
Quartiles Solver: Part II
In the first part of this three-part series, we developed the English dictionary for a Quartiles solver and developed some benchmarks for deserialization performance. In this post, the second part of the three-part series, we design and develop the solver itself. You may wish to check out the project at various points during our journey.
Design considerations for the solver
Armed with a fast dictionary amenable to prefix searching, we're ready to consider what we want out of the application as a whole:
- The application will be a text-based user interface (TUI) running on a single thread.
- Good user experience (UX) design requires that the user interface (UI remain responsive to the user at all times.
- Furthermore, good UX design requires that ongoing computation must show progress in some fashion.
A short, agreeable list, wouldn't you say? Now, given that the solver is the heart and soul of this application, how do these application design goals guide us in setting solver design goals?
- Recalling the upper bound that we computed in Part I, there are
123520possible permutations of the board that correspond to well-formed quartiles. This is possibly too much work to satisfy application design goal #2 (the UI must remain responsive). This implies that the solver should be interruptible. - But the solver does need to run until it has found all of the words on the board, which means that the solver needs to be resumable. Interruptible and resumable go hand in hand — it's not an interruption if you don't eventually resume an algorithm, it's just stoppage!
- As we just mentioned, the solver should find every word in the intersection of the board and the dictionary, so it should be exhaustive.
- Perhaps obvious, but the solver should terminate for every possible input. We'll see below that there are plenty of opportunities to fail at this one.
- The solver shouldn't be a total black box. It should be informative, communicating its discoveries to the UI, pursuant to application design goal #3 (computational progress should be shown).
- We want to run the whole application on a single thread and there'll be a user hanging on for a solution, so the solver should be fast. Finishing in hundreds of milliseconds should be plenty fast enough in meat time.
- In furtherance of being fast, the solver should be efficient, only processing each permutation a single time.
- Lastly, we want freedom in how we write tests and benchmarks for our solver, so the solver should be deterministic. Given the same board and dictionary, the solver should perform the same steps in the same order every time that it runs, modulo some variance in timings. It should at least examine the same permutations in the same order, even if it doesn't encounter interruptions at the same times.
Whew, sounds like a lot of design goals. And it is, but, with care and cunning, they are simultaneously achievable.
Exploring the state space
In order to continue an algorithm we need some kind of continuation: a snapshot of the complete machine state required to represent the activity of the algorithm at some interruptible checkpoint. Without looking at the algorithm yet, let's consider what we need in terms of machine state for a Quartiles solver.
The Quartiles solver is essentially a state space explorer. The state space comprises the set of 4-permutations of the 20-tile board: in other words, every possible permutation of 1 to 4 tiles, where each tile is a word fragment. So if we think of this state space like a result set from some hypothetical database table, what we need is a cursor capable of traversing the complete result set. But we can't rely on having complete rows furnished for us to iterate through linearly, because, well, we made up that result set.
But the idea of the cursor is incredibly useful. If the cursor doesn't have a stream of records to move back and forth over, then what does the cursor's motion look like? Let's play with the state space, imagining how we might traverse it manually.
We'll abstract away the word fragments for the moment and just consider that we have 20 of something, each of which is uniquely denoted by the labels 0 through 19 ([0,19]). We want to obtain the 1-, 2-, 3-, and 4-permutations of these 20 elements. Let's represent our cursor using tuple notation, e.g., (i0), (i0, i1), (i0, i1, i2), (i0, i1, i2, i3), etc., where each component in represents one of the 20 elements. We can technically pick any point in the state space as the origin for the cursor, but it's very useful to choose the 1-tuple containing the first element, so that makes (0) be the initial position of the cursor.
So how does the cursor move? Well, there are several axes of motion:
- If there are
<4elements, we can append a component:(i0) ⟹ (i0, i1) - If there are
>1elements, we can pop a component:(i0, i1) ⟹ (i0) - We can vary any component in place, but we only have to increment if we always start the component at
0:(i0) ⟹ (i0+ 1)
So we effectively have five dimensions of motion: append and pop operate on the length of the tuple (one dimension), while increment operates on the individual components (four dimensions). That sounds like a lot of dimensions, but the individual motions are very simple. Furthermore, we can add some simplifying constraints:
- We prioritize append over any other motion.
- We prioritize increment over pop.
- We ensure that pop is fused to a subsequent increment (to avoid repetition of cursor state).
- We only increment the rightmost component.
- We ensure that all components are disjoint, i.e.,
(i0, i1)is acceptable, but(i0, i0)is forbidden.
Recall that the uniqueness constraint stems directly from the rules of Quartiles: the same tile cannot be used twice in the same word.
Putting it all together, let's see how our cursor works. In the table below, we track the step number (of the full exploration), the motion to perform, and the cursor after the motion occurs. For simplicity, let's examine a 6-element space rather than a 20-element space. Here we go!
| Step# | Motion | Cursor |
|---|---|---|
| 0 | (origin) | (0) |
| 1 | append | (0, 1) |
| 2 | append | (0, 1, 2) |
| 3 | append | (0, 1, 2, 3) |
| 4 | increment | (0, 1, 2, 4) |
| 5 | increment | (0, 1, 2, 5) |
| 6 | pop + increment | (0, 1, 3) |
| 7 | append | (0, 1, 3, 2) |
| 8 | increment | (0, 1, 3, 4) |
| 9 | increment | (0, 1, 3, 5) |
| 10 | pop + increment | (0, 1, 4) |
| 11 | append | (0, 1, 4, 2) |
| 12 | increment | (0, 1, 4, 3) |
| 13 | increment | (0, 1, 4, 5) |
| 14 | pop + increment | (0, 1, 5) |
| 15 | append | (0, 1, 5, 2) |
| 16 | increment | (0, 1, 5, 3) |
| 17 | increment | (0, 1, 5, 4) |
| 18 | pop + increment | (0, 2) |
Obviously this goes on much longer, but this should be enough to see how the cursor traverses the state space. Consider what happens in step #6 if we just pop without the fused increment. The cursor would be (0, 1, 2): a regression to its state in step #2. Not only would this be redundant, but it would also be an infinite loop! So pop is out, but pop + increment is in: popcrement, if you will!
Looks good so far, but let's think about the cursor's endgame. What happens when popcrement would have to increment the rightmost component out of bounds? That's obviously forbidden, so we have to popcrement again. So popcrement actually needs to loop in order to ensure correctness, avoiding both redundant states and infinite loops. With that adjustment in mind, let's see the denouement:
| Motion | Cursor |
|---|---|
| append | (5, 4, 3, 0) |
| increment | (5, 4, 3, 1) |
| increment | (5, 4, 3, 2) |
| popcrement | () |
Boom, popcrement vacated the entire tuple! Based on our definitions above, this is an illegal state for the cursor — which is great! It means that we have a natural sentinel that denotes a tombstone for the algorithm. When we see the empty tuple, we're done!
We now have a cursor and rules that ensure exhaustive traversal of our state space, which means that we now have a continuation for our solver algorithm: the cursor itself is our continuation. The solver can always return the next cursor to process, and we can start and stop the solver wherever we please. Abstractly, we have ensured that the solver is interruptible, resumable, exhaustive, efficient, and deterministic. Hot dog, that's already 5 of our design goals!
FragmentPath
Good design is always the hard part, so now let's write some code. Connecting the cursor back to its purpose, which is tracking which tiles of the Quartiles board are selected and in what order, we settle on the name FragmentPath to denote this concept. Everything related to the FragmentPath can be found in src/solver.rs, so check it out if you want to see the inline comments or all of the code at once.
#[derive(Clone, Copy, Debug, Default, PartialEq, Eq)]
#[must_use]
pub struct FragmentPath([Option<usize>; 4]);We could use a Rust tuple for the payload of the FragmentPath, but it would make some of the implementation rather inconvenient. A fixed-sized array of 4 suits us better, where each element is an optional index into the Quartiles board that we want to solve. None represents an vacancy in the cursor, and all Nones must be clustered together on the right. We can thus represent (0, 1) straightforwardly as:
FragmentPath([Some(0), Some(1), None, None])Note the must_use attribute. Continuations are notoriously easy to ignore along some paths of control, so this reduces the risk of that. Now the compiler will ensure that we actually do something with a FragmentPath instead of just forgetting about it.
Iteration
At some point, we're going to need to traverse the board indices enclosed by a FragmentPath, so let's make it iterable:
pub fn iter(&self) -> impl Iterator<Item = Option<usize>> + '_
{
self.0.iter().copied()
}The board indices are simply usizes, so we answer an Iterator that will copy them. The anonymous lifetime ('_) indicates that the returned Iterator is borrowing from self, which is plain from the implementation. I'm excited that this particular piece of line noise is going away in Edition 2024.
Occupancy
We also need to know about vacancies in the FragmentPath, specifically whether it's empty (the sentinel condition we identified above) or full.
pub fn is_empty(&self) -> bool
{
self.0[0].is_none()
}
pub fn is_full(&self) -> bool
{
self.0[3].is_some()
}Since we carefully maintain the invariant that all Nones have to be clustered on the right, these are sufficient implementations.
Accessing
Directly indexing a FragmentPath is going to be useful for defining the motion operators, so we implement std::ops::Index and std::ops::IndexMut:
impl Index<usize> for FragmentPath
{
type Output = Option<usize>;
#[inline]
fn index(&self, index: usize) -> &Self::Output
{
&self.0[index]
}
}
impl IndexMut<usize> for FragmentPath
{
#[inline]
fn index_mut(&mut self, index: usize) -> &mut Self::Output
{
&mut self.0[index]
}
}Errors
Before looking at the cursor motions, let's see the possible failure modes:
#[derive(Clone, Copy, Debug, PartialEq, Eq)]
enum FragmentPathError
{
Overflow,
Underflow,
IndexOverflow,
CannotIncrementEmpty
}Overflow: Indicates that someFragmentPathwas full, so append failed.Underflow: Indicates that someFragmentPathwas empty, so pop failed.IndexOverflow: Indicates that the rightmost component of someFragmentPathwas already at the maximum unique board index, so increment failed.CannotIncrementEmpty: Indicates that someFragmentPathwas empty, so increment failed.
That's all that can go wrong, and we're going to use these error conditions in the solver algorithm itself, not just at the interface boundary. Finally, onward to cursor motion!
Append
We decided that append has the highest priority, so let's start there:
fn append(&self) -> Result<Self, FragmentPathError>
{
if self.is_full()
{
Err(FragmentPathError::Overflow)
}
else
{
let rightmost = self.0.iter()
.rposition(|&index| index.is_some())
.map(|i| i as i32)
.unwrap_or(-1);
let used = HashSet::<usize>::from_iter(
self.0.iter().flatten().copied()
);
let mut start_index = 0;
while used.contains(&start_index)
{
start_index += 1;
}
// Append the next fragment index.
let mut fragment = *self;
fragment[(rightmost + 1) as usize] = Some(start_index);
Ok(fragment)
}
}It's kind of a lot, so here's a flowchart to help us visualize it:
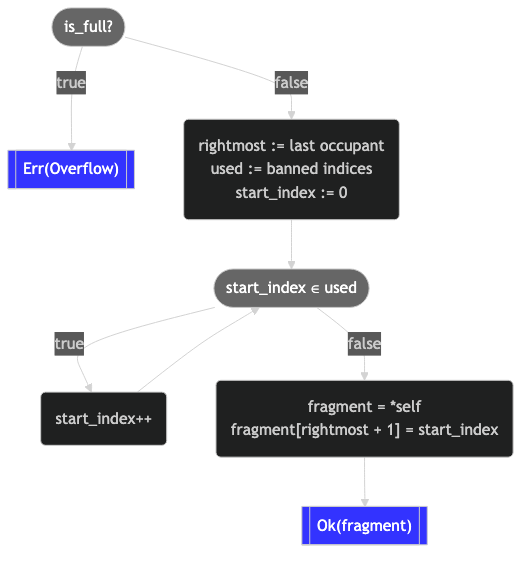
Now it's quite tractable:
- Signal overflow if full.
- Find the rightmost board index.
- Compute which board indices are present already.
- Find the smallest available board index.
- Append the smallest available board index onto a copy of the
FragmentPath. - Return the new
FragmentPath.
Increment
Increment is the most common motion for our cursor, and it is tragically also the most complex motion:
fn increment(&self) -> Result<Self, FragmentPathError>
{
let rightmost = self.0.iter()
.rposition(|&index| index.is_some())
.ok_or(FragmentPathError::CannotIncrementEmpty)?;
let used = HashSet::<usize>::from_iter(
self.0.iter().take(rightmost).flatten().copied()
);
let mut stop_index = 19;
while used.contains(&stop_index)
{
stop_index -= 1;
}
let mut fragment = *self;
loop
{
if fragment[rightmost] >= Some(stop_index)
{
return Err(FragmentPathError::IndexOverflow)
}
else
{
let next = fragment[rightmost].unwrap() + 1;
fragment[rightmost] = Some(next);
if !used.contains(&next)
{
return Ok(fragment)
}
}
}
}Counting never looked so hard, did it? Well, nothing makes counting look even harder than introducing a flowchart to explain it, but here it is anyway:
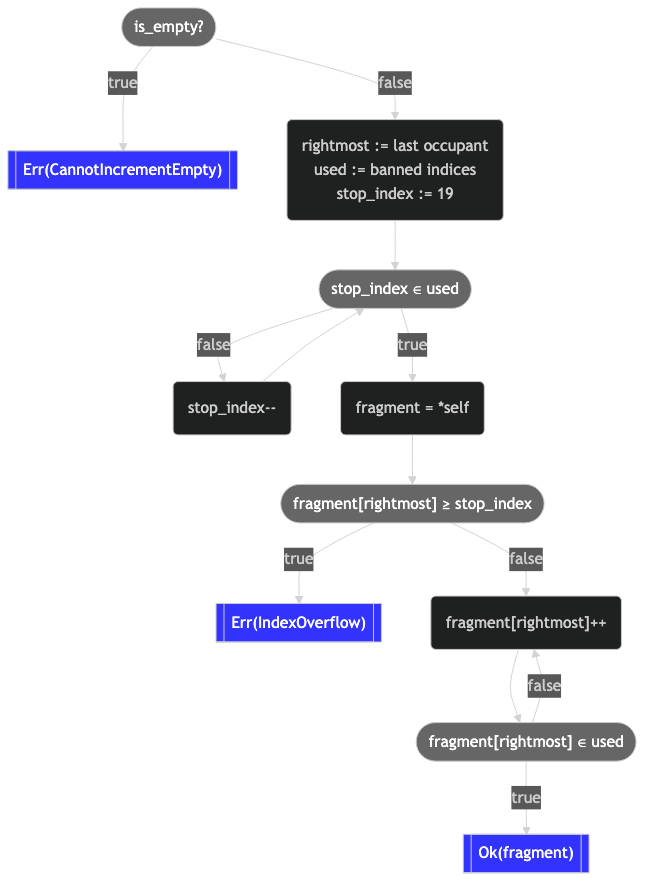
Oh, I'm supposed to make it easier, not harder. Right, right. Well, now we have the tools to take it apart:
- Find the rightmost board index.
- Signal cannot-increment if empty.
- Compute which board indices are present already.
- Find the stop index by scanning backward from
19(i.e., the highest valid board index) until we find an unused board index. This is the highest board index not already present in theFragmentPath. - Copy the
FragmentPathfor use as an accumulator. - Iteratively increment the rightmost component, until either:
- The stop index is met, in which case we must signal index overflow.
- An unused board index is discovered, in which case we can return the new
FragmentPath.
This is so tricky because we need to ensure that all of the board indices enclosed by a FragmentPath remain disjoint. This is an invariant that we carefully maintain at the boundaries of the API, and one that is central to ensuring an exhaustive, efficient traversal of the state space.
Pop…crement?
Pop turns out to be easy. So easy that I think it's safe to forego the flowchart. Voilà:
fn pop(&self) -> Result<Self, FragmentPathError>
{
if self.is_empty()
{
Err(FragmentPathError::Underflow)
}
else
{
let mut indices = self.0;
let rightmost = indices.iter()
.rposition(|&index| index.is_some())
.unwrap();
indices[rightmost] = None;
Ok(Self(indices))
}
}We underflow if the FragmentPath is empty, otherwise we chuck the rightmost component. But aren't we supposed to fuse pop and increment together for, er, popcrement? Sure, but having factored increment and pop makes it easy to define the fused operator:
fn pop_and_increment(&self) -> Result<Self, FragmentPathError>
{
let mut fragment = *self;
loop
{
fragment = fragment.pop()?;
match fragment.increment()
{
Ok(fragment) => return Ok(fragment),
Err(FragmentPathError::IndexOverflow) => continue,
Err(FragmentPathError::CannotIncrementEmpty) =>
return Err(FragmentPathError::CannotIncrementEmpty),
Err(_) => unreachable!()
}
}
}The only thing worth noting here is that IndexOverflow causes another component to be popped. I even had the good taste to name it pop_and_increment. There might still be some hope for me after all!
Mapping FragmentPaths to English words
A FragmentPath only contains board indices, but somewhere out there is a Quartiles board. We'd like to be able to test FragmentPath without building a solver, so we add the mapping logic as a method of FragmentPath:
fn word(&self, fragments: &[str8; 20]) -> str32
{
let mut word = str32::new();
for &index in self.0.iter().flatten()
{
word.push(&fragments[index]);
}
word
}str8 and str32 are string types from the popular fixedstr crate, which provides efficient, copyable, fixed-sized strings. Instances of str8 allocate exactly 8 bytes of character data on the stack, and it follows directly what str32 does. To date, Quartiles puzzles have only used fragments between 2 and 4 characters long, but we can't read Apple's mind, so we give ourselves some wiggle room. Since each of our fragments is at most 8 bytes, 32 bytes is enough to hold 4 of them.
Solver
All right, we know how to orient ourselves in the state space. FragmentPath in hand, we can now resume the solver. But first we need a solver to resume. Refer to src/solver.rs to see the inline comments. We start with the data structure itself:
#[derive(Clone, Debug)]
#[must_use]
pub struct Solver
{
dictionary: Rc<Dictionary>,
fragments: [str8; 20],
path: FragmentPath,
solution: Vec<FragmentPath>,
is_finished: bool
}dictionary: The English dictionary to use for solving the puzzle. The dictionary is big, and the application will end up holding onto it in multiple places, so we usestd::rc::Rcto ensure that we can avoid cloning it repeatedly.fragments: The Quartiles game board, as an array of fragments in row-major order. Note thatfragmentsmatches the eponymous parameter inFragmentPath::word.path: The next position in the state space to explore. When the solver resumes, it will resume here.solution: The accumulator for the solution. A solution comprises the5quartiles themselves plus any other words discovered during the traversal of the state space.is_finished: The flag that indicates whether the solver has completed. Whentrue,solutioncontains a complete solution to the Quartiles puzzle. If the user entered a board that wasn't canon, i.e., it didn't come from the official Quartiles game, then this might betrueandsolutionmight not contain5Quartiles. This would be the case if, for example, the user entered the same fragment multiple times, which seems to be forbidden for official boards.
Construction
To construct a Solver, we only need to supply the English dictionary and the game board:
pub fn new(dictionary: Rc<Dictionary>, fragments: [str8; 20]) -> Self
{
Self
{
dictionary,
fragments,
path: Default::default(),
solution: Vec::new(),
is_finished: false
}
}Completion
We expose is_finished through an eponymous method:
pub fn is_finished(&self) -> bool
{
self.is_finished
}As mentioned above, this really only tells us that the solver ran to completion, not whether it produced a valid solution. We'd like to be able to report to the user when we encounter an unsolvable puzzle, as this may indicate that the user entered the puzzle incorrectly or provided an insufficiently robust dictionary. So let's write a method to ascertain whether a solution is valid:
pub fn is_solved(&self) -> bool
{
if !self.is_finished
{
return false
}
let full_paths = self.solution.iter()
.filter(|p| p.is_full())
.collect::<Vec<_>>();
let unique = full_paths.iter()
.map(|p| p.word(&self.fragments).to_string())
.collect::<HashSet<_>>();
if unique.len() < 5
{
return false
}
let used_indices = full_paths.iter()
.flat_map(|p| p.0.iter().flatten())
.collect::<HashSet<_>>();
used_indices.len() == self.fragments.len()
}Breaking it down:
- We can't know whether the puzzle is solved unless the solver is finished.
- Check for
≥5words comprising4fragments. An official puzzle will hide exactly5such words. - To support unofficial puzzles, we further ensure that every fragment is actually used uniquely by one of the quartiles.
Obtaining the current word
For convenience, we provide an inline helper that the solver can use to obtain the English word corresponding to the current FragmentPath:
#[inline]
#[must_use]
fn current_word(&self) -> str32
{
self.path.word(&self.fragments)
}Accessing the solution
Naturally, the Solver wants to provide access to the solution to its client. We provide two flavors of this: one for obtaining the FragmentPaths and one for obtaining the English words. The application will use the former, whereas the test suite will use the latter.
#[inline]
#[must_use]
pub fn solution_paths(&self) -> Vec<FragmentPath>
{
self.solution.clone()
}
#[inline]
#[must_use]
pub fn solution(&self) -> Vec<str32>
{
self.solution.iter()
.map(|p| p.word(&self.fragments))
.collect()
}Solving Quartiles puzzles
Enough stalling! We've established the design goals and we've seen all of the building blocks. At last we are ready to write the mighty algorithm to solve Quartiles puzzles. Behold!
pub fn solve(mut self, duration: Duration) -> (Self, Option<FragmentPath>)
{
if self.is_finished
{
return (self, None)
}
let start_time = Instant::now();
let mut found_word = false;
loop
{
let start_path = self.path;
if self.dictionary.contains(self.current_word().as_str())
{
self.solution.push(self.path);
found_word = true;
}
if self.dictionary.contains_prefix(self.current_word().as_str())
{
match self.path.append()
{
Ok(path) =>
{
self.path = path;
}
Err(FragmentPathError::Overflow) => {}
Err(_) => unreachable!()
}
}
if self.path == start_path
{
match self.path.increment()
{
Ok(path) =>
{
self.path = path;
}
Err(FragmentPathError::IndexOverflow) =>
{
match self.path.pop_and_increment()
{
Ok(path) =>
{
self.path = path;
}
Err(FragmentPathError::CannotIncrementEmpty) =>
{
self.is_finished = true;
return (self, None)
}
Err(_) => unreachable!()
}
}
Err(_) => unreachable!()
}
}
if found_word
{
let word = *self.solution.last().unwrap();
return (self, Some(word))
}
let elapsed = Instant::now().duration_since(start_time);
if elapsed >= duration
{
return (self, None)
}
}
}The implementation isn't huge, but it is tricky, which is not surprising for a state space explorer that needs to satisfy all 8 of the design goals that we set for it.
We'll start with an examination of the interface. This is a method of Solver, and as it takes ownership of an instance it is therefore free to mutate that instance however it sees fit. The method accepts an instance of std::time::Duration, which is the soft limit on the desired running time; when the algorithm notices that this limitation has been exceeded, it returns. But the algorithm insists on processing at least 1 fragment path, no matter how small the requested running time, to ensure that it makes inexorable progress toward completion. The method returns a 2-tuple comprising the modified Solver and any word that may have been found during this invocation. The method always returns after either exceeding the supplied duration or finding a single valid word. The caller can use found words as evidence of progress and update the UI accordingly.
This is a wee bit more complex than counting, which as we saw earlier was hard enough, so it definitely deserves visualization:
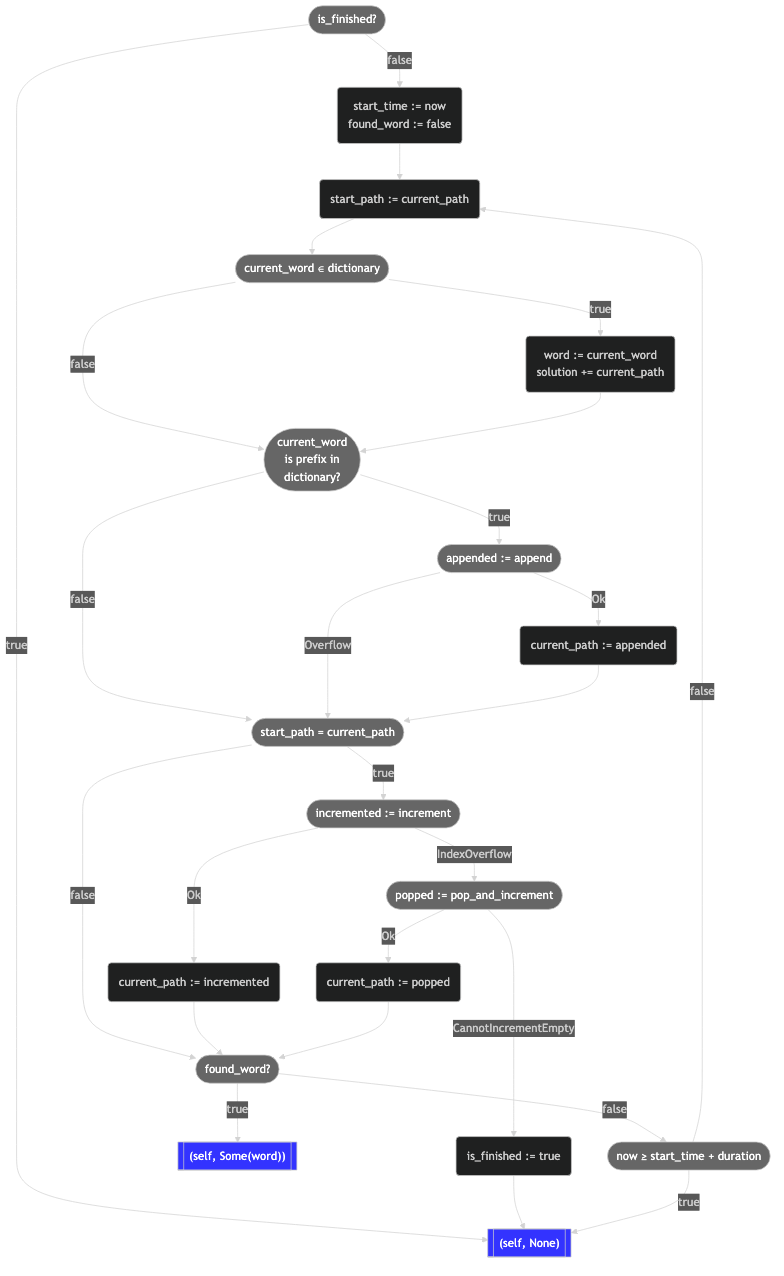
Still formidable, but the flowchart calls out the overall structure. Take a moment to study the graph, then we'll break down the logic.
First, we check to see if the solver has already run to completion. If it has, then we simply exit. Running solve on a solved Solver should be idempotent.
Now we recall that we want to make at least one pass through the algorithm to ensure incremental progress toward completion; this is required to ensure that the algorithm terminates for every possible input, which was one of our design goals. We note the current time (start), but we don't act on this information yet. We also create a flag (found_word) to track whether we've found a word during this invocation. We need to handle solution augmentation separately from state space exploration, and this flag will help with that.
At the loop head, we capture the current FragmentPath (start_path). We use the captured value below to determine which of the 5 axes of exploration we are going to traverse.
The next couple of blocks interrogate the dictionary. The first of these looks the current word up directly. If it's present, then we extend the solution to include the current word and set our found_word flag. Why don't we just return control to the caller here? Because we haven't actually advanced the cursor yet. If we returned now, then the next call would resume right here, "discovering" this same word again: an infinite loop.
The second dictionary interrogation is how we deliver the search space pruning that we promised back in Part I. We treat the current word as a prefix into the dictionary, asking the dictionary whether it knows any words that begin this way. If it doesn't, then we fall through to prune this part of the search space altogether. But if it does, then we use the append algorithm on the current FragmentPath. If append succeeds, then we advance the cursor accordingly. But if append overflows, we simply fall through this block to continue the algorithm.
If append succeeded, then start_path no longer agrees with the current path, which means that we have successfully updated the cursor; we can therefore skip over this huge block, because we must not advance the cursor multiple times without querying the dictionary in between. The algorithm would fail to be exhaustive, and potentially miss valid words.
If append failed, then the cursor hasn't moved yet, and we still need to ensure some kind of motion. So we try the increment algorithm on the current FragmentPath, advancing the cursor if that works; but if it overflows a component index, then we fall back by performing the popcrement algorithm.
Assuming that either increment or popcrement succeeded, we have advanced the cursor and reached the tail of the loop. If the found_word flag is set, then we return control to the caller, handing it the shiny new word that we discovered. If we didn't find a word yet, we use the captured start time to ascertain whether we've exceeded the supplied quantum of execution. If we're out of time, then we return control to the caller; otherwise, we make another circuit through the loop.
But if neither increment nor popcrement succeeded, then something more interesting than moving the cursor has occurred: we have finished the algorithm completely! We set is_finished and return control as our way of pronouncing "done" upon the algorithm and the solution. We hit all 8 of our solver design goals. Phew.
Testing
How do we know it all works? Testing, of course! Here's an abridged version of the main test:
#[test]
fn test_solver()
{
let dictionary = Rc::new(Dictionary::open("dict", "english").unwrap());
let (fragments, expected) = (
[
str8::from("azz"), str8::from("th"), str8::from("ss"),
str8::from("tru"), str8::from("ref"), str8::from("fu"),
str8::from("ra"), str8::from("nih"), str8::from("cro"),
str8::from("mat"), str8::from("wo"), str8::from("sh"),
str8::from("re"), str8::from("rds"), str8::from("tic"),
str8::from("il"), str8::from("lly"), str8::from("zz"),
str8::from("is"), str8::from("ment")
],
vec![
str32::from("cross"), str32::from("crosswords"),
str32::from("fully"), str32::from("fuss"), str32::from("fuzz"),
str32::from("is"), str32::from("mat"), str32::from("nihilistic"),
str32::from("rail"), str32::from("rally"), str32::from("rare"),
str32::from("rash"), str32::from("razz"), str32::from("razzmatazz"),
str32::from("recross"), str32::from("ref"), str32::from("refresh"),
str32::from("refreshment"), str32::from("rewords"),
str32::from("this"), str32::from("thrash"), str32::from("thresh"),
str32::from("tic"), str32::from("truss"), str32::from("truth"),
str32::from("truthfully"), str32::from("words"), str32::from("wore")
]
);
let solver = Solver::new(Rc::clone(&dictionary), fragments);
let solver = solver.solve_fully();
assert!(solver.is_finished());
assert!(solver.is_solved());
let mut solution = solver.solution();
solution.sort();
for word in solution.iter()
{
assert!(
dictionary.contains(word.as_str()),
"not in dictionary: {}",
word
);
}
let expected = HashSet::<str32>::from_iter(expected.iter().cloned());
let solution = HashSet::<str32>::from_iter(solution.iter().cloned());
assert!(expected.is_subset(&solution));
}fragments contains an official Quartiles puzzle. I played the game to reach 100 points, which unlocked the option to show all words found by the official dictionary. expected is that word list. Because the official dictionary is very likely different than the one that I bundled with the application, we test only whether the expected solution is a subset of the actual solution found by the solver.
I wrote quite a few tests other than this one, testing all of the modalities of the different cursor motions and so forth. Check them out in the project.
Performance
If you recall solver design goal #6 (the solver should be fast), we decided that the solver could take hundreds of milliseconds and still be plenty fast enough. Hundreds of milliseconds is perceptible to a user, but feels snappy for something like solving a whole puzzle.
So how did we do? Here's an excerpt of the report produced by cargo bench for my hardware:
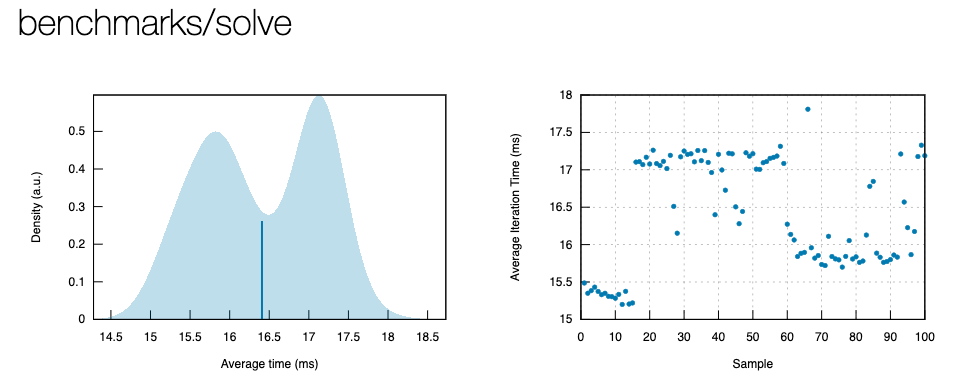
The mean time for running the Quartiles solver is 16.408 milliseconds. We beat our fuzzy target by an entire order of magnitude. Not too shabby; thank you, Rust!
Note that I elided the very simple benchmark for brevity, but check out the source if you're curious. Might as well make sure I'm not hoodwinking you about the terrific performance that we achieved, right?
And that's all for this installment. Next time we'll build the text-based user interface (TUI) and finally have the finished application! Stay tuned, because Part III is on its way! Thanks again for your time!
Written by
Todd Smith
Rust Solution Architect at Xebia Functional. Co-maintainer of the Avail programming language.
Contact