
Infrastructure as Code (IaC) codifies the provisioning of infrastructure. This way it can take advantage of software engineering best practices to produce faster and consistent deployment of infrastructure. One of the leading IaC software tools is Hashicorp’s Terraform and with the return of Hashiconf to Amsterdam I decided to share my personal recommendations on how to better structure your Terraform projects! In this blog I will give four tips that I have learnt through using Terraform in the field, but before that let’s first get started with creating a shared understanding of Terraform.
Getting a shared understanding of Terraform
Terraform is a vendor agnostic IaC software tool, meaning that it can be used to provision services from various vendors through so called providers. This is unlike tools such as AWS CloudFormation or Azure Resource Manager templates which only work for a single vendor. Popular Terraform providers are used for cloud providers like AWS, Azure and GCP; open source tooling like Kubernetes and Helm; enterprise tooling like Salesforce and Snowflake; and more!
To define infrastructure with Terraform, code is written that provisions resources using Terraform providers. The code is currently solely written in Hashicorp’s domain specific language named HCL, but soon it will support common programming languages through the in preview CDKTF! During deployments the Terraform code is then via the aforementioned providers converted to API calls of the specific vendor to provision the resources.
Terraform keeps track of the metadata for all the provisioned resources in a specific state file. Before every Terraform deployment that is performed (using terraform apply) the state is refreshed, meaning that all the deployed resources their metadata is retrieved and compared to the state file to determine which changes to the infrastructure should be made. Terraform is one of the few IaC software tools that utilizes state files and while it makes Terraform simple and performant, maintaining the state does bring its own set of challenges (as will become clear in this blog).
Tips for working with Terraform
While it is easy to start using Terraform in a “Hello world” setting, it quickly becomes challenging when applying Terraform to real-world systems that contain multiple resources. In these situations I always apply the following opinionated structure:
1. Use Terraform workspaces to separate environments
Every environment should have its own state file: so for a DTAP street a separate state is required for the development, test, acceptance and production environment. Terraform offers two ways to handle the situation of a separate state file per environment:
- Individual state files: one Terraform backend per environment:
- Terraform workspaces: one “shared” Terraform backend for all environments
For different environments I recommend using Terraform workspaces. Switching between environments when using workspaces is less hassle compared to individual state files: fast and simple terraform workspace select versus a slow terraform init that requires additional user input for the backend configuration as well. Moreover, workspaces enable environment specific logic in the Terraform code via the terraform.workspace variable which is a convenient way to distinguish between resource settings in different environments.
2. Prefer multiple smaller states instead of one large state
While it is convenient to store all resources for an environment in a single, monolithic state file, I am advocating against this because of:
- Slow Terraform operations
The most important Terraform operations (
terraform plan/apply/destroy) refresh the state file. As the number of resources tracked in the state file grows, the time to refresh a state file increases. While Terraform applies concurrency to minimize this refresh time, it is dependent on (rate-limited) APIs to get the necessary metadata. So the fewer resources that are tracked in a single state file, the better.
- Less control over deployments Tracking too many resources in a state file does not easily allow for fine-grained control over deployments, such as the partial (re-)deployment or destruction of resources. Moreover, by using smaller deployments instead of a single larger deployment the resource state is not refreshed by Terraform unless it is really necessary, preventing the introduction of (spurious) errors.
- Large blast radius: The state file is the single source of truth for resources provisioned with Terraform. If the complete infrastructure state is tracked in a single state file one error (e.g. accidental terraform destroy or state file corruption) puts the entire system at risk.
To not suffer from these issues I am instead opting for multiple smaller state files, one for every logical component. For a simple web app (see Figure 1) this would result in separate state files for for example the virtual network, database and app. In this situation the state files will be loosely coupled, since by default the state file in one directory is not aware of the resources in state files of other directories. If this information is desired the resource information can be imported through Terraform data sources.
[caption id="attachment_55675" align="aligncenter" width="550"]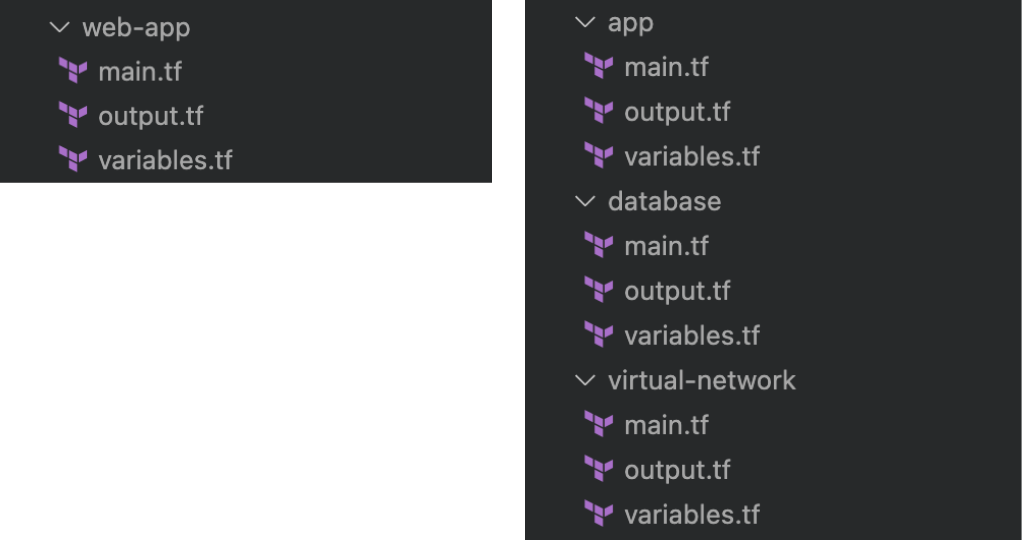 Figure 1: Left: Terraform setup with a monolithic state file, right: Terraform setup with multiple smaller state files[/caption]
Figure 1: Left: Terraform setup with a monolithic state file, right: Terraform setup with multiple smaller state files[/caption]
3. Give Terraform files logical names
Terraform tutorials online often demonstrate a directory structure consisting of three files:
main.tf: contains all providers, resources and data sourcesvariables.tf: contains all defined variablesoutput.tf: contains all output resources
The issue with this structure is that most logic is stored in the single main.tf file which therefore becomes pretty complex and long. Terraform, however, does not mandate this structure, it only requires a directory of Terraform files. Since the filenames do not matter to Terraform I propose to use a structure that enables users to quickly understand the code. Personally I prefer the following structure (see also Figure 2):
provider.tf: contains the terraform block and provider blockdata.tf: contains all data sourcesvariables.tf: contains all defined variableslocals.tf: contains all local variablesoutput.tf: contains all output resources- A file name per component, for our simple web app the storage directory would for example contain files such as
database.tfandpermissions.tf. These names are more descriptive thanmain.tfand immediately tell what kind of resources are expected there.
[caption id="attachment_55674" align="aligncenter" width="695"]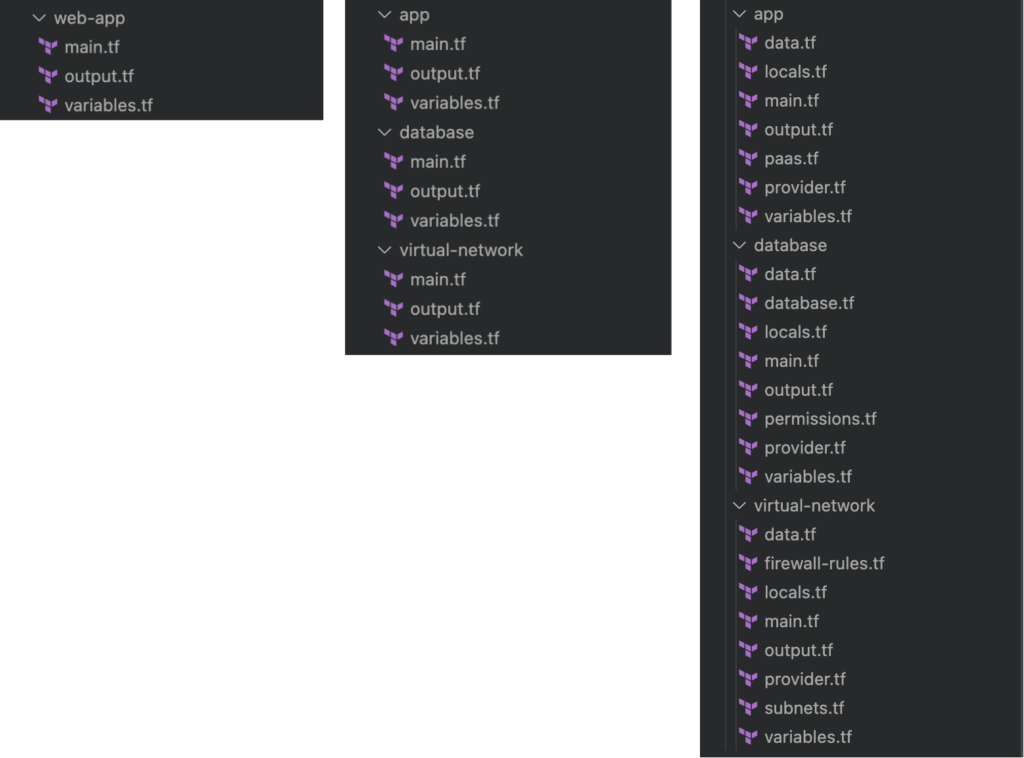 Figure 2: Left: Terraform setup with a monolithic state file and a monolithic
Figure 2: Left: Terraform setup with a monolithic state file and a monolithic main.tf, center: Terraform setup with multiple smaller state files and a monolithic main.tf, right: Terraform setup with multiple smaller state files and smaller Terraform files[/caption]
4. Locals are often sufficient
Terraform allows user-defined input in two ways:
- variable blocks: should be used for values that are not known beforehand, such IDs that are defined at runtime.
- Local blocks: should be used for values that are known beforehand, but are good to abstract as variables, such as constants.
In my experience most of the user-defined input for Terraform can be captured by locals and this significantly simplifies the Terraform codebase. Moreover, locals do not require passing values in *.tfvars(.json)files for a terraform apply making deployments simpler.
A bonus tip I would like to give is the usage of local blocks together with YAML files. Defining extensive mappings in HCL is quite verbose and I find them difficult to read, but with the yamldecode function these mappings can be stored in the more readable YAML format and be imported into Terraform.
[caption id="attachment_55676" align="aligncenter" width="763"] Figure 3: Define a mapping in a locals block using HCL (left) and YAML (right)[/caption]
Figure 3: Define a mapping in a locals block using HCL (left) and YAML (right)[/caption]
Conclusion
Terraform is a popular Infrastructure as Code software tool that is vendor agnostic and makes use of state to track resource metadata. Getting started with Terraform is easy, but applying it to real-world systems is hard. Therefore I always apply the following principles:
- Use Terraform workspaces to separate environments
- Prefer multiple smaller states instead of one large state
- Give Terraform files logical names
- Locals are often sufficient
What are your thoughts on these principles? Any tips for an even better setup? Share your thoughts in the comments below!
Written by
Avinash Pancham
Our Ideas
Explore More Blogs




Contact