Blog
Making joins faster in DataFusion based on table statistics

DataFusion is a new data processing engine written in the Rust programming language. It provides a SQL and a DataFrame API to transform datasets from multiple sources and in multiple file formats, similar to Spark. DataFusion uses Apache Arrow as the underlying memory model, an efficient in-memory columnar format. This choice has significant performance benefits compared to a row-level representation such as used by Apache Spark.
As other databases & engines have shown, performing analytical (OLAP) queries on a columnar rather than row-by-row format can significantly speed up query execution, often by 20x or more! When processing is done row-by-row, a lot of complex operations are being executed in the inner loop when executing a query, such as interpreting an expression, computing the result and going to the next value in the row, dealing with completely different operations and data types. In contrast, when operating on a columnar level, the inner loop can be very simple, making it easy for the CPU to see what instructions will likely run next and utilize various forms of instruction level parallelism. Modern CPUs can run hundreds of instructions at the same time, even on one core. Code can be written to use available SIMD instructions, operating at multiple inputs at the same time to speed up things even more.
Image source: Arrow website
DataFusion is implemented in Rust, a language that is both fast and has control over memory while still providing memory safety, making it a very suitable language to write performant and correct code. Compared to Java running on the JVM, systems written in Rust tend to use much less memory. This saves costs and makes it possible to run bigger workloads on a single machine! An earlier benchmark of Ballista, a distributed engine in Rust utilizing DataFusion, shows that it can do with about 10x less memory on small to medium sized datasets. The JVM needs at least 1 GB for the heap. Spark also keeps intermediate results in memory between stages. DataFusion can stream more in batches of records, keeping memory usage low. DataFusion also benefits from Arrow format, which stores data types such as strings in an efficient way.
Numerous performance improvements have been added in the Rust version of Arrow and DataFusion between version 2 and 3 which is planned for release in January. For example, I have contributed a faster CSV parser and improved the performance of hashing. Kernels have been improved that provide implementations of often-used calculations, such as sum, filter, taking multiple elements of an array by index (also called indexing or gathering), and more. As DataFusion and Arrow are relatively new projects, there is still a lot of room for further improvement.
Recently, I added a new optimization pass to DataFusion to make hash joins faster. A hash join is a popular algorithm to implement joins in a fast way. The hash join algorithm is divided in a build stage and a probe stage. The build (or left side) stage creates a lookup table to map the keys in the join condition to a row index. The probe (right side) stage looks up the items in the lookup table by key and adds the matching rows to the end result if there is a match. It is faster to create a lookup table for the smallest table. This will avoid work for creating the lookup table for more rows, as well as not having the requirement to keep the bigger table in memory. For the optimization to be possible, we need to know the number of rows of both sources before executing the query. Luckily, for Parquet and in-memory tables this can be calculated based on the metadata. This information has been exposed recently in DataFusion.
Implementation / Results
The optimization is implemented as an optimization pass on the logical plan, an abstract representation of a query. When the left side of a join has more rows than the right side, the order and join type are swapped. If the left side already is smaller, the order is kept intact.
While testing the optimization something unexpected happened: When the optimization rule was used to change the order, the query performed worse than the original.
While studying the implementation of the hash join in DataFusion, it became clear that next to the left side of a join, the right part creates a lookup table as well!
I changed the implementation to only use the probe side to look up items on the left side and simplified the implementation, removing some other inefficiencies. Now queries having joins run much faster than before. This can be demonstrated on two TCP-H benchmark queries that include a join and are supported in DataFusion. Notably, TCP-H 5 is now 16x faster and TCP-H 12 more than 4 times faster.
I ran the TPC-H benchmarks using the command: cargo run --release --bin tpch -- benchmark --iterations 10 --path and averaged the results.
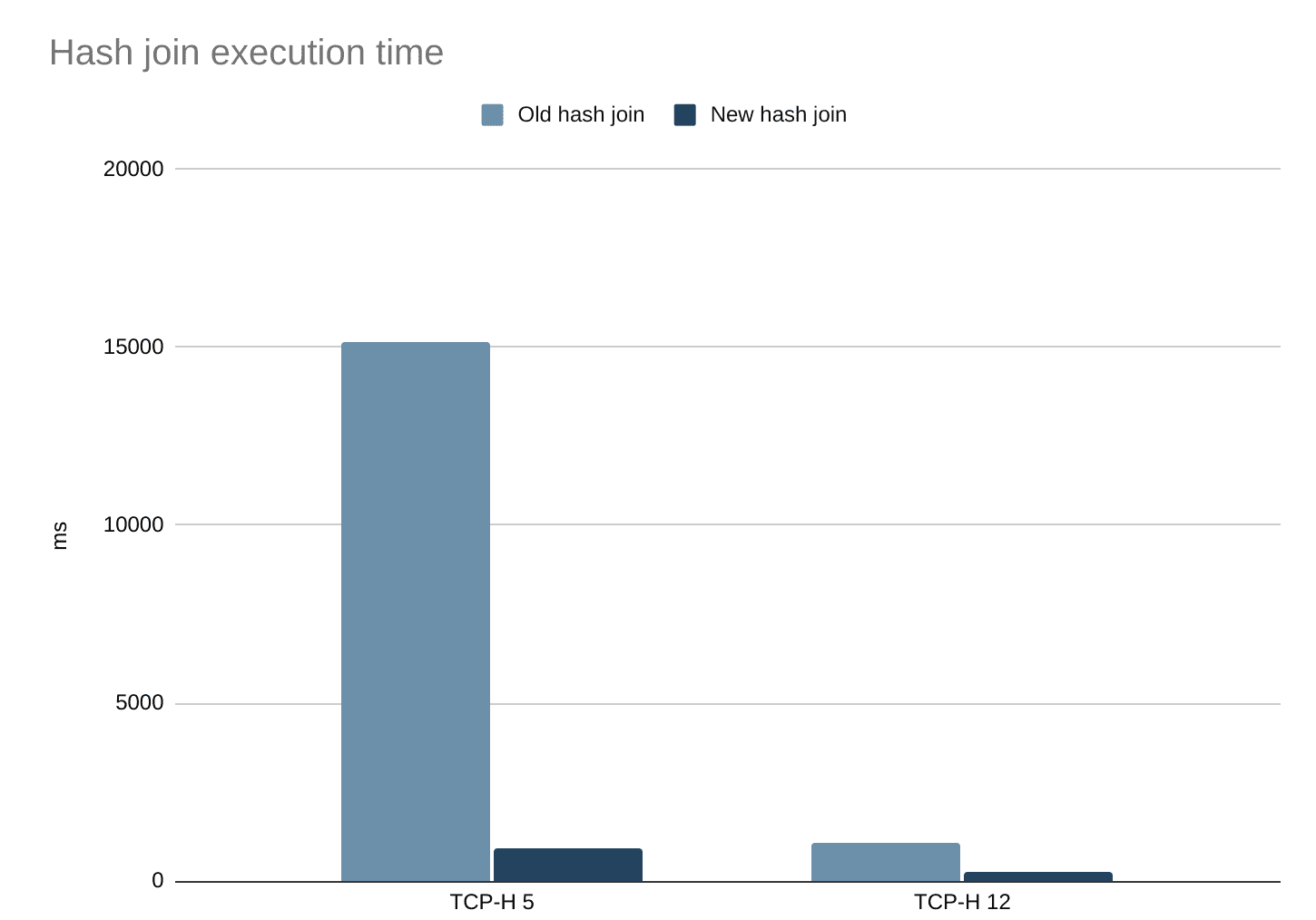
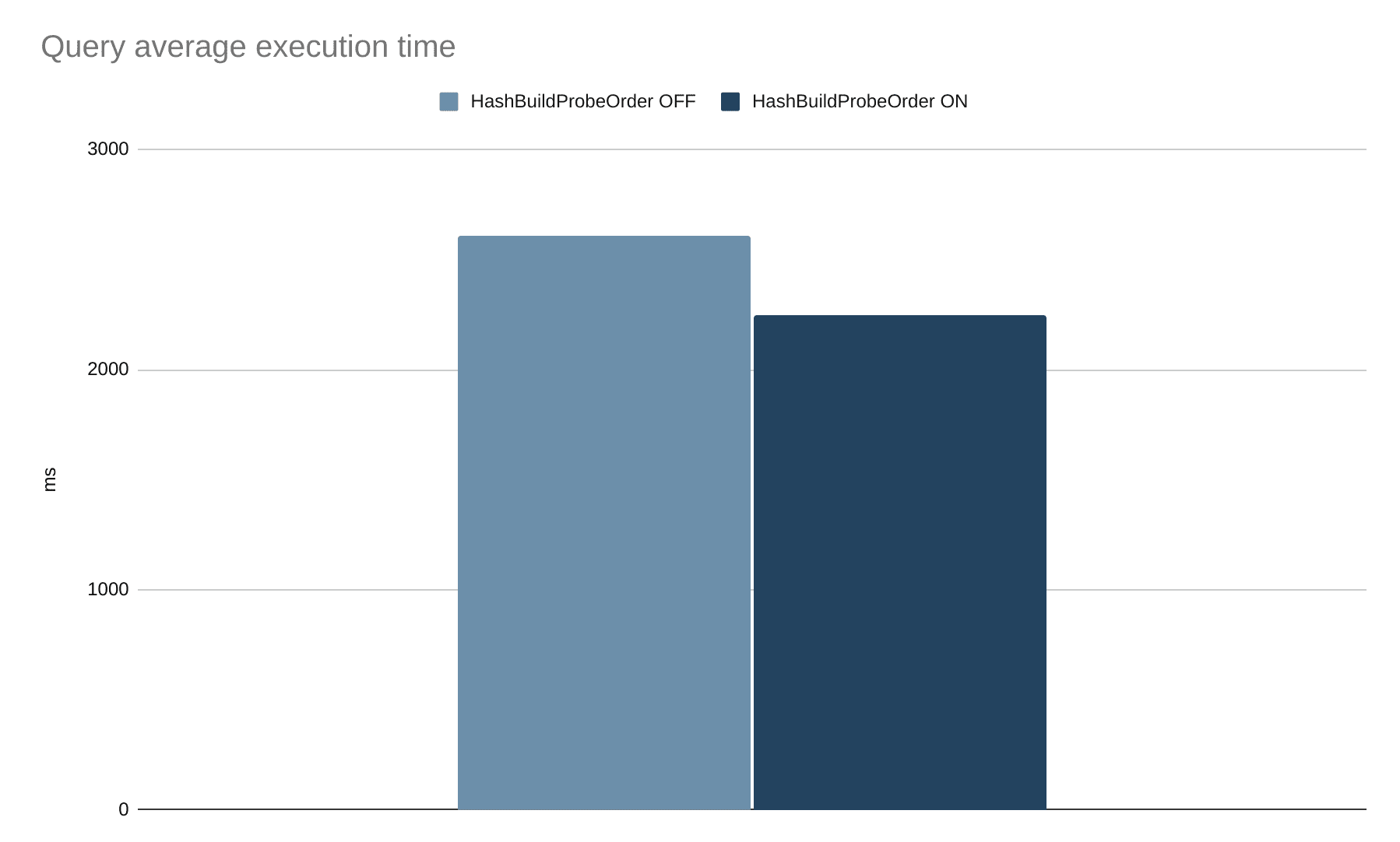
When the optimization rule is applied and combined with the improved hash join implementation, it makes the queries where the rule can be applied run faster, in this case reducing the total execution time by about 16%. For more imbalanced joins, the speedup can be greater. The data contains roughly 6 million line items (originally on the left side of the join) and 1.5 million orders (on the right side).
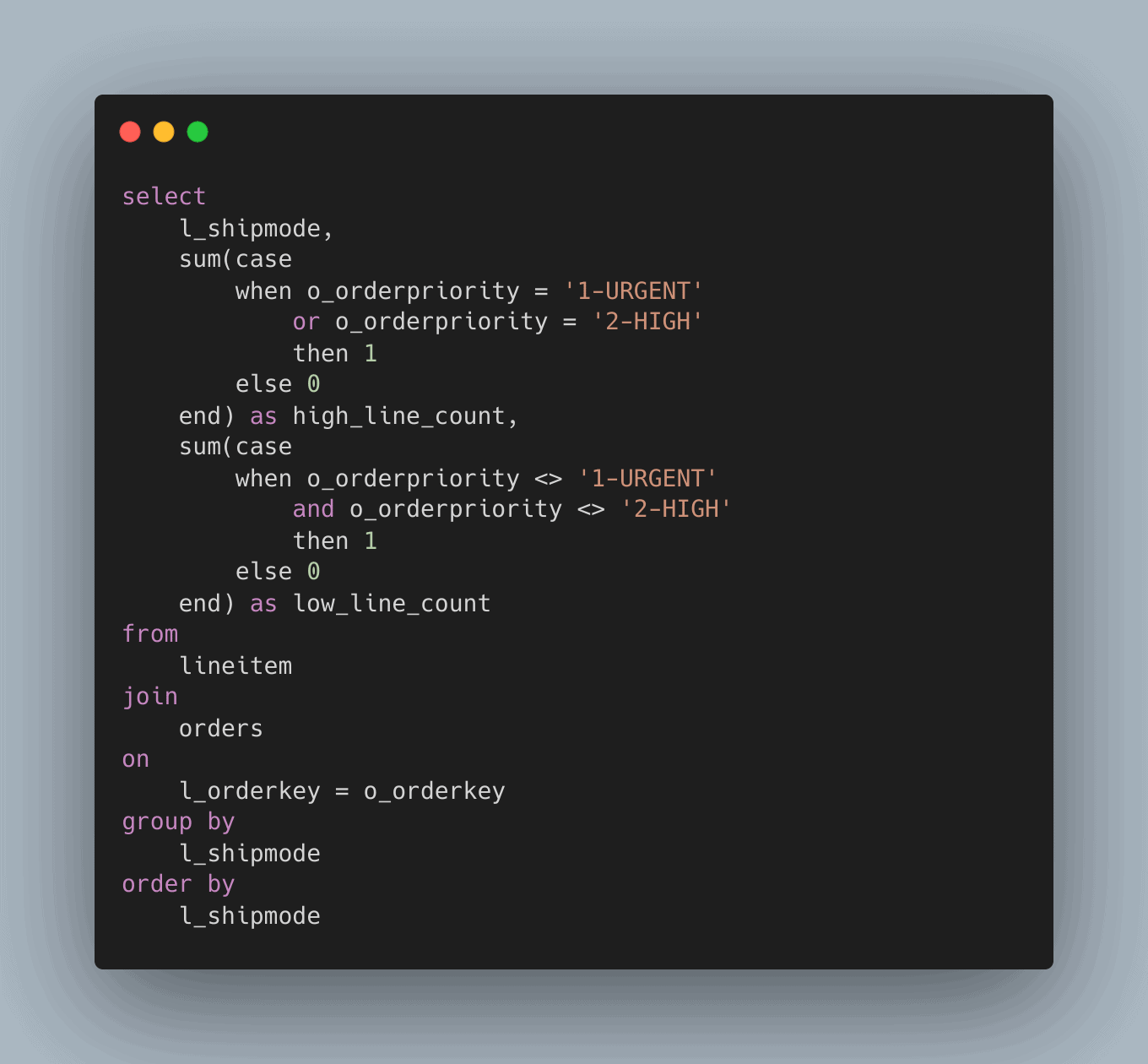
Conclusion
Statistics are a promising way to accelerate queries. In the future, a lot more optimizations could be added that benefit from table statistics. Many statistics however are known only after queries run, so in the future it would be interesting to add a form of Adaptive Query Execution as well. Hash joins could be further improved, for example by using vectorized hashing, which can also be used for hash aggregations which are used in GROUP BY queries.
I am personally very excited for what the future of Arrow and DataFusion brings and making Rust and Apache Arrow accelerate data analytics & data science.
Written by
Daniël Heres




Contact