
Why Ravioli Is My Favourite Recipe
No, this post is not about my favourite recipe. Or maybe in some way it is. This is a post about hexagonal architecture, an architectural pattern for building software. I’ll explain what hexagonal architecture is all about and what it has to do with cooking ravioli. To illustrate what it looks like in practice, I’ll show how to transform ‘spaghetti code’ into highly cohesive, loosely coupled and highly testable code using the principles of hexagonal architecture and domain driven design. I do this by rewriting a Kotlin and Spring Boot application using a hexagonal architecture.Multitier Architecture
To understand what hexagonal architecture is all about, let’s first have a look at the classic, layered architecture. In this type of software architecture, often compared with lasagne, you divide your code in a couple of layers or tiers. In a 3-tier architecture this would be: the presentation layer, the logic or domain layer and the persistence layer
 3-tier architecture[/caption]
3-tier architecture[/caption]
Presentation Layer
This layer provides the interface through which users or other systems can access your application, either for data entry or consumption. It presents results to users or clients and it enable users to interact with your application. This could for instance be by means of a GUI, web page or REST interface. In terms of software components this is the layer where you’d put your controllers and your views.
Logic Layer
This is the core of your application. It’s where the actual work happens, the business logic. Where the value of your application is generated. Usually this is where you’d define your domain models and your services. These services provide an interface for the presentation layer to access.
Data Layer
The data layer is concerned about persistence of your application’s data, e.g. using a database, data store or file share. It exposes a data access layer, your data access objects (DAO), for the logic layer to interact with.
A Cluttered Domain
Many projects involve integration or communication with external software systems. Think of databases, 3rd party services, but also application platforms or SDKs. What tends to happen, is that the domain layer gets cluttered with details or specifics regarding these integrations. The domain layer no longer contains only business logic, but there’s much more going on. For example: 3rd party integrations that bring in a dependency on a specific API version. Or by depending on the persistence layer and thereby having to deal with a specific persistence framework. Or maybe dealing with a specific application framework or SDK. Such integrations and dependencies can quickly get in your way, clutter your core domain and reduce testability of your core business logic.
To illustrate this we’ll take an imaginary problem domain. Imagine a Kotlin and Spring Boot user wallet management application that is built using a 3-tier architecture. Probably not very surprising one of its main features is making a deposit to a user’s account in a certain currency. The logic for this operation will be handled in the domain layer. Take for instance the following service
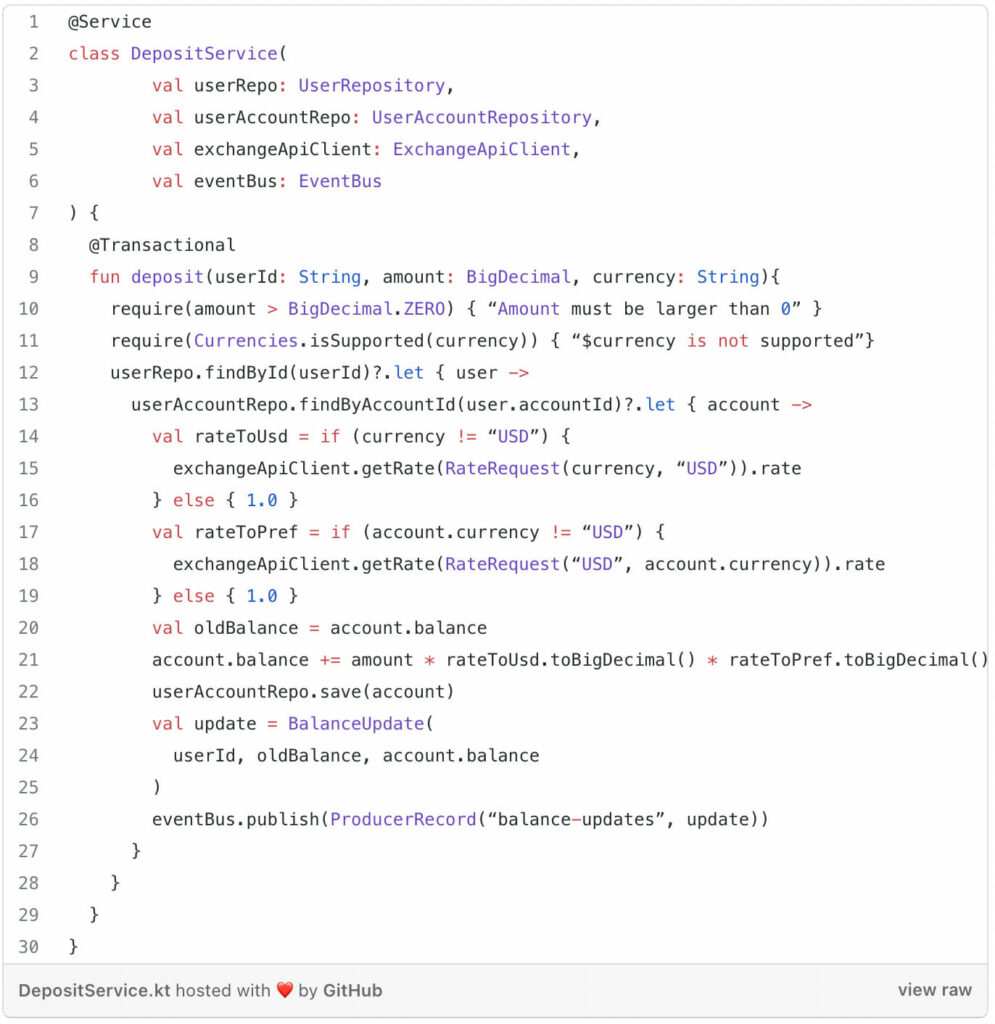
This service is responsible for making a deposit of funds happen in a certain currency. To be able to do that, it has a bunch of dependencies. The logic is mixed with integrating all these dependencies. It’s not the worst code in the world, but there is A LOT going on here.
First of all, the service depends on some repositories from the persistence layer. In the code above we are retrieving two different entities from two different repositories. Entities can be hard to deal with, because they are (usually) mutable. With mutability it’s easier to shoot yourself in the foot, especially when concurrency comes into play. This is more often the case than you might think. If you are building a web app, you already need to have concurrency in mind.
Secondly, our service depends on an exchange client, which potentially is a 3rd party service or REST api. It also depends on an event bus to publish balance updates. This means our code needs to adhere to a certain API model. Moreover, a specific version of it. To be able to test our logic, we need to mock those API calls. This can result in a lot of mocking and if there’s a new version, we need to update our logic, all our tests and our mocks.
Thirdly, besides logic there’s lots of orchestration going on. Our deposit function is marked with the @Transactional annotation, there’s an explicit call to persist the updated account in the database and we are publishing to an event bus in order to notify other services. Of course we need to think about transactions, security, logging, notifications, persistence. They are all very important business concerns, but they are not part of the actual business logic. So, this might not be the best place to deal with them, because it complicates your logic and the testing of it.
To summarise, mixing all these types of integrations and dealing with cross cutting business concerns in your service will lead to spaghetti code. I quite like spaghetti, but not in my code base. The code becomes much harder to reason about, much harder to maintain and much harder to change.
- It decreases testability. To be able to test our logic we need to mock away all those dependencies and orchestration. It is really tedious work and pollutes our tests.
- Depending on specific APIs or platforms leads to tight coupling between our service logic and 3rd party code. How do we deal with changes in API versions? Maybe we need to support multiple versions? This all can be very painful and quickly becomes expensive.
- Using mutable data structures, like entities, in your logic increases the chance of making mistakes (e.g. with regards to concurrency).
Dependency Inversion
What if, for a second we could forget about any integration and solely focus on the business logic? What if we could isolate our core logic, make sure it’s properly tested and then worry about the REST (pun intended) later? In order to do this we need to decouple our domain, the core logic, from everything else, the infrastructure. We need dependency inversion. Consider the diagram below.
 dependency inversion[/caption]
dependency inversion[/caption]
The diagram looks very similar to the 3-tier architecture one at the start of this article with one subtle, but important difference: the arrow from persistence layer is now pointing towards the domain layer. This indicates that the persistence layer is now depending on the domain layer, rather than the other way around. The domain now becomes the center of our application. Everything depends on the domain, while the domain depends on nothing. This is the core idea of a hexagonal architecture.
Hexagonal Architecture
Before we can rewrite our Kotlin and Spring Boot application using hexagonal architecture we first must better understand its design principles. Hexagonal architecture is about separating infrastructure from your core domain. It’s about making the domain the center of your application.
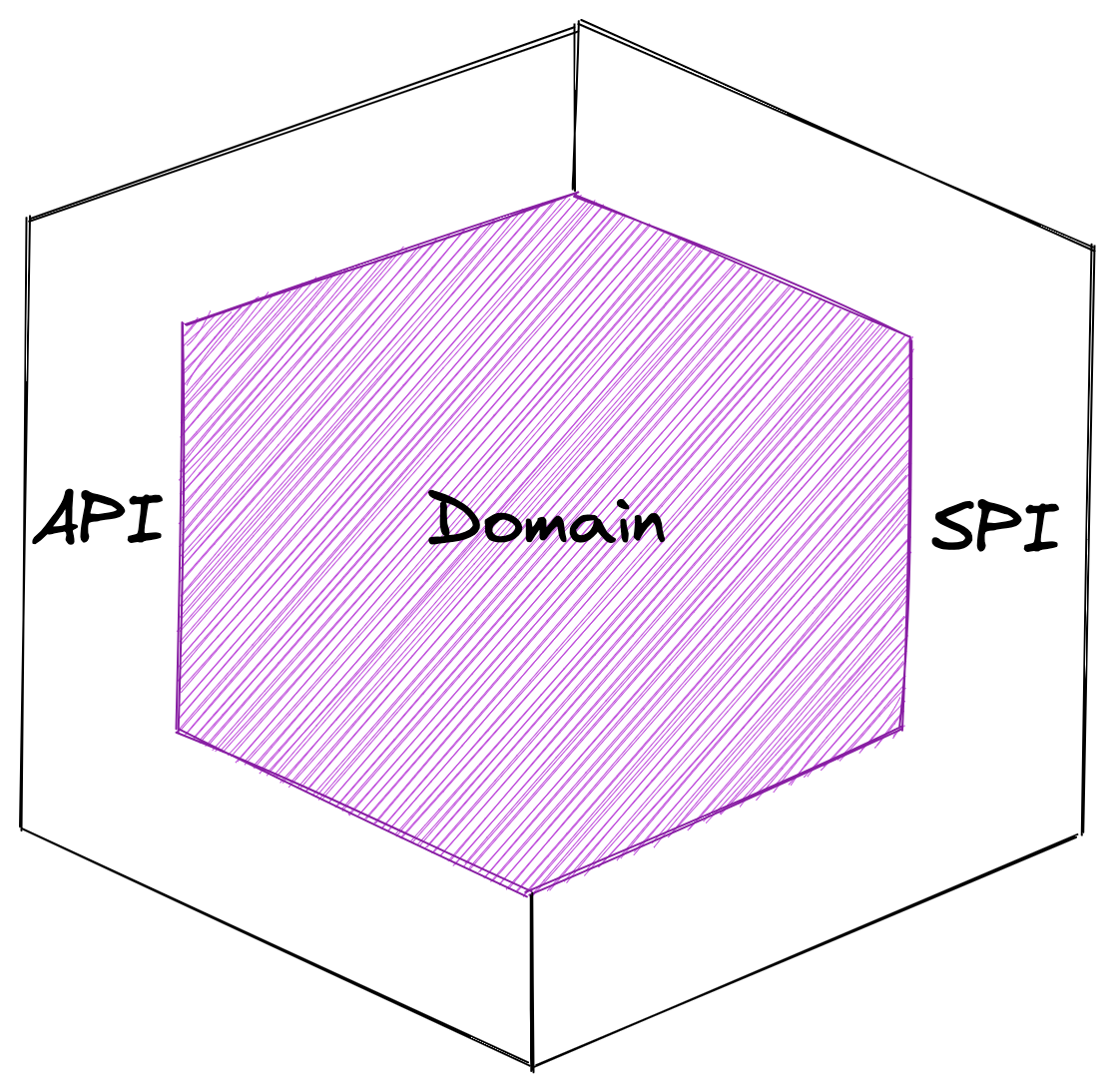 Domain surrounded by API and SPI layer[/caption]
Domain surrounded by API and SPI layer[/caption]
The domain is surrounded by an API layer and a service provider interface (SPI). The API ensures your domain is queryable for the outside world, for instance through a web interface. The goal of the service provider interface is to send or retrieve data to or from external systems. Think of fetching data from a 3rd party API or persisting data in a database.
Ports and Adapters
An alternative name for hexagonal architecture is ports and adapters (architecture). Ports and adapters are the main elements of a hexagonal architecture. Both the API and service provider interface layer are segmented into ports. Ports form a tech agnostic interface that is designed around the purpose of the interaction. This means ports are about the what rather than the how. In our wallet example this would mean that there’s a port that defines an interface to make a deposit without specifying (or depending on) any frameworks (e.g. Spring Boot), protocols, databases, etc. I’ve included a sample implementation further down this article to see how this would look like in practice.
The tech agnostic interface provided by ports can be implemented by adapters. As opposed to ports, adapter are technology specific. Adapters use ports to translate interaction intent to a technical implementation. Think of adapters to persist and entity in MongoDB or publish an event to Kafka. In that way adapters are about the how as the what is already defined by ports.
The diagram below shows how the API and service provider interface layer are segmented into ports surrounding our core domain. With a little bit of imagination this can be seen as a hexagon, hence the name hexagonal architecture.
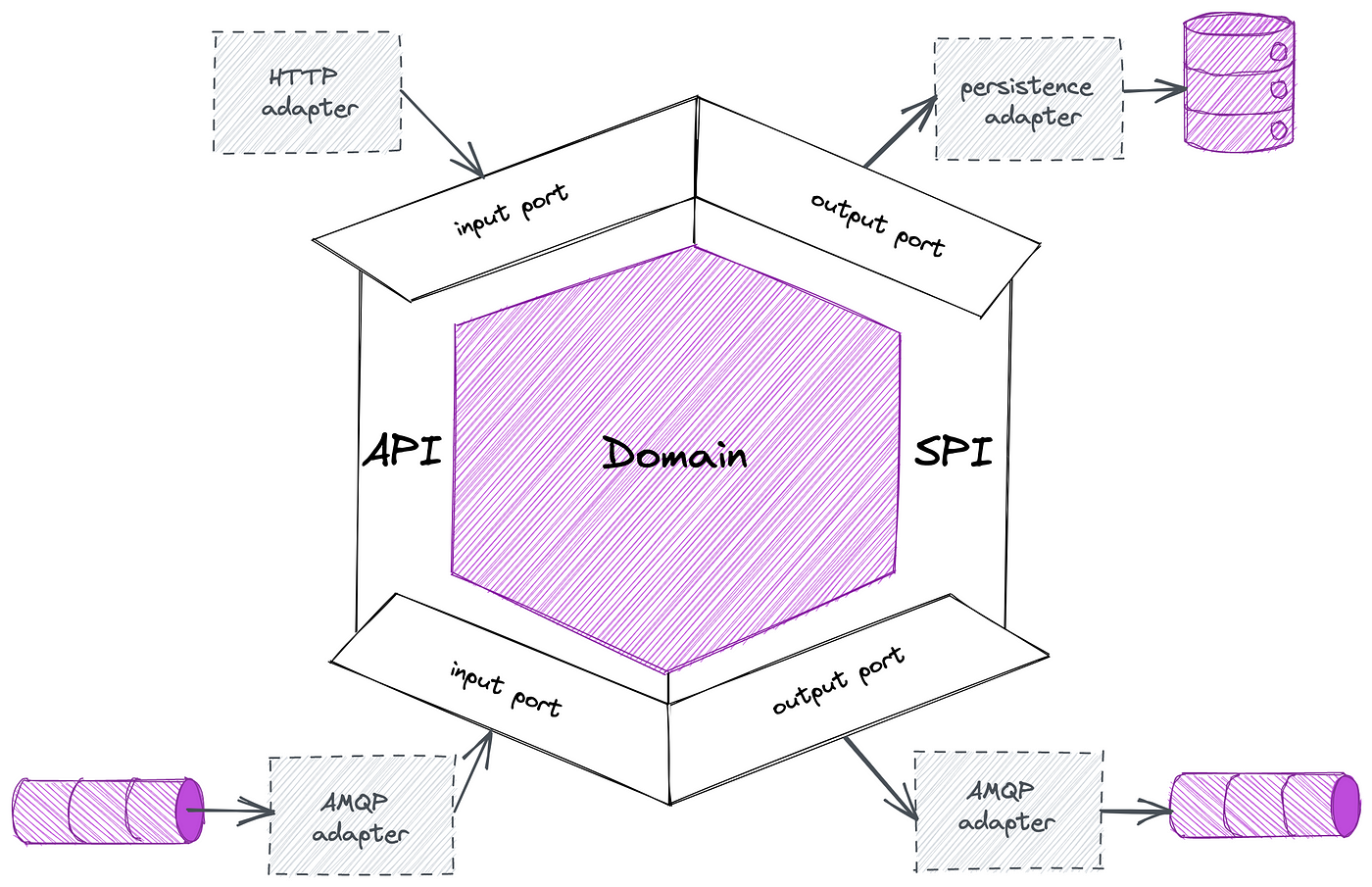 Example of ports and adapters[/caption]
Example of ports and adapters[/caption]
Wrap it like Ravioli
The important part is that our domain is nicely isolated from the outside world. The good, important stuff is nicely wrapped inside, like with a ravioli. Hence a design like this is sometimes referred to as ravioli code. In a ravioli architecture each of the modules is independent and self contained. Any component can be modified or replaced without significantly affecting other components.
Our domain is self-contained and doesn’t have any external dependencies. This makes it easy to verify correctness of its implementation. One can write very straight forward unit tests that don’t need (many) mocks and don’t depend on any framework. As a result those tests will also run really fast; we don’t need to spin up Spring Boot to be able to test our business logic.
The ports don’t have any external dependencies either. This means it is easy to swap out a specific technology or implementation by adding a different adapter. Changing or adding adapters will have low impact on the rest of our software, since we don’t have to change our ports or core domain. Hence, changing technology will have a low impact on the business.
Cook it ‘al dente’
When you overcook ravioli, it’s not very nice. It just starts falling apart. The same goes for overdoing modularisation and loose coupling. When overdoing loose coupling you lose cohesion and your code will start falling apart. Every business operation will involve lots of calls to different components. This will lead to bloated call stacks and simply navigating through the code base will become hard. Also things like transaction management become difficult as you would have to span transactions across multiple (asynchronous) boundaries.
Al dente:‘so as to be still firm when bitten’
For above reasons, it’s important to find the right balance and the right split when determining what should belong to your core domain. Your software modules need to be cooked ‘al dente’, to stay in the cooking pasta metaphor.
How to find the domain
So how do we find the right balance? How do we make the right split? What belongs in our core domain, what is in fact part of a different (problem) domain and what should be considered as infrastructure? To answer these question we can use domain driven design as our guideline.
Domain: A particular field of thought, activity or interest
What do we mean by domain? Looking at the above definition we can conclude that a domain comprises both the what and the how of all an organisation does. Especially in larger organisations this can be quite a lot. To keep things manageable we need to split up the domain into smaller, independent domain models with clear boundaries. A key term in domain driven design for such an independent model is bounded context. A bounded context is a distinct and unambiguous part of the domain.
According to Martin Fowler the key to controlling complexity in software is creating a good domain model. Eric Evans’ Domain-Driven Design: Tackling Complexity in the Heart of Software contains a lot of design best practices, experience-based techniques, and fundamental principles that facilitate the development of a good domain model in software projects facing complex domains.
In the next section I’ll show how we can apply the design best practices, techniques and principles of domain driven design to transform the design of our Kotlin and Spring Boot deposit application into a hexagonal architecture.
Building Blocks of Domain Driven Design
There are several building blocks of domain driven design that come to use when designing highly cohesive, loosely coupled software modules. In this section I’ll go over the most relevant ones for our use case and show how to apply domain driven design to improve our code example at the start of this article. Let's introduce hexagonal architecture to our Kotlin and Spring Boot application.
Value Objects
The first building block is the value object. Value objects are small and coherent models of part of your domain. They are stateless, immutable, thread-safe and side-effect free. Value objects are identified by their value, meaning if all properties of two value objects are equal, then both objects are considered equal (as opposed to entities). It’s a good practice to include business logic and validations that can be applied on the object itself in the particular value object. Consider the example below:
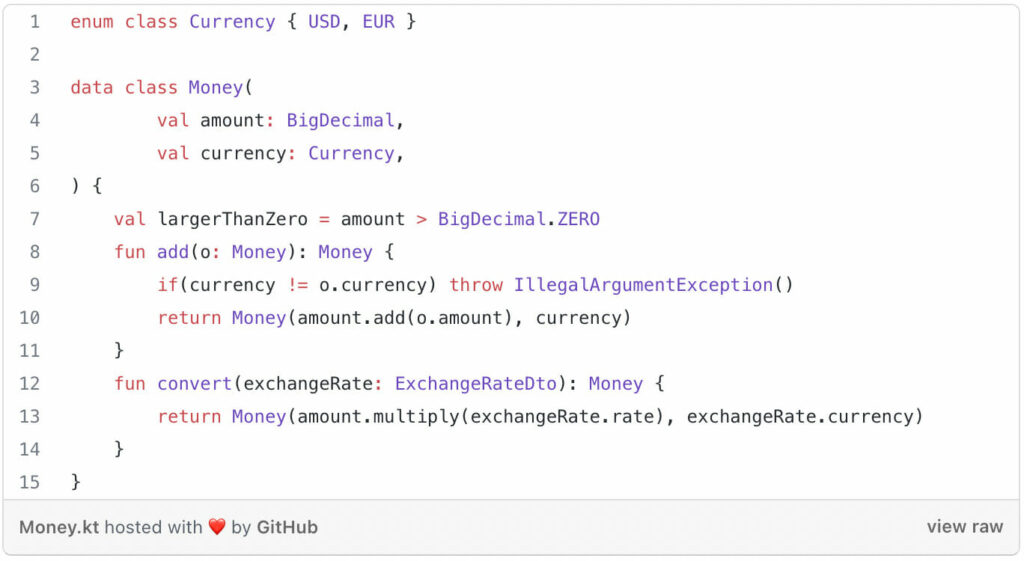 value object example[/caption]
value object example[/caption]We use Kotlin data classes in order to get immutable (strongly typed) properties and copy constructors. The business operations add and convert are part of the Money class itself. We don’t need to put them in the service layer; it’s a more natural fit and better for cohesion to put them in the Money class itself, because it’s a state transition on a Money instance. Thanks to Kotlin’s nullable types we have implicit null checks as well. The convert function takes another value object, ExchangeRateDto, as input which just encapsulates rate and currency properties.
Entities
Another building block you’ll often need to use is an entity. Use entities to represent records in a database or storage system. As opposed to earlier discussed value objects, entities are usually mutable and defined by their identity rather than their value (properties). Even if all properties of two entity objects are different, but the identifier (id) is the same we are still dealing with the same entity, e.g. the same database record. It simply has a different state. Since your entities live in the infrastructure module it’s fine to use database specific annotations in them. Also, it’s preferable to define meaningful functions that show business intent, instead of setters solely. Consider the following example:
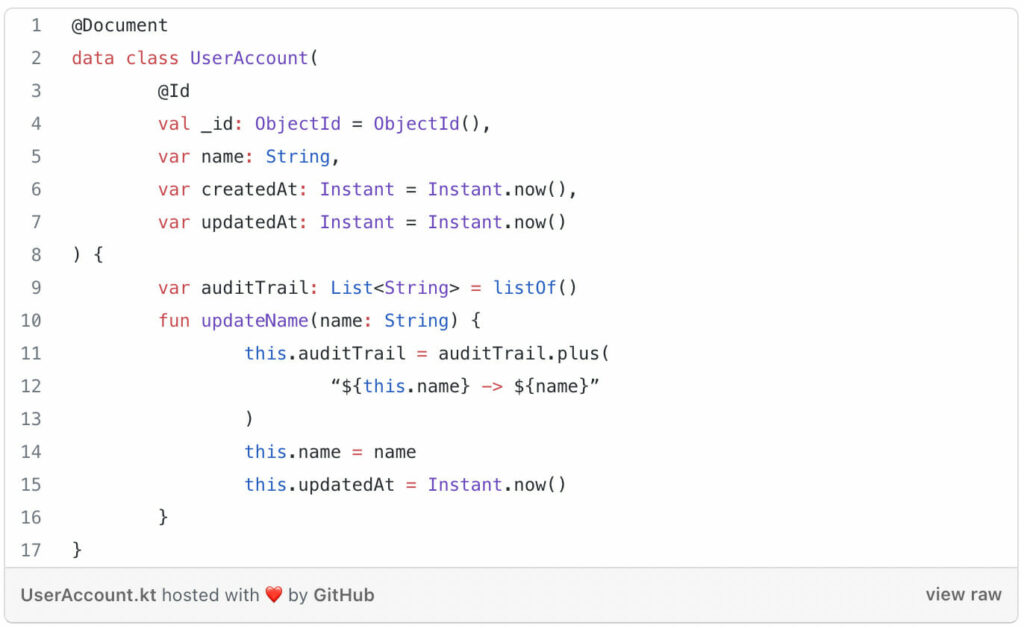 entity example[/caption]
entity example[/caption]
Once again we use a Kotlin data class, but this time with mutable (reassignable) properties. Since this class lives in the infrastructure model and not in our domain module, it’s fine to use MongoDB specific annotations from Spring Data like @Document and @Id. Rather than just using setters we expose a more meaningful function updateName that performs the state transition and necessary side effects.
Domain Services
The third building block of domain driven design we’ll dive into is a domain service. Use domain services for business logic that doesn’t naturally fit in value objects. Domain services are also stateless and highly cohesive. Using stateless components and immutable data structures will make it easier to construct objects (also in unit tests) and it will be less likely to shoot yourself in the foot when concurrency comes into play (e.g. when serving requests in a web app). Here’s an example of what our DepositService could look like if we make it a domain service using value objects and DTOs:
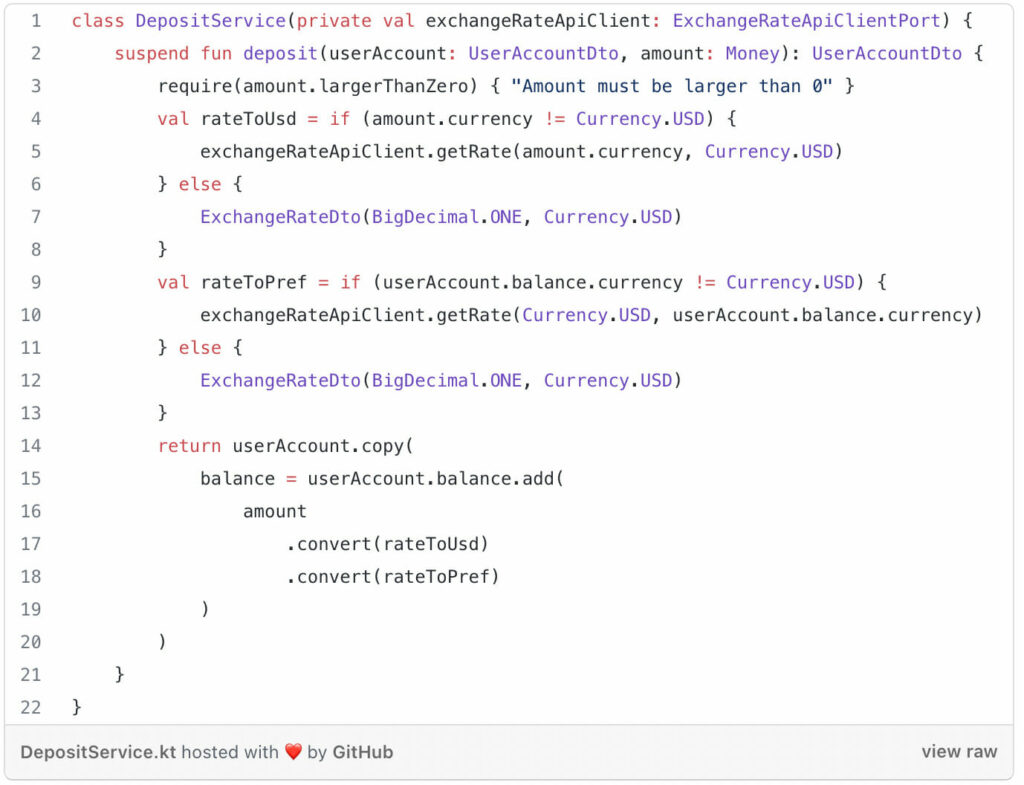 domain service example[/caption]
domain service example[/caption]
Our deposit service is not using the user account entity directly. It’s just using our value objects: Money and UserAccountDto. I’ve left out the implementation of UserAccountDto for brevity, but for our use case it could be as simple as:
data class UserAccountDTO(val balance: Money)
All required logic for updating the balance (i.e. converting between currencies and summing amounts) is already in the Money class. All our deposit service needs to do is fetch the exchange rates through an ExchangeRateApiClientPort. The implementation behind this port is irrelevant for the deposit service. All that matters is the contract: a source and target currency go in, an ExchangeRateDto comes out. Also note that there is no Spring annotations involved here. We are doing the wiring later.
The code snippet below shows an example implementation of an adapter that implements the ExchangeRateApiClientPort.
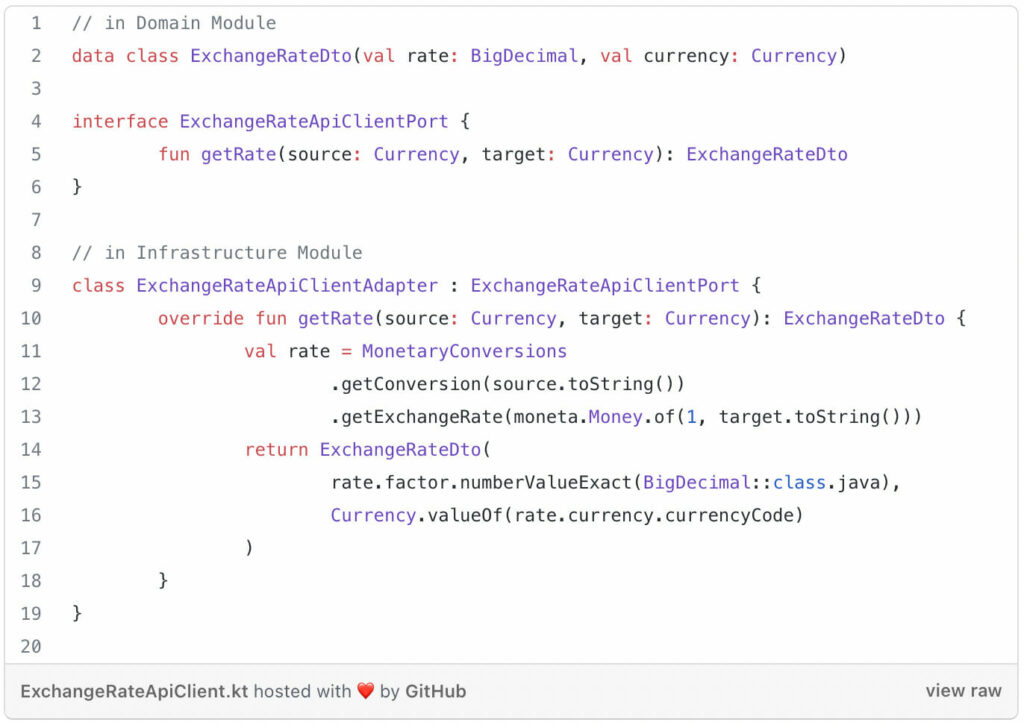 adapter example[/caption]
adapter example[/caption]
In the above implementation I’m using the Moneta API (javamoney.github.io/ri.html), but I might as well replace this later with a web service. The deposit service wouldn’t be affected by such a reimplementation.
Application Services
The fourth and last building block of domain driven design we’ll look into is the application service. Use application services to interact with the ports defined in your domain. application services can either implement a port interface to allow external systems to access your application (e.g. web interface or message bus) or they use a port interface implemented by an adapter to access external an external system. Application services are stateless and orchestrate business operations rather than implementing business logic. They address cross-cutting concerns such as transaction management, logging, notifications, persistence, etc. Here’s an example:
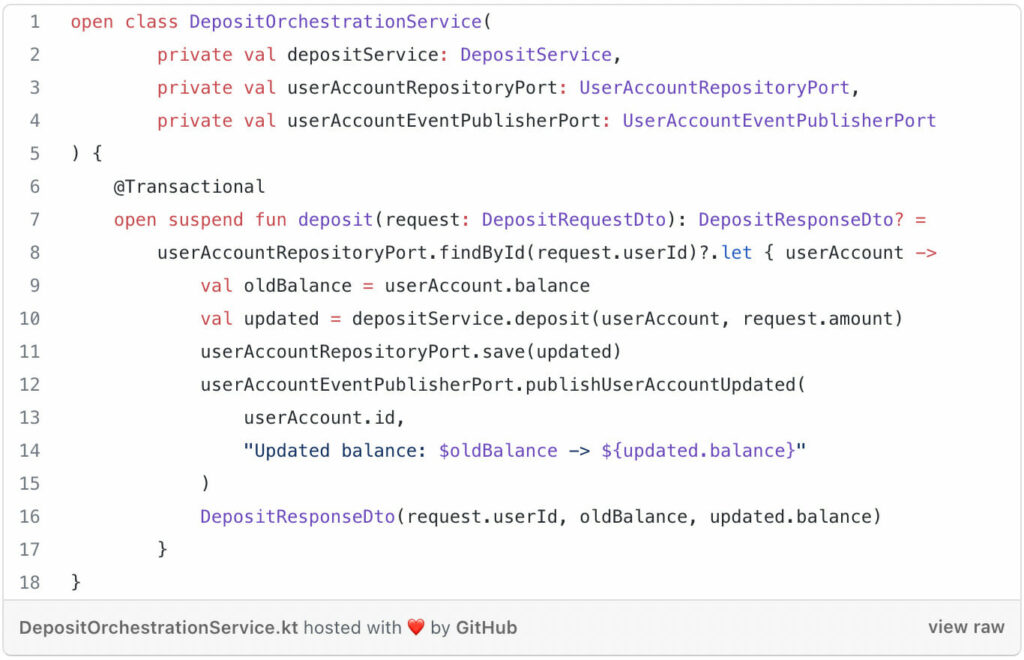 application service example[/caption]
application service example[/caption]
The DepositOrchestrationService ties everything together. Besides delegating a deposit request to the DepositService, it adds transaction management (using the @Transactionalannotation of the Spring tx module), ensures the updated user account is persisted and ensures that an update event is published through the UserAccountRepositoryPort respectively the UserAccountEventPublisherPort. In case the user for whom the deposit request is made is not found, we simply return null (once again using nullable types). The presentation layer, e.g. a REST api can then decide how to present such situations to the end user, for instance by returning an HTTP 404 response.
This was the last step of rewriting our Kotlin and Spring Boot application using the principles of hexagonal architecture and the building blocks of domain driven design.
Conclusion
Although we ended up with a little more code than we started with, I hope you agree we made several improvements by applying the principles of hexagonal architecture and domain driven design in our Kotlin and Spring Boot application. There now is a clear separation of concerns, our code has high cohesion, loose coupling and our core logic can be tested without having to worry about mocking technical dependencies or frameworks. We minimised the impact of version upgrades in our dependencies and other changes in infrastructure on the core part of our software. That way we minimised the impact of such changes on our business.
The main take aways for designing software following the principles of hexagonal architecture are:
- Start by designing a tech agnostic domain. In the end this is where the value of the software lies. By starting with the domain you can bring value early to your stakeholders and delay choices on technical implementation until you have gathered enough knowledge to make them.
- Ensure the domain is a stand-alone, isolated module with embedded (unit) tests. Make a clear cut, for instance by making it a separate Maven module. That way you are more aware of the dependencies of your domain module and cannot unknowingly mix in any technical dependencies.
- Keep (technology specific) adapters in your infrastructure module. Write as many adapters as you need. You can swap out adapters or reimplement them without affecting the rest of the software.
- There might be situations where hexagonal architecture is a bit of overkill. It mostly shines when you have an actual domain to model. For example when merely proxying or transforming data from one format to another it might not be worth the effort and overhead. That being said, using language features like data classes or record types the overhead is usually quite minimal.
Thanks for reading this far! I hope you enjoyed the article and will consider hexagonal architecture for your projects. Most (if not all) code examples can be found at github.com kotlin-hexagonal-architecture-example. If you consider using hexagonal architecture for a Spring Boot and Kotlin project, consider using my template repository at github.com kotlin-hexagonal-architecture. For more information around the subject I refer to my J-Fall 2021 talk (J-Fall 2021: Jeroen Rosenberg - Cooking your Ravioli "Al Dente" with Hexagonal Architecture ).
Written by
Jeroen Rosenberg
Dev of the Ops / foodie / speaker / blogger. Founder of @amsscala. Passionate about Agile, Continuous Delivery. Proud father of three.
Our Ideas
Explore More Blogs

Where the GitHub Copilot Extension Points Break Governance
A lot of the recent additions to the GitHub Copilot ecosystem add real value for individual developers, yet they also expand the security surface that...
Rob Bos



Contact