
Recently, GoDataDriven installed a Cloudera cluster on Microsoft Azure. In this article we provide some information about the use case, the implemented design and some basic information about Microsoft Azure. We discuss how you can install Cloudera on Azure and share best-practices about installing a distributed system on Azure.
Introduction
Processing large amounts of unstructured data requires serious computing power and also maintenance effort. As load on computing power typically fluctuates due to time and seasonal influences and/or processes running on certain times, a cloud solution like Microsoft Azure is a good option to be able to scale up easily and pay only for what is actually used.
The use-case: Data Science infrastructure for large European airport
In order to explore and analyze data, one of the largest European airports approached GoDataDriven to set-up a pre-production environment with adequate security measures, robust enough for production load. Cloudera was selected as Hadoop distribution to be installed on MS Azure.
The first use-case to motivate the installation of Cloudera was to be able to leverage the computing mechanisms offered to do predictive maintenance of the airports' assets. By collecting data from all the assets in the Cloudera cluster, the airport was able to develop predictive models for the maintenance based on power usage, visitor flow and sensor data.
Requirements & design
Requirements
The general requirements for our use case were:
- Install Cloudera Enterprise Hadoop on Azure
- Make sure single sign-on is possible
- To reduce costs, start by using only 5 worker nodes, with three 1 TB data disks each
And the following technical requirements were added:
- Deploy 3 master nodes, so if the cluster expands the load can be handled
- Make sure that HDFS and YARN are configured with high availability enabled
- Connect the Cloudera cluster to the Active Directory to be able to authenticate users who are allowed to use the cluster
- Install and configure Sentry to be able to assure access control.
- Set up one gateway machine from which the users would be able to work. On this gateway we would also have RStudio and IPython installed so these can be used for analysis
Design
Our goal was to build a production ready Hadoop cluster, including provisioning machines. Of course there were also some security related requirements which we had to take into account. For example: Users and administrator had to use a VPN tunnel to be able to access the Azure environment. Single sign-on had to be enable on all machines and Sentry had to be configured.
So we ended up creating a design which is presented in the picture below:
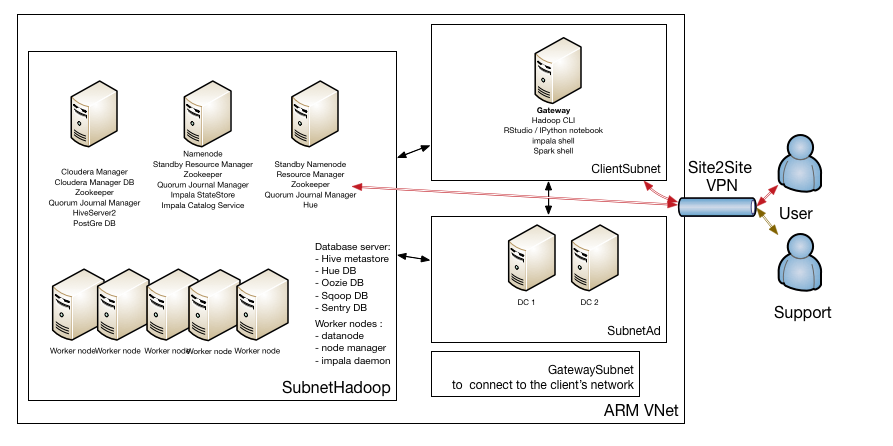
The GatewaySubnet is needed to be able to set up the Site2Site VPN between the client’s network and the Azure network where the Hadoop cluster resides.
For user management we decided to set up two Active Directory servers, which are also Domain Name Server. These are placed in their own subnet.
Because of the high traffic between all nodes in the cluster, the Hadoop machines are in their own subnet. You might wonder why, but let us explain shortly how HDFS works: When you write a file into HDFS, this file is split into blocks (block size is usually 128 MB) and these blocks are placed on the Datanodes. Each block has a replication factor of 3. Only the master node (Namenode) knows which block belongs to which file. The Namenode does not store blocks, but it does maintain the active replication factor. If a client wants to read a file from HDFS, it will first contact the Namenode, get the location of the blocks and then read the blocks from the Datanodes. The Datanodes send heartbeats to the Namenode and the when the active Namenode notices that a block hasn’t got the requested replication factor, it instructs another Datanode to copy that given block.
So now you can see that there is a lot of traffic between the Namenode - Datanode and also between Datanode – Datanode. And here we only mentioned the communication between one component, HDFS....
We chose to put the Hadoop cluster in its own subnet because like this we can also restrict better who can access this subnet.
We also have a ClientSubnet for the machines which can access the cluster. Users can connect to the machines in this subnet, do their analysis, but are not able to SSH to the machines in the Hadoop subnet.
By configuring single sign-on using the Active Directory on the Linux level and configuring Kerberos using Active Directory for the Hadoop services, users can use a single password everywhere.
To be able to provide a working environment to the customer, we had to learn a couple of things about Microsoft Azure, the preferred cloud provider of the customer.
Microsoft Azure basics to start a cluster
Microsoft Azure is a cloud service for both infrastructure-as-a-service (IaaS) and platform-as-a-service (PaaS), with data centers spanning the globe. We only needed the IaaS part to be able to set up the network and start machines, so that's what we'll explain further.
For Cloudera Enterprise deployments on Azure, the following service offerings are relevant:
- Azure Virtual Network (VNet), a logical network overlay that can include services and VMs and can be connected to your on-premise network through a VPN.
- Azure Virtual Machines enable end users to rent virtual machines of different configurations on demand and pay for the amount of time they use them. Images are used in Azure to provide a new virtual machine with an operating system. Two types of images can be used in Azure: VM image and OS image. See About images for virtual machines A VM image includes an operating system and all disks attached to a virtual machine when the image is created. This is the newer type of image. Before VM images were introduced, an image in Azure could have only a generalized operating system and no additional disks. A VM image that contains only a generalized operating system is basically the same as the original type of image, the OS image. From one VM image you can provision multiple VMs. These virtual machines will run on the Hypervisor. The provisioning can be done or using the Azure portal or with PowerShell or Azure command line interface.
- Azure Storage provides the persistence layer for data in Microsoft Azure. Up to 100 unique storage accounts can be created per subscription. Cloudera recommends Premium Storage, which stores data on the latest technology Solid State Drives (SSDs) whereas Standard Storage stores data on Hard Disk Drives (HDDs). A premium storage account currently supports Azure virtual machine disks only. Premium Storage delivers high-performance, low-latency disk support for I/O intensive workloads running on Azure Virtual Machines. You can attach several Premium Storage disks to a virtual machine (VM). With Premium Storage, your applications can have up to 64 TB of storage per VM and achieve 80,000 IOPS (input/output operations per second) per VM and 2000 MB per second disk throughput per VM with extremely low latencies for read operations. Cloudera recommends one storage account per node to be able to leverage higher IOPS. To see the impact of using SSD vs. HDD drives for Hadoop read The truth about MapReduce performance on SSD blog.
- Availability Sets provide redundancy to your application, ensuring that during either a planned or unplanned maintenance event, at least one virtual machine will be available and meet the 99.95% Azure SLA.
- Network Security Groups provide segmentation within a Virtual Network (VNet) as well as full control over traffic that ingresses or egresses a virtual machine in a VNet. It also helps achieve scenarios such as DMZs (demilitarized zones) to allow users to tightly secure backend services such as databases and application servers.
Deployment modes
At the moment Azure has two deployment modes available:
- ASM (Azure Service Management)
- ARM (Azure Resource Manager)
The ASM API is the “old” or “classic” API , and correlates to the web portal. Azure Service Management is an XML-driven REST API, which adds some overhead to API calls, compared to JSON.
The Azure Resource Manager (ARM) API is a JSON-driven REST API to interact with Azure cloud resources. Microsoft recommends deploying in ARM mode.
One of the benefits of using the ARM API is that you can declare cloud resources as part of what’s called an “ARM JSON template.” An ARM JSON template is a specially-crafted JSON file that contains cloud resource definitions. Once the resources have been declared in the JSON template, the template file is deployed into a container called a Resource Group. An ARM Resource Group is a logical set of correlated cloud resources that roughly share a life span. Using the ARM mode you are able to deploy resources in parallel, which was a limitation in ASM.
The new Azure Ibiza Preview Portal is used to provision Azure cloud resources with ARM. If you provision cloud resources using the “old” Azure Portal, they are provisioned through the ASM API. You are not limited to the portal to deploy your templates. You can use the PowerShell or the Azure command-line interface to manage all Azure resources and deploy complete templates. The Azure CLI is based on NodeJs and thereby available on all environments. Both ARM and ASM are modes which can be configured using the CLI. You can check which mode you are working in using the
azure config
command and change the mode using the
azure config mode <arm/asm> command.
When deciding which deployment model to use, you have to watch out, because resources deployed in the ASM mode cannot be seen by the resources deployed in the ARM mode by default. If you want to achieve this, you would need to create a VPN tunnel between the two VNets.
To understand the differences between ASM and ARM better, read the Azure Compute, Network, and Storage Providers under the Azure Resource Manager article.
How to install Cloudera on Azure?
There are multiple way in which you can install Cloudera on Azure. After some considerations we ended up with the following 2 scenarios:
-
Install everything from scratch:
- Provision machines and network using Azure CLI
- Use a provisioning tool (we prefer Ansible) to do the Linux configuration
- Install Cloudera Manager
- Install CDH (Cloudera Distribution for Apache Hadoop) using Cloudera Manager
-
Cloudera provides an ARM template which installs a Hadoop cluster, including OS and network tuning and Hadoop configuration tuning. The template can be found on GitHub. There is also an Azure VM image built and maintained by Cloudera which is used during deployment. This image is available on the Azure Marketplace. Out-of-the-box features of the template:
- Create a Resource Group for all the components
- Create VNet and subnets
- Create availability sets. Place masters and workers in different availability sets
- Create security groups
- Create Masternode and Workernode instances using the Cloudera VM Image (CentOS image built and maintained by Cloudera). The template automatically uses Azure DS14 machines, which are the only machine types recommended and supported by Cloudera for Hadoop installations.
- For each host a Premium Storage account is created
- Add disks to the machines, format and mount the disks (10 data disks of 1 TB per node)
- Set up forward/reverse lookup between hosts using /etc/hosts file
- Tune Linux OS and network configurations like disable SELinux, disable IPtables, TCP tuning parameters, disable huge pages
- Set up time synchronization to an external server (NTPD)
- Set up Cloudera Manager and the database used by the Cloudera Manager
- Set up Hadoop services using the Cloudera Python API
The template also has a disadvantage: it is meant to start up a cluster, but you cannot create extra data nodes and add them to the cluster. The template does not provision a gateway machine for you.
After analyzing the gaps between the template provided by Cloudera and the client requirements, we decided to chose a golden middle-way:
- Use the Cloudera-Azure template to provision the network, set up the machines, configure the OS and install Cloudera Manager
- Use Cloudera Manager (so not the Cloudera-Azure template) to install the CDH cluster.
In out next blog we will discuss what were these gaps in more detail.
Best practices for a manual implementation
We also identified a couple of best practices which we would need to keep in mind if we wouldn’t use the template:
- When deploying a Linux image on Azure there is a temporary drive added. When using the DS14 machines the attached disk on /mnt/resource is SSD and actually pretty big (something like 60 GB). This temporary storage must not be used to store data that you are not willing to lose. The temporary storage is present on the physical machine that is hosting your VM. Your VM can move to a different host at any point in time due to various reasons (hardware failure etc.). When this happens your VM will be recreated on the new host using the OS disk from your storage account. Any data saved on the previous temporary drive will not be migrated and you will be assigned a temporary drive on the new host. Understanding the temporary drive on Windows Azure Virtual Machines
- The OS root partition (where also the /var/log directory resides) is fairly small (10GB). This is perfect for an OS disk, but Cloudera also puts the parcels (an alternate form of distribution for Cloudera Hadoop) on /opt/cloudera and the logs into /var/logs. These take up quite a lot of space so a 10 GB disk is not enough. That’s why you should move the parcels and the log file to a different disk. (Reminder: normally the template takes care of this for you.) If you install Cloudera without moving these files to a different disk, you will see warning messages in Cloudera Manager that there not enough free disk space available.
- In a distributed system, thus also for a Hadoop cluster (especially if Kerberos is used), time synchronization between hosts is essential. Microsoft Azure provides time synchronization, but the VMs read the (emulated) hardware clock from the underlying Hyper-V platform only upon boot. From that point on the clock is maintained by the service using a timer interrupt. This is not a perfect time source, of course, and therefore you have to use NTP software to keep it accurate.
- If running Linux on Azure install the Linux Integration Services (LIS) - a set of drivers that enable synthetic device support in supported Linux virtual machines under Hyper-V.
Further information
Earlier, on November 3rd 2015, GoDataDriven already presented a webinar about running Cloudera on MS Azure, which has been recorded and is available for viewing after registration.
To be continued...
In the next post we will elaborate further on the gaps we saw between our client requirements and the Cloudera template and we will show how we modified the Cloudera template to fulfill our requirements.




Contact