
Many organisations have a new ambition to become a data-driven organisation. In essence, this means the organisation wants to make better business decisions based on insights provided by data [4]. Data itself is not able to advise a business for better decision-making. Therefore these organisations introduce a new capability: Data & Analytics.
This blog elaborates on how adopting DevOps principles can enhance business value creation for the world of Data & Analytics.
Data & Analytics should be able to provide the business with insights so that they can make better business decisions. Or in the (near) future, Advanced Data & Analytics should optimize the business by taking its own decisions and automatically improving the business it supports.
Data & Analytics as a separate business domain
Organisations often make a distinction between business domains e.g. Sales, Marketing, Finance, etc. Each business domain requires its own IT systems for its operation. We see Data & Analytics initially introduced as a separate (business) domain, which requires its own IT systems to operate (e.g. a data & analytics platform). This Data & Analytics domain has the mission to provide insights over business domains and facilitate individual business domains with their ‘insights’ demand. In practice, many organisations struggle with the implementation of the ‘facilitate’ part. Often ‘facilitate’ means ‘implement and operate the insights’ for the various business and product teams.
One example to illustrate what often happens in practice: a data scientist from a business team creates an analytical model on their own laptop and everything works. Next, the data scientist asks an engineer in the Data & Analytics domain to ‘productionize’ the analytical model. The request here is not: ‘please facilitate me so that I can bring my analytical model to production and operate it for my business after that is done’. The request is more like this: ‘please implement an insights application that can run in production based on my “Proof of Concept analytical model”. And also please let me know if it fails’. This example has been recognized by the DevOps community as an issue. It is comparable with the ‘normal’ application development challenges where (Business,) IT Development and IT Operations are separated.
Ideally, ‘facilitate individual business domains with their ‘insights’ demand’ means: individual business domains are capable to take ownership of creating and operating their own ‘data and insights’ needs. The Data & Analytics domain only needs to facilitate that they can do this by providing them the means suchs as a data platform, data governance policies, a development process for advanced analytics models, etc… Unfortunately, the ideal setup does not reflect reality at many organisations. Let’s first briefly explore the world of Data Science and better understand why DevOps can help.
The world of Data Science and Advanced Analytics
Data Science and Advanced Analytics encompasses a set of principles, problem definitions, algorithms, and processes for extracting non-obvious and useful patterns from large data sets [1]. The focus of data science is on improving decision making through the analysis of data [1]. This data analysis is captured in so-called (advanced) analytics models.
Typical use cases are:
- Clustering (or segmentation): extract patterns that help to identify groups of customers exhibiting similar behaviour and tastes;
- Anomaly (or outlier) detection: extract patterns that identify strange or abnormal events, such as fraudulent insurance claims;
- Association-rule mining: extract a pattern that identifies products that are frequently bought together;
- Prediction (including the subproblems of classification and regression): identify patterns that help us classify things, e.g. detect SPAM email.
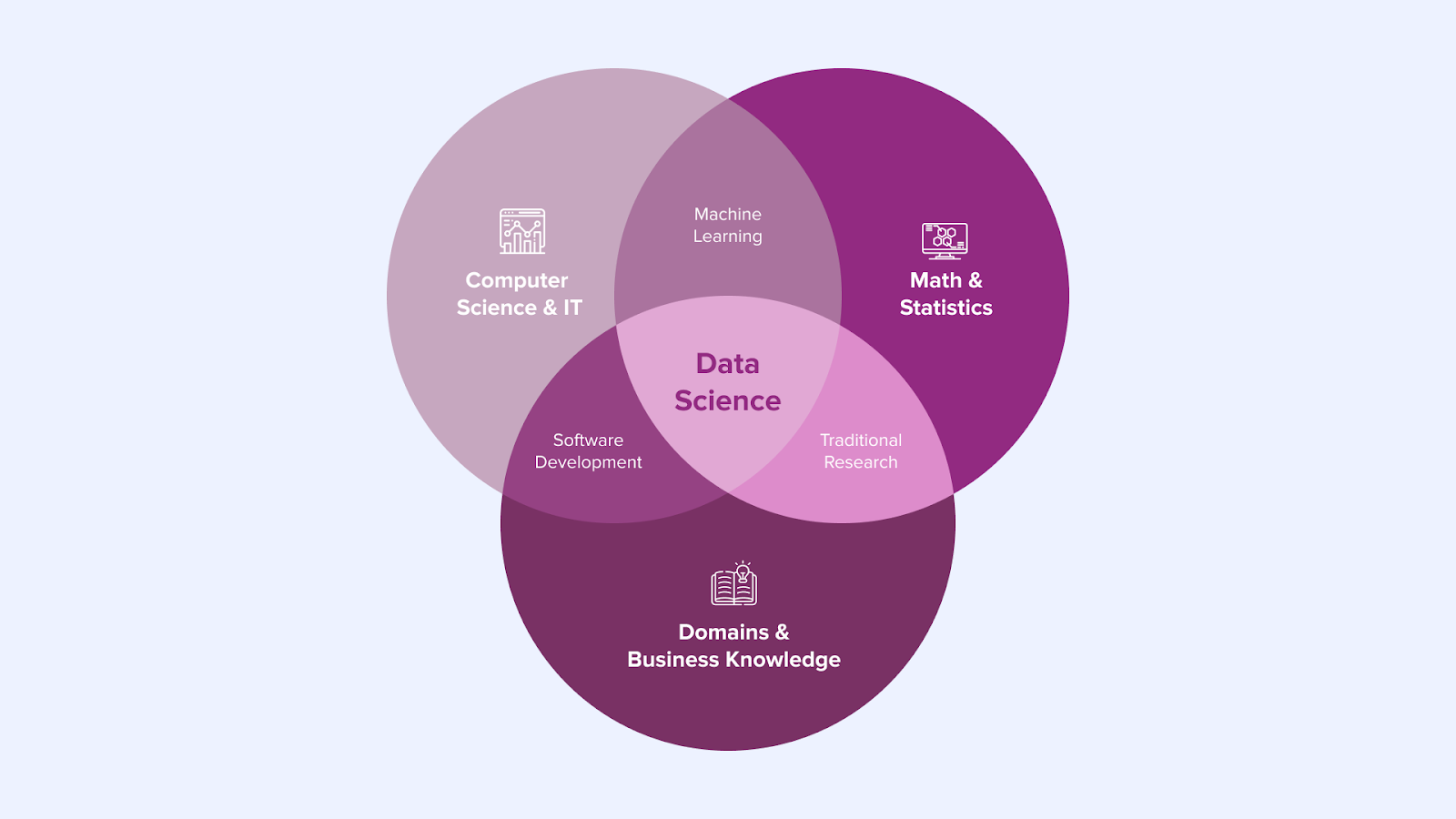
Figure 1
Figure 1 shows the skills of a typical data scientist. In practise, the ‘Math & Statistics’ and the ‘Domains & Business Knowledge’ is good. However, the ‘Computer Science & IT’ skills are ok for the Machine Learning part, but the Software Development skills of a Data Scientist are focussed on the creation of the advanced analytics model. The software development skills for bringing an advanced analytics model to production are limited. It is too often assumed that the Data & Analytics domain completely covers this (as addressed in the introduction). And in particular, the more complex / process-heavy implementation of a release process at a large organisation is not part of the skill set of an average Data Scientist. So, this Data Scientist is not capable to fully implement and operate the model he/she developed.
What is DevOps?
There are many meanings associated with the term DevOps. We use the definition from the DevOps Agile Skills Association [2]:
| DevOps is a CULTURAL and OPERATIONAL model that fosters COLLABORATION to ENABLE high-performance IT to ACHIEVE business goals. |
The DevOps community started with Patrick Debois [3]. In essence, it aims to bring the (traditionally separated) worlds of development and operations together. In many large organisations application development and running applications are separated. In between a so-called ‘wall of confusion’ exists (see Figure 2).
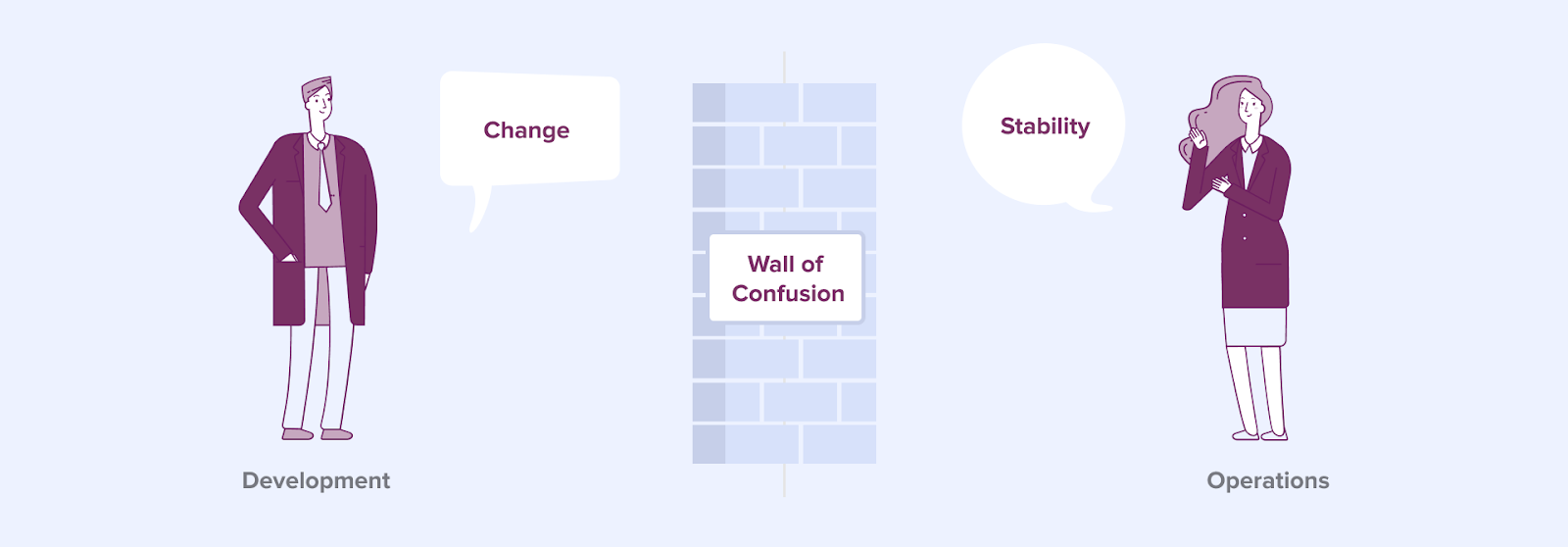
Figure 2
The DevOps community states that organisations need to break down this wall of confusion between Development (Dev) and Operations (Ops). We see this ‘wall of confusion’ applies in the data science world as well. Data Scientists mainly focus on developing advanced analytics models. Bringing advanced analytic models to ‘production’ and operating a model running in production is not part of their formal role in the organisation. As stated earlier, the skills for both of these activities are also limited for the average Data Scientist.
The DevOps Agile Skills Association (DASA) defined 6 principles, which should be adopted by an organisation that wants to adopt DevOps [2]. These principles are depicted in Figure 3.
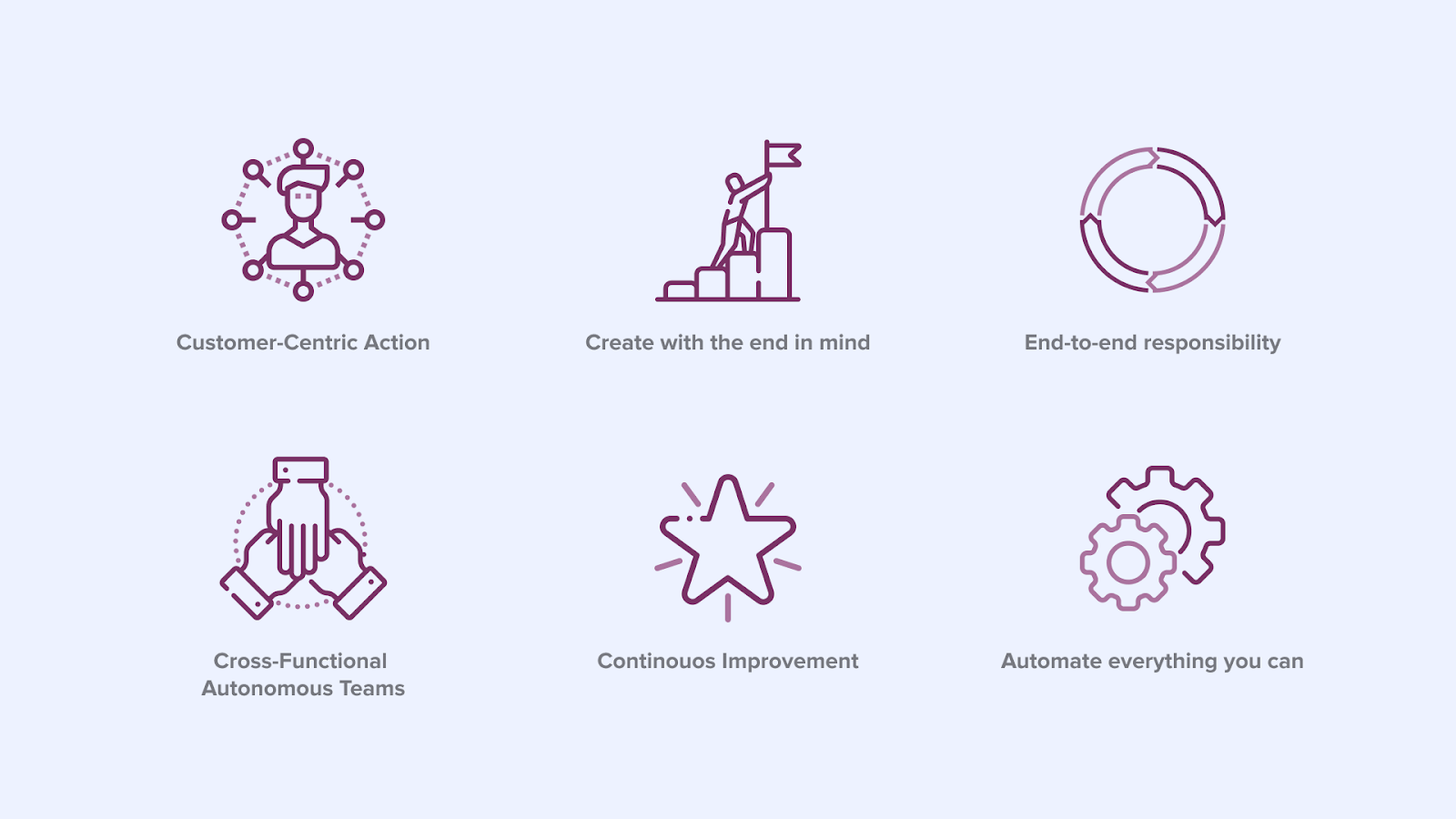
Figure 3
An organisation that adopts these 6 principles will deliver business value faster, etc. (for more information about the benefits of adopting DevOps see [4]). For our use case: breaking down the wall of confusion between Data Science and Operations of Data Applications in an enterprise setting, principles 3 and 4 are most important. The details will be discussed later. First the details of both worlds in practice are discussed.
Current State of Practice
For many organisations ‘Advanced Analytics’ (so not ‘traditional BI’) is relatively new. Following best practices, these organisations introduce advanced analytics in isolation, in what we call a ‘Lab Setting’. Such a lab setting has specific properties which are different compared to a regular software development setting in large organisations. We label this last setup as a ‘Factory Setting’. Both setups have different objectives and are not aligned. In this case, the advanced analytics capability is completely decoupled from the rest of the organisation. This is another so-called Wall of Confusion as depicted in Figure 4.

Figure 4
The consequences of such a wall are known and shared widely in the DevOps community [4]. For example, long lead times for releasing advanced analytics models, many iterations and handovers between Data Scientists and Data (platform) Engineers, etc… This results in slow decision-making and slow adaptation of your business based on your data. DevOps (and its principles) help in bringing both worlds together just like it did in the application development world. Therefore we state:
| Enterprises often create a ‘wall of confusion’ when starting an advanced analytics capability in their organisation. This wall of confusion needs to be broken down to realize the ambition of becoming a Data-Driven organisation |
So, a data & analytics capability in a large organisation faces the same challenges as a ‘traditional’ application development capability. And they make the same mistakes as most IT organisations did when building applications in the past (btw, many organisations still struggle with this). Let’s explain in more detail by zooming in on the lab setting and factory setting.
Properties of a Lab Setting vs a Factory Setting
A lab setting and a factory setting differ enormously. Table 1 shows the main differences between both setups.
| Lab Setting | Factory Setting |
| Full freedom to configure their personal development environment. For example: - New libraries can be installed as required; - Multiple versions of software packages can be used; - All cloud services can be used on personal basis; - No limits regarding resources. |
The production environment has a predefined configuration. For example: - Not every library is allowed to be used; - Only one version of a library is available; - Only approved cloud services are enabled; - Resources are limited. |
| Personal access to many data sources | Limited access to data sources via non-personal accounts |
| No or limited compliance policies applied | Strict compliance policies appliedEmbedded organisation controlsMandatory organisation integrations |
| No mandatory life-cycle management (LCM) process | Mandatory process for life-cycle management (LCM) needs to be followed with testing, validations, etc. |
| Full access to local runtime | No manual / user access to production workloads |
Table 1 shows that Data Scientists have a lot of freedom to configure their (often personal) lab setting. This freedom is not allowed for production environments in a factory setting. So, a working advanced analytics model in a lab setting is no guarantee that this model will also run successfully in the production environment. Because of the different character of the lab and factory setting, the request from a Data Scientist to the Data Engineer to productionise an advanced analytics model can be quite a labor intensive activity with many iterations and handovers. If we then also take into account that the Data & Analytics domain has a limited number of Data Engineers / Data Platform Engineers and that there are potentially many Data Scientists doing requests for multiple business teams, it will not be a surprise that this setup is also not scalable for a large organisation.
Data & Analytics adopting DevOps principles
Adopting the DevOps principles in the Data & Analytics domain means breaking down the silos of the lab setting and factory setting. A professional Data & Analytics domain should provide a mature development environment for data scientists which gives them the freedom of the lab setting, but where no personal access to data sources is needed and where the mandatory LCM process and compliance policies are already implemented out-of-the-box. In such a situation the Data Scientist in the business teams are facilitated and can take end-to-end responsibility (DevOps Principle 3) for the creation of their advanced analytics models.
The self-service model provided by the Data & Analytics domain gives the business teams also the possibility to work autonomously. However, it does expect that the business teams invest in their skills to understand and be able to work with the provided self-service interface. This not only concerns the interface for developing models, but also the tools for operating their models (DevOps Principle 4).
Finally, the results of the business specific developed advanced analytics models (which are labeled Data & Insight Applications) should also be consumable by the specific business team. Ideally, not only the Data & Insight Applications of their own business, but also Data & Insight Applications of other business teams should be consumable. So, the service portfolio of the Data & Analytics domain should facilitate both via a self-service model.
Service Portfolio Data & Analytics domain
From the perspective of the Data & Analytics domain there are 2 types of customers: Creators and Consumers of Insights (see Figure 6). Both types have different needs and need to be facilitated. To do this, these are the core services the Data & Analytics domain should provide to other business domains:
- Creation of insights and composite data sets
- A self-service environment to make data available for analytics
- A self-service environment to create and run advanced analytics models
- A self-service environment to create and run dashboards
- A self-service environment to publish or integrate advanced analytics model results
- A self-service interface to monitor and operate their advanced analytics models
- Consumption of Data and Insights
- Ability to explore available data and insights
- Ability to consume and use of Insight Applications
- Ability to consume and use of composite pre-processed data sets
- Ability to access predefined dashboards (management information / service reports / performance reports, etc.)
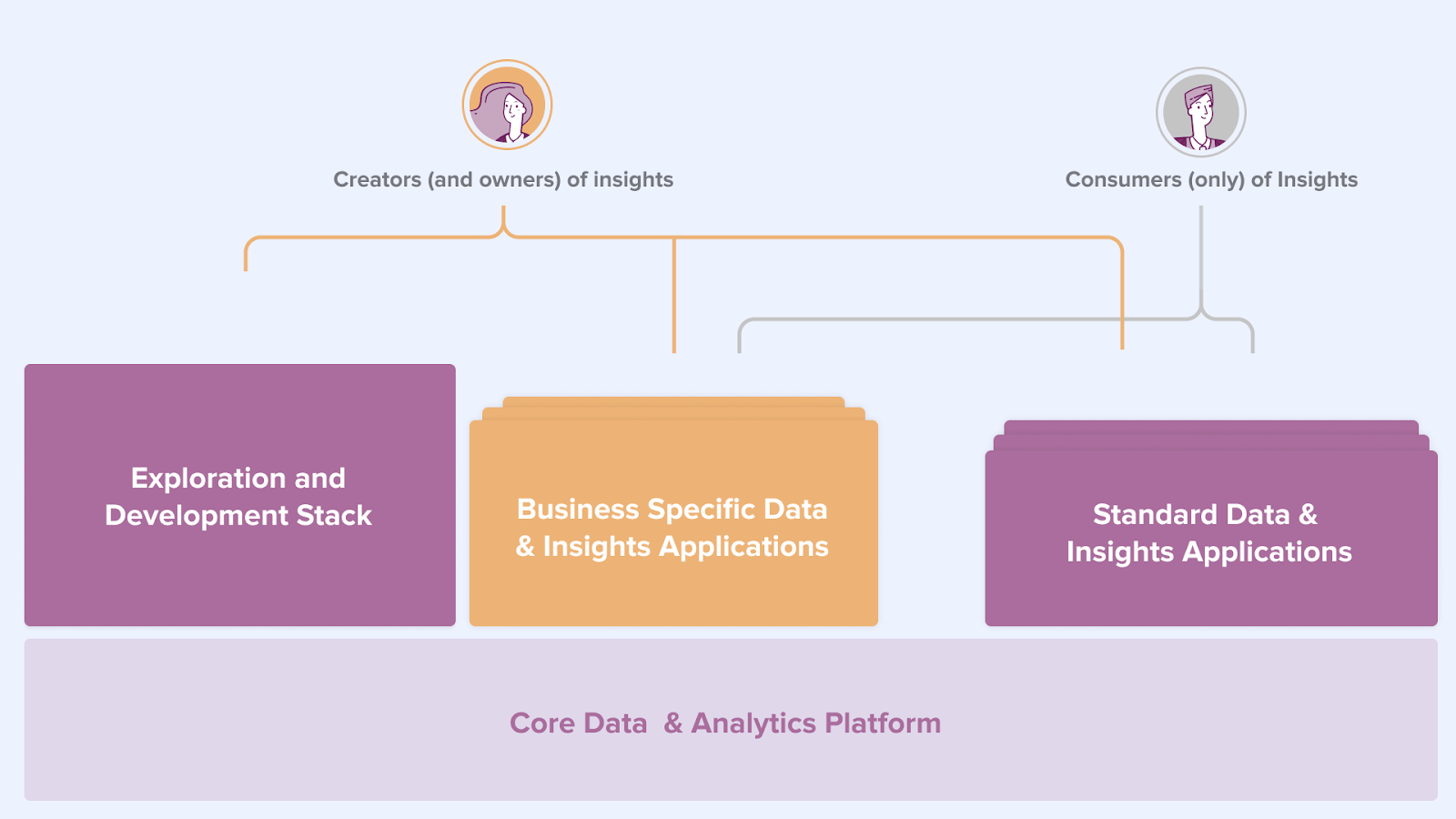
Figure 6
Expectations Business and Product teams using Data & Analytics
For a Data & Analytics domain to be successful and deliver their services, it needs to be fed with data from other business domains. So, in a data-driven organisation it is mandatory for business domains to provide data to the data & analytics domain. For many enterprises this is a challenge as this requirement ‘share your relevant data’ is not a requirement that gets a high priority in practice. This mindset should change. Recall that the Data & Analytics domain will provide the following service: A self-service environment to make data available for analytics. So from that perspective it should not be a blocker anymore to share relevant data for Analytics.
Besides this essential prerequisite of sharing data, the business teams do need to invest time in understanding the (self-service) environment and services provided for monitoring and operating their Data & Insights applications.
Concluding remarks
The isolated lab setting which many organisations have for their data science capability needs to be replaced by a professional Data & Analytics domain in combination with mature business and product teams that adopt the Data Science capabilities. The Data & Analytics domain will provide user-friendly self-service services for Data & Insights consumption and creation. This way Data Scientists are facilitated and can take end-to-end responsibility for their models.
Do you want to learn more? Check out DevOps for data science
References
[1] Data Science - John D. Kelleher and Brendan Tierney
[2] DASA whitepaper: devopsagileskills.org/dasa-devops-principles/
[3] History of DevOps by Patrick Debois: The (Short) History of DevOps
[4] DORA: devops-research.com/research.html
Written by
Marco Lormans




Contact