Blog
Decomposition strategies for RAG: Insights for proper ingestion of tables

Introduction
Convert a bunch of pdf files into plain text. Break that jumbo big string into smaller blocks. Load your (now) documents into a vector database; look at that -- a knowledge base! Now let every user input fall directly into the query for that vector database, and don't think twice: slap those top 5 similar documents into a string, concatenate some instructions, call it a prompt, feed that to an LLM, et voilà: we have RAG! Pretty cool, right? Well, if you were hopefully annoyed by my condescending tone, then you must have realized that it's a big no or, at most, not exactly.
Well, retrieval is great, but retrieving quality contents is what it takes to make RAG really work! And for that, we need to take the meaning of ingestion more seriously, almost literally. Especially when it comes to complex formats, such as tables, or multimedia formats, we need to chew, decompose what comes in, so only then we are able to absorb all it has to offer. In this blog I intend to explore that chewing process towards tables -- as tabularly-structured knowledge, not to be mistaken with tabular data -- or, in other words, I will share insights on how to properly ingest knowledge shaped in the form of tables by leveraging the strengths of language models, improving retrieval.
Semantical bottlenecks in raw format
Our must-have in knowledge bases, PDF, stands for Portable Document Format. Portability here ensures a document can be displayed the exact same way across all platforms and devices. Yet, such a visual fidelity comes at the expense of compromising what would be the core condition for computers to properly process and interpret text: semantics. Text fragments become visual elements and, for some optimization reason (for the lack of a better word), those elements may be differently arranged within the file in comparison to the overall semantics, i.e., the natural flow of text as intended at creation time.
So far it remains optimal for the human eye. The problem comes when the computer tries to read it. Parsing that file and converting the flow of visual elements into plain text may result in entangled text fragments that do not belong together. Take a look at this toy example:

|
|
|
| Output (row-wise): | Output (column-wise): | |
ab c def gh j klmn |
a g k b d h l e m c f j n |
Divergent outputs between PDF readers when traversing the same PDF document.
We can see different readers traversing the same PDF structure in their own way in an attempt to find some semantics in the midst of dummy visual elements. pypdf apparently follows the row-wise PDF stream (notice how a, b, c, ... appear sequentially), whereas pdftotext takes another direction. Another example prone to the same semantic-loss situation is a column layout document exported to PDF being parsed: the first line of the first column can be followed by the first line of second column, and only then by the second line of the first column, and so on, different to the flow the human eye would go through.
This is obviously a simplistic way to paint the picture, enough for the scope of this blog. The takeaway though is that PDF files lack semantics, as the layout complexity increases. And we do need to preserve semantics, so we have one less obstacle towards making our chunks sensible.
Chunking and the never-ending debate
By page, chapter, paragraph, sentence, character length, useless fancy recursively-defined character windows: what is the best way to organize a knowledge base into chunks? Let me try to answer this with more questions: Is that the right perspective? Must there even be a closed formula? If so, are we willing to accept how much this compromises the informative quality of chunks? Before I drift from the main point, allow me to anchor my rationale on some premises about the ideal chunk:
- Must be a unit of knowledge in the most complete and independent way possible
- If not informatively independent, links to complementary chunks can remedy this situation.
- Knowledge complexity varies, especially across different knowledge domains, and so must the respective chunk size.
Such premises bring robustness to RAG systems, as they maximize the semantical overlap between query and chunks. Search precision also improves, since units of knowledge would no longer be shattered across multiple chunks.
When we read tables ourselves, interpreting the underlying knowledge can be challenging even for us humans, depending on the complexity. We might even take some side notes that can be helpful when revisiting some table in the future. This kind of organic reasoning is key for breaking tables down to interpretable bits of descriptive knowledge, especially when we can leverage from generative and interpretative capabilities of language models.
Bottleneck is actually a matter of perspective
So far we have framed our bottleneck as the lack of semantics in the raw PDF stream for the sake of visual fidelity, proper for human's visual interpretation. Fortunately, current times allows us to leverage that very same perspective: what if we take a vision-driven approach to parse tables? With multimodal models we can not only do some fine prompt engineering, but also feed the final rendered table as an image at the input -- after all, that's the strong point of PDF, right? In addition, it easily transfers to digitalized documents, HTML, or any other format involved in some rendering process.
This idea is not so novel, though. RAG enthusiasts have been leveraging vision-driven approaches for ingesting tables at many levels of complexity (and creativity). For the sake of scope, let's stick to those involving multimodal models. Be it via Unstructured library, image encoding, or even the fanciest prompt that guarantees an accurate representation of the table (in markdown, JSON, TeX, you choose) at the output, they all share a common denominator: reverse engineering. The parsing is too literal, always retrieving structured format or, at most, prompting for an additional descriptive summary of the table. Well, reverse engineering can work pretty well with LLMs, as they are great at understanding structured formats. A minor detail however is that it depends on proper retrieval so that such a content gets to reach the prompt in the first place. And that's where we need more robustness.
Instead, I'd like to take parsing less literally here, just by taking a different direction in prompt engineering. Let's call it a decomposition, in the sense of breaking down the abstract into (concrete) building blocks. The rationale may hold for most tables, but consider the following one just so I can make my case:
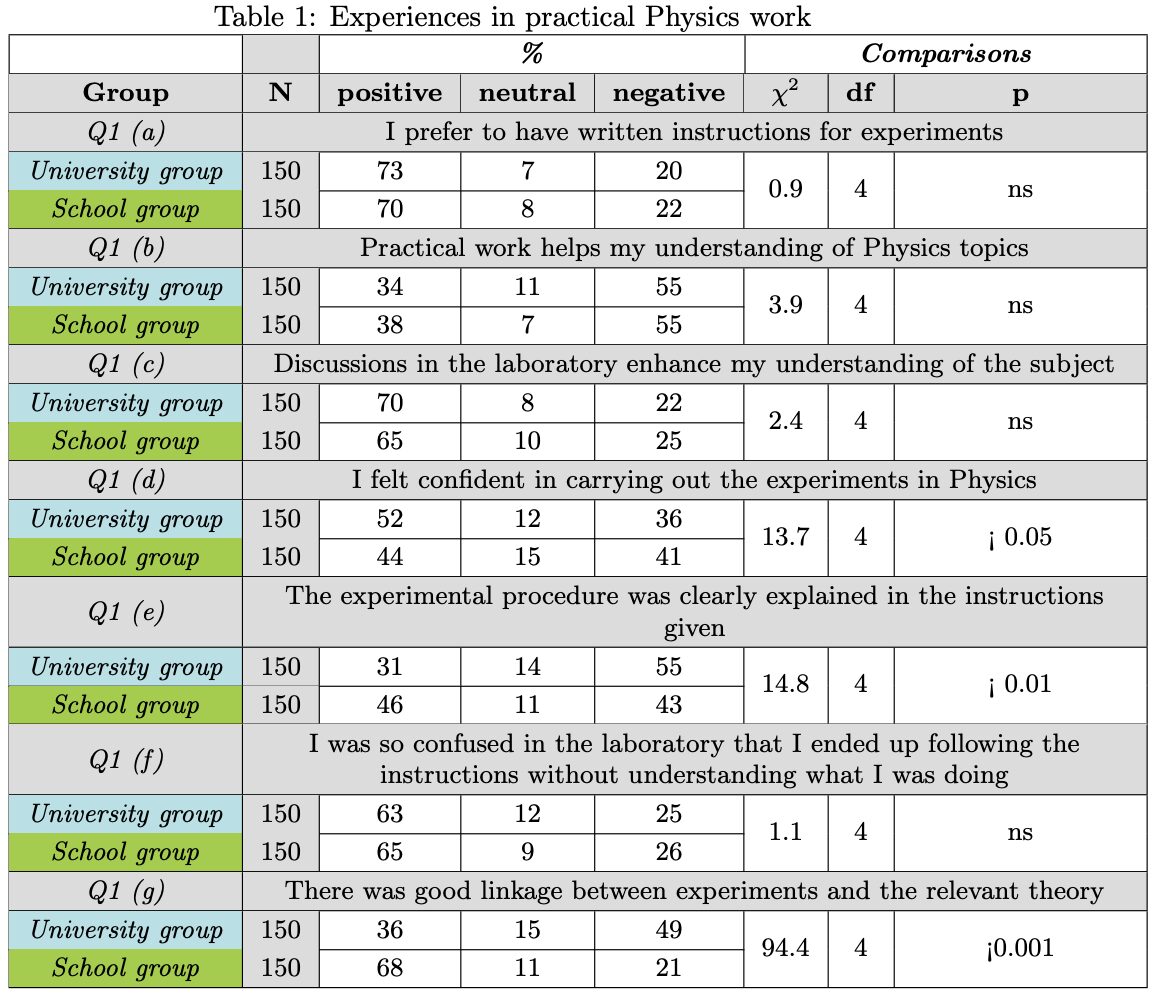
Example of a complex table for ingestion. Extracted from StackExchange.
It is reasonable to say that the knowledge from tables essentially reside in the values, not in headers or title. Headers and title only give format to the knowledge, whereas values are the knowledge. So what if we take into account what we established above regarding the ideal chunk and ask a multimodal model to interpret every value cell, whilst taking into account their headers and title? In other words, feeding both the table above and the following prompt into a multimodal model:
Explain every cell of the table above in a bullet-point list. Each element of the list should be a complete and independent piece of information, describing what that value (text or number) is about, considering its headers. Continue this list redundantly for every cell in this list. Do not explain cells of headers. Consider only the values. Do not include math operations in this list, but only descriptive observations about table values. The list must contain only explanations of the technical details of the table from cell values. Complementary information that explains how to read the table must be in a separate paragraph.
No rocket science, right? Quite the opposite, sounds even a bit redundant and repetitive. It is basically one way to interpret and convert every value cell of the table into a sentence, gluing all the headers together, and shaping the final knowledge into a sentence, as we can see was provided as output:
* 150 is the number of students in the University group that answered question Q1 (a).
* 73% of the students in the University group answered positively to question Q1 (a).
* 7% of the students in the University group answered neutrally to question Q1 (a).
* 20% of the students in the University group answered negatively to question Q1 (a).
* 150 is the number of students in the School group that answered question Q1 (a).
* 70% of the students in the School group answered positively to question Q1 (a).
* 8% of the students in the School group answered neutrally to question Q1 (a).
* 22% of the students in the School group answered negatively to question Q1 (a).
* 0.9 is the chi-squared value for the comparison between the University group and the School group for question Q1 (a).
* 4 is the degrees of freedom for the comparison between the University group and the School group for question Q1 (a).
* ns means that the difference between the University group and the School group for question Q1 (a) is not statistically significant.
* 150 is the number of students in the University group that answered question Q1 (b).
* 34% of the students in the University group answered positively to question Q1 (b).
[...]
* 15% of the students in the School group answered neutrally to question Q1 (d).
* 41% of the students in the School group answered negatively to question Q1 (d).
* 13.7 is the chi-squared value for the comparison between the University group and the School group for question Q1 (d).
* 4 is the degrees of freedom for the comparison between the University group and the School group for question Q1 (d).
* ¡ 0.05 means that the difference between the University group and the School group for question Q1 (d) is statistically significant at the 0.05 level.
[...]
* 150 is the number of students in the University group that answered question Q1 (g).
* 36% of the students in the University group answered positively to question Q1 (g).
* 15% of the students in the University group answered neutrally to question Q1 (g).
* 49% of the students in the University group answered negatively to question Q1 (g).
* 150 is the number of students in the School group that answered question Q1 (g).
* 68% of the students in the School group answered positively to question Q1 (g).
* 11% of the students in the School group answered neutrally to question Q1 (g).
* 21% of the students in the School group answered negatively to question Q1 (g).
* 94.4 is the chi-squared value for the comparison between the University group and the School group for question Q1 (g).
* 4 is the degrees of freedom for the comparison between the University group and the School group for question Q1 (g).
* ¡0.001 means that the difference between the University group and the School group for question Q1 (g) is statistically significant at the 0.001 level.
The table presents the results of a survey of 300 students (150 from a University and 150 from a School) about their experiences in practical Physics work. The table is divided into seven sections, one for each question (Q1 (a) to Q1 (g)). Each section shows the percentage of students who answered positively, neutrally, or negatively to the question. The table also shows the results of a chi-squared test of independence, which was used to determine whether there was a statistically significant difference between the responses of the University group and the School group for each question.
Generated with multimodal gemini-1.5-pro-001 with temperature=0
Notice each list element brings the full meaning behind any number/value from the table, conveyed from the perspective of their headers. Merged cells were also taken into account, as we can see the sensible interpretation of percentages, or which numbers are related to which question. Even us humans would go through a hard time formulating general rules that hold for multiple layouts. Not to mention it could figure the statistical lingo from minimal notation, bringing up terms like degrees-of-freedom, chi-squared, and statistical significance.
Okay, looks good. But how is this better?
Owing to the absence of a benchmark on decomposition of tables, allow me to propose a simple ad-hoc analysis here, so we can compare approaches in numbers. Consider the following questions someone minimally interested in the above table could ask:
- Is there statistical significance between groups about question Q1(g)?
- What is the biggest percentage point difference between university and school groups in any single response category?
- Which question showed the most statistically significant difference between groups?
- How many degrees of freedom were used for all the chi-squared tests?
- Which question showed no statistically significant difference between groups?
Now, in terms of embedding similarity, let's compare how those questions overlap with chunks from the three approaches we have seen after ingesting our example table: decomposition, reverse engineering and raw parsing (with pypdf). In order to avoid any bias from vendor's training data, especially in the case of decomposition, embeddings from OpenAI (text-embedding-3-large) were considered here, but feel free -- and encouraged -- to reproduce the experiment yourself with embeddings from another vendor, another similarity metric, etc. In addition, although the results here are numerical, higher/lower-than comparisons are enough for this discussion, as the absolute numbers remain abstract due to the nature of the embedding space.
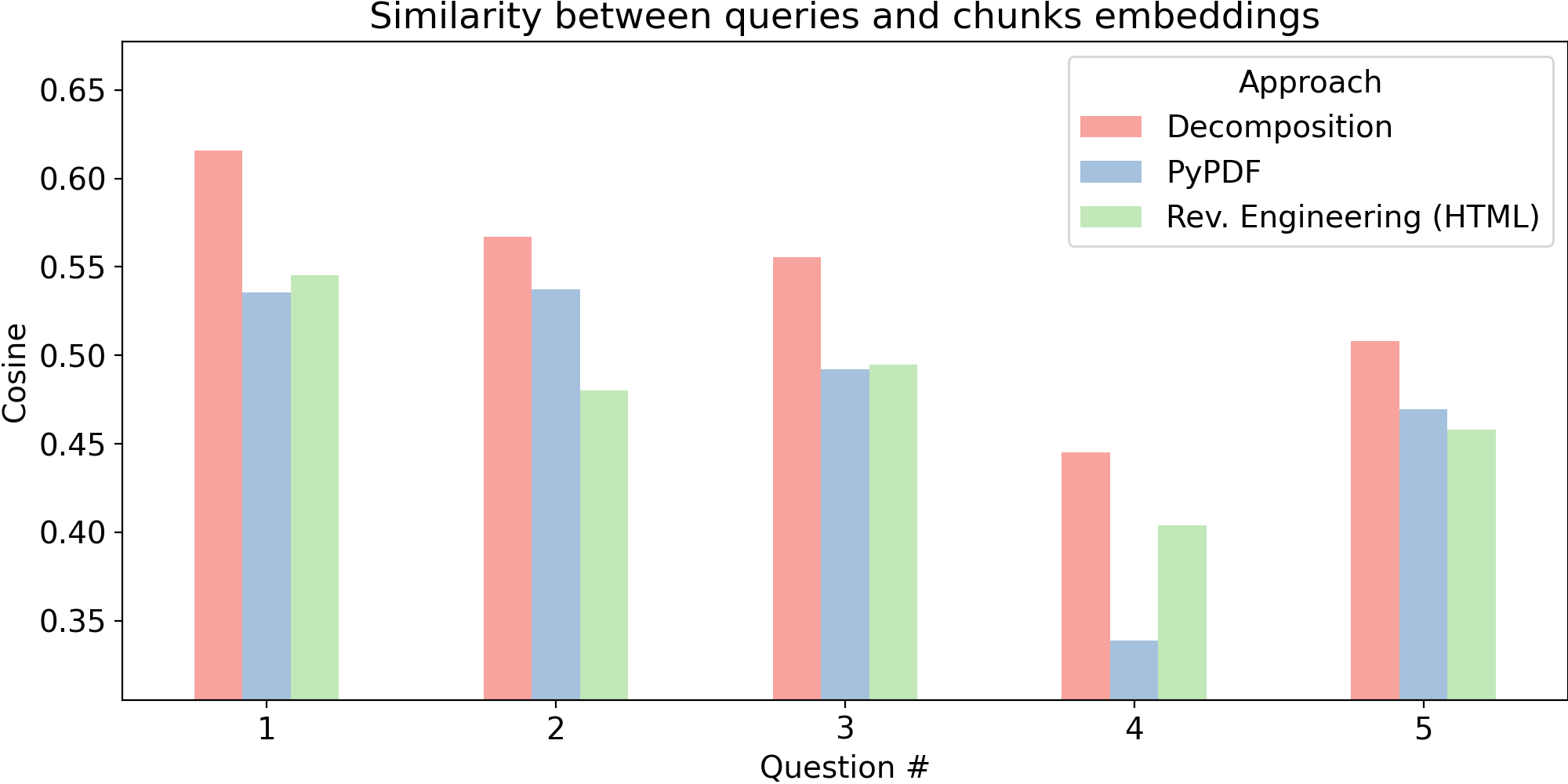
It is not very surprising that when it comes to reverse engineering and raw PDF parsing, neither method outperforms the other, as their similarities with organic questions are capped, to the same extent, to random keyword overlapping, with little semantics. Hence, it compromises the backbone of RAG: Retrieval. Perhaps their informative contributions in a prompt could be a crisp tie breaker (towards reverse engineering, as structured is better than scrambled), but this is a conversation for another day.
As expected, decomposition semantically overlaps the most with all questions, which portraits how beneficial it can be for retrieval, since it goes towards the biggest strength of language models: plain language, and nothing more. Chunks now describe knowledge in the very way closer to how humans would query or even reason when interpreting a table: from the gist of it (described by the additional summary paragraph) to how we would explain table values to someone (as phrased in the list elements).
Conclusion
Yet, another garbage in, garbage out situation. Translating to RAG lingo: we can say retrieval (out) is a solid backbone of RAG, which depends on proper (in)gestion. And for this we have seen that in order to ingest complex contents like tables we need to go beyond the mechanical parsing of text streams.
Decomposition makes the best out of the strengths of language models: plain language, and nothing more. Models with vision capabilities are key to breaking down complex tables into smaller, concrete and describable pieces of knowledge, just like humans would reason when interpreting, or even explaining those to someone. That said, this is the very way users will organically query for knowledge in an application. Such queries naturally overlap more with independent and complete chunks, making retrieval more robust. Additionally, it also discomplicates promting engineering at the generation step.
From an embedding similarity (ad-hoc) perspective decomposition outperforms both raw parsing and reverse engineering approaches at retrieval. It is debatable whether reverse engineering could outperform decomposition at generation time, as long as reverse-engineered content (retrieval dependent) gets to reach the prompt in the first place, but this is a conversation for another day. What is worth a debate for the next steps though is how to combine both approaches, strategically using each form at different steps. Metadata, for instance, is a good first step.
Written by
Caio Benatti Moretti
Contact