
Tip of the Iceberg
When we think of data, we usually tend to think of tables, nicely structured into rows and columns. But by far the most information is captured in unstructured data types. Think about e-mail, PDFs, but also images and videos. These formats were designed such that the data in them can be interpreted by humans. But this also makes it very difficult to use the contained information for other purposes, such as machine learning, building dashboards and reporting. In order to extract insights/value from that data, we need to structure it first. But what do we mean with structuring? How do we turn PDF and image into rows in a table?
First, we need to define what information we would like to search for in these files. What data points do we want to extract from them? Are they categorical or continuous? And are they strings, integers, booleans or something else? Then we need a mechanism that takes this wish list, and extracts the items from the file. From a technical perspective, this is the hard part. For each modality (fancy word for the type of data, i.e. image/text/video), the mechanism will be very different. For text formats, large language models are a feasible candidate to play this role. But there are also less complex and less expensive alternatives which might work just as well, depending on how ambitious your wish list is.
Example
Let's go through an example that's close to home: a data consultancy company. The sales staff uses CRM software to keep track of the sales process. A lot of interesting information can be extracted from those deals. Which engineering roles are required for the project? Are certain technologies in high demand right now? What about the FTE and project timelines? Answering these questions could help to make data-driven decisions about the hiring strategy, training programs and maybe even the sales process itself.
Let's say we can export a deal to a PDF file. The PDF contains the following information:
Name: Project W
Company: Umbrella Corporation
Activities:
2025-01-01: Call with the leadership team at Umbrella Corporation to discuss project requirements. Every fall, they experience an unexplainable surge in demand for their storm-proof umbrellas. To manage stock levels, they would like to build a model that can forecast the demand for this product.
2025-01-15: Follow-up meeting with the data science lead to discuss the project proposal. The project will require a data scientist and a machine learning engineer on a full-time basis. The development is expected to take 6 months, just in time for the next fall season. The project will start on 2025-02-01.
We would like to extract the following information: - Company name - Use case - FTE - Start date - Project fit
The reason why the above five fields are extracted is because for a data consultancy company, we would like to know which use case is for what company, how many people are needed from which start date, and whether this project is a nice fit.
As an english-speaking human being, you will get the following extraction: - Company name: Umbrella Corporation - Use case: Demand Forecasting - FTE: 2 - Start date: 2025-02-01 - Project fit: High
Easy enough, right? Sure, the company name seems straigthforward, it's preceded by the word 'Company' and its value is right after that. The others are more tricky, and require some understanding of the context. We will explore this later on.
When we do this for all the deals in our CRM, we can form a table. Each row represents a deal, and we will have five columns: Company name, Use case, FTE, Start date and Project fit. This table can then form the basis for further analysis. For example, we can count the number of deals per use case in the past year, or calculate the average FTE per deals.
Terminology
Before we dive into the details, let's define some terminology that we will use throughout this and subsequent blogposts on this topic.
- Source: The unstructured data that we want to extract information from. This can be a PDF, an image, a video, etc. In the example above, the source is the PDF file.
- Extractor: The mechanism that extracts information from the source. In the example above, the extractor it was you, the human reader.
- Extraction: The combined set of information that was extracted from a single source. It corresponds to a row in the table we mentioned earlier.
- Evidence: The part of the source that contains the information we want to extract. This can be a sentence, a paragraph, a bounding box in an image, etc.
Three levels of extraction
On the spectrum from easy to hard, there are three levels of extraction: 1. Exact match: The answer exists literally in the context. 2. Deduction: The answer needs to be deduced from the context. 3. Reasoning: The answer needs reasoning based on the context.
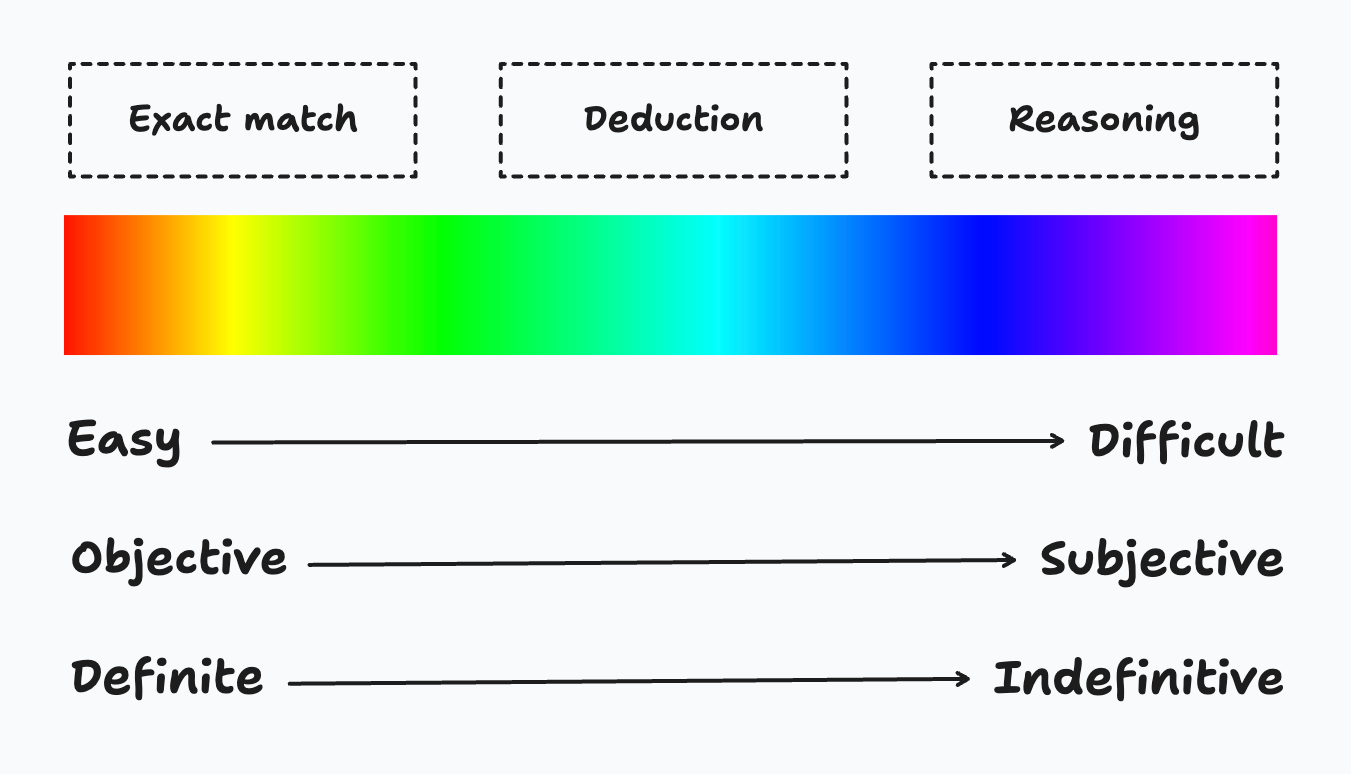
The harder it is to extract the answer, the answer also becomes more subjective and indefinite to evaluate its accuracy.
Let's see how the previous example falls into the above three categories. - Company name: Exact match -> The name directly comes after "Company:". - Use case: Deduction -> It is stated in the source that "they would like to build a model that can forecast the demand". - FTE: Deduction -> A data scientist and a machine learning engineer are needed full-time. By summation, it is two. - Start date: Deduction -> There are several dates listed in the source: "2025-01-01", "2025-01-15" and "2025-02-01". Only "2025-02-01" is the start date of the project. - Project fit: Reasoning -> The text does not provide a direct answer. However, by analyzing the details of the deal and understanding the strengths of the data consultancy firm, it is possible to reason whether the project would be suitable.
Tooling
The extraction problem is never new to us, we keep tackling it with various methods. From old to new tools in the extraction arsenal, there are plain old Regular Expression (RegEx), Named Entity Recognition (NER) and Large Language Model (LLM).
Let’s go back to our previous example to see which tool can be used to extract which information. - Company name: NER -> "Company name" is the named entity to be extracted. - Use case: LLM -> NER models can be trained to extract use cases, but here a summary of a long text is required. - FTE: LLM -> It needs summation. - Start date: NER or LLM -> NER might extract three dates. LLM can understand context better. - Project fit: LLM -> It needs reasoning.
To map these three tools to the three levels of extraction, it now looks like this!
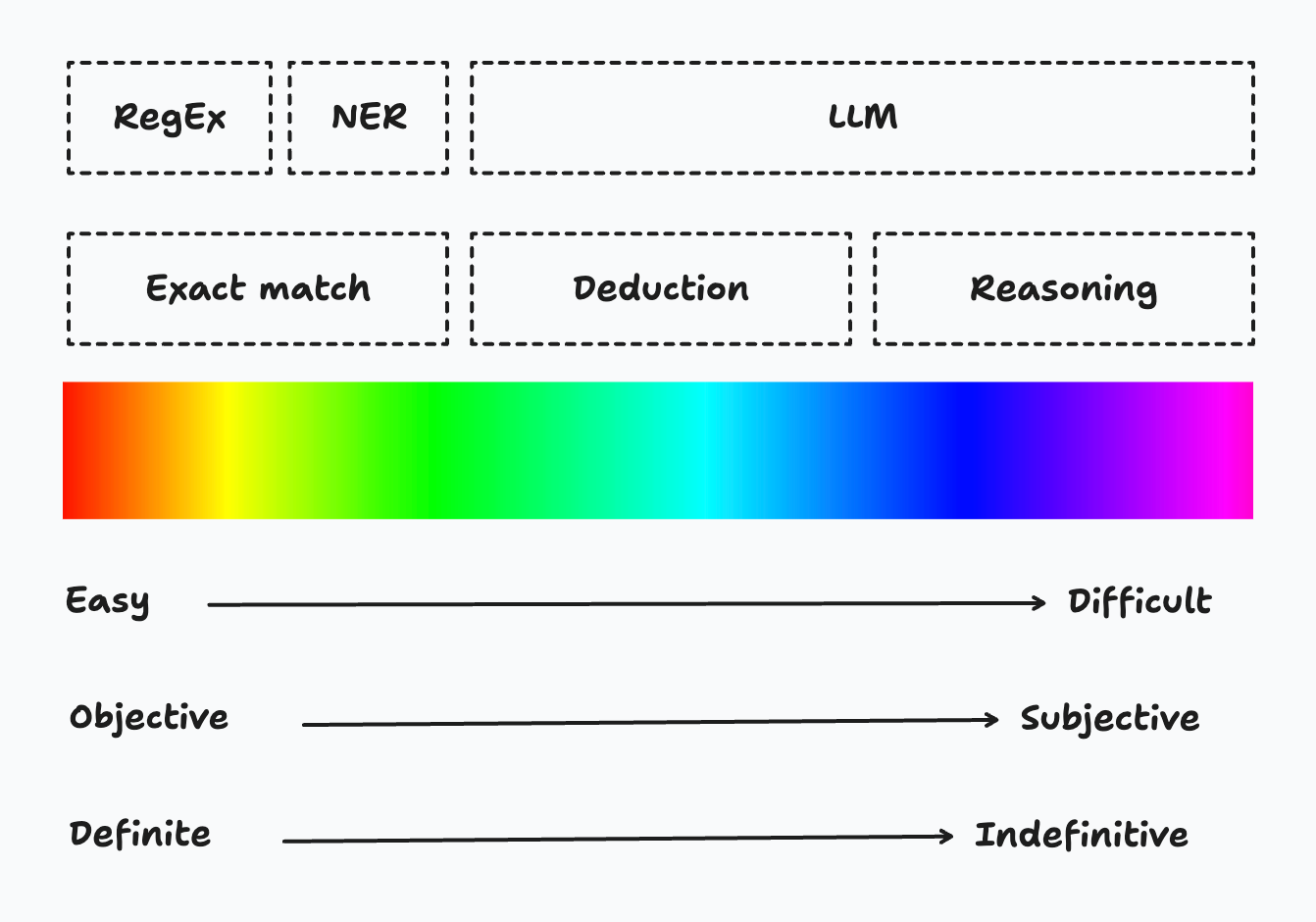
Let’s dip into the pros and cons of these three tools in detail.
| Tool | Pros | Cons |
|---|---|---|
| RegEx |
|
|
| NER |
|
|
| LLM |
|
|
Existing tools
There are already some implementations of the above tools ready-for-use.
Instructor is a open-source Python library, which can use almost any models of your choice, ranging from OpenAI GPT models, Google Gemini models to open-source models including Mistral/Mixtral, Ollama, to get structured data. You can use Instructor to build your own data pipeline.
Trellis AI is a SaaS product, which can extract structured data from documents, including PDFs, XLSX, images, slides, and DOCX. It supports data source and destination integration, e.g., building data pipeline from S3 to PostgreSQL.
Databricks ai_extract function is available in Databricks notebooks and SQL queries, leverages a large language model (LLM) to facilitate data extraction. This function allows users to specify only the names of the fields to be extracted, with no additional configuration options available for the extraction process.
But what's next after the data are extracted, structured and stored? A critical piece is evaluation. Out of a host of model options and configurations, we need to know how well they perform.
What is next?
In the next article, we will deep dive into evaluation. What is evaluation? Why is evaluation needed? How can we evaluate LLM extractions?
Written by
Shu Zhao




Contact