
Today, we’re exploring another technique that can significantly elevate your software’s quality: Fuzzing. At its core, fuzzing revolves around a straightforward concept: Supply a program with invalid, random, or unexpected input until it encounters a crash.
Understanding the basics
Imagine you’ve developed a program designed to process JPEG images. Now, picture loading a PNG image, a PDF file, a hefty 200MB PowerPoint presentation, or even a file filled with random gibberish. What should the program do? Well, that depends on your program, but a controlled exit with an informative error message (such as “the file you provided is not a valid JPEG image”) seems reasonable. Depending on the file-check implementation, you might reject the PDF file, but the PNG image might sneak through your initial validation since it’s a valid image format. But how does your image decoder, the component responsible for reading and decoding the JPEG binary stream, respond to the bits and bytes of a PNG file? Does it gracefully continue or crash catastrophically? It might survive if it can’t understand the bytes that constitute the file header. However, what if we substitute the PNG file with a corrupted JPEG file? One with a valid file header but random data thereafter?
The potential for errors is vast. While rigorous software development practices like comprehensive automated testing, and even Test Driven Development (TDD), combined with consideration for edge cases, can guard against many issues, there’s always the possibility of unforeseen errors.
This is where fuzzing comes into play, automating the process described above. You specify the program you want to test, and the fuzzing tool hurls randomly generated files at it until it discovers something that triggers a crash. These crash-inducing files can then be manually examined, analyzed, evaluated, and used to rectify the root causes of these crashes. Ultimately, this boosts your product’s quality, particularly when considering vulnerabilities like memory corruption or exploitable buffer overflows.
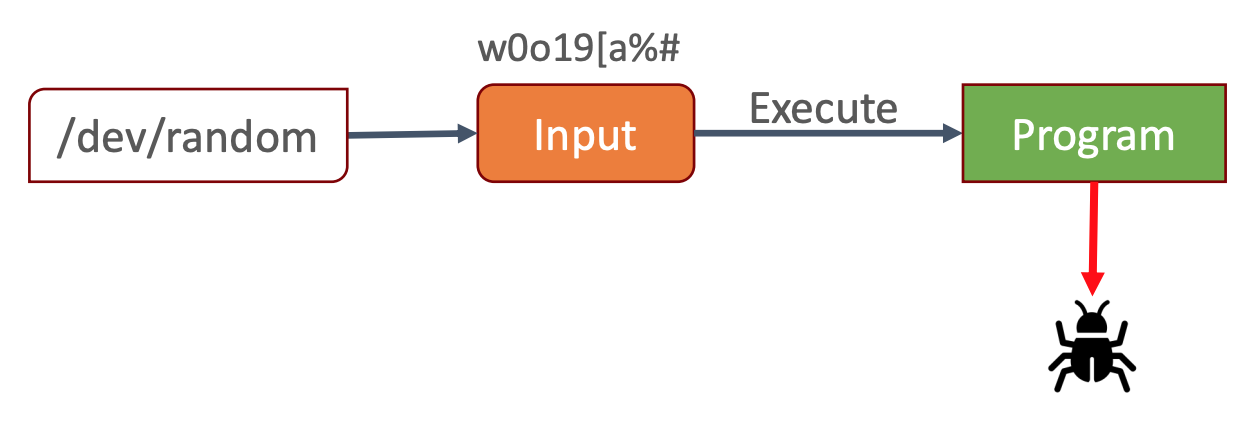
Figure 1: Workload Idea
Challenges with pure random data
Now that we’ve covered the fundamental principle, let’s delve into the first step: generating the files to feed into our program and, more critically, where to obtain them.
The challenge here lies in the fact that we (a) cannot supply the files ourselves, as part of the fuzzing process is uncovering unknown problems, and (b) pure random data is not ideal. Indeed, generating pure random data is straightforward; we could simply read from a random source like /dev/random. However, does it truly assist us? More often than not, pure random data is just noise within the context of our program.
To illustrate, consider Apache Ant, a build automation tool that interprets build definitions from XML files. Replacing the XML file with random bytes would result in chaos:
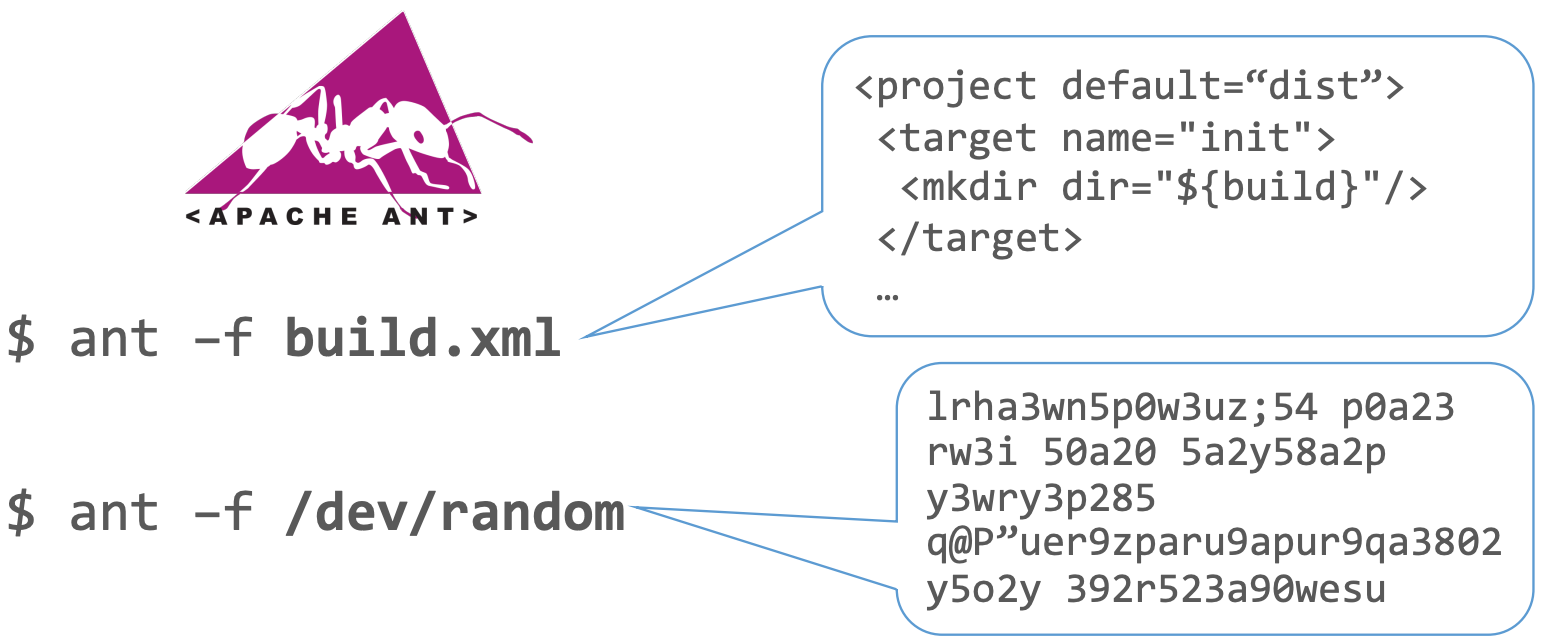
Figure 2: Ant Random
Our random bytes bear no resemblance to valid input. While it’s possible to generate a valid XML file with random bytes, the odds are slim, and we want fuzzing to yield actionable results within a reasonable timeframe. We cannot disregard the runtime of our fuzzing endeavor.
Since random bytes are vastly different from reasonable XML, likely, we’ll repeatedly encounter the same input sanity checks. Is the input a valid XML file? No? Exit early. This cycle would continue, bypassing any business-related code.
However, if we shift our strategy from pure randomness to a slightly “mutated” approach (the attentive reader might notice the relation to Mutation Testing), we end up with something like this:
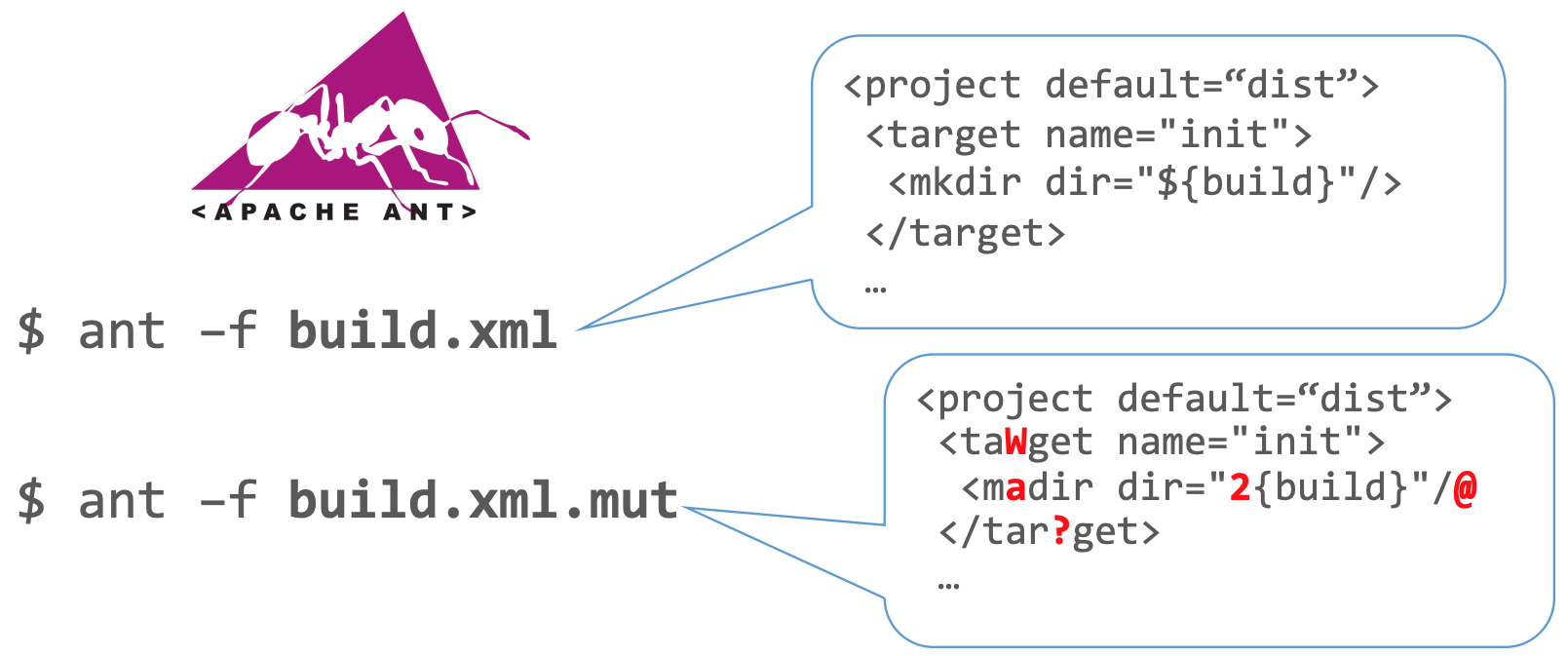
Figure 3: Ant Mutated
Here, things get interesting. Our new input still resembles XML but with minor defects — defects subtle enough to permit entry into deeper parts of our program while still being defects. Consider that you’ve written code responsible for handling a specific XML node, so that <mkdir dir="foo" /> creates a directory named "foo".
Where do you register this new action? Perhaps in a global lookup table where you assign your action callback function to the name mkdir? Excellent. This central registration point simplifies action definition and registration.
But how does our program handle access to this global hashtable? Does it handle it gracefully when trying to retrieve the callback function for an unknown action name? Or does it produce an out-of-bounds error because no one has ever tested it with invalid or unknown action names?
This illustrates that slightly mutated data is far more effective than pure random data. With a single, minor mutation, our build definition was able to trigger an invalid action (madir, just a single-character error away from the valid mkdir).
Tracking progress
We’ve established that mutated data surpasses pure randomness. But how do we gauge our progress? When do we decide that we’ve made enough attempts with mutated data? The theoretical space of possible function calls is seemingly infinite.
Wouldn’t it be fantastic to somehow peer into the program we’re testing, even briefly, to observe our progress? How deeply have we delved into the program with our mutated input?
This is precisely what coverage-guided fuzzing does. To implement this, we need a special build of our program with some instrumentation added. This instrumentation doesn’t affect the program’s behavior; it merely enables the fuzzing tool to monitor execution paths.
Now that we can track execution paths, we can assess our mutated input. This capability is crucial because it enables us to create a positive feedback loop, automatically steering us deeper into the program, thereby reaching more code with our malicious input. How does it work? Let’s examine the process:
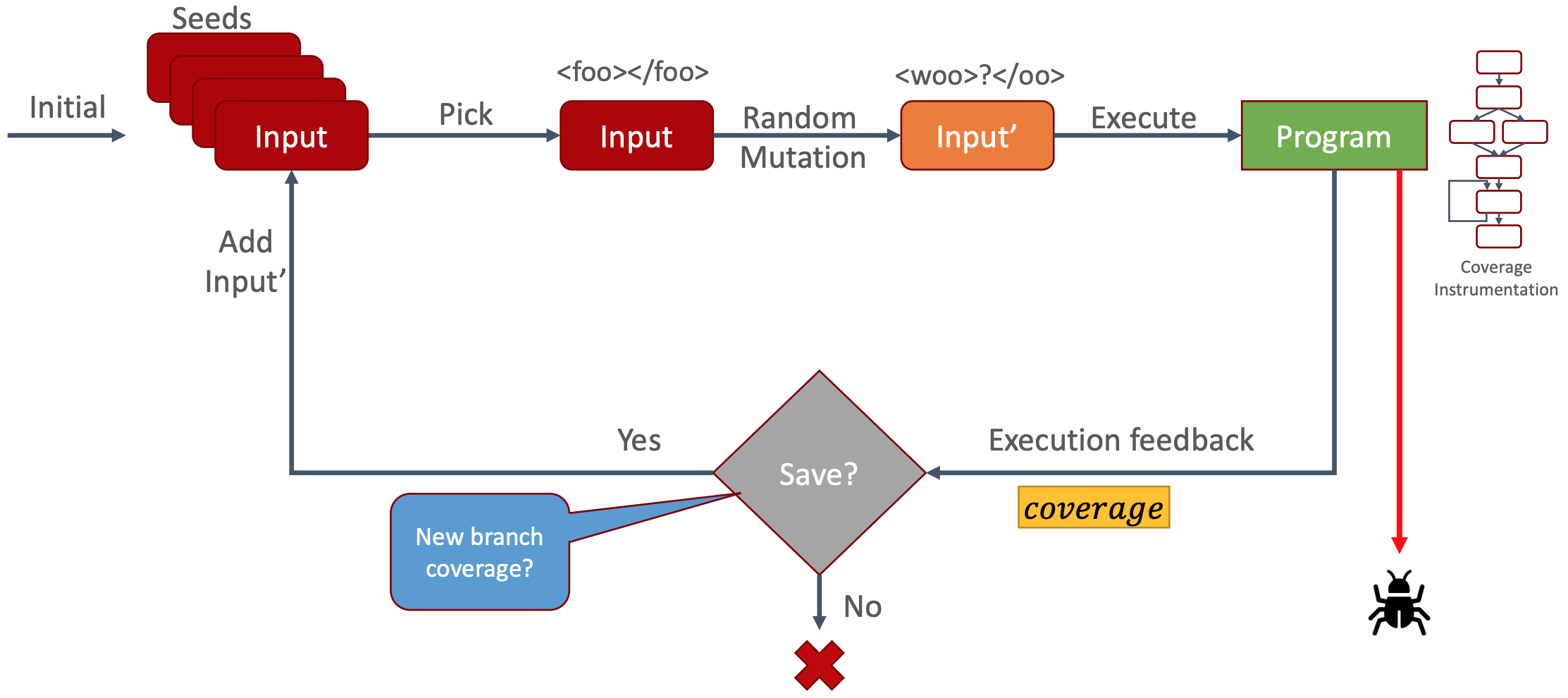
Figure 4: Full Workflow
- Initialize and prepare some seed files, which can include entirely valid files like a functional Ant build XML file.
- The fuzzing tool selects one of the seed files.
- It applies a random mutation to the chosen file.
- The mutated file is then passed to the program for testing.
- Did it crash? If yes, we’ve discovered something, and we report the input file that caused the crash.
- If no crash occurs, we examine the execution path (thanks to the instrumentation code).
- Did we traverse previously unexplored paths? If yes, we add the input file to our collection of seed inputs.
- If not, we can simply discard everything.
This loop repeats continuously, but Step 7 is the crucial one. Consider this for a moment: Every input file that leads to new execution paths within the program is added to our seed collection.
This process resembles evolution. A “first-generation” mutated input file might just “get its foot in the door”. By reintroducing it into the seed collection, it has the opportunity to create a “second generation”. This second-generation input file could progress further, perhaps fully infiltrating the program. We’re essentially evolving through mutation and failure.
Automating the process
Up to this point, we’ve discussed theory. But how can we put this into practice? Do we need to build everything from scratch, or can we use existing tools? Enter AFL and SharpFuzz. Both open-source tools make fuzzing in C# a straightforward process.
AFL (American Fuzzy Lop) is considered the de-facto standard for fuzzing and enjoys widespread use. It has detected numerous significant software bugs in major applications such as OpenSSL, bash, Firefox, and SQLite. AFL is also widely used in academia, as academic fuzzers are often forks of it, and AFL is commonly used as a baseline to evaluate new techniques.
SharpFuzz extends the power of AFL to .NET. It’s a lightweight library that facilitates the addition of the required instrumentation code (enabling AFL to work with .NET) and provides functions to simplify setup.
With both tools at your disposal, you don’t need to concern yourself with the intricacies of fuzzing logic. Instead, you can focus on your code.
What to target
The final aspect to grasp is that fuzzing is versatile — you can target virtually anything. It doesn’t have to be your entire application. Imagine you’ve created a Windows desktop app that can render HTML, and you want to use fuzzing to fortify this rendering process. But it’s tucked away within layers of menus and buttons! Do you now need to “fuzzy-navigate” through the entire user interface?
Absolutely not. Sure, from AFL’s perspective, it’s simply an executable binary receiving mutated input files. You can effortlessly create a small fuzzing harness, like this:
public class Program
{
public static void Main(string[] args)
{
Fuzzer.OutOfProcess.Run(stream => {
try {
new HtmlParser().Parse(stream);
}
catch (InvalidOperationException) {
// Whitelist known or "good" exceptions
}
});
}
}Here, HtmlParser represents the HTML parsing library you wish to test. With SharpFuzz’s assistance, creating a dedicated fuzzing harness is straightforward.
Notable here is the InvalidOperationException that we catch. From AFL’s perspective, any program crash is flagged as “erroneous behavior” and tracked as a potential error. However, this isn’t the case for InvalidOperationException. This exception serves as HtmlParser’s way to signal the caller that it encountered something it couldn’t parse. To prevent AFL from flagging this as a false positive, we catch and whitelist this exception.
With the fuzzing harness in place, you only require a single seed input file, which can be a perfectly valid file like this concise HTML snippet:
<!DOCTYPE html><html><body><h1>h1</h1><p>p</p></body></html>Now, you can direct AFL at your program and let it work its magic:

Figure 5: American Fuzzy Lop
While the output might seem overwhelming, it’s a screenshot of the AFL Command Line Interface (CLI) output, an interactive Text User Interface (TUI) that allows you to monitor and follow progress in real-time. It provides vital information, including:
- Total run time (top left)
- Total unique paths discovered by AFL (upper right)
- Total program executions (middle left)
- Program executions per second (middle left)
- Mutation strategies applied by AFL (lower left)
This interface allows you to closely observe AFL’s execution, and at some point, AFL might uncover a crash! You can then examine the file AFL generated:
<svg><!DOCTYPE html><<template>html><desc><template>><p>p</p></body></html>Success! We’ve found malicious input capable of crashing our HtmlParser. Now we can debug this issue, create a unit test to prevent future regressions and apply standard development practices.
Creating images out of thin air
We’ve witnessed AFL mutate our simple HTML input sufficiently to trigger a crash in the HtmlParser. But how capable is AFL? How far can it stretch its abilities? In short, quite far!
I stumbled upon this intriguing article by Michal Zalewski, where he detailed how AFL was able to generate valid JPG files seemingly out of thin air:

Figure 6: Thin Air
Admittedly, these are not aesthetically pleasing images, but they are unquestionably valid JPG files. All created by AFL as it diligently mutated its way through a JPG decoding tool.
Conclusion
Fuzzing is an engaging adventure that can uncover bugs in your program. Importantly, it isn’t limited to end-user applications. With a dedicated fuzzing harness, you can isolate individual functions or entire libraries and direct AFL to them.
However, due to its generative nature, it’s essential to be mindful of runtime. Fuzzing will invariably be slower than unit tests. Therefore, consider it a complementary tool. Unit tests verify the known paths, but fuzzing excels at discovering the unknown paths!
This article is part of XPRT. Magazine #15 Download here

Written by

Michael Contento
Our Ideas
Explore More Blogs




Contact