Blog
Distributed Dashboarding with DuckDB-Wasm, could it be the future of BI?

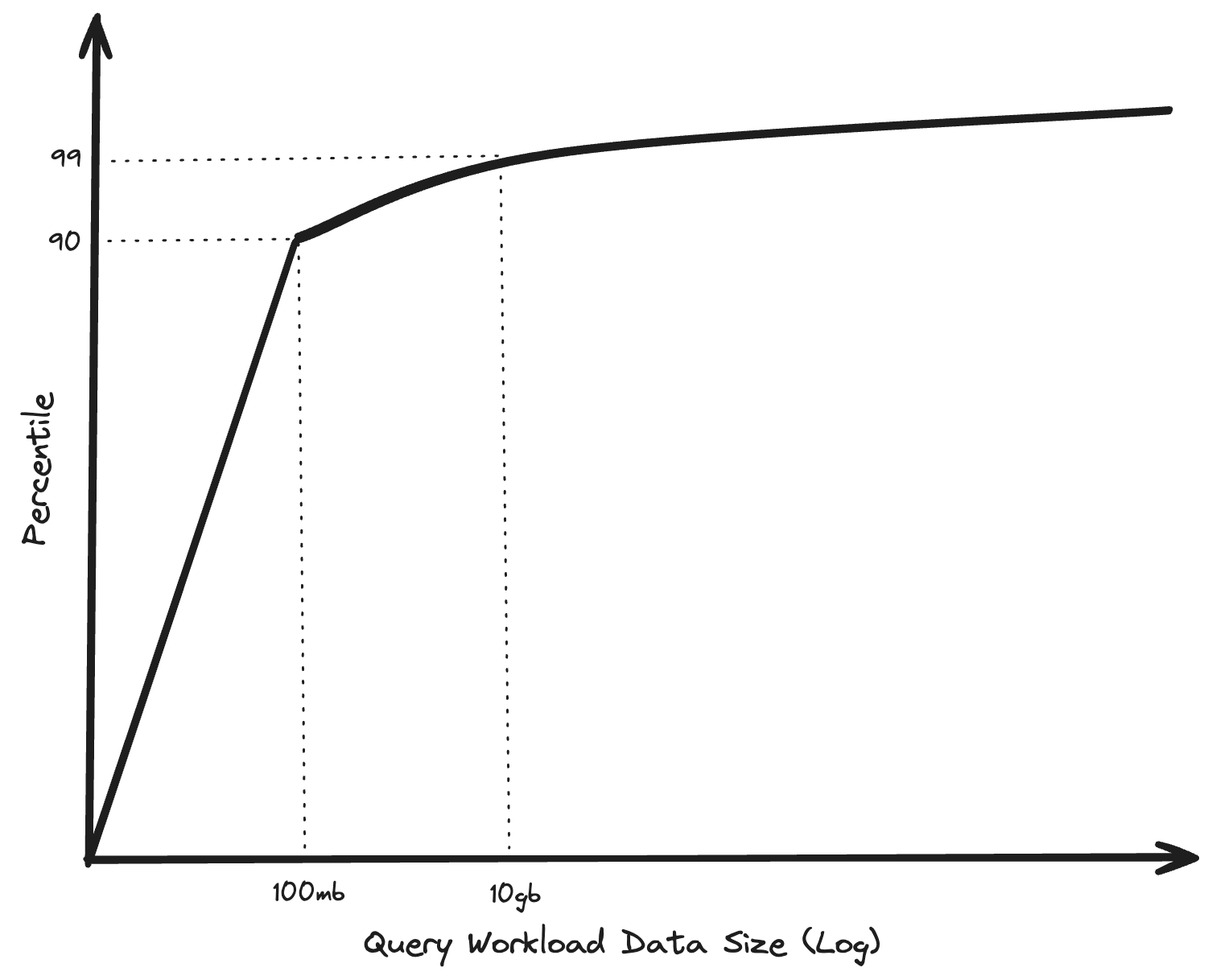
A blog from 2023: “BIG DATA IS DEAD” by Jordan Tigani, inspired me to dive a bit into the DuckDB and MotherDuck ecosystem. Tigani is a former founding engineer of Google BigQuery, and worked for more than 10 years on the product. In his blog “BIG DATA IS DEAD”, Tigani explains that in his eyes the Big Data era turned out differently than expected. Lots of organizations are building these giant data warehouses, leveraging cloud compute to run their supposedly big data workloads in the cloud. In reality, it turns out that about 90% of the queries being executed on BigQuery, process less than 100 MB of data. That's not to say that Big Data doesn't exist, however it is not being queried or processed as often as you would expect. And if you are not always processing "Big Data", perhaps you don't always need to process data using an infrastructure and tools designed for "Big Data" processing.
Meanwhile, over the past ten years the specs of an average laptop improved drastically, it is rather common than an exception to have 16 or 32 GB of memory and a powerful multi-core processor in a standard business laptop. Doesn’t it make more sense, especially for smaller data processing workloads, to be run on your local machine? A machine that is already paid for. Of course this will bring other challenges, I mean when do you decide to run something locally or in the cloud? And do you even want to decide this yourself? Isn’t the cost of transferring data over a network (referring to egress costs in the cloud) higher than the actual cloud compute for the workload itself? Unfortunately in this blog post you will not find answers to these questions, however the concept to move more data processing from the cloud to the local machine seems promising to me. Instead, I will explain in this blog post how I see "Distributed Dashboarding", including a practical example using DuckDB-Wasm.
A company called MotherDuck recently raised $100 Million to work on their cloud offering of DuckDB, and is working on solutions and answers around the questions I mentioned before. DuckDB is a blazingly fast in-process analytical database system, written in C++. MotherDuck is not "just a cloud offering" of DuckDB, they actually offer some cool features on top of DuckDB. Hybrid query execution is one of those features, and also a key selling point for MotherDuck. With hybrid query execution the MotherDuck extension decides when to run a query locally, partly locally and partly in the cloud, or fully in the cloud. With the embedded nature of DuckDB, and it's extension mechanism, this is being made possible. If you want to know more about hybrid query execution and MotherDuck their architecture, I would recommend reading the hybrid query execution paper which was recently presented at CIDR 2024.
DuckDB-Wasm opens the doors to run DuckDB entirely within the web browser using WebAssembly. This makes it easier to integrate DuckDB (and therefore also MotherDuck via the extension) into general web applications, or even browser based BI tools. Imagine the possibilities of having a blazingly fast SQL interface with almost zero latency directly available within the browser. MotherDuck is really focusing on the concept of doing more processing (partly or fully) client-side, and I am quite excited what the future will bring. In my opinion this might be a pioneering step towards a possibly new era in the data warehousing and analytics domain. I am especially excited to see if it will change the way how we currently handle BI use-cases on "supposedly" big data
Distributed Dashboarding
The term "Distributed Dashboarding" might have caught your attention, and triggered you into reading this blog post in the first place. I have to be honest here, it is a term I just made up to get your attention. However, the concept is in my opinion quite promising. I think we will see more and more examples of it in the future, especially with the evolution of the internet in terms of speed and bandwidth. Sending a dataset of several hundred megabytes to clients is nowadays quite fast, and is positioned to become even faster in the future. The idea I have with "Distributed Dashboarding" is to send a part, or in some cases the full dataset that is required for a dashboard towards the client (therefore the term "Distributed"), together with the (analytical) processing logic. The browser downloads this dataset once, and then stores it into the cache of the browser. Because of DuckDB-Wasm and the embedded nature of DuckDB, the browser can then load this dataset into a client-side DuckDB-Wasm instance. This offers a blazingly fast SQL interface on top of the raw dataset. Most of the slicing and dicing of the data, for example for self-service BI purposes, can happen within the browser on the local machine, instead of necessarily needing the compute of a large scale data warehouse. The web based BI application simply needs to generate SQL code, and run this SQL code against the in-browser DuckDB-Wasm instance.
Of course there are a lot of challenges around this concept, and it will not fit all the existing BI and/or OLAP use-cases. There are definitely use-cases that require processing on top of really big data, and that just can't be done locally on a single machine. However, I think there are plenty of use-cases where this can work quite well, especially those where you do not necessarily do analysis on extremely large amounts of data. I will go through some of the challenges that I can think of with possible solutions. For example, what if the dataset is quite big, or the network latency is not that good? Maybe it is possible to send pre-aggregated data for the dashboard in the first place, and then download the entire dataset (or the part that the user requires) in the background? Maybe if the client detects slow network latency, it can decide to do the execution in the cloud instead of locally. While for another user with great network latency it can decide to download the full dataset and do the processing locally. Possibly an AI model can help making these decisions? I also think there are a lot of use-cases where most users only look at the last week or even last days of data. Maybe it is possible to include this (smaller) timespan of data with the initial dashboard load, and do the analytical processing for most users locally. However, when a user wants to look further back than the provided timespan, and do analysis on a larger set of data, the query gets executed against the data warehouse. Another challenge might be the retrieval of increments. For instance, when I have the last month of data stored locally in cache, and I open the dashboard tomorrow, there should be a mechanism that downloads the new day of data and appends it to the local dataset.
Hopefully the MotherDuck extension for DuckDB will offer solutions for some of these problems in the future, and take away the heavy lifting of implementing (partly) client-side data processing for BI dashboards. I am also excited to see if there will be examples of BI tools in the next few years which adopt the concept of doing more data processing locally. In my opinion it can be a unique selling point for a BI tool, especially if you expect a lot of users doing their own self-service BI on top of your data.
Example of Distributed Dashboarding using React and DuckDB-Wasm
To bring the concept of Distributed Dashboarding a bit more into a real-life example, and to experiment around with DuckDB-Wasm, I decided to build a small dashboard application using React and DuckDB-Wasm. A colleague worked on an internal use-case by which we track the GitHub contributions of some of our Xebia colleagues, and offer a dashboard to gain insights into which OSS projects we are most active. The project uses dbt with the dbt-duckdb adapter, and a self-made dbt-duckdb plugin which fetches data from the GitHub API. Eventually dbt writes all data via the dbt-duckdb adapter into an in-memory DuckDB database (which creates a .duckdb file). This .duckdb file contains all the relevant GitHub contributions, and is shipped with the web-application, so it can be used directly in the browser via DuckDB-Wasm.
 Try out the github-contributions dashboard yourself
Try out the github-contributions dashboard yourself
The cool thing is that the browser only has to download the github-contributions.duckdb file once, and from then on stores it within browser cache (in the current example it only caches for 10 minutes because GitHub pages does not allow to alter the caching headers). All the filtering and aggregation functionalities within the dashboard are being handled by the local DuckDB-Wasm instance via SQL statements.
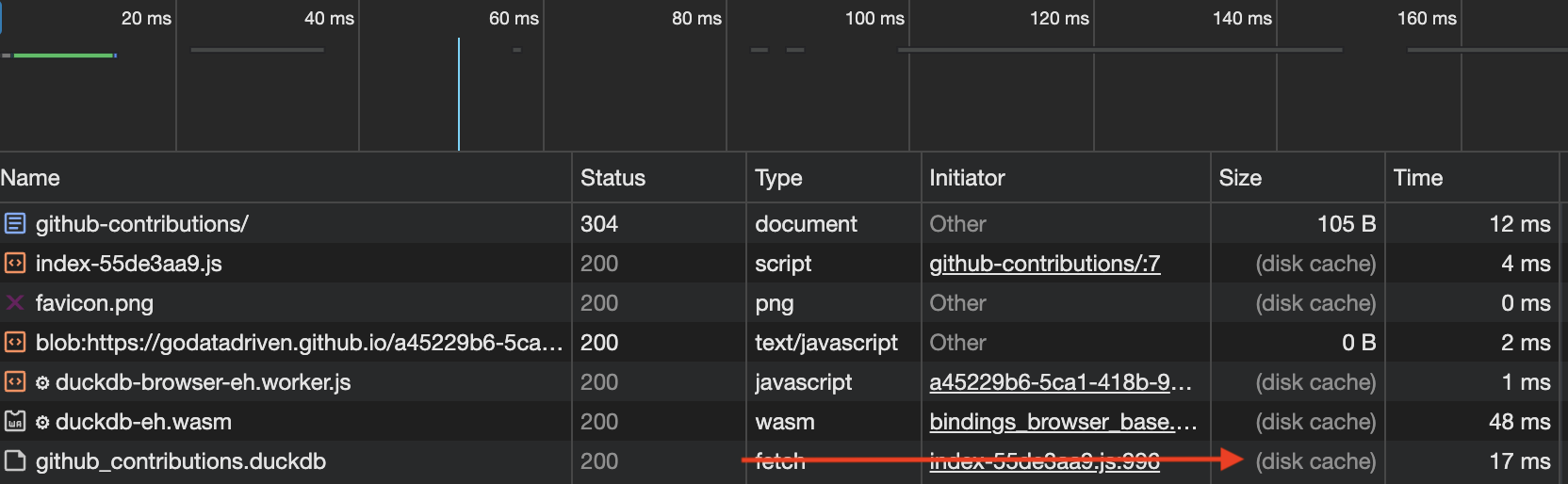
To make this possible I used the duckdb-wasm-kit which makes it easier to use DuckDB-Wasm within React applications. The duckdb-wasm-kit offers hooks and utilities to easily interact with DuckDB-Wasm. I had to make some small contributions to make it work with external .duckdb files, but in the end I got it to work. In case you are curious how the exact implementation looks like, the source code for the github-contributions project can be found here. For using DuckDB-Wasm in other client-side JavaScript applications you could directly use the duckdb-wasm npm package, however this requires a little more boilerplating to set up. In the duckdb-wasm GitHub repository they provide some examples on how to do this.
Conclusion
While the concept of Distributed Dashboarding is promising, I would say it's currently still in its early stages. For a real-world business I wouldn't recommend using React or any other web application framework to build dashboards, but rather just go for one of the widely adopted BI tools. However, envisioning the integration of technologies such as DuckDB-Wasm and MotherDuck's hybrid query execution into widely used BI tools, presents an exciting prospect for the future. It was a nice experiment to play around with DuckDB-Wasm, and experience an example that Distributed Dashboarding is theoretically possible. Hopefully we will see more and more examples of it in the future.
Feel free to reach out if you have any questions or remarks about this blog post.
Written by
Ramon Vermeulen
Cloud Engineer
Our Ideas
Explore More Blogs




Contact