Blog
Green Software is Event Driven and Carbon Aware, with Kubernetes and KEDA

Did you know that data centres emit more carbon than aviation or shipping? And it is not slowing down, with some research forecasting that computing will contribute 14% of global emissions by 2040. Even worse, a significant portion of these emissions is wasted on non-production resources running outside office hours, always having your application scaled out for peak hours. This is not only bad for the planet but also for your cloud bill.
How can we do better? Instead of having a fixed number of application replicas, we should match the scale of our applications to:
- Current events, for example, in terms of incoming web requests or messages in a Kafka topic. Sizing your application based on how much work it has alleviates overprovisioning and always-on resources.
- The availability of clean energy. The electricity on the data centre's power grid comes from different sources, such as coal, nuclear, and solar. We should do more when the energy is cleaner, i.e., the carbon intensity is lower to reduce emissions further.
This article shows how we can make our applications greener by making them event-driven and carbon-aware. We'll introduce these properties at the level of the Kubernetes cluster using KEDA (Kubernetes Event-Driven Autoscaler) and Microsoft's Carbon Aware KEDA Operator, so all applications in the cluster can benefit without becoming more complex themselves. All code examples are found in my GitHub repo.
The webshop that wants to become greener
Consider a simple webshop with only two applications: a webserver that serves the website to customers and an ordering system that takes care of all other things. When a customer places an order, the webserver puts a message with all necessary information on a queue and immediately thanks the customer for its purchase. The ordering system consumes these messages asynchronously, checks the warehouse, dispatches the delivery, and then sends a confirmation email to the customer.
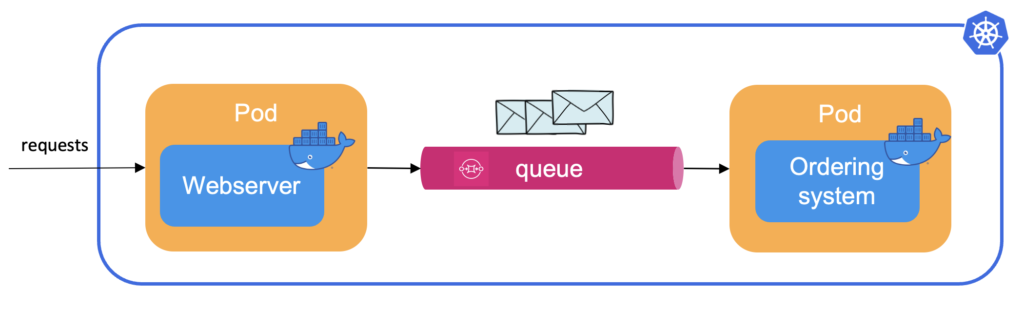
Even though the number of customers varies throughout the day, both applications are currently deployed with a fixed number of replica pods appropriate for busy moments. Below is a graph with the number of messages in the queue and the ordering system replicas in the cluster. The red line indicates the number of messages on the queue, and blue shows the number of pods.
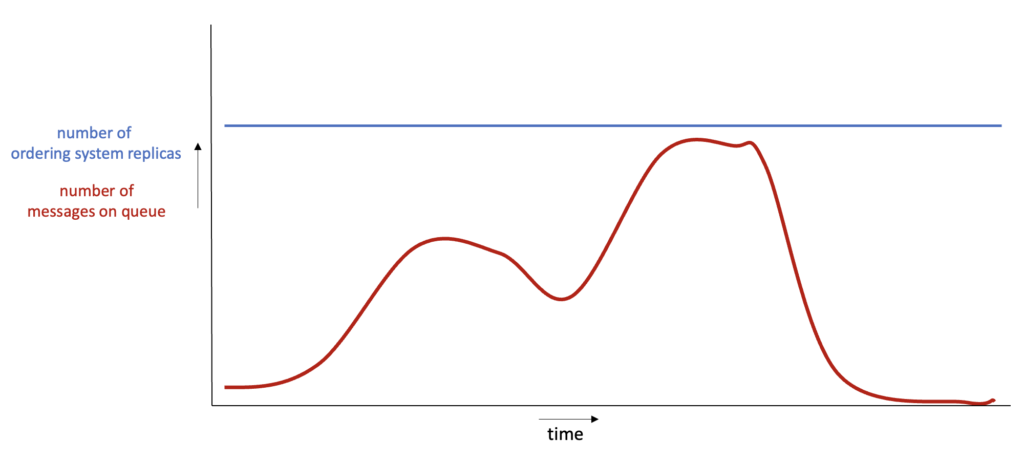
For simplicity, we assume that the replicas and messages at a specific y-coordinate would be exactly in balance, i.e., precisely enough replicas for that number of messages. In that case, the area under the blue and red lines relates to the total and useful resource consumption, respectively. The difference is wasted resources.
The webshop takes pride in its sustainable reputation and also wants to cut back on cloud costs. The webshop owner spoke with customers and learned that while the webserver should always be available and fast, it's okay if the asynchronous email confirmation arrives a bit later.
The webshop owner wants to scale the ordering system based on the queue size and whether clean energy is available. In other words, when carbon intensity is low, and many messages are waiting in the queue, the ordering system can go full speed:
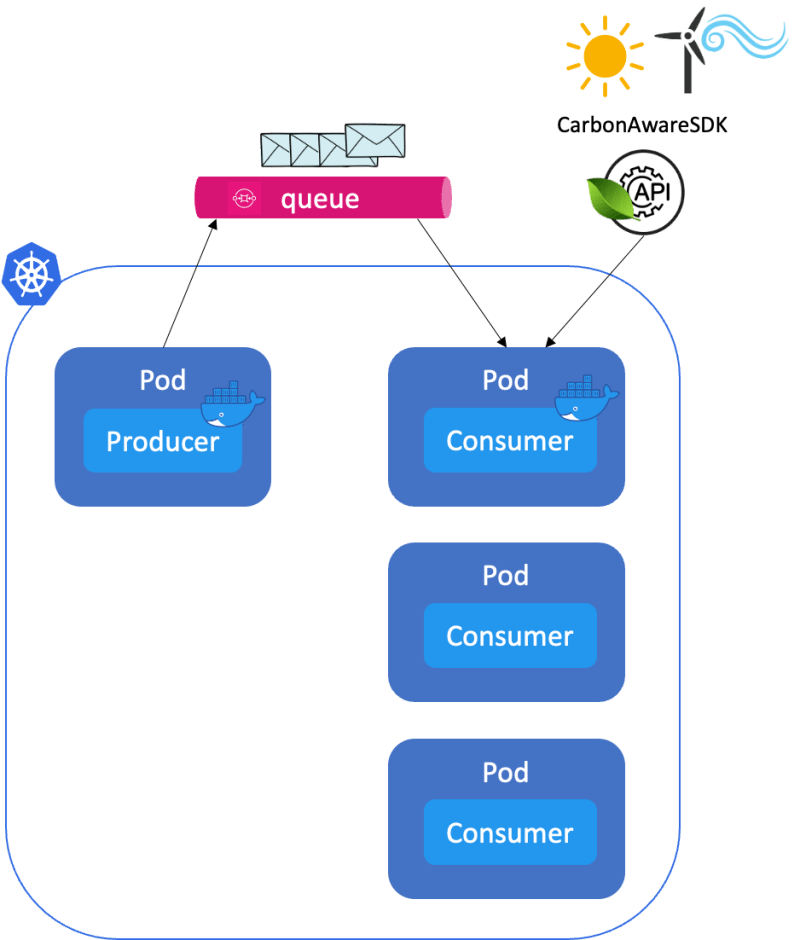
If, on the other hand, either the carbon intensity is high or the number of messages is low, we should balance the number of replicas:
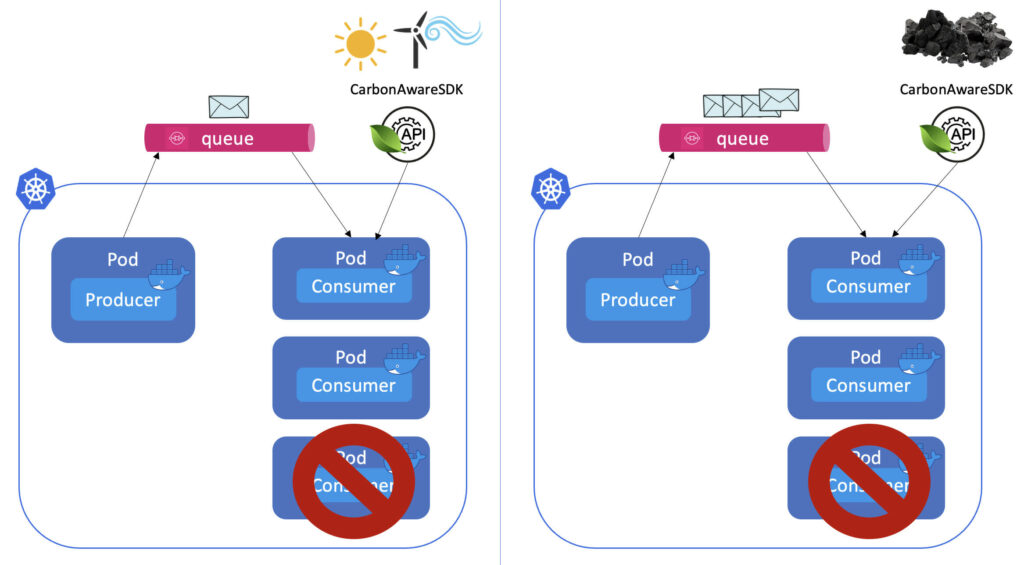
Let's explore how we can achieve this with KEDA.
Event-driven scaling of pods
We want to move away from an always-on ordering system with too many replicas. To dynamically scale the ordering system based on the number of messages in the queue, we use KEDA (Kubernetes Event-Driven Autoscaler), a Kubernetes operator that can scale our application based on 'events'. In our case, 'events' refer to the messages on the queue, but many more events are supported. With the KEDA Controller installed in the cluster, we can dynamically scale the ordering system by creating a ScaledObject:
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: ordering-system-scaler
spec:
scaleTargetRef:
name: ordering-system
pollingInterval: 5
cooldownPeriod: 5
idleReplicaCount: 0
minReplicaCount: 1
maxReplicaCount: 10
fallback:
failureThreshold: 4
replicas: 5
triggers:
- type: aws-sqs-queue
authenticationRef:
name: ordering-system-triggerauth
metadata:
queueURL: <AWS-DOMAIN>/000000000000/ordering-queue
awsEndpoint: <AWS-DOMAIN>
queueLength: "50"
awsRegion: "eu-west-1"
identityOwner: podThe YAML above consists of roughly three parts:
- We must tell the
ScaledObjectwhich application we want to scale. This is done through thescaleTargetRefkey. In this case, the targetordering-systemis theDeploymentthat manages the ordering system replicas. - Then, we configure how we want to scale the application.
minReplicaCountandmaxReplicaCountdetermine the range of scaling, and we can configure many other properties as well. - Finally, we tell which event(s) to scale on in
triggers. Here, we defined the AWS SQS Queue trigger and told it to strive for 50 messages in the queue.
The graph from earlier changes as follows:
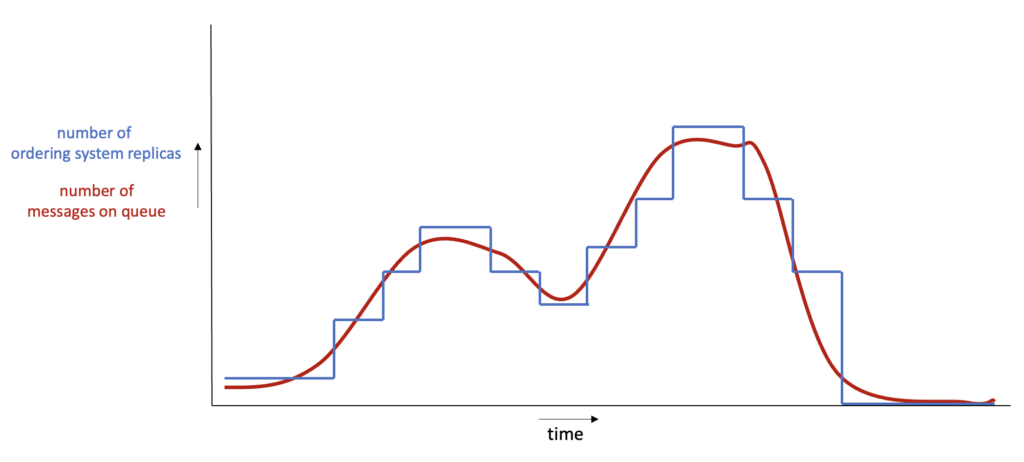 The difference in area under both lines is much smaller now, indicating more efficient resource usage.
The difference in area under both lines is much smaller now, indicating more efficient resource usage.
What I really like about KEDA is that it does not try to reinvent the wheel. Instead, it reuses Kubernetes' built-in HPA (Horizontal Pod Autoscaler). Since Kubernetes 1.10, the HPA can use external metrics based on External Metrics Servers. KEDA 'simply' implements an External Metrics Server that exposes data about the triggers we define in our ScaledObject.
Carbon-aware limits to scaling
With KEDA's event-driven scaling, our resource consumption already changed drastically. Still, the ordering system does not take into account the current availability of clean energy. If the webshop is busier on moments with less clean energy, we can still emit much more than we would like. Let's see how we can add carbon-awareness using the Carbon Aware KEDA Operator. This Kubernetes operator limits how far KEDA can scale our consumer based on the carbon-intensity. This operator essentially sets a ceiling for allowed maxReplicas in KEDA's ScaledObject based on the carbon intensity of the current time, allowing more scaling when carbon intensity is lower. Once the operator is installed, we can configure the scaling limits through a custom resource definition:
apiVersion: carbonaware.kubernetes.azure.com/v1alpha1
kind: CarbonAwareKedaScaler
metadata:
name: carbon-aware-ordering-system-scaler
spec:
maxReplicasByCarbonIntensity:
- carbonIntensityThreshold: 237
maxReplicas: 10
- carbonIntensityThreshold: 459
maxReplicas: 6
- carbonIntensityThreshold: 570
maxReplicas: 3
kedaTarget: scaledobjects.keda.sh
kedaTargetRef:
name: ordering-system-scaler
namespace: default
carbonIntensityForecastDataSource:
mockCarbonForecast: true
localConfigMap:
name: carbon-intensity
namespace: kube-system
key: dataSimilar to how the ScaledObject targeted a Deployment through its scaleTargetRef, this CarbonAwareKedaScaler targets a ScaledObject defined in kedaTargetRef. This makes for a neat layered approach where each layer is unaware of the layer above.
The essential part of the YAML definition above is the maxReplicasByCarbonIntensity key, which lets us configure increasingly strict scaling limits based on the availability of clean energy.
The operator retrieves the current carbon intensity from the ConfigMap we define under the carbonIntensityForecastDataSource key, but actually filling the ConfigMap is not something it can do for you. Fortunately, Microsoft created a companion operator called the Carbon Intensity Exporter, which builds on the Green Software Foundations's CarbonAwareSDK to provide carbon intensity data in the Kubernetes cluster. However, if you just want to play around then you can also set the mockCarbonForecast key to true. The operator will then create a ConfigMap with fake carbon intensity data for testing purposes.
With the Carbon Aware KEDA Operator configured in our cluster, we further decrease our webshop's carbon emissions by doing more when energy is cleaner:
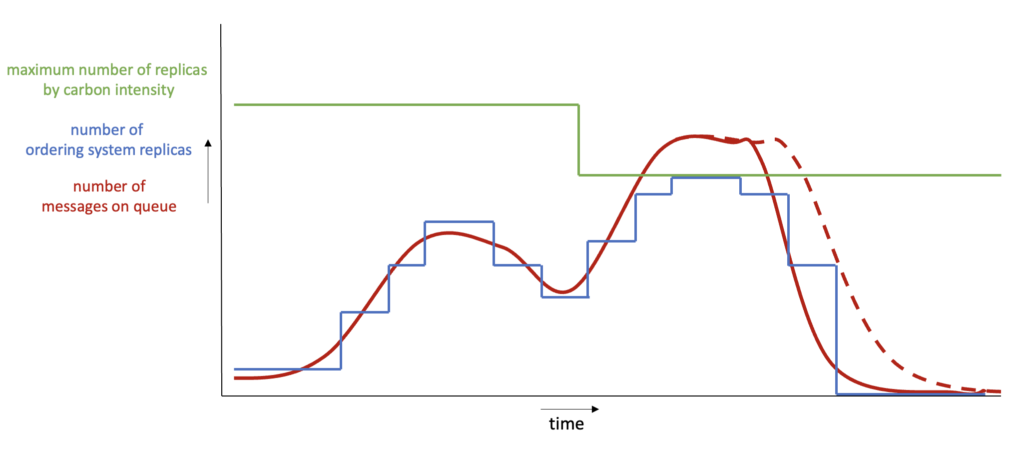
In the second peak, the messages are consumed at a slightly slower pace because carbon intensity is too high at that moment. The customer might need to wait a few more seconds for the confirmation email but likely won't even notice.
Conclusion
Computing significantly contributes to global carbon emissions, and digitalisation shows no signs of slowing down. We should, therefore, become more efficient in our resource usage. This article shows how we can use KEDA to become more event-driven and carbon-aware and reduce overprovisioning of our applications.
Photo by Lucie Hošová on Unsplash
Written by

Bjorn van der Laan
Software engineer at Xebia Software Development
Our Ideas
Explore More Blogs

Embedding Requirement Agents Across Jira, Confluence and Enterprise Agile...
Requirement Agents deliver value far beyond generating superior requirements. When deeply integrated with Jira, Confluence, and Azure DevOps,...
Manoj Sharma



Contact