
The amount of information around us is constantly increasing, with over 3 million blogs published on the web every day (Internetlivestats, 2020). Indexing this information made Google great — their search engine processes a whopping 3.5 billion + searches a day (Internetlivestats, 2020).
Meanwhile, Covid-19 has the world in its grip. As scientists measure and observe progress of the disease, we all learn a bit more as they publish their findings in papers, articles and blogs everyday. I found myself curious to learn what all is out there. In my explorations I stumbled across this dataset with 550K articles about Covid-19. It sealed the deal: I was going to build myself a search engine for articles related to Covid-19. I created my own tool for understanding the pandemic better, and in this blog I'll share how I did it. For those of you who can't wait, click here to check it out.
Anatomy of an Covid-19 Search Engine
In the end my Covid-19 search engine looked like this:

To build this solution I used of the following technology:
- Search engine: Azure Cognitive Search
- Data storage: Azure Blob Storage
- User interface: Docker and Streamlit
- App Deployment: Azure Container Registry and Azure App Services
First, I'll outline my overall process. I started out by storing the articles in the blob storage, using the cognitive search API to index all of them. Then I created a simple user interface with a search bar for entering queries. The search bar sends the search query to the cognitive search API, which returns the most relevant results. To deploy the whole application, I embedded it in a Docker image which I pushed to the Azure Container Registry. Azure App Services then deploys this image as a website, which can be found here. A schematic visualization of the whole solution is shown below.

Let's go through each step in more detail, so you can recreate the solution yourself.
Step 1: Get the code
Before we start, clone the code repository to a folder on your computer. With minor changes you can tweak it to create your own search engine with different files. Use your terminal to navigate to the build-your-own-search-engine folder, here you can find all the code.
cd build-your-own-search-engine Step 2: Get the data
Let’s look at the dataset first, to get an idea what we are dealing with. The dataset contains over 1.5 million Covid-19-related articles, gathered from Nov 2019 to July 2020 from over 400 global sources. You can download the full set here (please note it is >7 GB).
In the interface I want to be able to show the article date, source, title, and content. Therefore I'm interested in the following variables in the dataset:
- Identifier: to uniquely identify the documents
- Timestamp: to sort the articles on recency
- Source: to check where the data comes from
- Article title: to index the article on & show as a search result
- Article body: to index the article on & show as a search result
For simplicity, I recommend using the prepared subset of articles which is stored in the repository (data/aylien_covid_news_data_sample.jsonl). However, if you want to use the full, follow the next steps.
After downloading the dataset, unpack it and put it in the data folder in the cloned directory. Open your terminal, go to the data folder and run the following code.
python preprocessing_sample.pyThis will create a file called "aylien_covid_news_data_sample.jsonl". In this file there are 50 sample records. If you want all the data, run the preprocessing_all.py script instead. This will create a set of files containing 100K documents each. Note that downloading, preprocessing, uploading, and indexing of all the records will take a significant amount of time, which is why I recommend to using the prepared subset instead.
Step 3: Store the data in the cloud
We need to store the data in the Azure Blob Storage. If you don't have an Azure account, subscribe for free. First create a storage account and then create a container. Make sure the name of the container is "covid-news" or alter the used container name in the setup_acs.py script later. Finally, upload the created "aylien_covid_news_data_sample.jsonl" file into the container you have created.
Look up the storage account connection string. You can find your connection string on the Azure portal here:
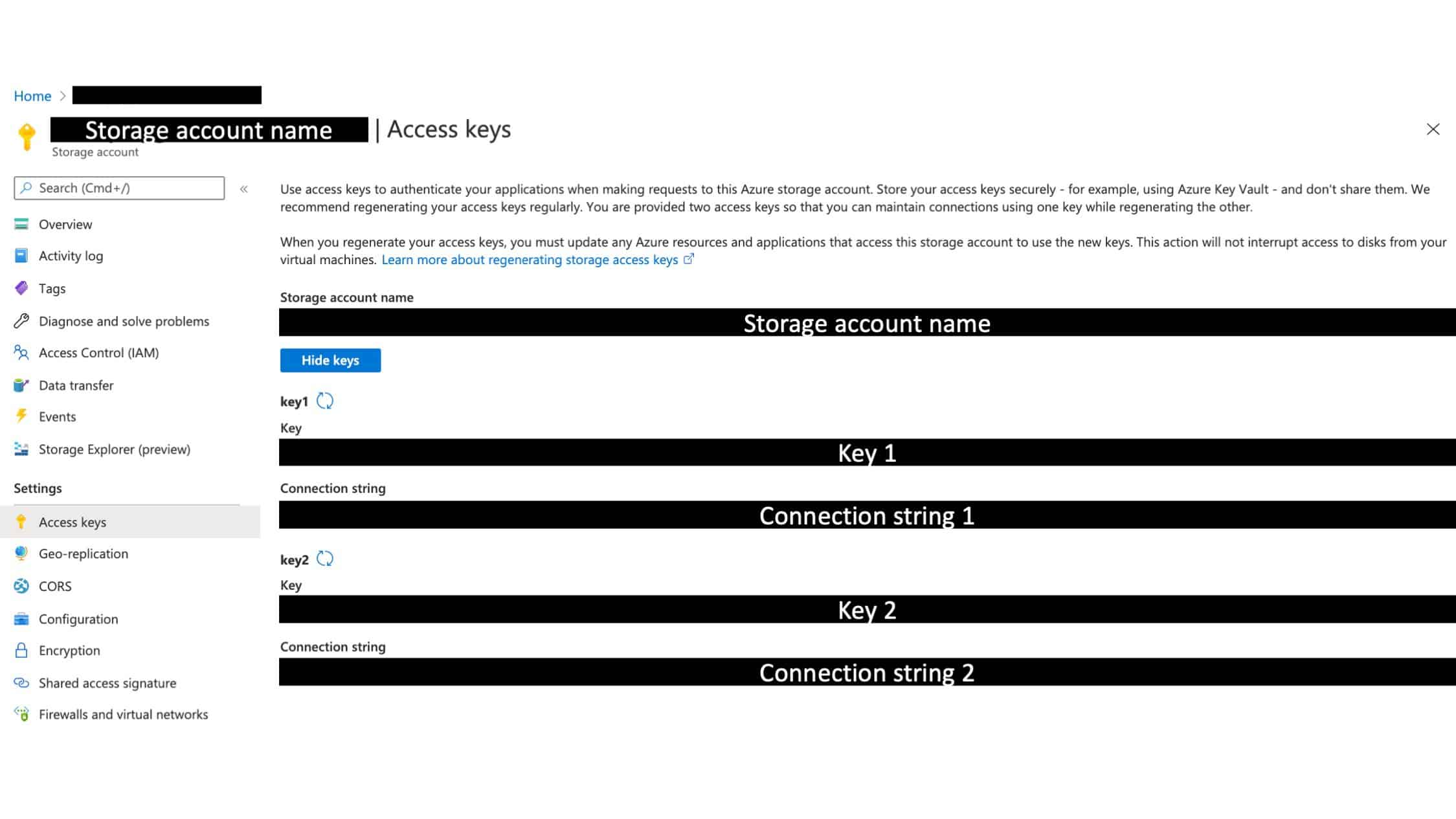
We need to register this string as an environment variable called SA_CONN_STR on your machine. The connection string that you copy from the UI has an obsolete part at the end which would break our solution. Therefore, make sure to delete the part of the string after the ==;. Then, add the following line to your ~/.bash_profile, replacing the part between the quotes with the relevant part of your connection string:
export SA_CONN_STR='DefaultEndpointsProtocol=https;AccountName=XXX;AccountKey=XXX==;'Open a new terminal and check if your connection string is correctly stored as an environment variable by running:
echo $SA_CONN_STRIf you did it right, this should print the connection string. If you get stuck here, google on how to add environment variables to your operating system.
Step 4: Build the search engine
In the Azure portal, navigate to the Azure search service. Create a new search service. Write down the URL from the overview page. This is the ACS_ENDPOINT. Then navigate to the keys tab in the pane on the left. The primary admin key is your ACS_API_KEY. Also add your client IP in the networking tab. Do not forget to hit save!
Now, also register the ACS_ENDPOINT and ACS_API_KEY on your machine as environment variables.
You can find them from the Azure portal here:
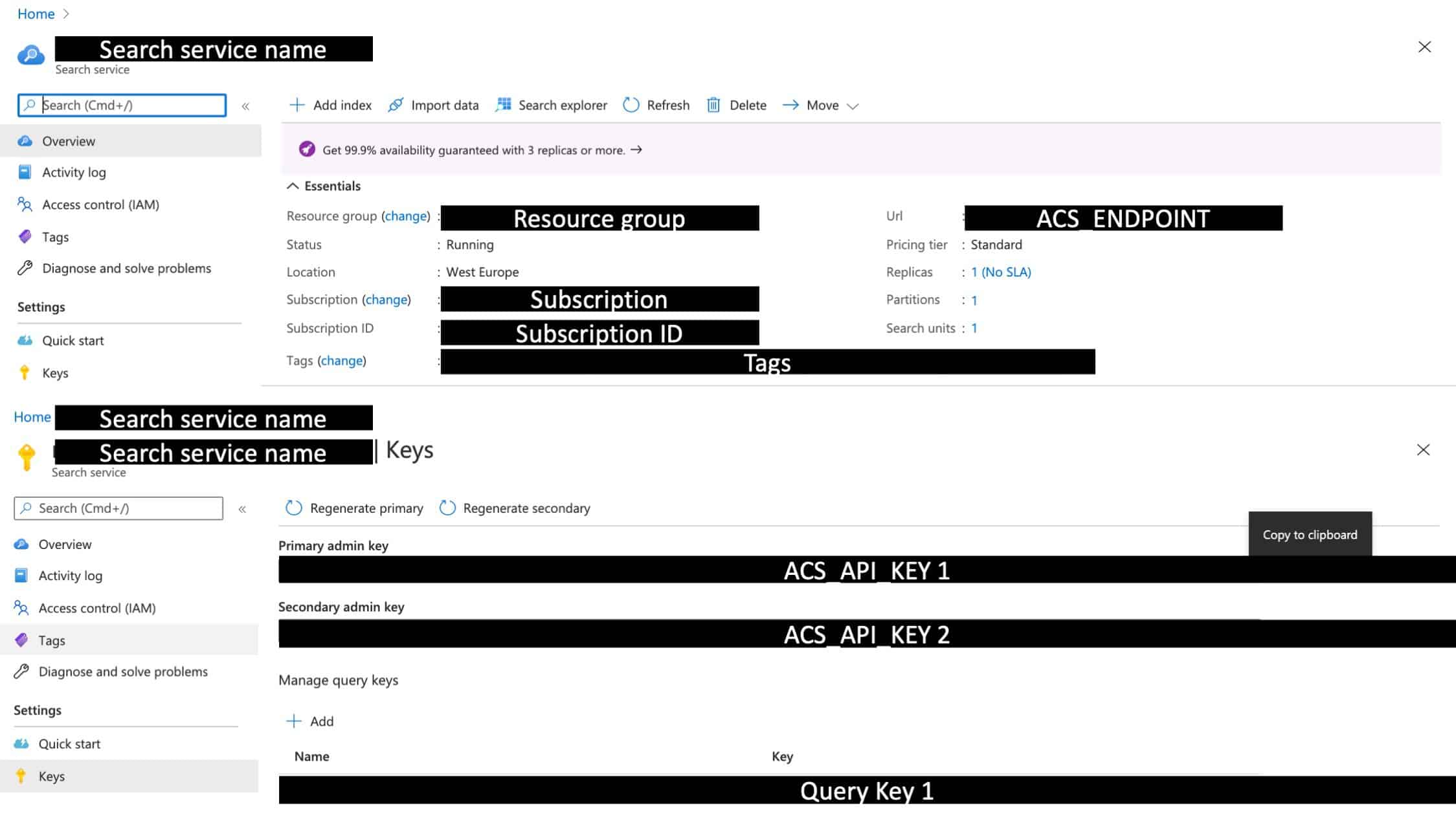
When exporting your environmental variables please note the trailing slash in the ACS_ENDPOINT.
export ACS_API_KEY=XXX
export ACS_ENDPOINT='https://XXX.search.windows.net/'Please note the '/' at the end of the ACS_ENDPOINT.
When you have added the environment variables open a new terminal and run the setup script:
my-search-engine-demo/my-search-engine-demo/setup_acs.pyTo index articles you need to do four things:
- Create a data source read the docs
- Create an index read the docs
- Create an indexer read the docs
- Run the indexer read the docs
I've created a script for you that takes care of this. But before you can run it, you have to create the search service.
First install the dependencies. You probably want to do this in a virtual environment E.g.
virtualenv <name_env>
source <name_env>/bin/activate
pip install -r my-search-engine-demo/requirements.txtThen run the following command:
python my-search-engine-demo/my-search-engine-demo/setup_acs.pyThis will trigger the indexation process. Wait until you see "Indexer created correctly..." and some fancy ASCII art which tells you that the indexation is done.
If you are running into timeout errors, please check if your IP is whitelisted from the networking settings in the Azure portal for in Azure Cognitive Search. If not, please add your IP.
Step 5: Develop the user interface
For the user interface we will create a Streamlit app. According to their website:
"Streamlit’s open-source app framework is the easiest way for data scientists and machine learning engineers to create beautiful, performant apps in only a few hours! All in pure Python. All for free.""
Let's put that to the test shall we? Check out the "my-search-engine-demo/my-search-engine-demo/user_interface.py" file in the repository to check out how the user interface is made.
The paginator and download results functions are nice to haves. So, you can leave them out if you want to. The following are essential:
1) Create a title 2) Render an image 3) Create the search bar 4) Load the API secrets 5) Send the search query to the API 6) Render the results
You can try it out locally by running:
streamlit run my-search-engine-demo/my-search-engine-demo/user_interface.pyStep 6: Deploy the user interface
Docker image
For this part you need to install Docker on your local machine.
According to their website:
"Docker is an open platform for developing, shipping, and running applications. Docker enables you to separate your applications from your infrastructure so you can deliver software quickly."
We will create a Docker image, with the required dependencies and the code for the user interface.
We build the image from the my-search-engine-demo/my-search-engine-demo directory by running:
docker build --build-arg BUILDTIME_ACS_API_KEY=${ACS_API_KEY} --build-arg BUILDTIME_ACS_ENDPOINT=${ACS_ENDPOINT} --build-arg BUILDTIME_SA_CONN_STR=${SA_CONN_STR} -t covid-19-search:latest .This way we create a docker image tagged with "my-search-engin-demo:latest". The environmental variables will be copied into the image.
To test if your image was build correctly run it locally:
docker run -p 8080:8080 covid-19-search:latestYou should now be able to access the user interface from your browser with localhost:8080.
The exposed port is specified in the Dockerfile. If you want to expose the service on a different port, alter it there.
Azure container registry
Now we must create an Azure container registry. Write down the server name, which is something like "XXX.Azurecr.io
From the access keys menu, enable admin and write down the username and password so you can log into the server.
Now it is time to push the image to the registry. First, we tag our image with the login server/image name:tag.
docker tag covid-19-search:latest {login server}/{image name}:{tag}It will look something like "XXX.Azurecr.io/covid-19-search:latest"
Second, we log into the server
docker login <<servername e.g. XXX.Azurecr.io>> Third, we push our image to the server:
docker push server/image name:tagYou should now see the image in your Container Registry repository.
Azure app services
You are almost done! The last step is to publish the image as a webpage accessible from the internet.
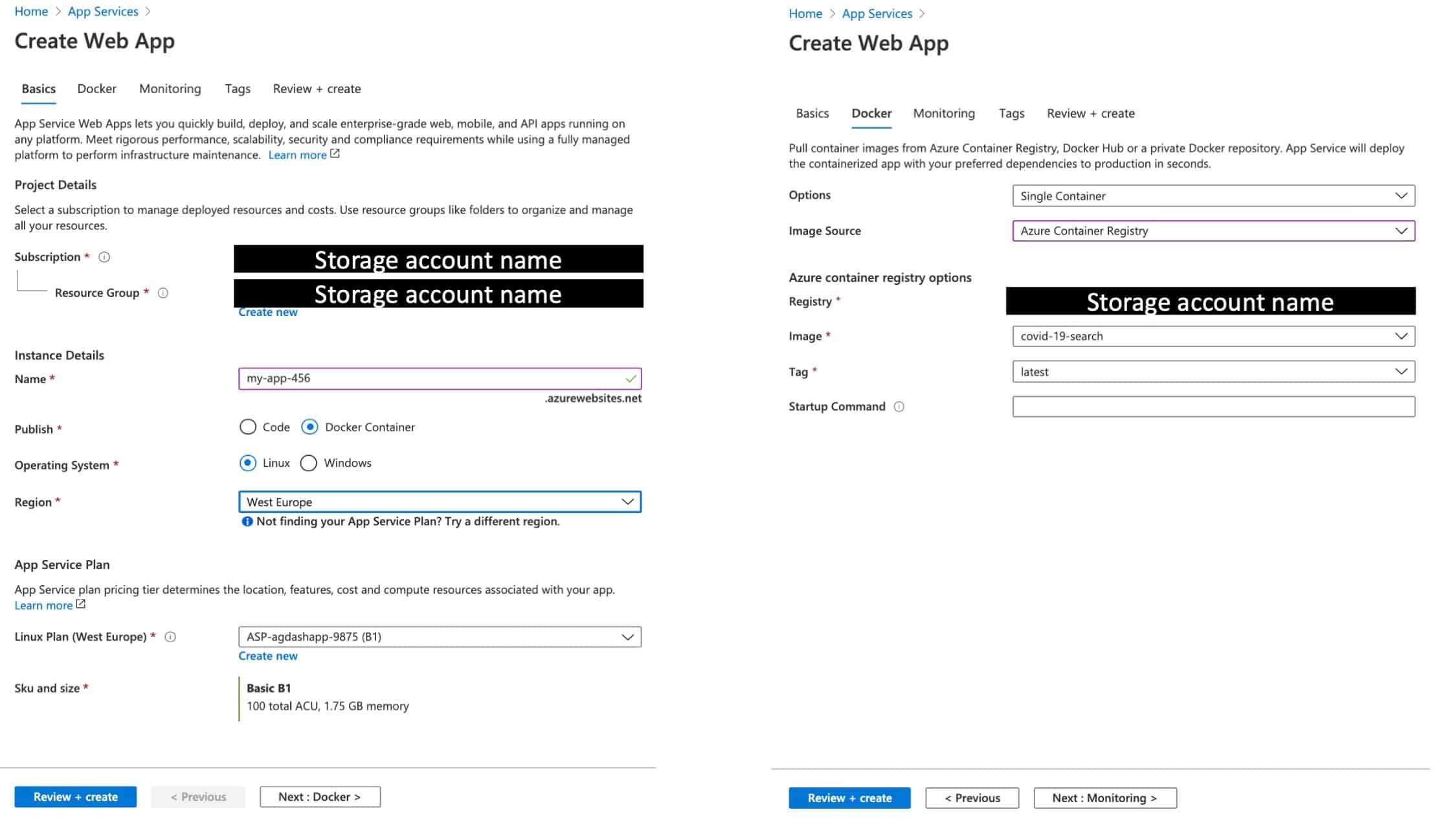
1) In the Azure portal, go to Azure app services and add a web app.
2) Enter a name for your new web app and select or create a new resource group. For the operating system, choose Linux.
3) Choose "configure container" and select Azure Container Registry. Use the drop-down lists to select the registry you created, and the Docker image and tag that you generated earlier.
Now create your service. Once that's done head to the service URL to access your website!
The above steps should look something like:
If the website is accessible, but it seems to load forever (the search bar does not show), you might have stumbled upon a bug. I fixed it by upgrading to a production tier plan, and scaled back to the cheaper plan after. This might raise some eyebrows, including my own, but it did the trick. If you find the cause, please let me know,
Conclusion
Building you own search engine by indexing articles with the cognitive search API is easier than you might think! In this blog we've covered how to use Streamlit to interact with the search engine and learned how to dockerize and deploy the solution as a web app.
I hope that by reading this blog you've gained one of these three insights. 1) Found relevant information regarding Covid-19. 2) Identified an opportunity to alter this solution to a different dataset. 3) Identified an opportunity to alter this solution to replace the search engine with a different analytics engine.
Don't hesitate to share what you've learned in the comments below, or to contribute to the code base!




Contact