
Using AWS Glue in your data processing pipelines can be really powerful. However something you run into something that at first sight might seem counterintuitive or tricky to fix.
An example of this is where we ran into some issues with a data processing pipeline that was unable to handle schema changes in the incoming data. The pipeline was working fine but then all of a sudden it stopped working. In the logs it said: "Parquet column cannot be converted in file". After some digging around it was clear that the schema between the different parquet files changed due to a change in the upstream source system.
But isn’t Glue supposed to be able to handle schema changes?
Well, yes and no. Although Glue itself can handle schema changes, it is built as an extension to Apache Spark. So when the parquet files are loaded into the dynamic frame, Spark expects the files to have a compatible schema. This is different from loading schema-less source files like JSON or CSV. In that case Spark is perfectly fine with loading all the data and to allow the Glue dynamic frame to make a decision on what data types should be used by using ResolveChoice and ApplyMapping.
In order to fix the issue described above I wanted to reproduce the schema conflict error with a really simple data set. The exception could be triggered by loading parquet files that have some customer account info and a balance. In the first file I created a schema with the balance as an integer, the second file contains a balance as a double. To spice it up a little I created a third file which also has a new address field in the schema.
import pandas as pd
pd.DataFrame({"name": ["Homer Simpson", "Bart Simpson"], "age": [36,10], "balance": [-500,-100]}).to_parquet("dataset1.parquet")
pd.DataFrame({"name": ["Marge Simpson", "Lisa Simpson"], "age": [34,8], "balance": [24990.50,500.21]}).to_parquet("dataset2.parquet")
pd.DataFrame({"name": ["Maggie Simpson"], "age": [1], "balance": [10], "address": "742 Evergreen Terrace"}).to_parquet("dataset3.parquet")
After uploading the files to S3 I ran a Glue Crawler to index the files and to create a table, which resulted in the following schema.
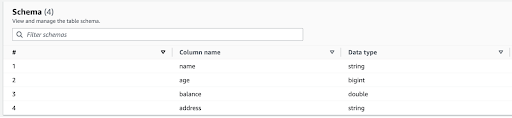
Interestingly enough, Glue only gives me a single schema version with balance as a double.
Next I open up a Glue interactive session and try to read the data from the Glue table and display it.
dyf = glueContext.create_dynamic_frame.from_catalog(database='blog', table_name='people')
dyf.printSchema()
The output is similar to what we saw in the Glue console, which makes sense as it just reads it from the data catalog.
root |-- name: string |-- age: long |-- balance: long |-- address: string
However as soon as we try to actually read the data in the Dynamic frame an exception is raised.
dyf.show()
Py4JJavaError: An error occurred while calling o87.showString.
: org.apache.spark.SparkException: Job aborted due to stage failure: Task 1 in stage 1.0 failed 4 times, most recent failure: Lost task 1.3 in stage 1.0 (TID 5) (172.34.254.19 executor 1): org.apache.spark.sql.execution.QueryExecutionException: Parquet column cannot be converted in file s3://conflicting-schemas-blog-post/people/dataset2.parquet. Column: [balance], Expected: bigint, Found: DOUBLE
at org.apache.spark.sql.errors.QueryExecutionErrors$.unsupportedSchemaColumnConvertError(QueryExecutionErrors.scala:706)
Reading the data directly from S3 with Spark, even including the mergeSchema option, causes the same issue.
bucket_name = 'conflicting-schemas-blog-post'
prefix = 'people/'
df = spark.read.option("mergeSchema", "true").parquet(f's3://{bucket_name}/{prefix}')
df.printSchema()
Py4JJavaError: An error occurred while calling o94.parquet.
: org.apache.spark.SparkException: Failed merging schema:
root
|-- name: string (nullable = true)
|-- age: long (nullable = true)
|-- balance: double (nullable = true)
|-- address: string (nullable = true)
…
Caused by: org.apache.spark.SparkException: Failed to merge fields 'balance' and 'balance'. Failed to merge incompatible data types bigint and double
Although Spark is able to merge different schemas, it still expects that the fields in the data frame have the same data type across all files*. To make the conflicting files adhere to a certain schema can be accomplished by preprocessing the parquet files one at a time. A simple example of how this could be done is given below:
import boto3
from awsglue.dynamicframe import DynamicFrame
from pyspark.sql.functions import col
s3 = boto3.resource('s3')
bucket = s3.Bucket(bucket_name)
# A variable to store the union of all dataframes
dfa = None
# Loop through the objects in your path
# or change this to go through the files from the Glue bookmark
for obj in bucket.objects.filter(Prefix=prefix):
if obj.key == prefix:
# This is the bucket prefix itself, ignore
continue
# Open the file
df = spark.read.parquet(f's3://{bucket_name}/{obj.key}')
# Test if the problematic column exists
if "balance" in df.columns:
# Cast it to the correct value
df = df.withColumn("balance", col("balance").cast("double"))
# Create a dynamic frame to merge it and allow for other schema changes
dyf = DynamicFrame.fromDF(df, glueContext, "adjusted_schema")
# Merge the dynamic frames
dfa = dfa.mergeDynamicFrame(dyf, []) if dfa else dyf
dfa.printSchema()
dfa.show()
Which results in a dataframe where all entries have the same data types across all fields.
root
|-- name: string
|-- age: long
|-- balance: double
|-- address: string
{"name": "Homer Simpson", "age": 36, "balance": -500.0}
{"name": "Bart Simpson", "age": 10, "balance": -100.0}
{"name": "Marge Simpson", "age": 34, "balance": 24990.5}
{"name": "Lisa Simpson", "age": 8, "balance": 500.21}
{"name": "Maggie Simpson", "age": 1, "balance": 10.0, "address": "742 Evergreen Terrace"}
With this merged dynamic frame you can now continue your ETL process. You could either include the code above in your Glue job or add it as a pre-processing job in your workflow.
Feel free to reach out if you have questions regarding data and analytics on AWS.
* See https://spark.apache.org/docs/3.3.0/sql-data-sources-parquet.html#schema-merging
Written by
Thomas Wijntjes




Contact