Blog
How to Extract Structured Data from Unstructured Text using LLMs

In today's world, more organizations strive for data-driven decision-making. However, they commonly face the challenge of extracting valuable insights from unstructured text data, such as customer reviews or feedback.
This post is tailored for data scientists, analysts, and decision-makers who want to use unstructured data to get useful insights. We explore a batch use case for Large Language Models (LLMs), focusing on the transformation of unstructured text into structured data. By leveraging this approach, businesses can enrich their databases with structured information and improve their understanding of unstructured data sources. To illustrate this type of use case, we will delve into the example of customer feedback analysis.
This repository provides a general setup for you to get started with this type of LLM batch use case.
Use case: customer feedback
Let's take the example of customer reviews on a webpage, corresponding to a specific product.

We may have some structured information available, such as the number of stars each customer gives. However, we may want more specific information. For example, why has a customer given a high or low rating? To find out, we would need to read and filter these reviews ourselves. In the case of 100s of reviews for 1000s of products, this becomes an infeasible process.
Ideally, perhaps, we would see ratings for each topic, such as quality, shipping, price, etc. This has two benefits:
- We would be better able to identify what we can improve.
- We would help customers to make better decisions when buying a product.
In the figure below, we can see such an overview of ratings per topic.
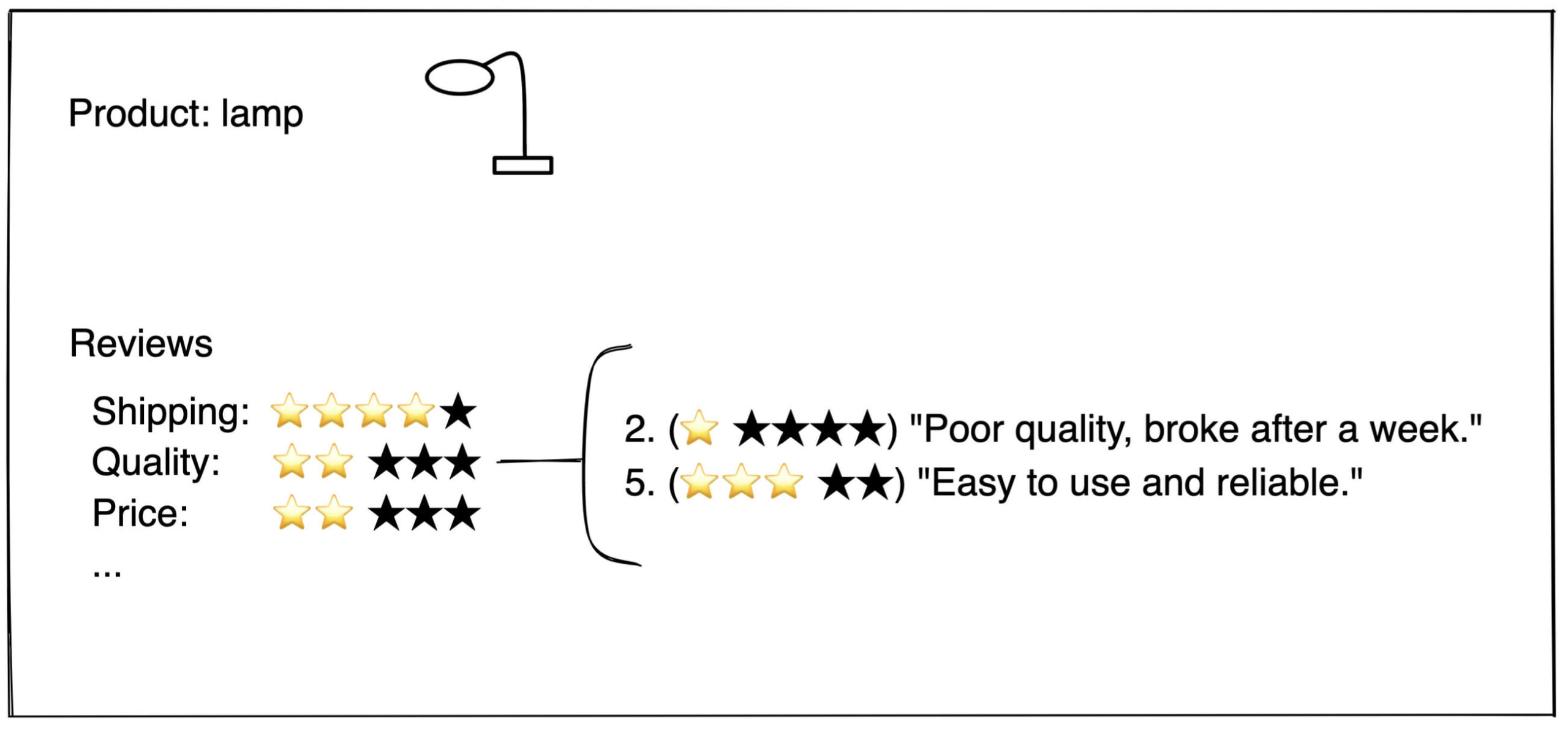
Based on the figure, a sharp eye may notice we're averaging ratings of all reviews mentioning a certain topic. This doesn't work so well if we get a review mentioning multiple topics: "Great quality, bad shipping". In that case, we may falsely assign a low rating to quality, or a high rating to shipping. However, to keep our example simple, we ignore those type of reviews for now.
You may wonder, why not let the customer provide feedback on each of these topics directly? Well, in that case, the review process will be become more complex. This may cause the customer not to review at all.
So, how do we do this? We need a scalable way to extract structured information, i.e. the topic, from the unstructured text, i.e. the review.
You might also be interested in: Cloud Trainings | Data & AI Trainings
Extract structured information using an LLM
In this example, we use an LLM because of its flexibility and ease of use. It allows us to complete the task without training a model. But note that for very structured outputs, a simple classification model could also be trained once enough samples are collected.
We can take the following approach:
- Create a clever prompt
- Give the unstructured text to an LLM
- Retrieve the structured output from the LLM
- (Save it to a database)
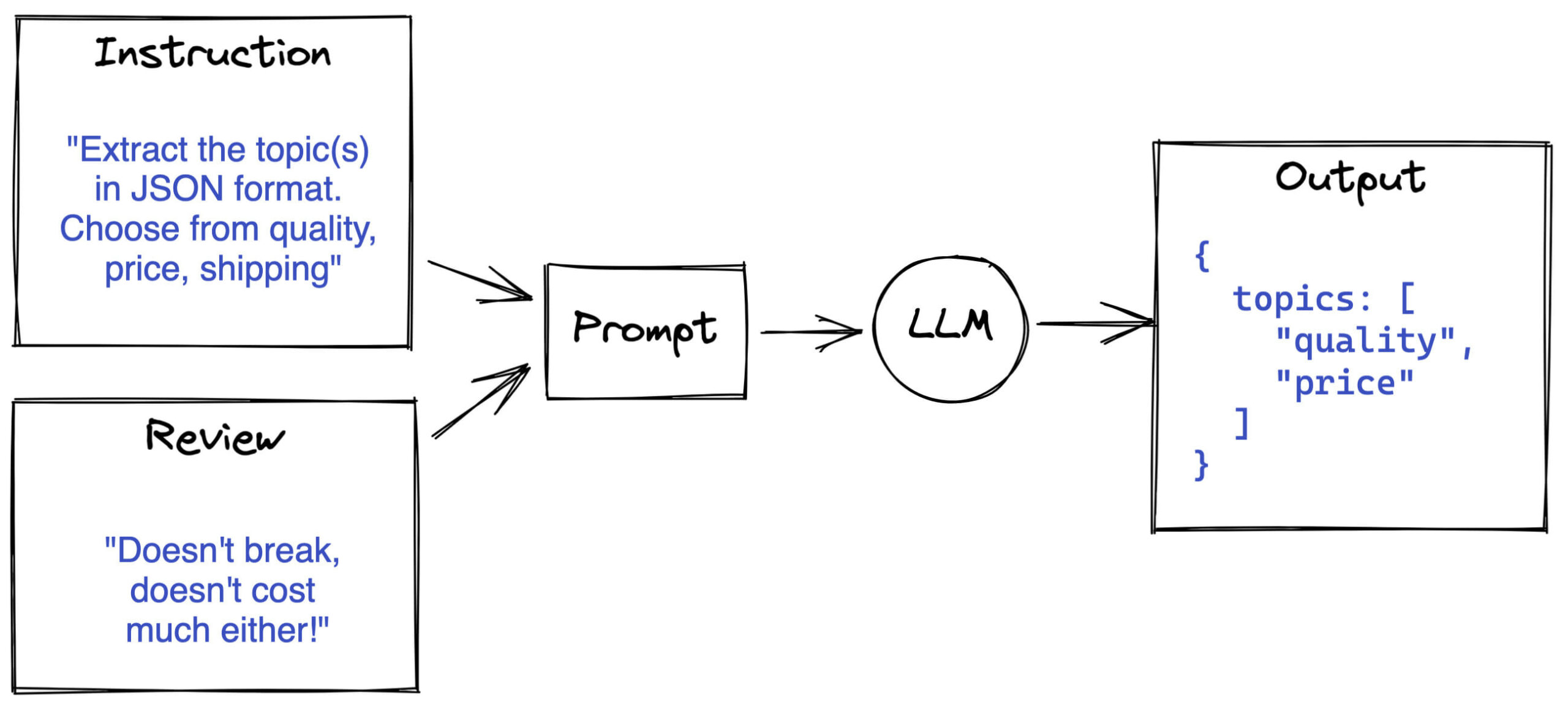
We try to enforce the LLM to output valid JSON, because we can easily load raw JSON as an object in Python. For example, we can define a Pydantic BaseModel, and use it to validate the model outputs. In addition, we can use its definition to immediately give the model the right formatting instructions. To read more about enforcing an LLM to give structured outputs, check out our previous blog post.
Our Pydantic BaseModel would look something like this:
from typing import List, Literal
from pydantic import BaseModel, Field
class DesiredOutput(BaseModel):
topics: List[
Literal[
"quality",
"price",
"shipping",
]
] = Field("Topic(s) in the input text")
However, the model might not get it right the first time. We can give the model a few tries by feeding validation errors back into the prompt. Such an approach can be considered a Las Vegas type algorithm. The flow then looks like:
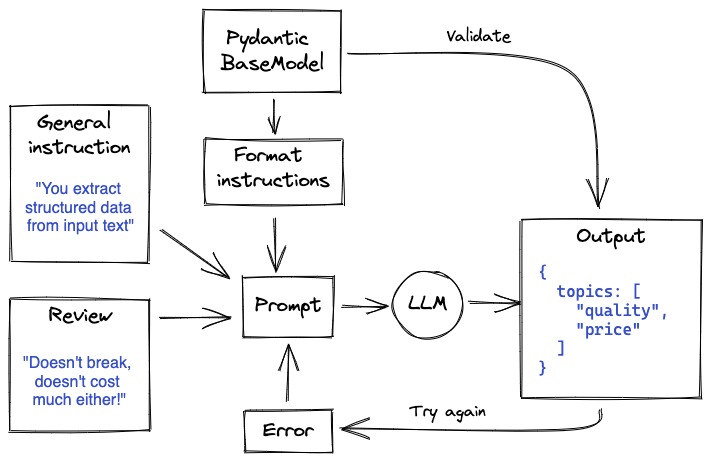
That's it! At least for the basics. We can extend this, for example by allowing for a general user-defined schema, which can then be parsed into a Pydantic BaseModel. 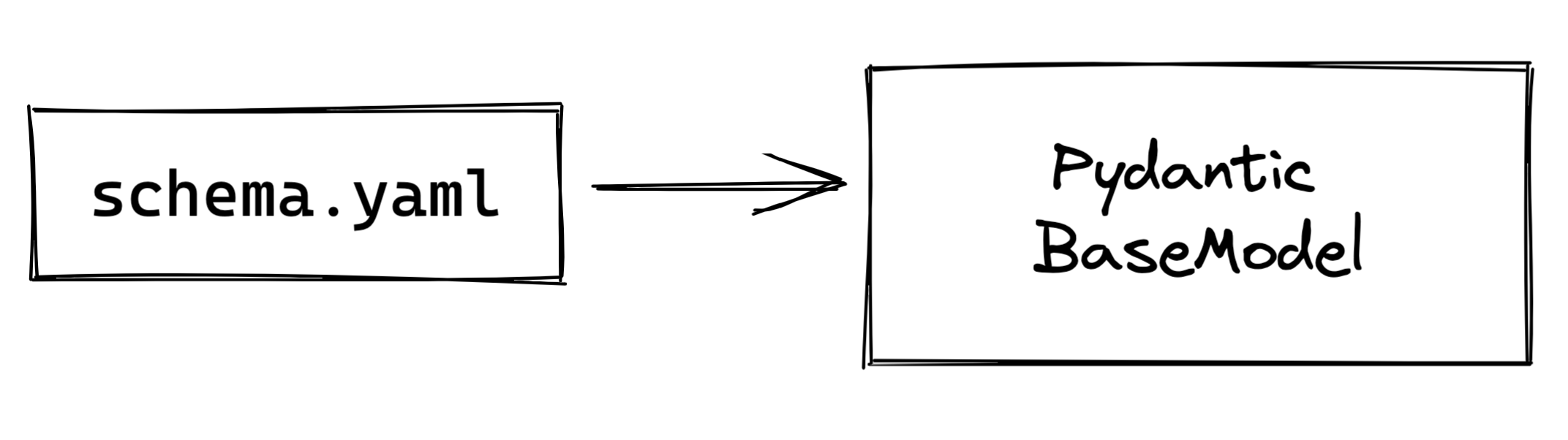
Structuring as batch operation
As a last step, we separate our logic from our inputs and outputs, so we can easily run these operations on new batches of data. 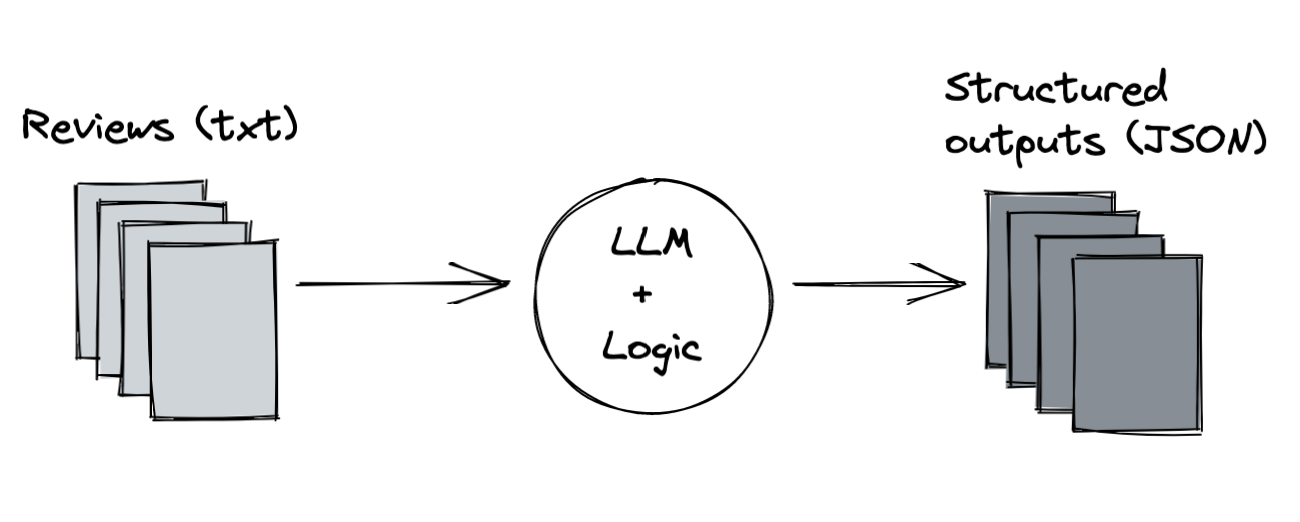 We can do so by parametrizing the location to the input reviews, and the output location for the JSON files. We use these to load reviews and store output files as we run our batch.
We can do so by parametrizing the location to the input reviews, and the output location for the JSON files. We use these to load reviews and store output files as we run our batch.
When we run our batch job, we prompt the LLM (using the logic as described in previous section) once per review. The review itself can be dynamically inserted into our prompt using a prompt template, which was implemented in the source repo here.
Subsequently, we can use the output JSONs however we want. They should contain all the information we specified in our BaseModel. In the example of customer reviews, we can now easily group the reviews together by topic with the available structured information.
After we get this running locally, all that's left to do is to enable this batch operation to run on a server for a given time interval. But we leave that out of scope for this post.
Generalizing the solution
The above solution is already applicable to many use cases where we want to extract structured information from unstructured input data. However, to generalize even further we can add the functionality to process pdf documents as well, as these are often the starting point of text-related use cases.
On a high level, the overall solution then roughly becomes:
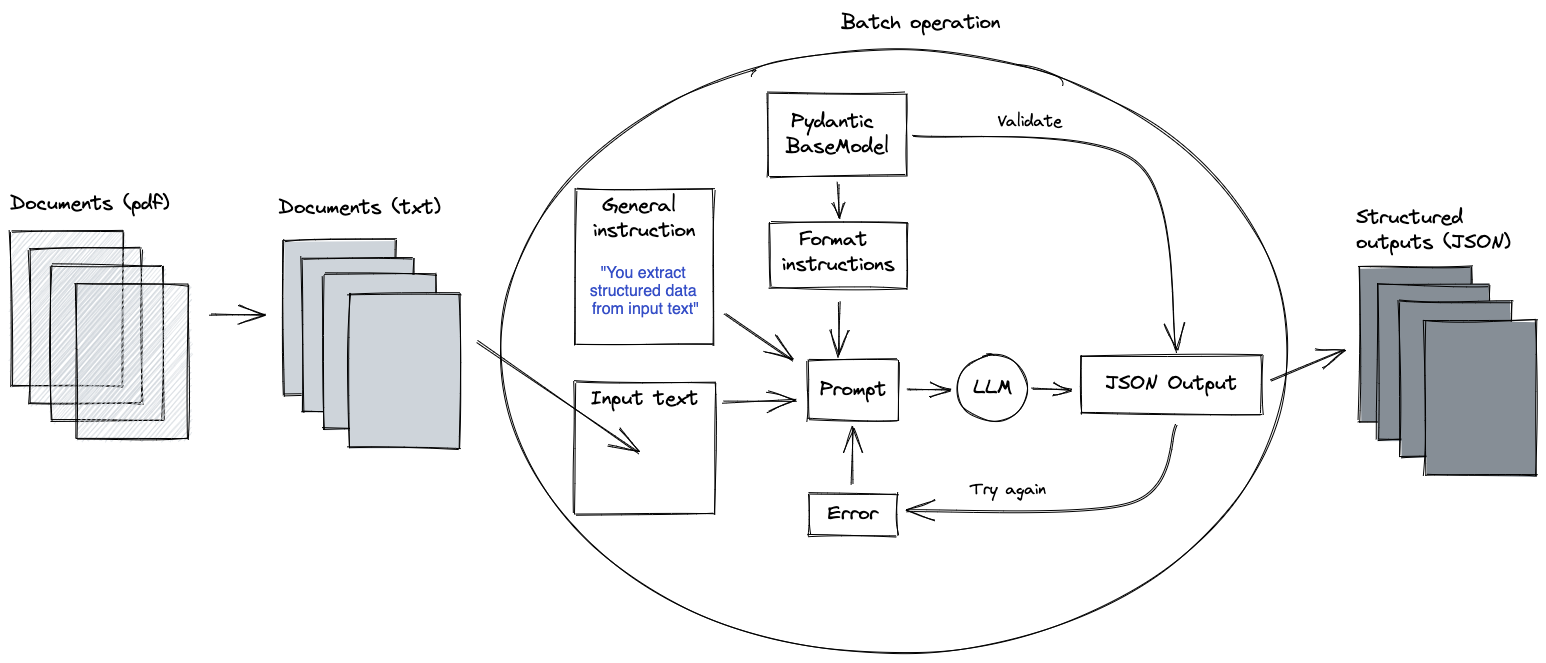
In the source repo, we have assumed the simple case where the documents are small enough to be fed through an LLM all at once. In some cases however, pdfs span dozens of pages. The input then becomes too large for an LLM, and additional processing needs to be implemented.
Conclusion
In this blog post, we explored a typical batch use case for LLMs, focusing on extracting structured data from unstructured text. We demonstrated this approach through the example of customer feedback analysis. By using an LLM and a well-designed prompting strategy, we can efficiently convert unstructured text data into structured information. We can then use this information to enrich our databases and facilitate better decision-making.
The provided repository showcases this type of use case in its basic form and can be easily adapted to your specific needs. We encourage you to try it out with your own data and explore the possibilities of leveraging LLMs to extract valuable insights from unstructured text.
Photo by Brett Jordan on Unsplash
Written by
Yke Rusticus




Contact