Blog
Databricks Lakehouse Optimization: A deep dive into Delta Lake's VACUUM

Databricks is a powerful Data + AI platform that enables companies to efficiently build data pipelines, perform large-scale analytics, and deploy machine learning models. Organizations turn to Databricks for its ability to unify data engineering, data science, and business analytics, simplifying collaboration and driving innovation.
However, managing costs can be challenging, a reality that applies to any cloud-based or on-premise service. As businesses grow, total costs increase, making cost efficiency a key area of focus.
This blog will be part of a series that focuses on cost optimization in the Databricks ecosystem, starting with Delta Lake storage. We’ll begin by highlighting the importance of regular table maintenance for managing storage in Delta Lake, then explore how the VACUUM command helps optimize storage costs, share strategies for its efficient use, and introduce Databricks' managed service for automating the process. By the end of this blog, you'll have actionable techniques to optimize Delta Lake storage to lower costs.
Optimizing Storage Costs in Delta Lake
Delta Lake is a core component of Databricks, offering ACID transaction support and a high-performance storage format for managing large datasets.
Nevertheless, storing vast amounts of data in Delta tables without regular maintenance can result in wasted storage space and inflated costs.
Before diving into storage optimization techniques, we’ll first cover some theory about the inner workings of Delta tables. Understanding how Delta manages data and the transaction log will provide the foundation needed to grasp the importance of regular table maintenance.

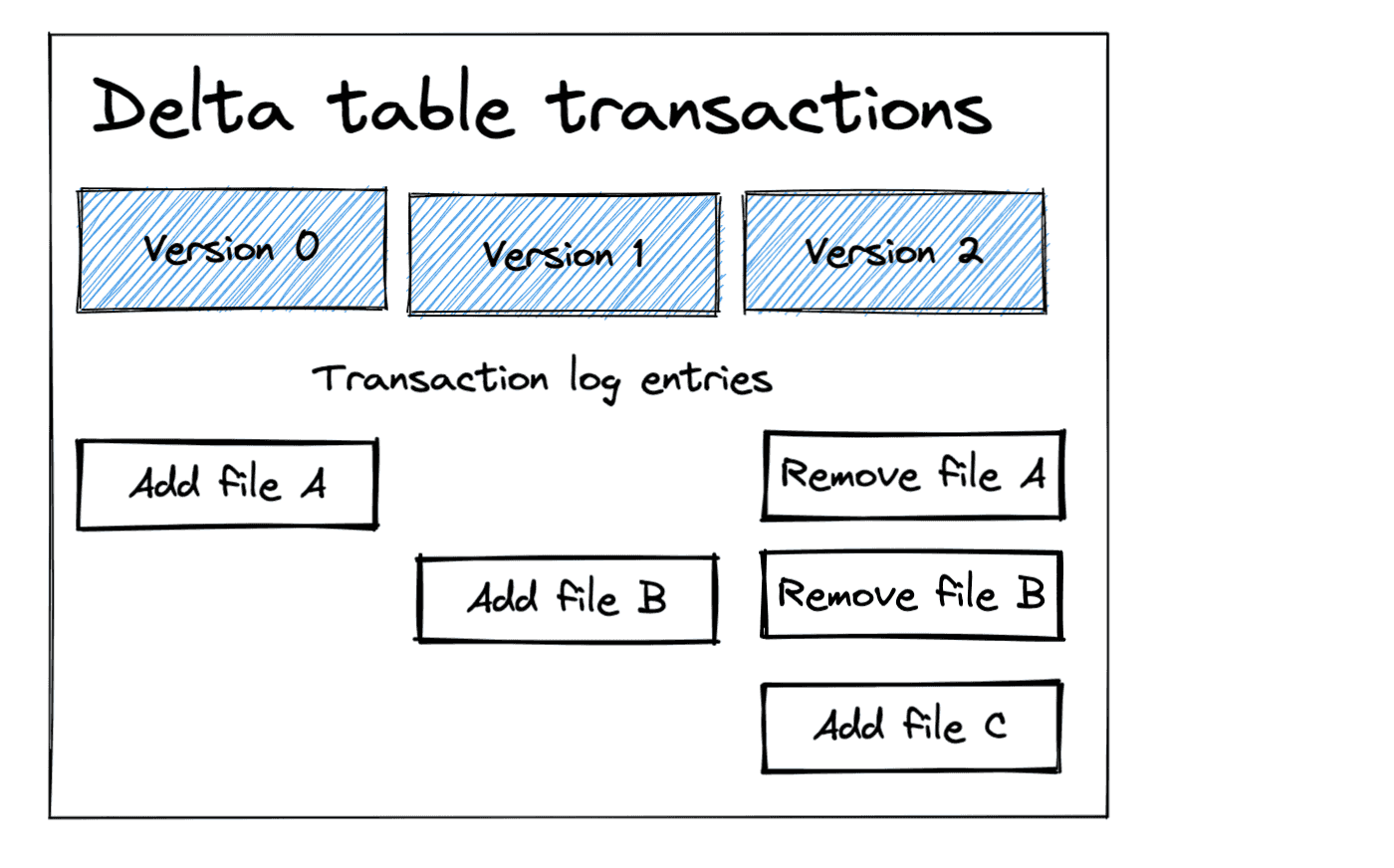
Delta Lake's transaction log
Delta tables maintain historical versions of your data, enabling time travel that allows you to query older snapshots. This capability relies on the Delta transaction log, which records the necessary files for each version.
To support time travel, Delta Lake retains:
- The transaction log
jsonentry for the desired version.- These entries are deleted automatically each time a checkpoint is written based on the log retention period.
- The associated
parquetdata files for that version.- These files are added or marked for removal in the transaction log.
- These files are not deleted automatically.
Each version represents a specific state of the table at a given point in time, capturing all changes made through operations known as transactions. Transactions capture metadata about the changes in the Delta transaction log.
The transaction log primarily tracks:
- Data files that were added to the table during each transaction.
- We can't update the already existing parquet files since parquet files are immutable. We also need them in order to time travel to a previous state of the table. This means that even for operations that affect a single record we have to create a new parquet file
- Data files marked for removal after a transaction has completed, ensuring ACID compliance by maintaining consistency and isolating changes until they are fully committed.
While the Delta log tracks additional metadata that can optimize compute performance, this post focuses on these two core aspects relevant to managing storage costs.
Key Points to Remember
- Log entries are cleaned up automatically.
- Data files marked for deletion are not cleaned up automatically.
- Thus, if these data files aren't regularly cleaned up, storage costs will continue to rise as unused data accumulates.
Delta Lake's VACUUM command
Fortunately, Delta Lake provides a VACUUM command that cleans up storage by safely deleting files in the delta table storage directory.
This includes:
- Files older than the file delete retention period that have been marked for removal in the transaction log.
- All other files not managed by Delta Lake i.e. files that are not referenced in the transaction log
This excludes:
- Files stored in underscored directories like
_checkpointsor_delta_log. - Files younger than the file delete retention period.
- Files that are actively being referenced by the latest snapshot of the table.
Running the VACUUM command is supported for SQL, Python, Scala and Java workloads. For examples, consult the extensive delta documentation
VACUUM properties for delta tables
You can adjust the retention period for Delta tables based on your time travel requirements. For some tables, you may want to retain all versions indefinitely, while others might benefit from more frequent cleanup. There are two relevant delta table properties you can adjust:
delta.deletedFileRetentionDurationThe shortest duration for Delta Lake to keep data files marked for deletion before deleting them. The default is 7 daysdelta.logRetentionDurationHow long the transaction log entries (versions) for a Delta table are retained. Each time a checkpoint is written, Delta Lake automatically cleans up log entries older than the retention interval. The default is 30 days
Things to take into consideration:
- As mentioned earlier, to preserve the ability time travel you need to retain the log entry and data files for that version. For example, if you want to always travel back 10 days you need to set both to be at least 10 days.
- Specifically for setting
delta.deletedFileRetentionDuration- This setting should be larger than the longest possible duration of a job if you run
VACUUMwhen there are concurrent readers or writers accessing the Delta table. - You need to ensure that any queries that process data incrementally from this table, have already processed data from the deleted versions/files
- This setting should be larger than the longest possible duration of a job if you run
⚙️ VACUUM under the hood
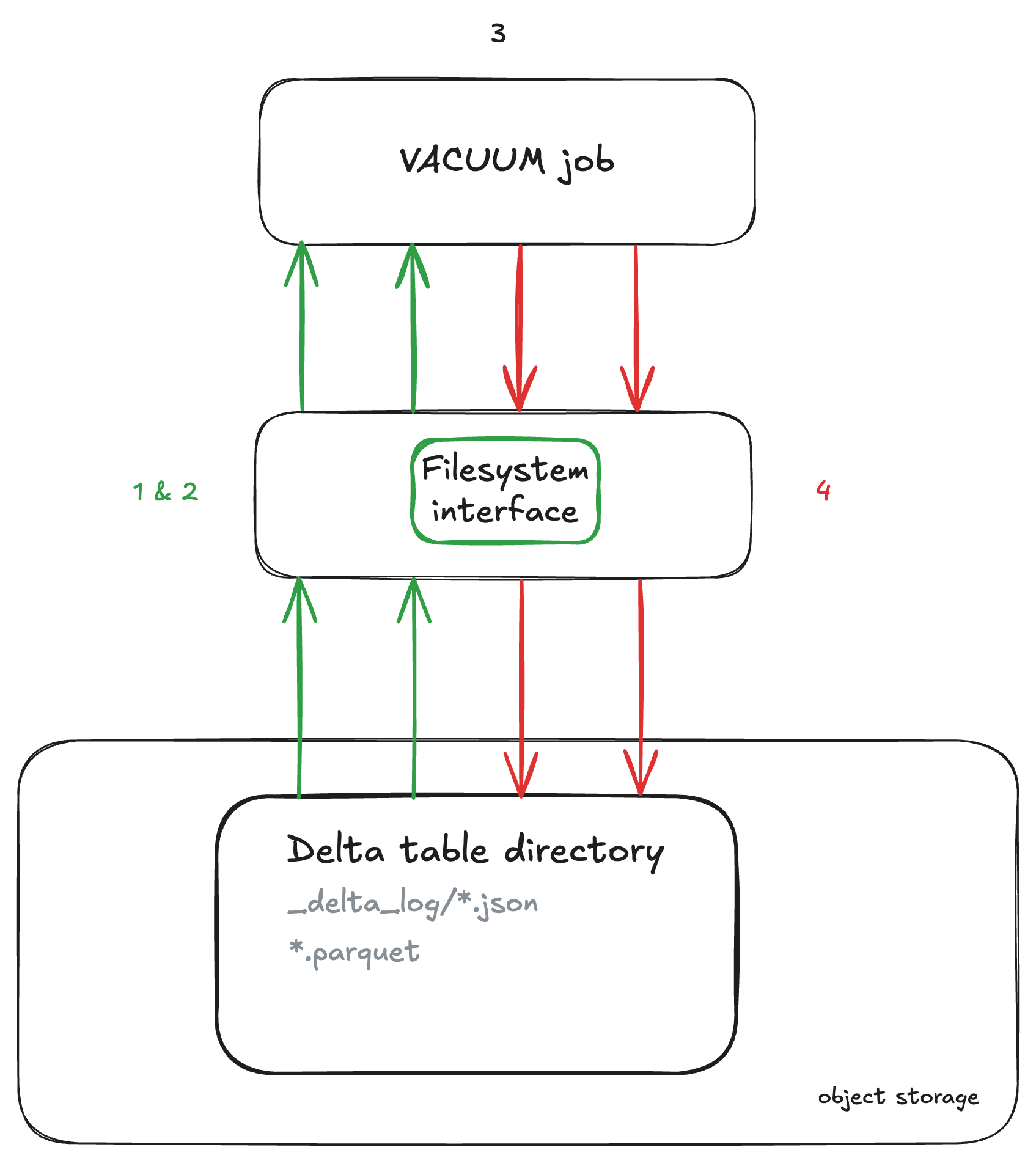
- The
VACUUMcommand first gets a list of actively referenced delta files from the latest table snapshot using the_delta_logtransaction log. - It recursively navigates the contents of the Delta table directory using the relevant filesystem interface for the object storage (e.g., S3, Azure Blob Storage). The level of parallelism is affected by the cardinality of the directories; a greater number of unique directory entries across all levels facilitates more concurrent processing opportunities (partition directories) and supports horizontal scaling across worker nodes. The time required for the listing operation can vary widely, ranging from just a few minutes to several hours, depending on the size and complexity of the partitions. Hidden directories are omitted from the listing.
- After this the result set is calculated which is the substraction of all of the files in the table directory excluding the files that are in the state (latest snapshot) or younger than the deletion retention period.
- Finally, we can safely start the actual deletion of the files . This can be done in parallel using multiple threads on the driver node. To configure this you can set the spark setting
spark.databricks.delta.vacuum.parallelDelete.enabledtotrue.
For those interested in more details please refer to the scala code here.
VACUUM more efficiently USING INVENTORY
In May 2024, Delta Lake introduced VACUUM USING INVENTORY with version 3.2.0, now supported in the Databricks runtime 15.4 LTS (released August 2024).
This feature allows users to provide an inventory of files, either as a Delta table or a Spark SQL query, to replace the traditional file listing in VACUUM. It turns VACUUM into a two-stage process: first, identifying unreferenced files by comparing the inventory with the Delta log, and then deleting those files.
You can use cloud storage inventory services like Azure Storage Blob Inventory, which generates daily or weekly reports in CSV or Parquet format. These reports include details on containers, blobs, blob versions, and snapshots, along with their properties. This simplifies auditing, retention management, and data processing, while making it easier to identify files for deletion during VACUUM. Blob inventory rules also let you filter the report by blob type, prefix, or specific properties to further streamline VACUUM operations.
Using an inventory-based approach offers several advantages. It is significantly more cost-efficient compared to live file listing APIs, reducing both storage listing charges and compute time. It also improves performance by speeding up the VACUUM process, allowing multiple tables to be handled in fewer jobs and with less frequent execution.
For more detailed information and practical examples, please refer to the extensive delta documentation
The light-weight version of VACUUM
In Delta Lake 3.3.0 (supported in the Databricks runtime 16.1) and above, a new mode called VACUUM LITE was introduced to optimize the process of removing unused files. This mode is designed to run faster than the traditional VACUUM command by leveraging the Delta transaction log instead of scanning the entire table directory.
When you run VACUUM LITE, it identifies and removes files that are no longer referenced by any table versions within the retention duration. This is achieved by directly using the Delta log, which significantly reduces the overhead associated with listing all files in the table directory.
This lightweight mode is ideal for quickly cleaning up unused files without the full cost of a traditional VACUUM. It’s perfect for maintaining table performance and storage efficiency, especially in environments requiring frequent cleanups. For cost-effective maintenance, combine regular VACUUM LITE operations with occasional standard VACUUM for deeper clean-ups.
Configuration for VACUUM jobs
Regular maintenance is essential for Delta tables, and running VACUUM is a key task that should be performed routinely. You can schedule one or more jobs to run the VACUUM command on a selected set of tables.
With a clear understanding of how the VACUUM command works, we can design an optimized job configuration to ensure efficient storage management:
- When not using an
INVENTORYto runVACUUM, the file listing process can scale horizontally across worker nodes and is primarily compute-intensive rather than memory-intensive. To maximize efficiency, we will use an auto-scaling cluster configuration to handle varying loads, ensuring flexibility and speed during the listing phase. - The file deletion process runs on the driver node and can leverage multiple threads. Like the listing phase, this step is compute-intensive, requiring a more powerful driver node with increased CPU cores to boost parallelism during the deletion phase.
The final configuration
- Auto-scaling cluster with compute-optimized worker nodes, tailored for compute-heavy tasks during the file listing process.
- A larger compute-optimized driver node with additional cores to maximize parallelism for file deletion, ensuring efficient handling of this single-thread-sensitive phase.
- In the cluster spark configuration, we will set
spark.databricks.delta.vacuum.parallelDelete.enabledtotrueso that theVACUUMoperation will perform deletes in parallel.
This configuration balances scalability and performance, ensuring optimal use of resources during both listing and deletion phases.
Dynamically targeted VACUUM operations using cloud storage & table metadata
Understanding how your data is stored and utilized is crucial for optimizing costs, and combining both cloud storage metadata and table metadata provides valuable insights.
1. Cloud storage metadata
Cloud providers like AWS, Azure, and GCP offer detailed metadata about your storage usage. Services like AWS S3 Inventory, Azure Blob Inventory or GCP's Storage Insights inventory can give you a breakdown of the size, age, and access patterns of your stored files. By analyzing this data, you can identify old or infrequently accessed files and move them to cheaper storage tiers, or even delete them if they are no longer necessary. You can configure the storage inventory service to get these reports (datasets) on a daily/weekly basis in csv or parquet format.
2. Table metadata in Databricks
Within Databricks, you can query metadata about your tables using SQL. For instance, SQL commands allow you to retrieve the size of your Delta tables, the owner, the partition columns, the number of partitions, and the total number of actively referenced delta files. By leveraging this metadata, you can identify inefficiencies, such as tables with an excessive number of small files or those that occupy more space than anticipated. While Databricks currently lacks built-in table inventory reports for all the metadata fields we’re interested in, we have devised a method to efficiently extract table metadata for all tables. We’ll cover this approach in an upcoming post.
3. Combining the two metadata sources
One of the most effective strategies is to compare the table metadata with the cloud storage metadata. This allows you to check whether the size of the latest snapshot (version) of your Delta table aligns closely with the actual storage size in the cloud. While some discrepancy is expected due to Delta’s version tracking, a significant mismatch is a red flag. Large differences may indicate orphaned files or inefficient storage usage, signaling the need for a VACUUM to clean up stale data and optimize storage costs.
Below are the Databricks visualizations that I was able to create by joining the two metadata sources.
Top 50 tables with the most VACUUUMable storage
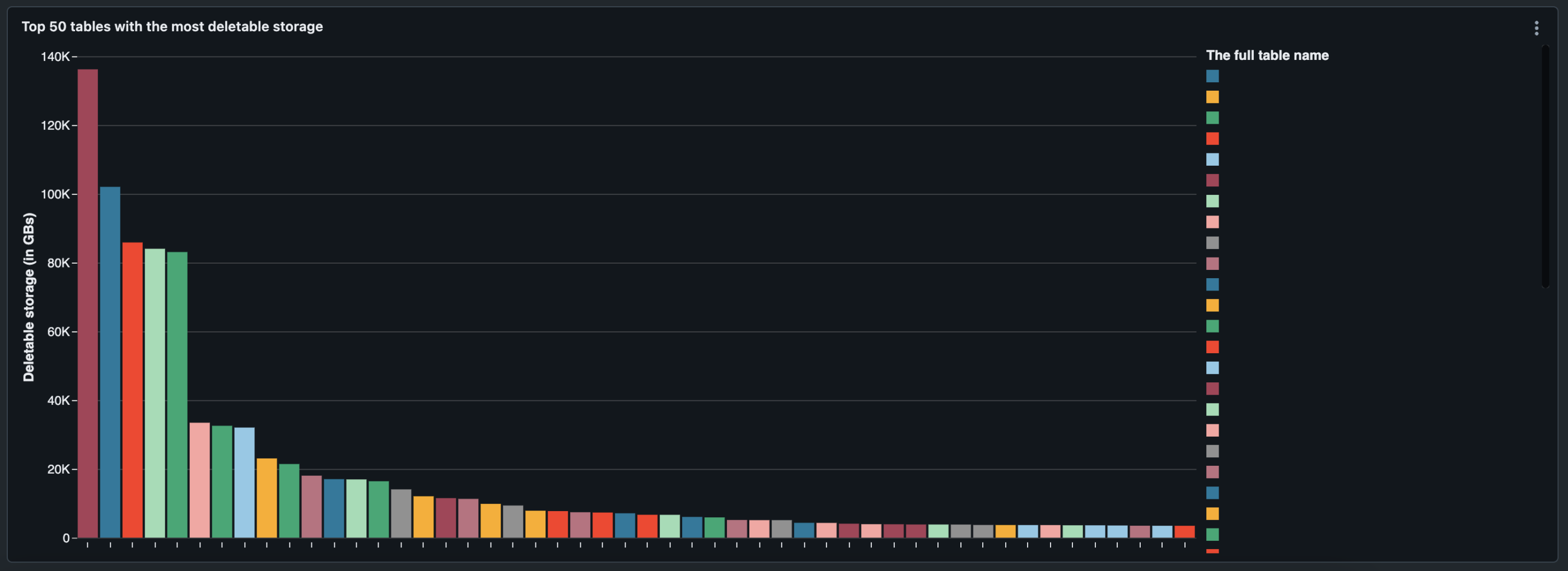
In the visualization above, you can see which tables have the largest size discrepancy between the latest Delta table snapshot and cloud storage.
VACUUMable storage per storage account over time
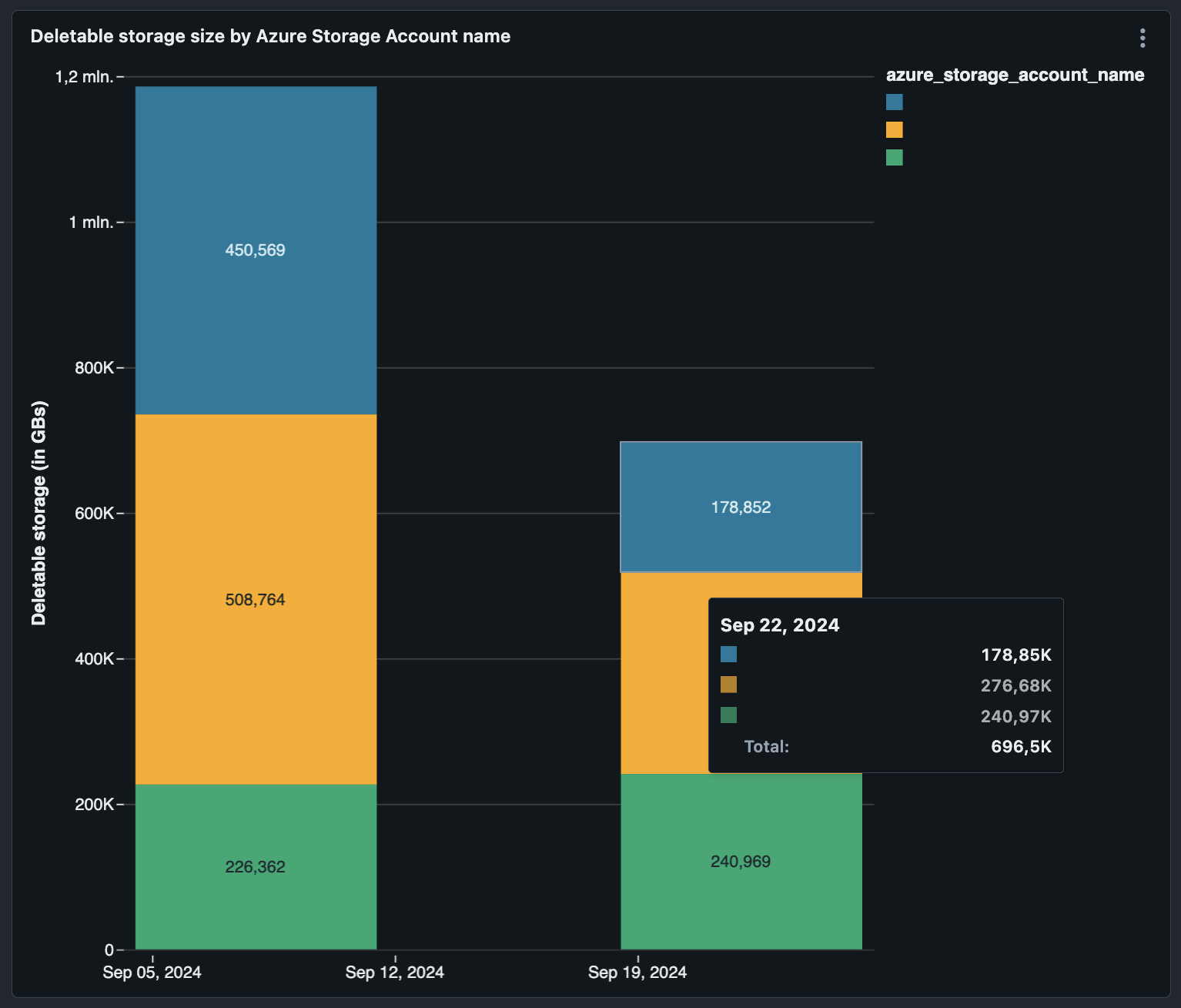
In the above visualization, you can observe which storage accounts display the largest size discrepancies between the most recent Delta table snapshot and cloud storage over time.
Benefits of this (meta) data-driven approach
- Instead of having a scheduled job running
VACUUMacross all or a statically defined list of tables, you can dynamically target those with a significant size discrepancy, ensuring efficient storage management and minimizing unnecessary operations. - Likewise, you can also filter out tables dynamically based on the number of files in the delta table directory. Since the performance of
VACUUMis highly dependent on the number of files it might be more efficient to first address the underlying problem e.g. rewriting over-partitioned tables first and then after validation deleting the entire underlying storage directory which can be done recursively using cloud storage APIs. - Additionally, by analyzing both metadata sources, you can identify storage locations that are no longer referenced by any tables in the catalog. This often happens when external tables are deleted from the catalog, as deleting an EXTERNAL table does not remove the underlying data in cloud storage. These orphaned storage locations are prime candidates for cleanup.
️ Automated VACUUM (managed by Databricks)
Predictive optimization in Databricks streamlines table maintenance for Unity Catalog managed tables by automating the identification and execution of necessary operations. This eliminates the need for manual intervention, ensuring that essential tasks like VACUUM are run only when beneficial, reducing the overhead of monitoring and troubleshooting performance issues.
Note: Predictive optimization also supports running
OPTIMIZE, which improves query performance. We will coverOPTIMIZEin detail in the next episode of this series.
Limitations
While predictive optimization offers significant advantages, there are some limitations to be aware of:
- Regional Availability: Not all Databricks regions support predictive optimization.
- File Retention Settings: Predictive optimization skips
VACUUMon tables where the retention window is set below the default of 7 days. - Unsupported Table Types: Predictive optimization does not apply to
- Delta Sharing recipient tables
- External tables
- Materialized views
- Streaming tables
For more information on predictive optimization please refer the documentation here.
Key takeaways
1. Don't wait for your storage costs to spike! Run VACUUM regularly.
By ingesting and combining both table and cloud storage metadata on a regular basis, you can target specific tables for optimization. Also consider using VACUUM LITE for frequent, lightweight cleanups and reserve regular VACUUM for occasional deep clean-ups. This approach balances performance, storage efficiency, and cost.
2. Understand Delta Lake's transaction log
Familiarize yourself with how the transaction log manages data versions. Knowing this will help you appreciate the importance of regular maintenance.
3. Use cloud inventory services to reduce storage costs
Cloud inventory services, such as Azure Blob or AWS S3 Inventory, play a crucial role in controlling storage costs by providing detailed reports on your stored data. These services help you identify orphaned or outdated files, streamline VACUUM operations, and improve storage efficiency. By leveraging these inventory reports, you can reduce the cost and complexity of live file scans, making it easier to clean up unnecessary data and maintain a lean cloud environment.
4. Adjust retention periods wisely.
Tailor the delta.deletedFileRetentionDuration and delta.logRetentionDuration settings based on your business needs to ensure effective time travel while minimizing unnecessary data retention.
5. Consider using Unity's predictive optimization.
Predictive optimization helps automate table maintenance, reducing manual efforts and preventing performance issues. However, keep in mind that it may not be available in all regions and does not apply to certain table types, such as external tables.
Conclusion
In today's data-driven world, managing costs in cloud environments like Databricks is essential for maximizing your organization's value from data investments.
Delta Lake's VACUUM command is essential for maintaining a lean data environment by cleaning up unnecessary files and reducing storage costs.
Additionally, Unity's predictive optimization offers the benefit of automating this maintenance process for managed tables, freeing you from manual oversight.
We've learned that by regularly applying VACUUM and leveraging metadata from Delta Lake and cloud storage, you can dynamically target high-cost tables based on size discrepancies and the number of files, optimizing storage without unnecessary operations.
On top of that, using VACUUM LITE for frequent, lightweight cleanups and reserving regular VACUUM for deeper clean-ups ensures a cost-effective and efficient storage management strategy.
Stay tuned for our next installment, where we'll dive into compute optimization techniques, further enhancing your ability to manage costs effectively in Databricks.
Written by
Frank Mbonu
Frank is a Data Engineer at Xebia Data. He has a passion for end-to-end data solutions and his experience encompasses the entire data value chain, from the initial stages of raw data ingestion to the productionization of machine learning models.
Our Ideas
Explore More Blogs


From Spec to Code: Building Software with Spec Kit
This article walks through the full workflow, from installation to a working implementation, covering both greenfield projects and extending an...
Hidde de Smet, Emanuele Bartolesi


Contact