
Introduction
Large Language Models (LLMs) have proven useful for numerous tasks. They can summarise text, generate text, classify text, or translate text. LLMs can also convert unstructured data to structured data.
This can have huge benefits. Useful facts that were previously hidden inside a large piece of text can now be unveiled, allowing you to use properties of a dataset that could before not be directly accessed. LLMs come in useful to build such extraction tools quickly, cutting development time significantly. Though more importantly, with the power behind LLMs, the properties to be extracted can be more complex than what was previously possible with traditional methods.
In this blog post, we will explore three strategies for using LLMs to extract structured data from a piece of text: 1) providing a JSON example, 2) defining a Pydantic schema (also see this blog post), and finally, 3) using OpenAI's Function Calling API. But before we dive into these strategies, let's first explore what a naive approach would look like.
Follow along!
A first naive approach
Let's start with a naive approach. We have a piece of text, and we want to extract some structured data from it. Let's take an example. We will consider a house ad for a rental house in Amsterdam. The ad is as follows (this is not a real ad):
Title: Charming Amsterdam House with Balcony, Pet-Friendly for Couples
Description:
Welcome to this charming house in the heart of beautiful Amsterdam! This cozy and well-maintained property offers a delightful living space, complete with a private balcony, making it the perfect home for a couple seeking comfort and convenience.
Key Features:
- Balcony: Step out onto the balcony and enjoy your morning coffee or unwind with a glass of wine in the evening. The balcony offers a peaceful retreat where you can soak up the vibrant atmosphere of Amsterdam.
- Pet-Friendly: We understand that pets are an important part of your family. This house gladly welcomes your furry companions, allowing you to create lasting memories with your beloved pets.
- Ideal for Couples: With its intimate atmosphere and well-designed layout, this house is an ideal choice for couples. Whether you're enjoying a romantic dinner in the dining area or relaxing in the cozy living room, this house provides a comfortable and intimate space for you and your partner.
- Central Location: Situated in the heart of Amsterdam, this house offers easy access to the city's most popular attractions, vibrant nightlife, and cultural hotspots. Explore the charming canals, visit world-renowned museums, or indulge in the diverse culinary scene – all just a stone's throw away from your doorstep.
- Well-Maintained: This house has been meticulously cared for, ensuring a comfortable living experience. The property features modern amenities, including a fully equipped kitchen, a spacious bedroom, and a clean and functional bathroom.
Additional Information:
- The house is available for long-term rental.
- Furnishings and appliances are included.
- Utilities (electricity, water, internet) are not included in the rental price.
- Public transportation options and amenities are easily accessible from the house.
Don't miss out on this fantastic opportunity to make this charming Amsterdam house your home. Contact us today to schedule a viewing or to request further information.
There is, in fact, a lot of potentially useful information in there! The ad lists 'key features' which include a Balcony, Pet friendliness, Ideal for Couples, etc. If you have a pet, you will care about whether they are- or are not allowed in you rental appartment. Similar for the balcony: perhaps you have been going through many house ads to find your dream house with a balcony! That is time spent filtering the ads that could also have been automated. In a similar fashion, there can be a dozen other properties that can be very useful to anyone searching for a new home. Let's try to extract these properties using an LLM!

Figure: overview of process. A piece of text is passed to the LLM, which outputs a structured version of the information. Note: the house ad on the left is not real.
Let's try a prompt to see if we can extract some information.
A house listing will follow, as it appeared on a housing website. Please extract the following information from the listing:
- Is pet friendly (yes/no/unknown, quote: "...")
- Has a garden (yes/no/unknown, quote: "...")
- Has a parking place (yes/no/unknown, quote: "...")
- Is suitable for a couple (yes/no/unknown, quote: "...")
- Has a balcony (yes/no/unknown, quote: "...")
## House listing
{house}
... where we are substituting {house} with the house ad above. Let's see what OpenAI's GPT-3.5 turbo outputs:
From the house listing, the extracted information is as follows:
- Is pet friendly: Yes (quote: "Pet-Friendly: We understand that pets are an important part of your family. This house gladly welcomes your furry companions, allowing you to create lasting memories with your beloved pets.")
- Has a garden: Unknown (no mention of a garden in the listing)
- Has a parking place: Unknown (no mention of a parking place in the listing)
- Is suitable for a couple: Yes (quote: "Ideal for Couples: With its intimate atmosphere and well-designed layout, this house is an ideal choice for couples. Whether you're enjoying a romantic dinner in the dining area or relaxing in the cozy living room, this house provides a comfortable and intimate space for you and your partner.")
- Has a balcony: Yes (quote: "Balcony: Step out onto the balcony and enjoy your morning coffee or unwind with a glass of wine in the evening. The balcony offers a peaceful retreat where you can soak up the vibrant atmosphere of Amsterdam.")
Not bad! It seems to have most properties right, including those that it could not determine (Unknown). It also provided a quote in cases where it could extract the information.
We still, however, do not have the information in a structured format. That's a pity, because that's what we need to work with it. Let's try to retrieve the information in a structured format.
Going structured
So our goal is to get the information in a structured manner. Structure can take many forms. There are many structured file formats, for example. Think of JSON, XML, CSV, etc. We will use JSON because it is a very common format and it is easy to work with in Python.
We will explore different approaches to prompting the LLM. You can call this Prompt Engineering if you want. The goal is to determine which approaches work well with a chosen LLM model and which don't. Let's start.
1. JSON example
We are going to ask the LLM to provide its output in JSON. Therefore, we should inform the LLM about the format in which it should return the JSON. For this, we can simply give the LLM an example of the desired JSON output. This will be our prompt:
A house listing will follow, as it appeared on a housing website. Please extract the following information from the listing in a JSON response:
```
{
"is_pet_friendly": {
"value": ..., # yes/no/unknown
"quote": ..., # exact quote from listing
},
"has_garden": {
"value": ..., # yes/no/unknown
"quote": ..., # exact quote from listing
},
"has_parking_place": {
"value": ..., # yes/no/unknown
"quote": ..., # exact quote from listing
},
"is_suitable_for_couple": {
"value": ..., # yes/no/unknown
"quote": ..., # exact quote from listing
},
"has_balcony": {
"value": ..., # yes/no/unknown
"quote": ..., # exact quote from listing
},
}
```
... on which GPT-3.5 turbo has the following response:
{
"is_pet_friendly": {
"value": "no",
"quote": "Pets not allowed"
},
"has_garden": {
"value": "unknown",
"quote": "-"
},
"has_parking_place": {
"value": "yes",
"quote": "Parking possibility: Private parking place outside"
},
"is_suitable_for_couple": {
"value": "unknown",
"quote": "-"
},
"has_balcony": {
"value": "yes",
"quote": "Balcony (facing South-West)"
}
}
Note: this response was generated on a different input example than in the previous section.
That is cool! The LLM just returned a valid JSON. It provided the format that we desired, listing the properties as objects containing a value and a quote. We can parse this into Python using json.loads:
obj = json.loads(
response_text
)
... where response_text is the text that the LLM returned. That is great. We can now use the data in a structured manner in Python.
However, LLMs do not guarantee a certain output despite you asking for it. There can be cases, for example, when the house listing is so short that the LLM will hallucinate. Provided with too little input data, the LLM deviates from the asked-for format.
Consider this output the LLM generated:
"House listing"
{
"title": "Beautiful Modern House",
"description": "Spacious and modern house with stunning views. Perfect for a couple or small family.",
"location": "123 Main Street, Anytown, USA",
"price": "$500,000",
"is_pet_friendly": {
"value": "yes",
"quote": "Pets allowed with additional deposit."
},
"has_garden": {
"value": "yes",
"quote": "Large backyard garden with fruit trees."
},
"has_parking_place": {
"value": "yes",
"quote": "Two-car garage and additional street parking available."
},
"is_suitable_for_couple": {
"value": "yes",
"quote": "Perfect for a couple or small family."
},
"has_balcony": {
"value": "yes",
"quote": "Spacious balcony with beautiful views."
}
}
That was created using the same prompt as before. Now, however, the LLM returned all sorts of properties not asked for, like price, location, description and title. Even worse, the string at the top "House listing" makes the output invalid JSON. Parsing this yields:
JSONDecodeError Traceback (most recent call last)
……
----> 1 obj = json.loads(
2 response["choices"][0]["message"]["content"]
3 )
……
JSONDecodeError: Extra data: line 2 column 1 (char 16)
... that's an error.
To prevent this from happening, the input can be checked up front to check whether there's enough data to work with. Still, if we want to repair like this, there can be two strategies:
- Re-run the prompt. Given that we set the
temperaturehigher than 0.0, the LLM can generate another response. Perhaps it will generate a valid JSON this time. - Show the LLM its own error. Better yet, we can run another prompt but include the error itself. We will ask the LLM to consider the error and provide a valid JSON the next time.
These methods can help us try to repair the previously generated error. But are there better ways to let the LLM retrieve this structure from the data? Let's try another approach.
2. Pydantic schema
Before, we were giving the LLM an example JSON output that it could work with. But can we provide a more exact definition of our desired output? We can use it pydantic for that. Pydantic is a data validation library for Python, which has useful functions for serializing and deserializing JSON. We can define a class that describes the to-be-extracted properties:
from typing import Optional
from pydantic import Field, BaseModel
class HouseFeature(BaseModel):
was_extracted: bool = Field(..., description="Whether the feature was extracted")
quote: Optional[str] = Field(
default=None, description="Exact quote from the listing"
)
value: Optional[bool] = Field(
default=None, description="Whether the house has the feature"
)
class HouseFeatures(BaseModel):
"""Correctly extracted house listing features"""
is_pet_friendly: HouseFeature
has_garden: HouseFeature
has_parking_place: HouseFeature
is_suitable_for_couple: HouseFeature
has_balcony: HouseFeature
So these two classes describe the information that we want to extract. Now we can utilise all of Pydantic's functionality to help formulate the prompt and parse the response afterwards. Pydantic lets us print an elaborate schema of the models using HouseFeatures.model_json_schema() like so:
output_template = HouseFeatures.model_json_schema()
output_template_str = json.dumps(output_template)
... where the output_template_str is now a JSON string containing all the details:
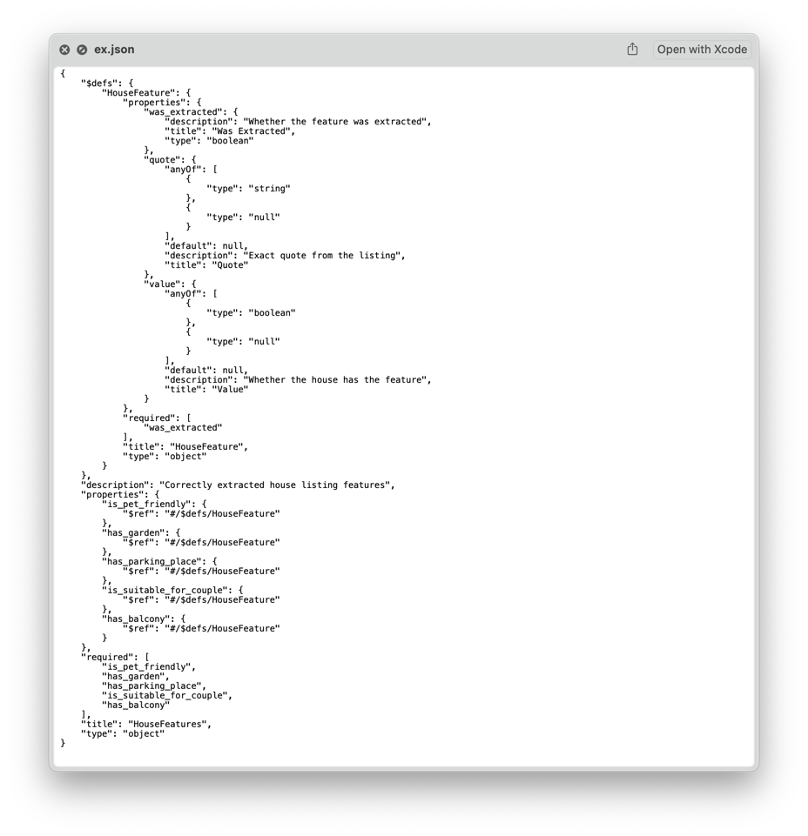
That is very detailed information! The exact desired types of each of the attributes is defined, like boolean, string or null. We can now use this to formulate a new prompt:
A house listing will follow. Your task is to extract details from the house listing. Fill in the following template:
# template
{output_template_str}
# house listing
{str(house)}
... here we are substituting the output_template_str for the Pydantic schema we just generated. Let's see what the LLM returns.
{
"is_pet_friendly": {
"was_extracted": false
},
"has_garden": {
"was_extracted": false
},
"has_parking_place": {
"was_extracted": true,
"value": true,
"quote": "Parking in front of the building is available through a permit system"
},
"is_suitable_for_couple": {
"was_extracted": true,
"value": true,
"quote": "preference for single household"
},
"has_balcony": {
"was_extracted": true,
"value": true,
"quote": "east-facing balcony (morning sun) spans the entire width of the apartment and overlooks the beautiful courtyard"
}
}
Perfect! That looks like a valid JSON. Now comes the fun part. To deserialize the JSON back into an instance of the Pydantic model, we can simply do:
house_features = HouseFeatures.model_validate_json(
response_text
)
And like that, we are in the Python world. Additionally, Pydantic can give descriptive errors in cases where parsing fails. We can then deploy the strategies described in the previous section to try to fix the parsing.
This is already a powerful technique. However, we are, of course, very curious about what else is possible. OpenAI has something in store for us.
3. OpenAI Function Calling
In June 2023, OpenAI announced support for function calling. This allows you to define functions that the LLM can choose to call as part of its response. GPT-3.5 and GPT-4 are finetuned to respond in a specific format when we provide functions. Actually calling the function code is still on your side, but the LLM can suggest which function to call and with which arguments. Think of use cases like retrieving the current weather, executing a SQL query, or sending a message to a recipient. But we can exploit the same for our use case: what if we define a function that has as arguments the properties that we want to extract? Let's find out together.
First, we define a function in the required OpenAI format:
functions = [
{
"name": "extract_house_features",
"type": "function",
"description": "Extract features and properties from a house listing text.",
"parameters": {
"type": "object",
"properties": {
"is_pet_friendly": {
"type": "boolean",
"description": "Whether the house allows pets"
},
"has_garden": {
"type": "boolean",
"description": "Whether the house has a garden"
},
"has_parking_place": {
"type": "boolean",
"description": "Whether the house has a parking place"
},
"is_suitable_for_couple": {
"type": "boolean",
"description": "Whether the house is suitable for couples"
},
"has_balcony": {
"type": "boolean",
"description": "Whether the house has a balcony"
},
},
"required": [
"is_pet_friendly",
"has_garden",
"has_parking_place",
"is_suitable_for_couple",
"has_balcony"
]
},
}
]
That elaborately describes the function, with all arguments, their types, and whether they are optional or required. We can now pass this functions object to the OpenAI ChatCompletion API:
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-0613",
deployment_id="gpt-35-turbo-us",
messages=messages,
functions=functions,
function_call={
"name": "extract_house_features”
},
)
Noteworthy here is the function_call parameter. This forces calling that function in every call, which is the desired functionality for our use case.
Additionally, we are going to provide the LLM with a different context:
Assistant is a large language model designed to extract structured data from text.
Also called the system prompt. See this post. The system prompt helps point the LLM more specifically toward its goal. We only need a prompt:
{house}
That just got super short! All instructions are already encapsulated inside the context and the function description. Let's see what the LLM returns:
{
"name": "extract_house_features",
"arguments": "{n "is_pet_friendly": false,n "has_garden": false,n "has_parking_place": true,n "is_suitable_for_couple": true,n "has_balcony": truen}"
}
That is a JSON formatted in a specific format. The format is such that it can directly be used to execute the function we defined earlier. In particular, the function is to be executed using certain values that the LLM has also defined for us: this is the data that we desired to extract. Note that for simplicity's sake we did not include the quote property in the function definition.
We can now parse this JSON and actually call the function:
function_call_args = json.loads(
function_call["arguments"]
)
extract_house_features(
**function_call_args
)
... which brings our data into the structured, Python world. That is great! There is even another way to make it even better. There is a library that makes the former process a bit easier.
Instructor library
The GitHub instructor library provides some shortcuts for what we did above. Instead of meticulously defining our function definition in JSON like above, we can now use a Pydantic model to define which information we want. From this Pydantic model, we can generate the function definition. This works like so:
from instructor import OpenAISchema
class HouseFeatures(OpenAISchema):
"""Correctly extracted house listing features"""
is_pet_friendly: bool
has_garden: bool
has_parking_place: bool
is_suitable_for_couple: bool
has_balcony: bool
If we now call HouseFeatures.openai_schema the schema will be printed, containing a function with the properties as arguments. We can now do the LLM call like so:
prompt = str(house)
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-0613",
deployment_id="gpt-35-turbo-us",
functions=[HouseFeatures.openai_schema],
function_call={"name": HouseFeatures.openai_schema["name"]},
messages=[
{"role": "system", "content": "Assistant is a large language model designed to extract structured data from text."},
{"role": "user", "content": prompt}
],
)
house_features = HouseFeatures.from_response(response)
... where house_features now contains our structured data in a Pydantic model! Using the instructor library the process got even smoother ✨.
Conclusion
Unstructured data, like text, can potentially contain very valuable information. LLMs can help us extract this information. There are three main approaches to do this:
- JSON example. Provide the LLM with an example of the desired JSON output, instructing it to generate an output in the same format. This is straightforward, but it can be prone to producing outputs in the wrong format. Performance varies per LLM used.
- Pydantic schema. Using
pydanticwe can define a schema of the desired output. We can then use this schema to formulate a prompt. The LLM will then try to generate a JSON in the same format. Powerful technique, but no guarantees for better performance. Again, performance varies per LLM used. - OpenAI Function Calling. Using OpenAI's Function Calling API, we can instruct the LLM to call a function with the desired properties as arguments. OpenAI's models are fine-tuned to produce a specifically formatted output that can easily be parsed. This can be a lot more robust than the former, but it is only usable with OpenAI's models.
Try out different models to see which works best for your use case. Models from different providers or even Open-Source handle each method with varying performance. An experiment is justified to see which works best for you.
Great, you've been reading along & good luck with your own use case!
Code with examples available at: Dataset enrichment with llms
This content was also featured in a PyData talk! Check out the recording here: Jeroen Overschie - Dataset enrichment using LLM's ✨ Youtube
Written by

Jeroen Overschie
Machine Learning Engineer
Jeroen is a Machine Learning Engineer at Xebia.
Our Ideas
Explore More Blogs




Contact