Blog
Observability and Security in Kubernetes


Learning the Lingo & Basics of IT Infrastructure Abstraction
How cattle, pets, containers, and tools can add value to your business. Every new technology brings a unique set of benefits worth protecting and that's where we, the security nerds, come in. We thrive on the constantly evolving nature of our work. You might think security consultants are constantly knee-deep in code, but that’s not always the case. So, what else do we do? Much of our time is spent educating customers about security, like the lingo and nuances of certain technologies.
As new technologies like public clouds, containers, and orchestration tools emerge, we remain committed to adapting and integrating them in a way that enhances operations for our client’s businesses. We firmly believe that security must add value because if it doesn’t, why bother?
This blog series will guide you through the labyrinth of abstractions and technologies while prioritizing security. First, let's get some lingo straight.
Why IT Infrastructure Abstraction?
It's becoming increasingly common for businesses to automate and abstract their IT infrastructure to achieve faster product delivery cycles. Doing so makes the process more efficient and predictable so new ideas can be quickly turned into a finished product.
A predictable infrastructure makes an application’s behavior more reliable. This result is not a given because bad code can still cause bugs and flaws, but blaming the platform team is no longer an option when the network layer is abstracted (please take this with a grain of salt coming from a former network security engineer). So, why else do companies abstract their IT infrastructure?
Cattle vs. Pets
One of the benefits of automating and abstracting IT infrastructure is the ability to treat it as "cattle" rather than as "pets." In the IT world, "pets" are indispensable components that require special care, such as a server that has been running for an extended period. While we may love our pets, they require individual attention and can be demanding. That dynamic is fine at home with your puppy, but a business does not want everything to stop when their “pet” has a problem.
That’s where the “cattle” come in. Treating IT infrastructure this way means that the components can be deleted and rebuilt without negatively impacting the overall infrastructure. Cattle don’t receive the same loving attention we give our pets. For IT infrastructure, that is a good thing!
This concept is further explained in the Distributed, Immutable, and Ephemeral (DIE) triage, which helps organizations design and build their IT infrastructure securely. The combination of a public cloud, containers, and orchestration technologies enables this dynamic. We'll delve deeper into the DIE triage in a separate blog post. Stay tuned.
Kubernetes is the holy grail, right?
Wrong! We know that may come as a shock. Let us explain. Kubernetes, a container orchestration tool, has been adopted across all public cloud platforms and can address many issues. However, it doesn’t solve everything.
While we can rely on Kubernetes to run IT infrastructure effectively, we know from experience that verifying applications are running as intended is essential. The real world often introduces unexpected factors that may compromise security, stability, and reliability.
Numerous organizations utilize monitoring tools to oversee their applications and ensure they function correctly. Any deviations from expected behavior may lead to availability or security issues known as drift detection. Unfortunately, Kubernetes doesn't provide default tooling to manage workload communications or gain insights into their performance. So, how can businesses ensure visibility and observability and protect their workloads while using Kubernetes?

Keep calm; we have containers!
The container lifecycle typically consists of four stages: coding, building, testing and deployment, and monitoring.
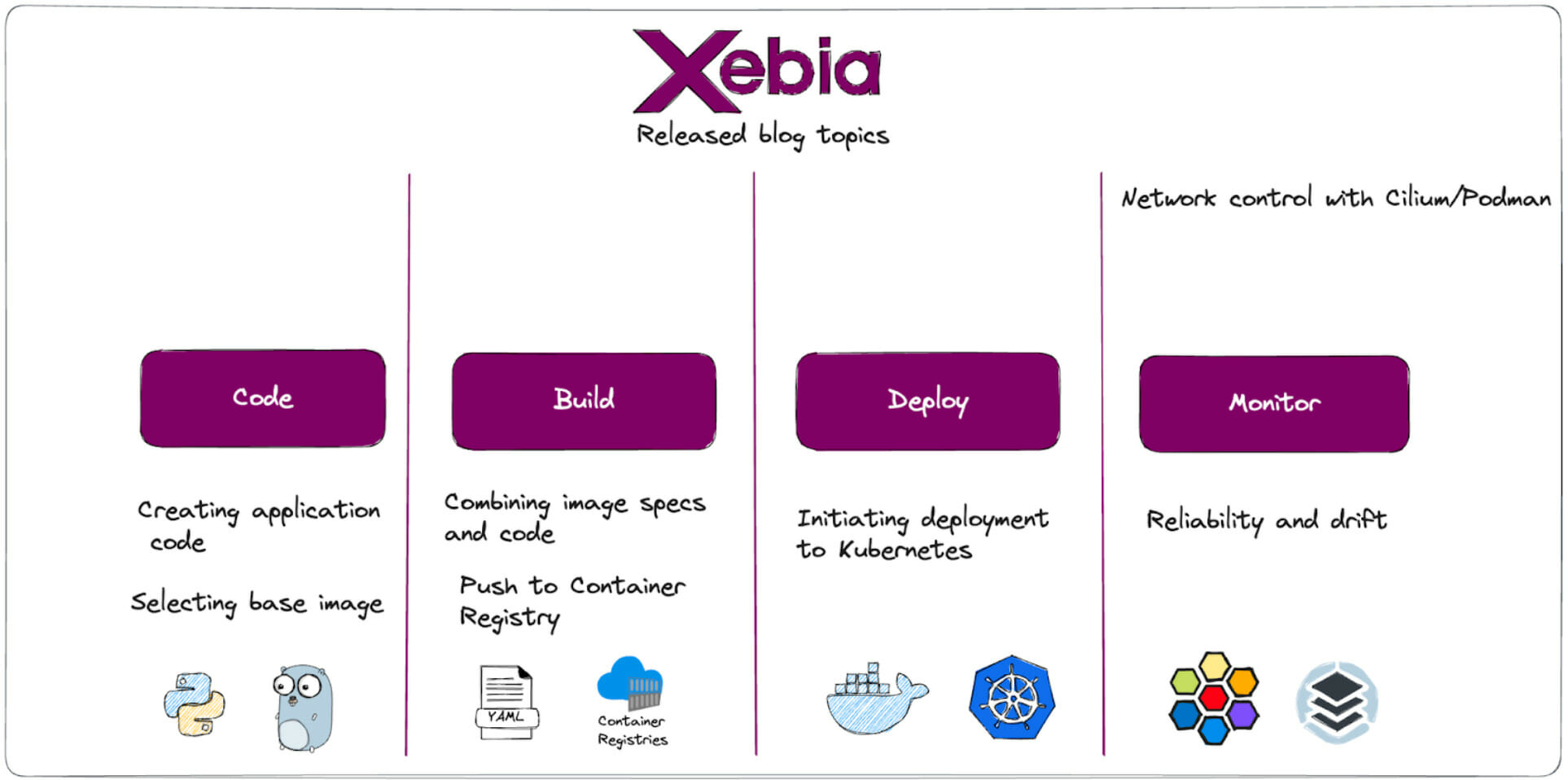
Code
- Developers write the application code and define infrastructure and environment as code.
- The code is packaged into a container image locally.
- If everything is acceptable, the changes are preferably pushed to the code repository.
Build
- Changes in the code repository trigger actions to build the container image.
- The container image is prepared for deployment, and dependencies, libraries, and runtime environments are configured.
Deployment
- The container image and defined infrastructure undergo testing to ensure functionality, performance, and security.
- Deployment automation tools are used to deploy the infrastructure and container images to the production environment.
Monitor
- Monitoring tools and techniques continuously monitor the infrastructure and application's performance, health, and resource utilization.
- Metrics like CPU usage, memory consumption, and network traffic are tracked.
- Logging and alerting mechanisms are integrated to detect and respond to any issues that arise.
Currently, various tools utilize an agent, or eBPF, in Kubernetes to capture traffic and logs. In another blog, we will focus on one tool per area to provide helpful insights and discuss its benefits, drawbacks, and approaches. As security nerds, we will refer to the National Institute of Standards and Technology (NIST) principles of Identity, Protect, Detect, Respond, and Recover to analyze each tool's effectiveness.
Next blog
In our upcoming blogs, we will also share our experiences with various tools (mostly moments when we banged our heads against the keyboard so you can avoid them), explore their architectural implications, provide demo examples, and offer business design recommendations. By the end of this blog series, we will provide an overview of the different tools, their pros and cons, and how they align with the NIST principles.
Written by
Nima Sead
At Xebia Cloud, Nima works as a DevSecOps engineer and ethical hacker. He aims to transform security engineering from a blocker to an enabler. He offers consultation services and coaches teams on various security topics, including secure coding, threat modeling, DevSecOps, Cloud native security, and AWS security engineering.
Our Ideas
Explore More Blogs




Contact