join bv_order_header on sat_order_items.order_code = bv_order_header.bk_order_code
and sat_order_items.load_date between bv_order_header.load_date and bv_order_header.end_date
),
end_date_calculation as (
select
*,
lead (load_date) over (
partition by
bk_order_line_code
order by
load_date
) as end_date
from
add_unique_key
)
select
*,
coalesce(end_date, '9999-12-31') as end_date
from
end_date_calculation
| order_code | bk_order_code | bk_order_line_code | line_code | item_code | quantity | amount | load_date | end_date |
| 1111 | 1111 || 10/10/2024 | 1111 || 1 || 10/10/2024 | 1 | AB | 1 | 32 | 11/10/2024 | 31/12/9999 |
| 1111 | 1111 || 10/10/2024 | 1111 || 2 || 10/10/2024 | 2 | BC | 2 | 34.99 | 11/10/2024 | 31/12/9999 |
| 1111 | 1111 || 10/10/2024 | 1111 || 3 || 10/10/2024 | 3 | DF | 10 | 56 | 11/10/2024 | 31/12/9999 |
| 1112 | 1112 || 11/10/2024 | 1112 || 1 || 11/10/2024 | 1 | BC | 5 | 70 | 12/10/2024 | 31/12/9999 |
| 1112 | 1112 || 11/10/2024 | 1112 || 2 || 11/10/2024 | 2 | XS | 1 | 5 | 12/10/2024 | 31/12/9999 |
| 1111 | 1111 || 12/11/2024 | 1111 || 1 || 12/11/2024 | 1 | DE | 20 | 251.95 | 12/11/2024 | 31/12/9999 |
With the Business Vault in place, you can now create Information Marts that fully complies with the BI requirements.
By materializing the Information Mart as a view that pulls directly from the Business Vault, you can avoid duplicating data across multiple layers and reduce the need for computations at the Information Mart layer. This approach significantly improves the speed at which BI tools can access and analyze the data.
It’s important to note that, since a new business key was created by applying business logic, you will also need to reconstruct the Order Hub and establish links between the new business key and the Customer and Item Hubs within the Business Vault. This ensures consistent integration and traceability across the model.
Conclusion
Managing re-used business keys in a Data Vault 2.0 implementation can be challenging, but the Business Vault provides a robust solution to maintain historical integrity and ensure data uniqueness.
Do you need help tackling complex Data Vault 2.0 challenges? Our Data Vault 2.0 certified analytics engineers at Xebia are here to assist you in leveraging your data vault effectively. Contact us today to unlock the full potential of your data!
Written by
Camila Birocchi
I'm a technology enthusiast passionate about problem-solving and making companies data-driven. I thrive on turning challenges into solutions and transforming data into actionable insights.
Our Ideas
Explore More Blogs




Contact