Blog
How to Build & Run a High Performance Serverless Voting System for Less Than $100

As a freshly certified AWS software developer associate, I couldn’t wait to put my newly acquired skills into practice. I didn’t have to wait long for an opportunity. Shortly after I passed the certification exam, one of my colleagues asked my friend and me to work on a small AWS Cloud project.
The requirements seemed simple. We needed to implement a high-performance voting system based on Serverless services available on the AWS Cloud.
The Challenge
As with most of these kinds of systems, the real challenge was the “high performance” part. But what does it really mean for a system to be a high-performance one? Well, it depends… Mostly on user traffic but also on the system’s complexity or the budget that a company is allowed to spend. Having this in mind, let’s define some of our solution’s requirements. The use case is to prepare an online survey available in a specified voting window. It should be able to handle massive user traffic. For instance, your favourite live TV show allows the audience to vote for a certain period of time (e.g. 10 min.) and then, after the commercial break, it presents the results (see timeline below).

Considering all this, we now know that our system needs to handle a large amount of irregular user traffic in a very short time. In such a case, an on-premise solution would be an enormous waste of money, as it stays mostly idle when traffic is low. So, let’s consider how we can manage this problem by adopting a Serverless approach.
Architecture
To start off, we need to define what kind of components are needed for the system. Our task was to build it with native AWS components, but in most cases, there are open source equivalents.
Frontend
From the user’s perspective, it would be nice to have a user-friendly interface. This part was pretty simple thanks to S3 and its feature, which serves bucket as a static website. According to AWS, it should scale seamlessly even on a heavy load. In addition, you only pay for real traffic, which means that the development process is very cheap. Then, with access to all the goods of modern frontend development, one of my friends quickly built a simple single page application in Vue.js. Let me describe what this app has to offer its users.

The application’s URL welcomes the user with an input form. The view consists of the survey provider’s logo, a unique user identifier input field, a submit button, and a countdown clock.

After submitting the form, the application redirects the user to the question view, which consists of the same logo as in the previous view, a question text, a list of answers, and another submit button. Clicking the submit button redirects the user to the results of the survey, which are updated every five seconds so that the user can follow the survey’s status (live updates will be covered in another part of this article). In our example, the survey takes 10 minutes and we provided an additional 120 seconds for the processing of trailing votes.
Backend
At this point, we described the hosting of a frontend application. However, a static application is not enough for a voting platform.
The heart of the system is hidden behind an API Gateway service. The API Gateway serves as a proxy for one of the lambda functions used in our solution; (namely, for a lambda function responsible for vote validation and the transfer of votes to the SQS service). The data pipeline queue is crucial due to the limits of DynamoDB. The DynamoDB service has limited throughput for both read and write. Fortunately, the throughput can be changed at any point in time (e.g. using SDK).
Having all of this in mind, we introduced a lambda function called orchestrator, which is responsible for checking the current queue status and scaling the database throughput proportionally to the number of messages in the queue. In addition, after the successful scaling of DynamoDB, the orchestrator is responsible for spawning children processes in the form of worker lambda functions. The number of such processes should also be proportional to the number of messages currently available in the queue in order to handle all of the votes as quickly as possible. The worker lambda function logic is simple. The process, when created, pulls messages from SQS, tries to transfer them to DynamoDB, and removes them from the queue in case of success. In case of failure, while transferring messages to the database, the lambda function also fails and the messages return to the queue – ready to be processed by another worker. The diagram below presents this system.
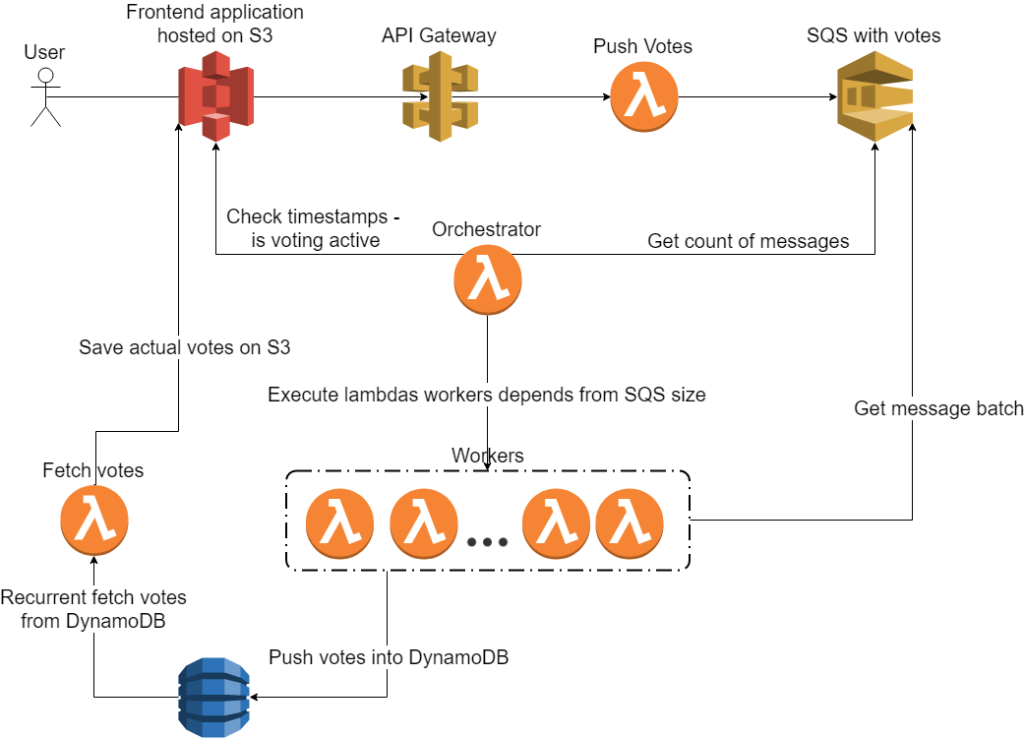
The diagram shows one element of the system, which hasn’t been discussed yet. There is yet another lambda function between DynamoDB and S3 bucket. This function is responsible for the previously mentioned live updates of survey results. It queries DynamoDB in a loop and transfers the results to the S3 bucket. Then an Ajax call reads results from the bucket and refreshes the chart.
Of course, however, something needs to trigger the orchestrator lambda and the abovementioned lambda in order for it to fetch results. To make it simple, we decided to go with Amazon CloudWatch – it triggers lambda functions every minute.
Testing
Okay, so at this point, we have our voting system implemented and available on the AWS Cloud. Now we just need to check if it can be considered a high-performance one.
It is also worth mentioning that, until this moment, the development process cost us less than $1.00!
To simulate the traffic, we used the Locust performance testing library as it has a friendly Python API. A single t2.micro EC2 with one CPU and 1GB of memory was able to send more than 250,000 requests in a 10-minute window. We decided to build an AMI with a previously prepared testing script. The script was working as a daemon, constantly sending predefined requests to the indicated URL of the API Gateway. Having AMI, we could stress test the solution by spawning multiple instances of EC2 machines. We were ready to test!
We started with a single machine. In the first iteration, we wanted to use an autoscaling feature of DynamoDB. This didn’t work out for us though. A massive throughput peak was throttled and, after a while, we received a Provisioned Throughput Exception. Then, after about 10 minutes, we observed that the database scaled. See the screenshot below.
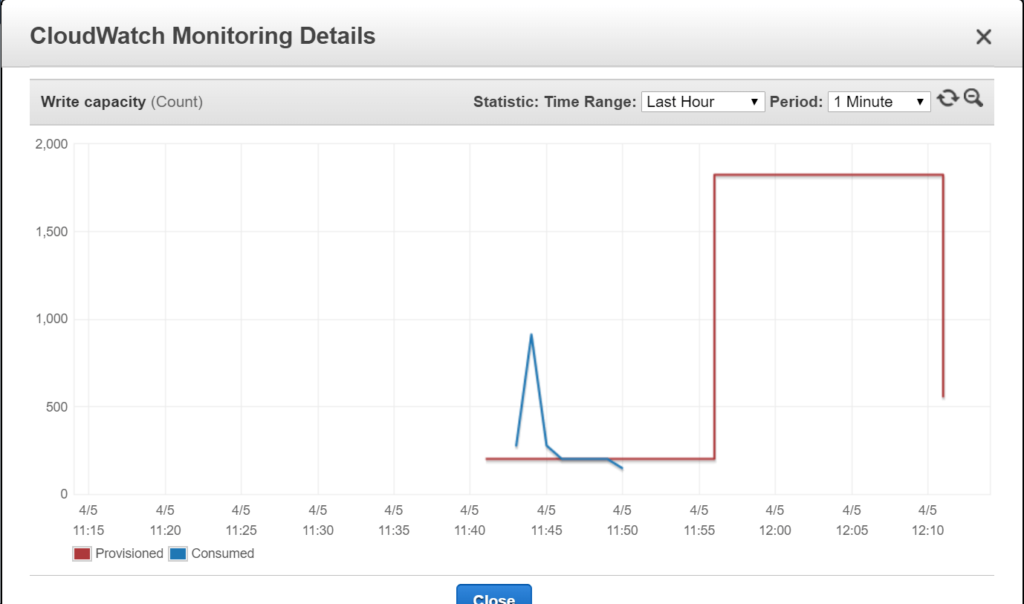
This issue definitely needs a closer look but we decided to skip autoscaling and add manual scaling to the lambda orchestrator. This way we could proceed with testing.
After resolving the scaling issue, DynamoDB testing with a single machine seemed fine. We decided to go big! Ten EC2 instances sending 4,000 requests per second. And then we hit another obstacle… To be more precise - the limit of concurrent lambda functions in the AWS region. The default is 1000, which means that we could have only 1000 concurrently running lambda functions in a single AWS region. This limit can be increased though. All you need to do is contact an AWS Cloud provider, describe your intention, and wait. We sent a request and, the next day, we were asked to provide some additional information like the average time of a lambda run or information regarding average memory usage. We sent another request but, at the same time, we decided to test the system with two EC2 instances.
The open voting window seemed fine at the beginning. The interesting stuff happens about 5 minutes later - all of the survey bars freeze. The problem is the previously mentioned limit of concurrent lambda functions. The function responsible for updating results cannot start due to a number of currently running lambda functions. After some time, it finally refreshes the results but it ruins the experience. On top of that, the system hardly manages to count all of the votes in time, due to a limited number of running workers. Most of the limit is used by lambda functions connected directly to the API Gateway. One incoming request means one lambda invocation. So at this point, further testing is pointless unless the limit is increased. I don’t mean that we cannot improve the solution; but more on that later.
Costs
As mentioned before, the development process costs less than $1. The cost of running EC2 instances for testing is also negligible. The overall sum of expenses amounted to $76. To analyse where this number came from, it should be said that we sent several million requests. The API Gateway turned out to be the most expensive part of the system as it cost $32. DynamoDB came in second place at $12 and AWS Lambda placed third, costing $8.
Lessons Learned
As usual, after you finish something, you can easily point out the parts that could have been improved. This project is not an exception. It occurred to us that it would have been a good idea to remove the API Gateway and to move the vote validation to the workers. Votes could have been sent from a static website directly to SQS. Certain permissions could have been obtained using the Cognito service. This way we would have been able to use most of the lambda functions as workers. However, it cannot be ruled out that we will carry out all of the improvements mentioned above and publish a follow-up article in the near future.
Conclusion
The AWS platform is a very developer-friendly work environment. It provides a vast amount of services ready to integrate easily with various solutions. Serverless architecture is definitely something worth trying out. You only pay for what you actually use which means that the development process is really inexpensive. You can easily start small and, as the project and customers grow in numbers, your bills will scale proportionally.
The Serverless approach does have some disadvantages though. Solutions Architects need to be familiar with the services that they want to adopt. This knowledge is crucial in order to avoid unexpected blockers somewhere in the middle of the implementation process. Moreover, it’s hard to build such a solution in a way that is totally independent of a certain Cloud platform provider – and building solutions deployable on more than one Cloud platform isn’t an easy task.
To sum up, when it comes to the voting system, choosing to go with a Serverless architecture seems to be the best solution – there is no need to invest in expensive hardware, systems scale automatically, and the development process is cheap as you pay only for what you actually use.
Written by
Xebia Author
Our Ideas
Explore More Blogs




Contact