Blog
Ducklake: A journey to integrate DuckDB with Unity Catalog

This summer, Databricks announced the open-sourcing of Unity Catalog. This creates the opportunity for combining lightweight tools like DuckDB with Unity Catalog. In this post, we’ll dive into how you can integrate DuckDB with the open-source Unity Catalog, walking you through our hands-on experience, sharing the setup process, and exploring both the opportunities and challenges of combining these two technologies.
Why Integrate DuckDB with Unity Catalog?
DuckDB is an in-process analytical database designed for fast query execution, especially suited for analytics workloads. It’s gaining popularity due to its simplicity and performance – currently getting over 1.5 million downloads per week. However, DuckDB doesn't provide data governance support yet.
Unity Catalog gives you centralized governance, meaning you get great features like access controls and data lineage to keep your tables secure, findable and traceable. Unity Catalog can thus bridge the gap in DuckDB setups, where governance and security are more limited, by adding a robust layer of management and compliance. Vice versa, for companies using Unity Catalog as their governance solution, DuckDB may not yet be a feasible option.
All in all, for both DuckDB users and Unity Catalog users, this integration is a win-win.
As we're combining data lakehouse technology with DuckDB, we call our solution DuckLake. In this blog, we'll explore how all of this works
Ducklake
In this section, we show how we created the integration with DuckDB and Unity catalog. We'll address the current limitations and discuss the workaround for adding write support. In addition, we show our local setup using Docker Compose.
Limitations (and opportunities!)
There are a few limitations to be aware of, but these are evolving fast, and solutions are already on the horizon.
-
Unity Catalog Authentication: At the time of initial development we used Unity Catalog 0.1.0. This version did not include Role-Based Access Control (RBAC) yet. Since then, support for this was added in Unity Catalog 0.2.0, making our setup even more powerful. In the upcoming series, we’ll be able to demonstrate how to set it up—so stay tuned for that future post.
-
Read-Only Delta Support: Currently, DuckDB can only read from Unity Catalog, because of its dependency on
delta-kernel-rs, which limits operations to read-only. The DuckDB team is actively working on write support, and it’s definitely on their roadmap. In the meantime, we’ve developed a workaround to help you write to Unity Catalog, so you can keep moving forward even before native support arrives. -
Motherduck Integration: Motherduck offers a managed DuckDB experience, but unfortunately does not yet support uc_catalog extension, that doesn’t stop us! To get similar notebook integration, we have built a solution using Jupyter notebooks, a web-based tool for interactive computing.
To address the lack of write support in DuckDB, we created a unity plugin for the dbt-duckdb library. Dbt is a popular tool for transforming data in a data warehouse or data lake. It enables data engineers and analysts to write modular SQL transformations, with built-in support for data testing and documentation. This makes dbt a natural choice for the Ducklake setup.
Additionally, we created a Jupyter Kernel library, dunky, which enables writing to Unity Catalog directly using SQL.
Here's a schematic overview of the integration using dbt and Jupyter: 
Write workaround
The workaround involves the following steps:
- Convert DuckDB query results into an in-memory Apache Arrow Table.
- Convert the Arrow Table schema into a Unity Catalog schema using the pyarrow-unity library.
- Writing the table involves:
- Creating a Unity Catalog table.
- Writing the in-memory Arrow table to a Delta table.
Here’s a schematic overview of this write workaround:
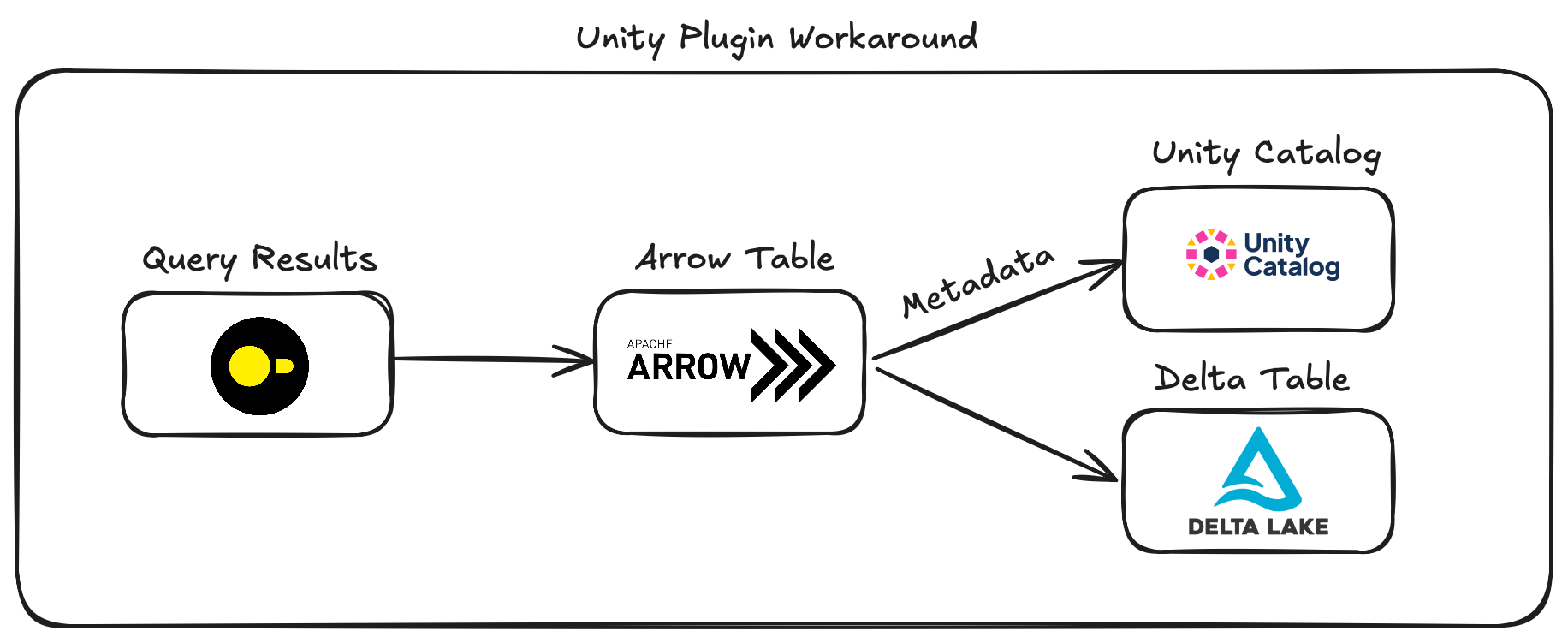
While effective, this workaround will never be as efficient as a native DuckDB solution. Converting DuckDB query results to an Arrow table introduces extra steps. For instance, DuckDB has to map its internal data structure such as vectors and chunks to Arrow's columnar format. This means that each column is converted to an Arrow array and each data type such as INTEGER and VARCHAR are mapped to Arrow data types (e.g., pa.int32() and pa.string()). Luckily, DuckDB’s built-in support for Apache Arrow makes this conversion efficient and seamless.
Docker Compose Setup
Docker is a platform that allows developers to package applications and dependencies into containers. We’ll use Docker Compose to manage and run the services (Unity Catalog, Jupyter, etc.) locally. Here is an overview of the Docker compose setup:
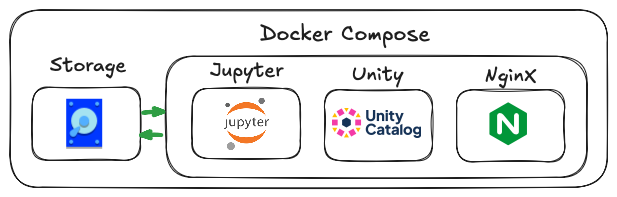
We use Docker Compose to host four services:
- Unity Catalog: Running version 0.1.0, the Docker image is sourced from godatadriven dockerhub.
- Unity Catalog UI: A web UI for browsing the catalog.
- Jupyter: Enables interaction with dbt models and querying Unity Catalog. We use a minimal Jupyter image from quay.io. During build we add the dbt-duckdb with the unity plugin.
- Nginx: A reverse proxy allowing external services to communicate with Unity Catalog API. This enables Jupyter’s Unity Catalog sidebar extension, junity, to fetch tables.
Jaffle Shop Demo
To demonstrate our setup, we’ll use the jaffle_shop example. Jaffle shop is a fictional e-commerce store often used for dbt demos. This dbt example transforms raw data into customer and order models.
You can find all example material used in this blog here
Configuration
We define the following in the profiles.yml:
jaffle_shop:
outputs:
dev:
type: duckdb
catalog: unity
attach:
- path: unity
alias: unity
type: UC_CATALOG
extensions:
- name: delta
- name: uc_catalog
repository: http://nightly-extensions.duckdb.org
secrets:
- type: UC
token: 'not-used'
endpoint: 'http://uc:8080'
aws_region: 'eu-west-1'
plugins:
- module: unity
target: dev
This config attaches DuckDB to Unity Catalog and sets up the necessary extensions and secrets. Additionally, for model definitions:
{{ config(
materialized='external_table',
location="{{ env_var('LOCATION_PREFIX') }}/customers",
plugin = 'unity'
)
}}
We specify external_table materialization and a storage location (local or cloud, like AWS S3).
Deploying the Setup
docker compose up --build -d
After the services are up and running, the Jupyter interface is accessible at http://localhost:8888/lab?token=ducklake and the Unity Catalog UI at http://localhost:3000. As expected, the example tables will be visible in the Unity Catalog UI.
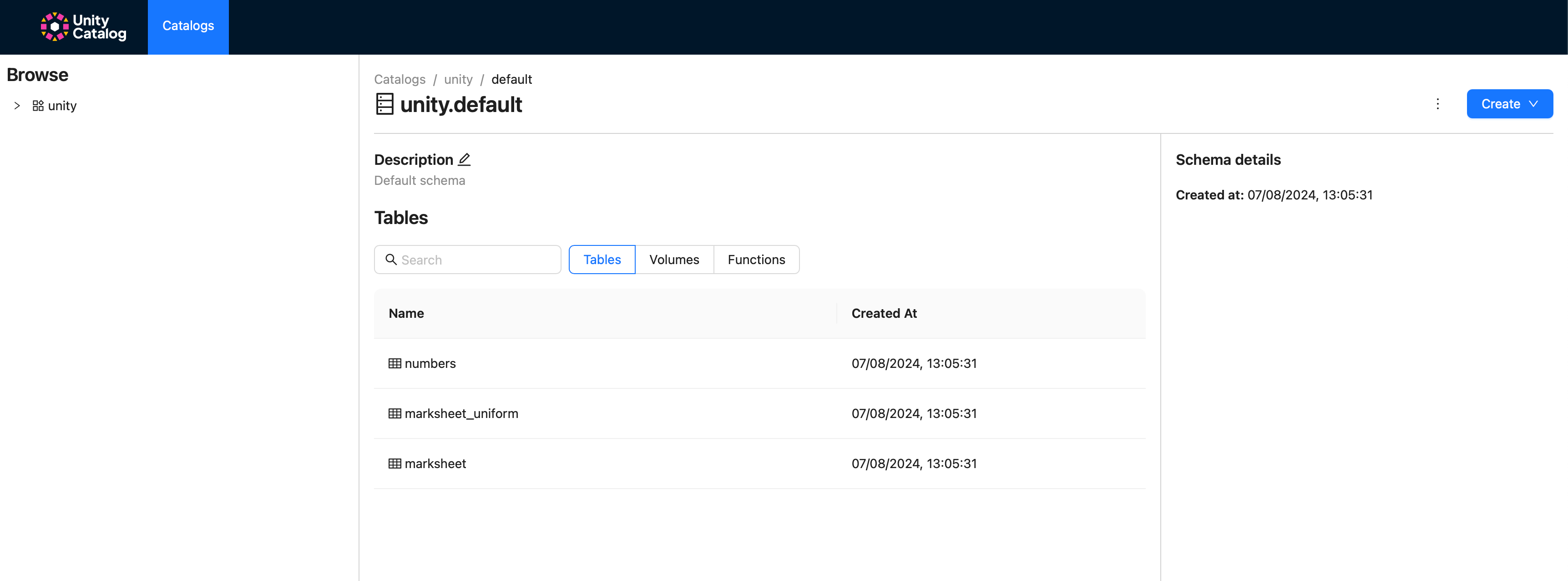
Running DuckDB against Unity Catalog
With the setup running, we can build the dbt models. 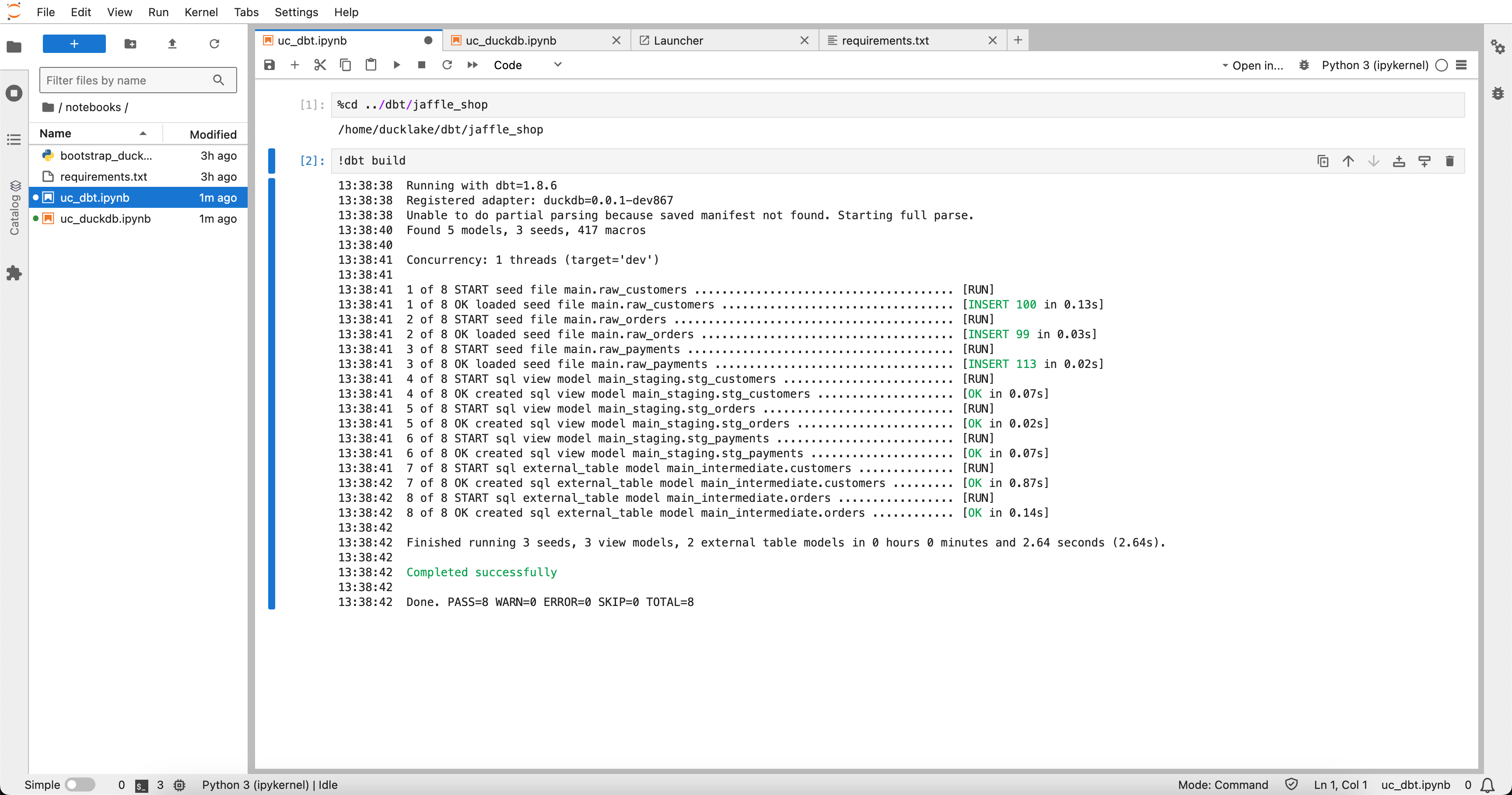 Success! The dbt models are built, and we can now query the tables interactively.
Success! The dbt models are built, and we can now query the tables interactively.
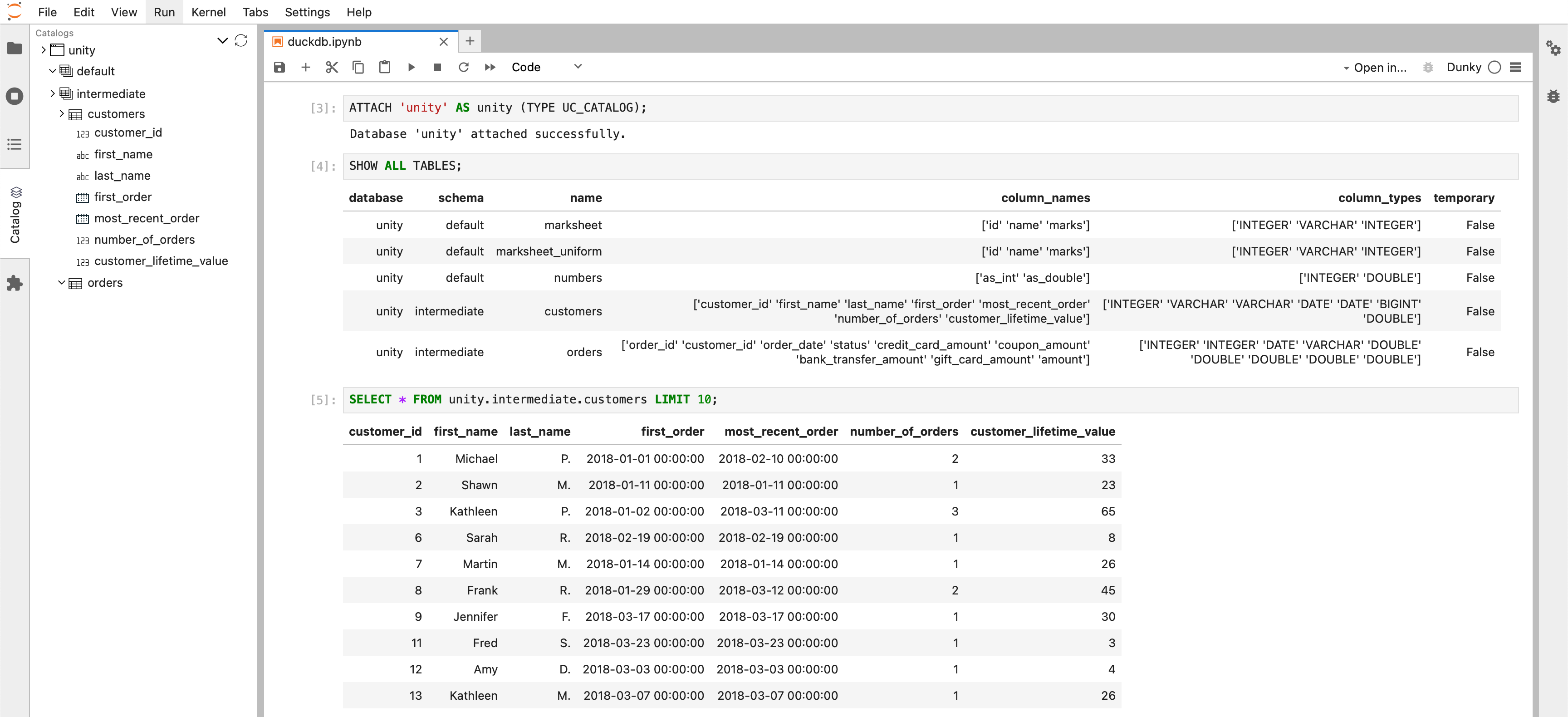
The Unity Catalog sidebar extension, junity, allows for easy exploration of the catalog and enables seamless insertion of table paths into notebook cells.
In addition to querying, the Dunky Jupyter kernel also enables us to create new Unity Catalog tables interactively, providing a more flexible way to manage data within the catalog.
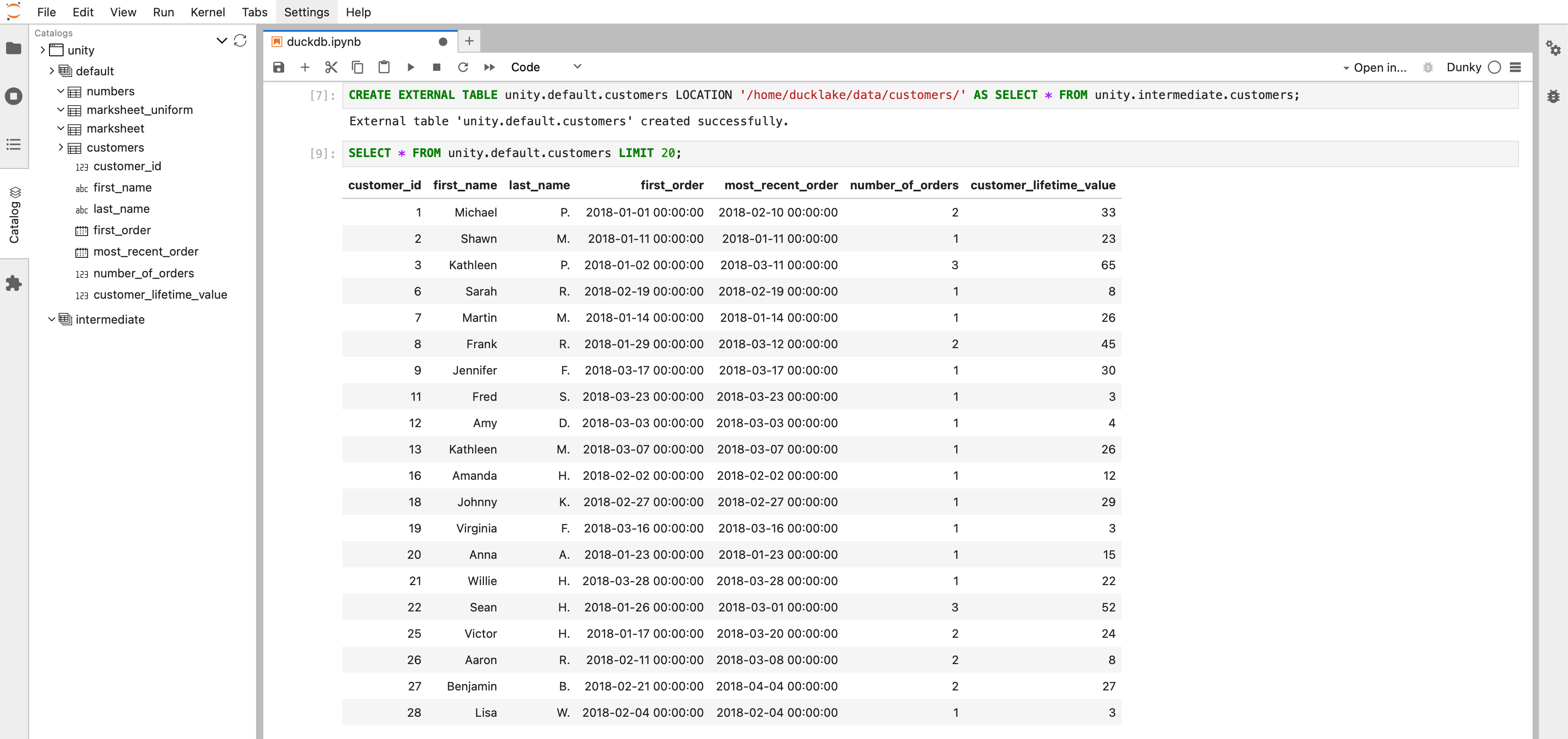
You can find the notebooks in the notebooks directory here
Conclusion
In this post, we demonstrated how DuckDB can be integrated with Unity Catalog using dbt and Jupyter notebooks. While there are some limitations, we were able to set up a functioning local environment where DuckDB interacts with Unity Catalog. The real-time updates in the Unity Catalog UI confirm that DuckDB and Unity Catalog are fully integrated.
What's Next?
☁️ Moving to the Cloud (AWS)
With the local setup complete, we’re ready to explore cloud deployment options. In the next post, we’ll look into setting up Ducklake in AWS.
Adding RBAC Support
As mentioned earlier, RBAC is not yet available for Unity Catalog, but it’s expected soon. Once it’s released, we’ll integrate RBAC into our setup to allow for granular permission management across different users.
❄️ Polaris Integration
We’ve also begun experimenting with integrating Polaris into this setup. We’re excited to share our findings in a future post, so stay tuned!
Written by
Frank Mbonu
Frank is a Data Engineer at Xebia Data. He has a passion for end-to-end data solutions and his experience encompasses the entire data value chain, from the initial stages of raw data ingestion to the productionization of machine learning models.
Our Ideas
Explore More Blogs




Contact