Blog
Kedro: the ultimate wingman for your data pipeline across any cloud platform

TL;DR: Kedro is an open-source data pipeline framework that simplifies writing code that works on multiple cloud platforms. Its modular design centralizes configurations, making the code less error-prone and enabling it to run locally and on the cloud. Kedro generates simpler boilerplate code and has thorough documentation and guides. If you want to improve your data pipeline development skills and simplify adapting code to different cloud platforms, Kedro is a good choice.
Intro
We all know the struggle of making our pipelines work seamlessly across multiple cloud platforms and how time consuming it can be to learn specific code for every cloud stack. That's where Kedro takes place.
Starting from scratch or adjusting to another platform can be a real pain, or even figuring out how to reuse code for a new project. And don't even get us started on poor documentation or tutorials -- or the lack of those -- which can be pretty discouraging. Plus, given that cloud infrastructures have (almost) nothing to do with running any code locally, testing becomes a real challenge. We'll explore in this blog how to address the headaches of dealing with different cloud stacks. So, get ready to say goodbye to repetitive and tedious cloud-specific coding and hello to a more streamlined and efficient workflow!
The uncalled-for bottlenecks
Besides the steep learning curve towards mastering the intricacies of each cloud stack, there naturally comes some limited flexibility, especially because of different proprietary tooling and workflow constraints. That prompts cloud users for time-consuming adaptations that may feel frustrating.
One of the great things about Kedro is that it has become cloud agnostic in practice, thanks to the increasing participation and contributions of the community. Our colleagues from GetInData took care of all the interfacing to machine learning platforms on the cloud like Azure ML, Vertex AI and Sagemaker. This means that your code can be written once -- in Python, of course -- and run on basically any cloud platform, making your pipeline more portable and flexible.
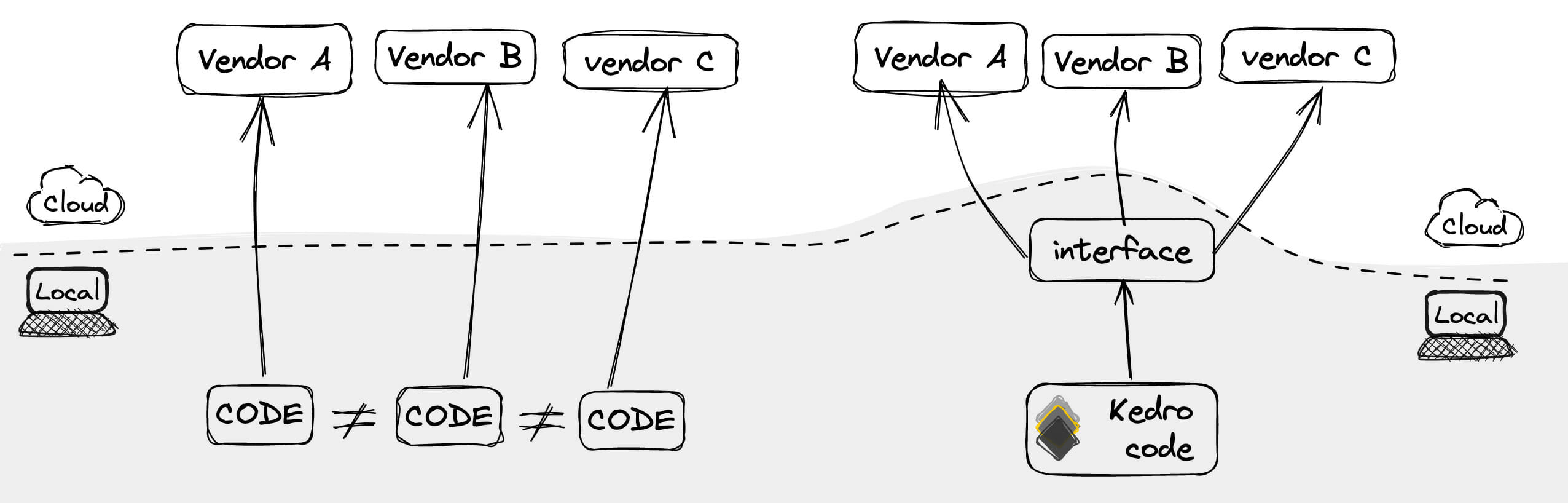
Be it strategical move, or just a matter of different perspective, cloud providers organize their infrastructures and services their own way. That said, similar resources sometimes can't be quite comparable for having additional or lacking features, which may influence (not to say compromise) design and entail vendor lock-in. Another issue lies on the inability of running pipeline nodes locally -- debugging and testing are paramount when it comes to coding, so why not, right? As a result, we must work around these limitations in the code and use cloud resources only to some extent. For example, we may choose to load large data volumes in memory from a data lake and handle the remaining tasks locally, or submit particular jobs to the cloud and patiently wait for scheduling delays while sipping on multiple cups of coffee. In other words, respectable, yet unnecessary efforts.
Why Kedro?
Kedro is an open-source data pipeline framework that brings the best practices of software engineering towards cleaner and more consistent code. As I mentioned before, the community is active and the documentation is very thorough, so every now and then we are going to be seeing some new must-have features that empowers the framework even more.
Not everything is unicorns and rainbows, I know. Kedro also has a steep learning curve, but the good part is, again, the community. The easy and detailed documentation makes it very convenient for new users to stay and even contribute in the future. Talking about convenience, it may be wise to invest some time learning a single framework that can run seamlessly across cloud platforms, rather than having the same pain everytime a new platform stands in your way.
Consistency and portability
One of the features that dazzles every beginner is how artifacts are used from a high level perspective. In other words, every dataset, trained model or any other artifact generated along the pipeline can be accessed (or created) seamlessly, by simply referring to its name. This gives more consistency to the code since paths, data types and particular configurations are centralized in a data catalog. Hence, the code becomes less error-prone -- Gone are the days we throw the classic it runs on my machine because of hardcoded stuff.
This is good news for Jupyter notebook fans. Kedro creates a particular kernel so the data catalog is already available to use without having to import or run a single line of code. So catalog is ready to load an artifact, list the available ones, and so on. By the way, I'll stop here. The data catalog itself is already a subject for a separate discussion that it's worth exploring with extra consideration.
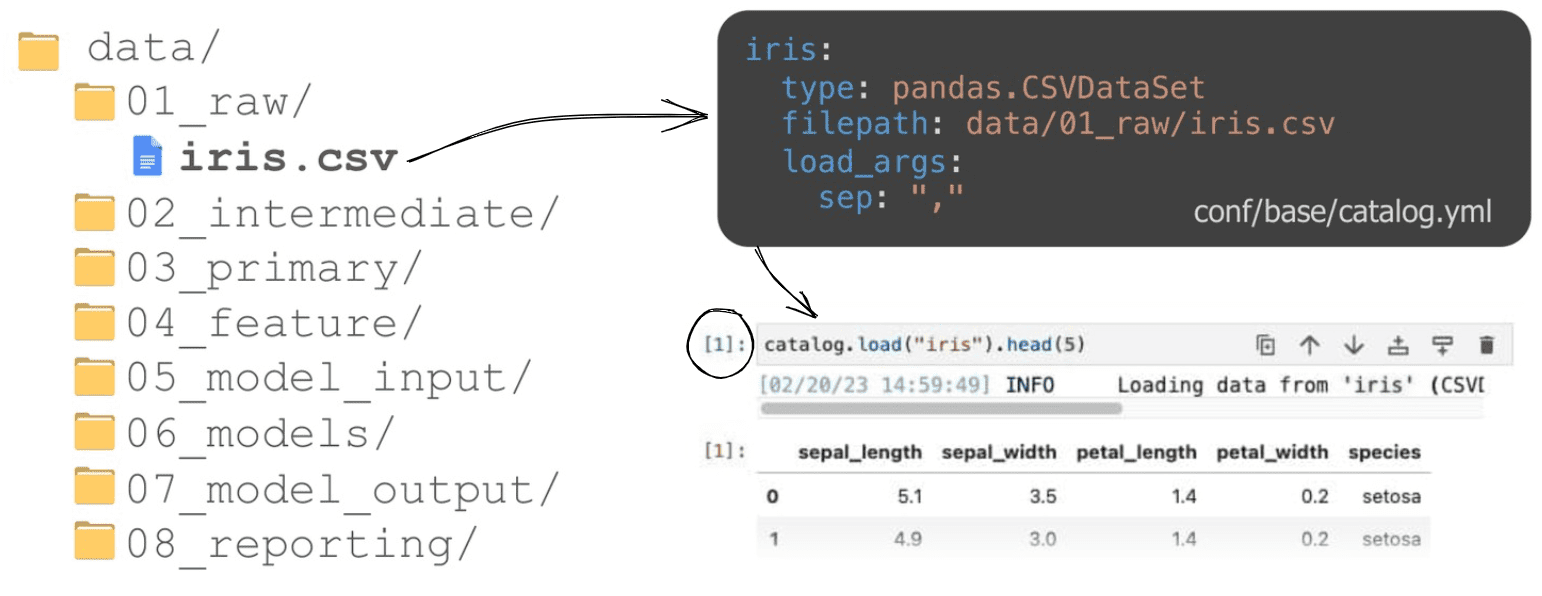
But that's not all -- Kedro also streamlines your pipeline development cycle by allowing the very same code to run both locally and on the cloud. This makes debugging, testing and IO inspection for specific pipeline nodes much easier, and you can even visualize the pipeline flow and code of each node side by side. Plus, if you want to run specific nodes locally, that can also be possible, going for the cloud only when needed, which can save you both time and money.
Boilerplate code
Using the SDK from the cloud platform itself -- say, Azure ML, Sagemaker, or Vertex AI -- introduces some complexities. Azure ML requires executing Python files and passing arguments via code, which can feel like an adapted CLI command in Python. Sagemaker is less technical, but configuration is still blended into the code. At a first glance it may seem confusing how to associate configs and IO with specific nodes. Vertex AI takes a different approach, treating the entire pipeline as a function and allowing the code flow to determine the order of node executions, but still requires explicit configuration in the code.
In contrast, given that configurations and artifact definitions are decoupled, organized in specific files, the remaining Kedro code is clean and minimal. What is left is essentially what needs to be done: define nodes and their respective code, the IO and the connection between them. Then, all it takes to run is a simple CLI command referring to which pipeline to run. In theory, it can't be more concise than that. Almost sounds like magic, which can be kind of annoying, but when you get used to where all the infos are, it is reasonable to have a framework handling technicalities on the lower level.
Modular design
Last but not least: modularity. This is another nice feature impacted by the data catalog, since the current state of a pipeline node can be exactly retrieved by its IO. By making core pieces of code independent, you can easily test -- with real, or even mock data -- a specific node, reuse and ensure cleaner code overall.
Kedro's modular design does not stop there, though. If you end up spotting bottlenecks when using it, those will probably arise from something not yet implemented, which can be solved as an additional contribution, rather than maintenance of what is already there. Say, for example, you need to load a dataset, but its unusual format is not within the extensive list the data catalog would read from. What you have to do is then implement a way to read it (wrapping AbstractDataSet), and you are good to go. Your brush stroke will make it a masterpiece.
Hello world Kedro
After reading this far, I'm confident that you're eager to dive into some hands-on practice, am I right? Fortunately, we've got you covered with this tutorial `
/Kedro-Azureml-Starter/blob/main/tutorial.md). The goal is to refactor a simple train.py` file with the iris dataset into Kedro pipelines and make it run on Azure.
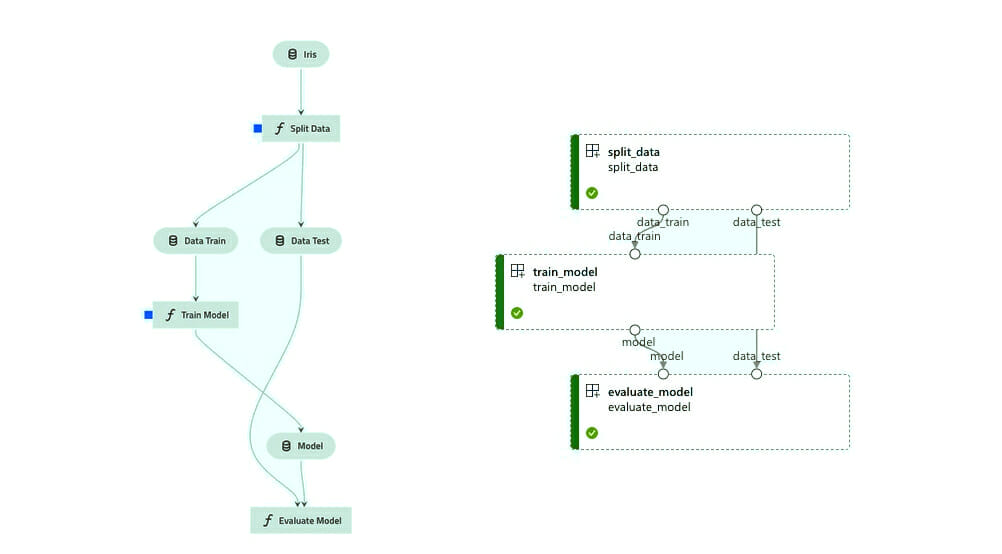
Even though it might seem a bit like over-engineering for this toy example, it is a nice approach to focus more on the infrastricture and intricacies of Kedro and the cloud, rather than on the complexity of the project itself.
In conclusion, Kedro is a powerful solution for developers looking to streamline their workflow and reduce the burden of writing cloud-specific code. With its cloud-agnostic capabilities, data catalog, modularity, documentation and solid community support, Kedro simplifies the development of data pipelines and makes code more portable and flexible across different cloud platforms. Its design enforces cleaner, more consistent, and less error-prone code, allowing users to run particular pieces of code locally, on the cloud, or both, just as needed. If you're looking to improve your skills on data pipeline development and simplify the process of adapting code to different cloud platforms, Kedro is definitely a nice way to go.
Feeling excited? Don’t miss your chance to learn how to run data pipelines with Kedro at our engaging Kedro Code Breakfast on May 23rd in Amsterdam. [Register now] for this free event before seats run out!
Written by
Caio Benatti Moretti
Our Ideas
Explore More Blogs




Contact