Blog
RAG on GCP: production-ready GenAI on Google Cloud Platform

Introduction
Google Cloud Platform has an increasing set of managed services that can help you build production-ready Retrieval-Augmented Generation applications. Services like Vertex AI Search & Conversation and Vertex AI Vector Search give us scalability and ease of use. How can you best leverage them to build RAG applications? Let's explore together. Read along!
Retrieval Augmented Generation
Even though Retrieval-Augmented Generation (RAG) was coined already in 2020, the technique got supercharged since the rise of Large Language Models (LLMs). With RAG, LLMs are combined with search techniques like vector search to enable realtime and efficient lookup of information that is outside the model's knowledge. This opens up many exciting new possibilities. Whereas previously interactions with LLMs were limited to the model's knowledge, with RAG it is now possible to load in company internal data like knowledge bases. Additionally, by instructing the LLM to always 'ground' its answer based on factual data, hallucinations can be reduced.
Why RAG?
Let's first take a step back. How exactly can RAG benefit us? When we interact with an LLM, all its factual knowledge is stored inside the model weights. The model weights are set during its training phase, which can be a while ago. In fact, this can be more than a year.
| LLM | Knowledge cut-off |
|---|---|
| Gemini 1.0 Pro | Early 2023 1 |
| GPT-3.5 turbo | September 2021 [2] |
| GPT-4 | September 2021 [3] |
Knowledge cut-offs as of March 2024.
Additionally, these publically offered models are trained on mostly public data. If you want to use company internal data, an option is to fine-tune or retrain the model, which can be expensive and time-consuming.
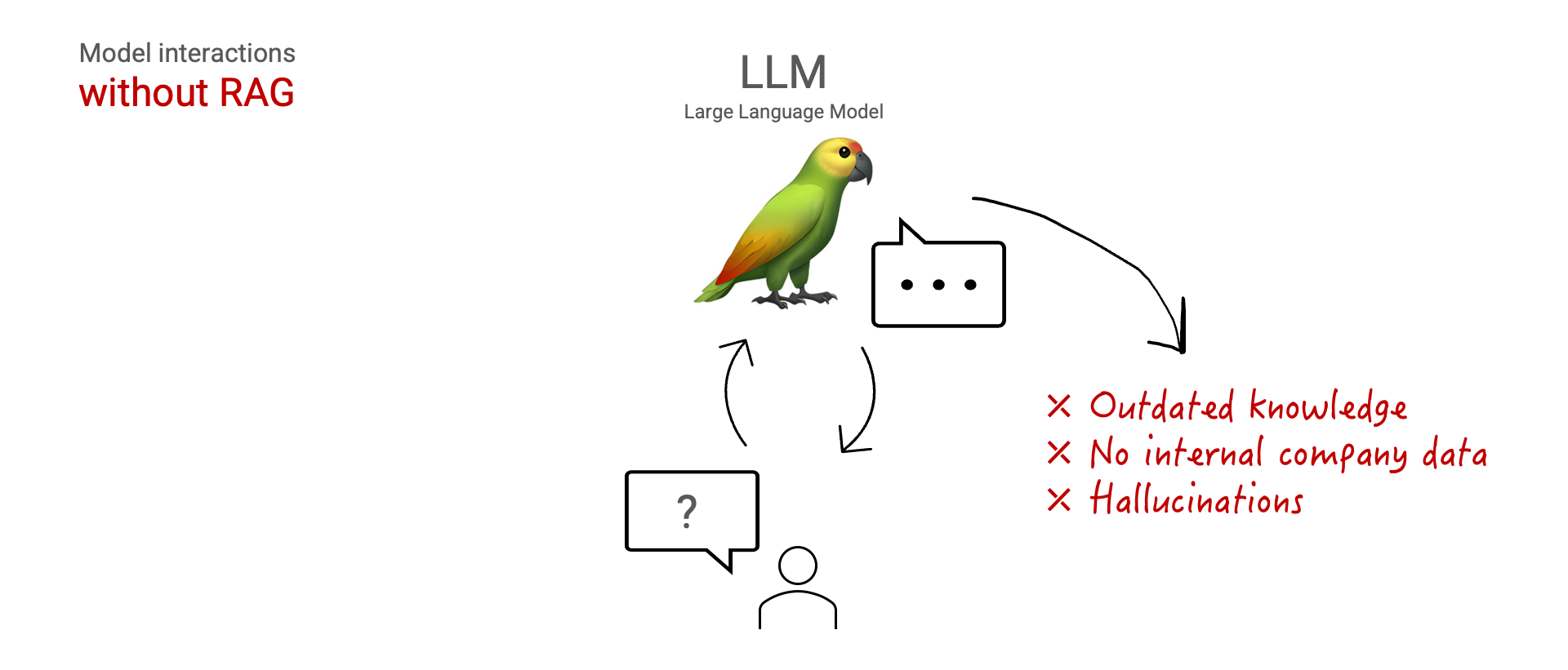
This boils down to three main limitations: the models knowledge is outdated, the model has no access to internal data, and the model can hallucinate answers.
With RAG we can circumvent these limitations. Given the question a user has, information relevant to that question can be retrieved first to then be presented to the LLM.
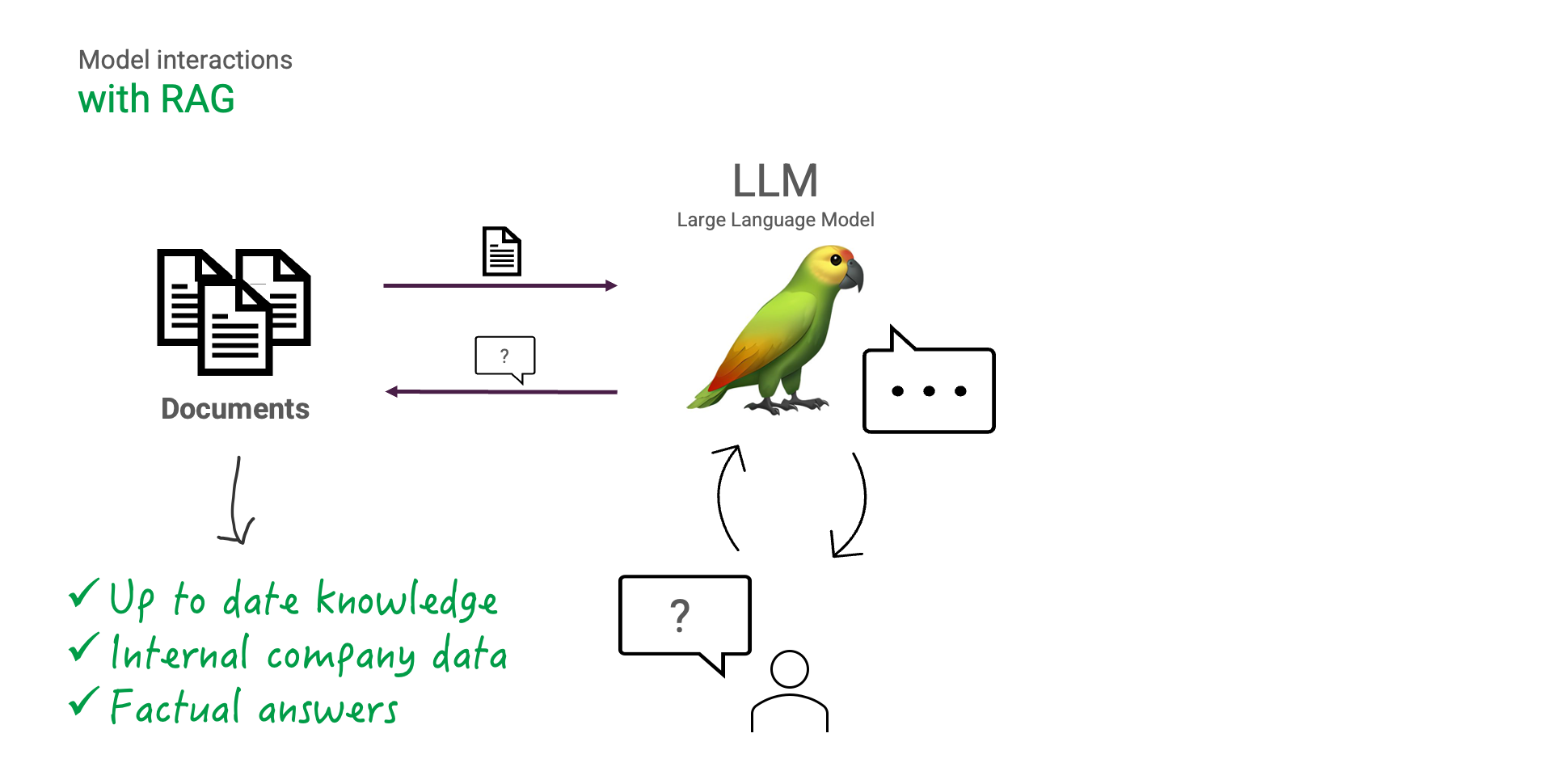
The LLM can then augment its answer with the retrieved information to generate a factual, up-to-date and yet human-readable answer. The LLM is to be instructed to at all times ground its answer in the retrieved information, which can help reduce hallucinations.
These benefits are great. So how do we actually build a RAG system?
Building a RAG system
In a RAG system, there are two main steps: 1) Document retrieval and 2) Answer generation. Whereas the document retrieval is responsible for finding the most relevant information given the user's question, the answer generation is responsible for generating a human-readable answer based on information found in the retrieval step. Let's take a look at both in more detail.
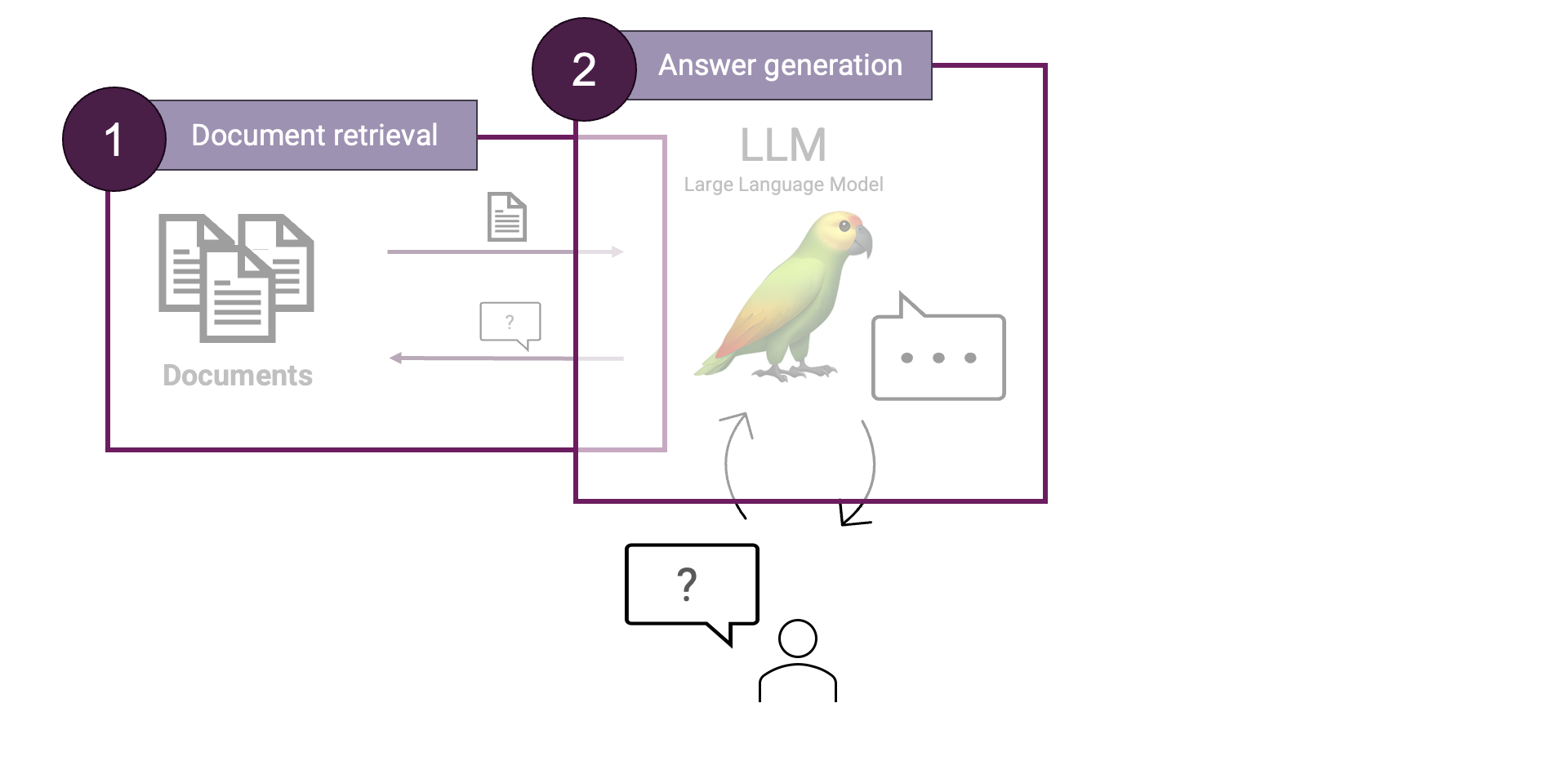
Document retrieval
First, Document retrieval. Documents are converted to plain text and chunked. The chunks are then embedded and stored in a vector database. User questions are also embedded, enabling a vector similarity search to obtain the best matching documents. Optionally, a step can be added to extract document metadata like title, author, summary, keywords, etc, which can subsequently be used to perform a keyword search. This can all be illustrated like so:
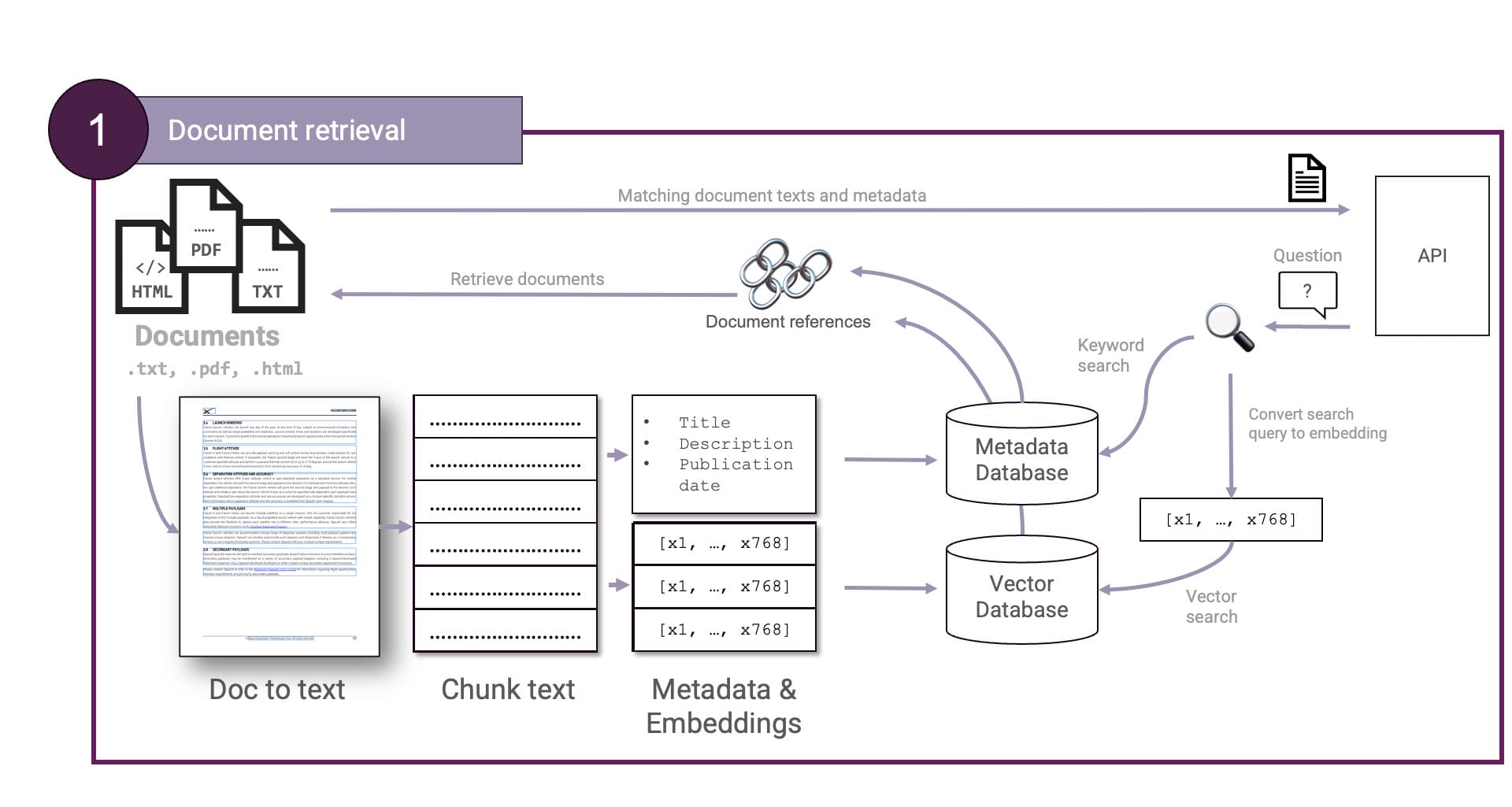
Neat. But what about GCP. We can map the former to GCP as follows:
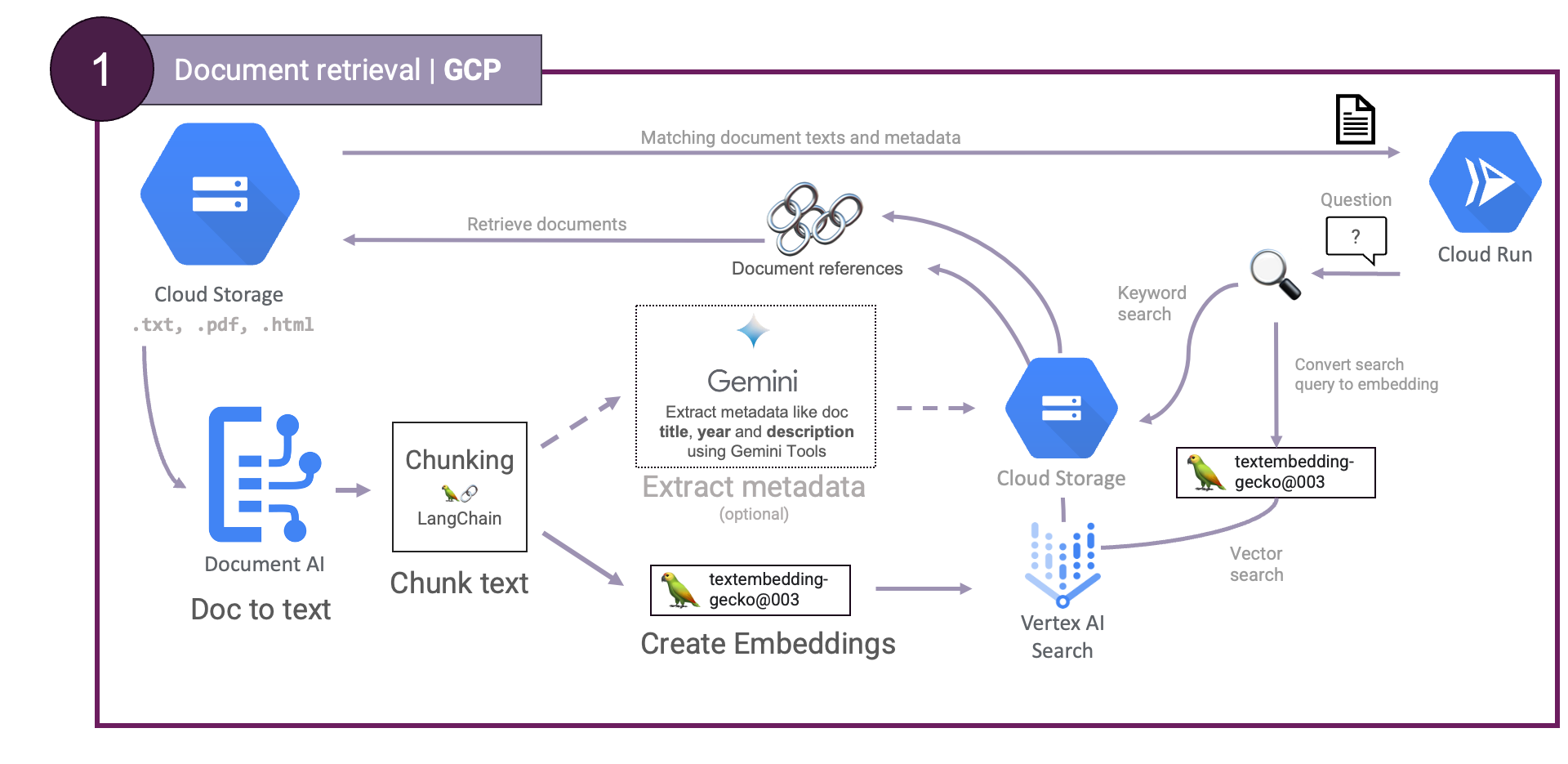
textembedding-gecko and Vertex AI Vector Search.Document AI is used to process documents and extract text, Gemini and textembedding-gecko to generate metadata and embeddings respectively and Vertex AI Vector Search is used to store the embeddings and perform similarity search. By using these services, we can build a scalable retrieval step.
Answer generation
Then, Answer generation. We will need an LLM for this and instruct it to use the provided documents. We can illustrate this like so:
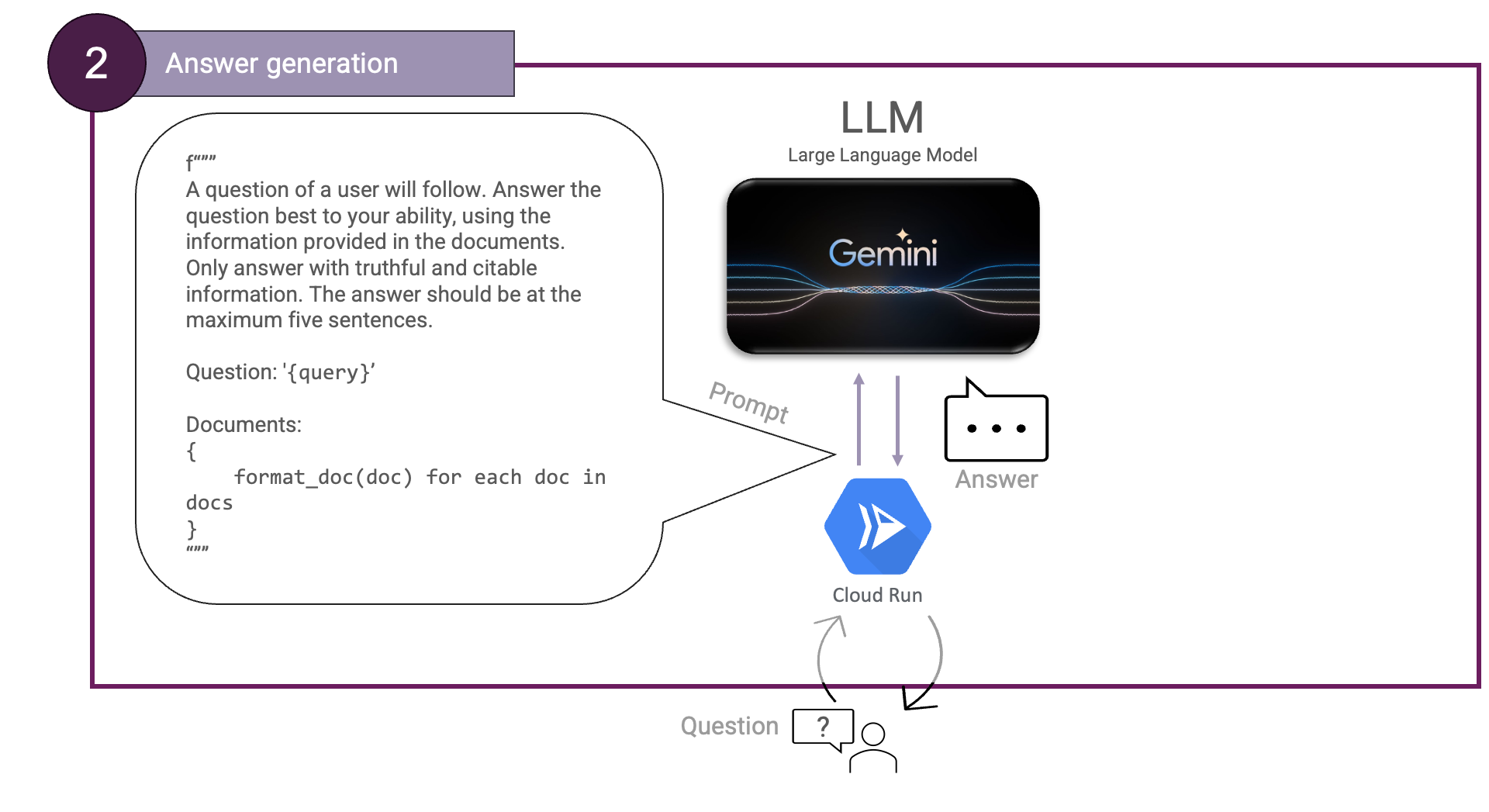
Here, the documents can be formatted using an arbitrary function that generates valid markdown.
We have already come across multiple GCP services that can help us build a RAG system. So now, what other offerings does GCP have to help us build a RAG system and what flavours are there to combine services?
The RAG flavours on GCP
So far, we have seen GCP services that can help us build a RAG system. These include Document AI, Vertex AI Vector Search, Gemini Pro, Cloud Storage and Cloud Run. But GCP also has Vertex AI Search & Conversation.
Vertex AI Search & Conversation is a service tailored to GenAI usecases, built to do some of the heavy lifting for us. It can ingest documents, create embeddings and manage the vector database. You just have to focus on ingesting data in the correct format. Then, you can use Search & Conversation in multiple ways. You can either get only search results, given a search query, or you can let Search & Conversation generate a full answer for you with source citations.
Even though Vertex AI Search & Conversation is very powerful, there can be scenarios when you want more control. Let's take a look on these levels of going either managed or remaining in-control.
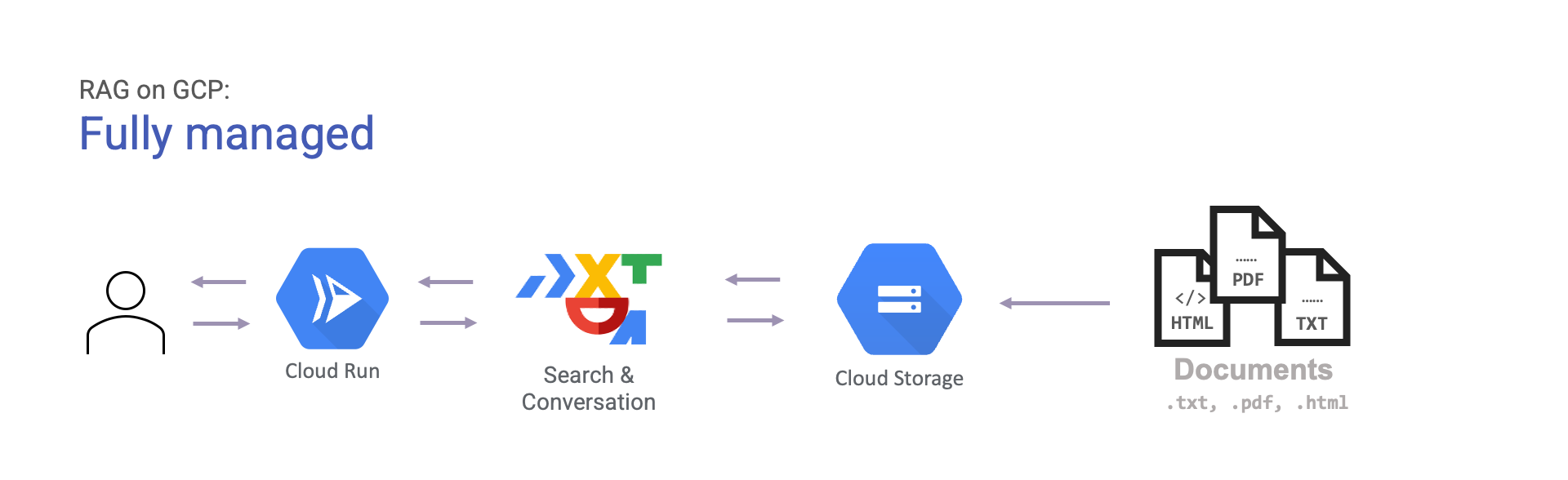
The easiest way to get started with RAG on GCP is to use Search & Conversation. The service can ingest documents from multiple sources like Big Query and Google Cloud Storage. Once those are ingested, it can generate answers backed by citations for you. This is simply illustrated like so:
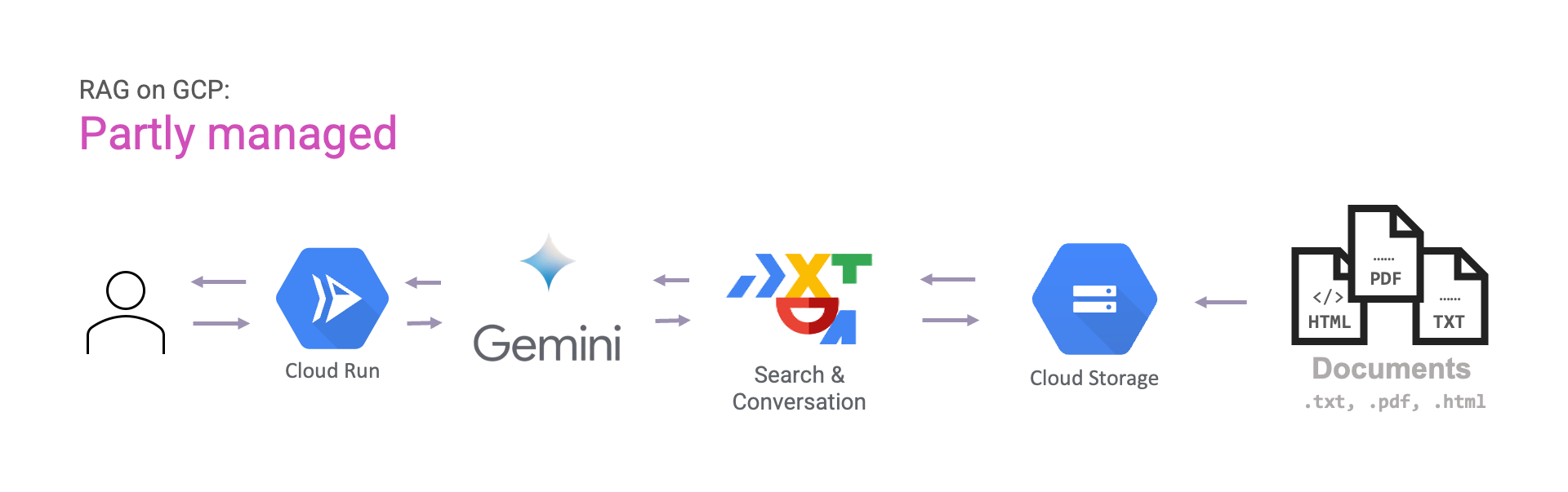
If you want more control, you can use Gemini for answer generation instead of letting Search & Conversation do it for us. This way, you can have more control to do any prompt engineering you like.
Lastly, you can have full control over the RAG system. This means you have to manage both the document retrieval and answer generation yourself. This does mean more manual work in engineering the system. Documents can be processed by Document AI, chunked, embedded and its vectors stored in Vertex AI Vector Search. Then Gemini can be used to generate the final answers.
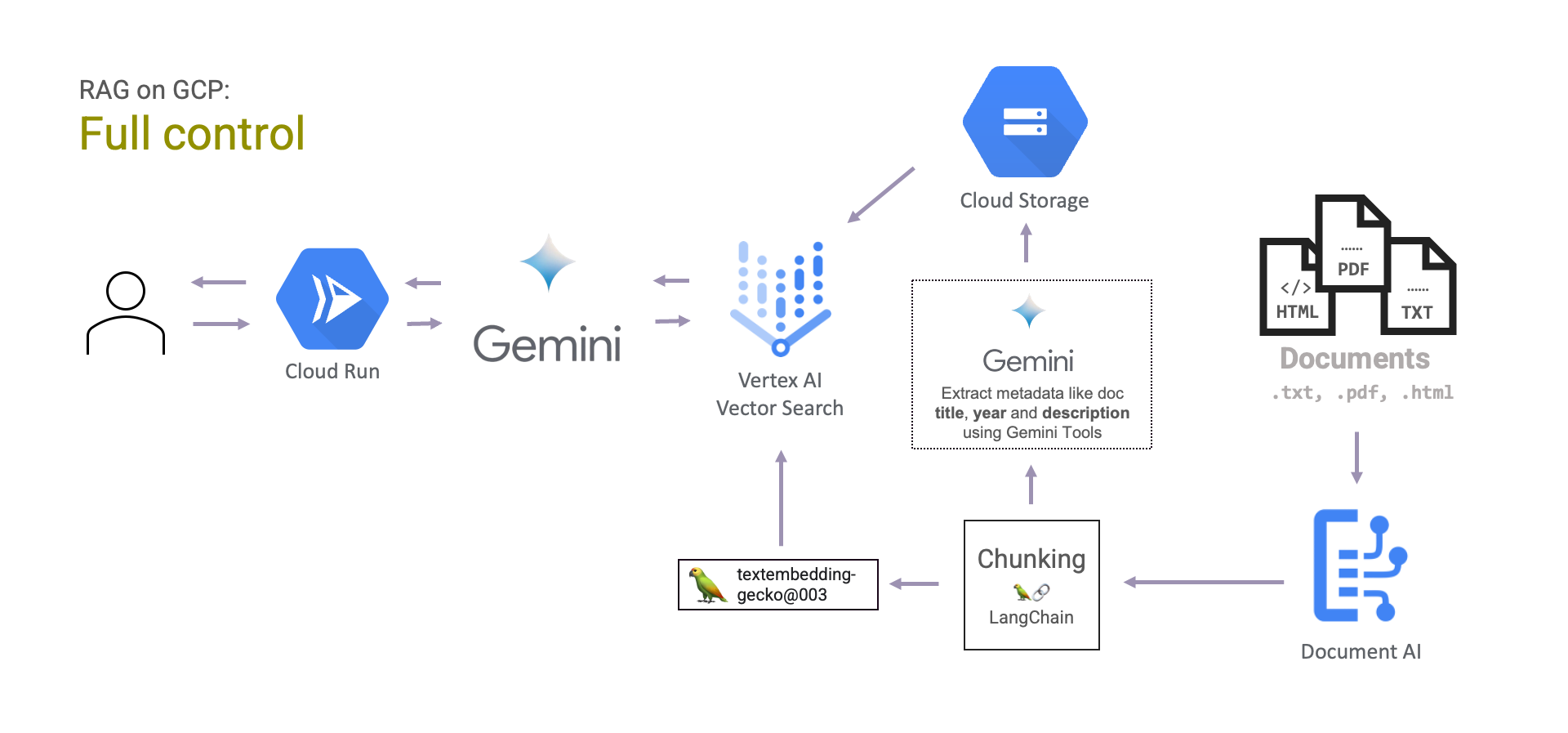
The advantage here is that you are able to fully control yourself how you process the documents an convert them to embeddings. You can use all of Document AI's Processors offering to process the documents in different ways.
Do take the the managed versus manual approach tradeoffs into consideration. Ask yourself questions like:
- How much time and energy do you want to invest building something custom for the flexibility that you need?
- Do you really need the flexibility for your solution to give in to extra maintenance cost?
- Do you have the engineering capacity to build- and maintain a custom solution?
- Are the initially invested build costs worth the money saved in not using a managed solution?
So then, you can decide what works best for you ✓.
Concluding
RAG is a powerful way to augment LLMs with external data. This can help reduce hallucinations and provide more factual answers. At the core of RAG systems are document processors, vector databases and LLM's.
Google Cloud Platform offers services that can help build production-ready RAG solutions. We have described three levels of control in deploying a RAG application on GCP:
- Fully managed: using Search & Conversation.
- Partly managed: managed search using Search & Conversation but manual prompt-engineering using Gemini.
- Full control: manual document processing using Document AI, embedding creation and vector database management using Vertex AI Vector Search.
That said, I wish you good luck implementing your own RAG system. Use RAG for great good! ♡
Photo by Ilo Frey: https://www.pexels.com/photo/photo-of-yellow-and-blue-macaw-with-one-wing-open-perched-on-a-wooden-stick-2317904/
Written by

Jeroen Overschie
Machine Learning Engineer
Jeroen is a Machine Learning Engineer at Xebia.




Contact