Blog
Data pipeline components are just normal applications

A data pipeline component is nothing more than a normal application
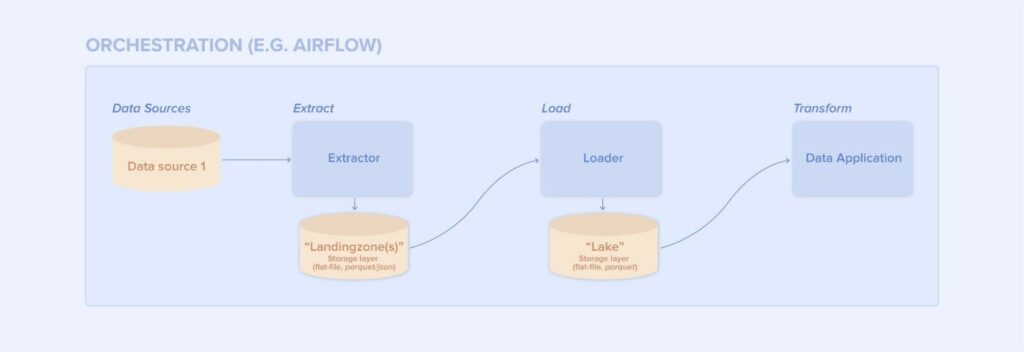
Fig1. Example data pipeline: ELT
It goes through the same lifecycle as any other application: the component is developed and tested, an artifact is built and finally it gets deployed. The artifact is then run as part of your data pipeline. During this the application uses normal application development processes like:
- CI/CD
- All of the steps in the pipeline will run as a normal application, so for each of them an artifact needs to be built and tested. This can be done using the same process as done for any other application, i.e. build a (Docker) image, run tests and deploy any resources that need deploying.
- Monitoring, dashboarding and alerting
- Make use of the existing monitoring and dashboarding infrastructure. Most Kubernetes clusters will have something like Promotheus in place to gather metrics. All of your data pipeline components can integrate with this to make the metrics available the same way as all the other applications running on the cluster. This way you can make use of the same dashboarding and alerting solution as all the other teams in your organization.
The application itself uses and builds on common application building blocks like:
- Compute
- The modus operandi we prefer is running jobs on Kubernetes. This provides a lot of advantages from a platform perspective.
- Storage
- Each of the pipeline steps is responsible for storing its own output. Store this output separately from the compute, generally on blob storage.
- Connectivity to other systems/data sources
- Leverage the existing connectivity of the platform to other on-premise or cloud-based systems, don’t build your own custom connectivity solutions in your applications
- Non-functionals
- Scalability
The resource usage of the data pipelines processes are generally predictable. Because of this it’s most of the time not necessary to invest time in scaling the individual extractors or loaders. It is however beneficial to scale the underlying Kubernetes cluster to reduce cost. This will also allow finishing all data pipeline processes in a shorter amount of time.
- Reliability
Since we’re running pods on a Kubernetes cluster we can make use of regular Kubernetes mechanisms to guarantee reliability. Think about setting resource requests and limits, pod disruption budgets, retries, etc
- Portability
Since our artifact is just a Docker image it can be run anywhere. You can run it locally or on CI/CD for validation purposes or run it on any cluster for validation or production use
- Security
Apply the principle of least-privilege to your data pipeline components. An extractor should be the only component that has access to credentials for and is able to connect to a source system. On the other hand, a loader should be the only component allowed to write data into your data lake. The rest of the components should not have access to the data in your lake.
- Make use of Kubernetes service accounts bound to cloud provider service accounts and manage the permissions on the cloud provider service accounts.
In some cases it is mandatory to scan offloaded data for anomalies.
Use separate namespaces for isolation.
- Maintainability
Use shared code/libraries for code you will reuse.
...with more focus on some areas
Some of the building blocks and processes are the same between a normal application and a data-pipeline component. However, it might be necessary to focus more on specific areas. This is mainly because of the inherent challenges of the data domain like the large volume of data and the fact that data applications are often run in batches and are all about (processing) the data instead of the application itself. Examples of this are:
- Make use of the platform’s scalability for your resource heavy applications. This can bring significant cost benefits to the data platform because of the often large resource requirements of data applications that are run in batches. Do make sure that important tasks are scheduled on nodes that won’t just disappear so they can run safely without getting killed.
- Since the volume of data is quite large, make use of the platform’s blob storage to store the data, this is generally much more cost-efficient than other ways of storing these large volumes of data.
- If you value quality and consistency make sure you validate the incoming data, for example against a schema that’s part of the application’s configuration.
- Write metrics about the data processed by the application to provide insights and allow monitoring of your pipeline. Make sure that if your data pipelines run in batches the information about which batch the pipeline was run for is included in these metrics.
...and some additional functionality
And finally there’s functionality that’s unique to a data-platform, we strive to keep this to a minimum. There are some exceptions though, like making sure to register the data produced by every application in the data catalog.
Final thoughts
Think of your data-pipeline components as nothing more than a normal application with some additional functionality on top to make it specific to the requirements of the data domain. Having knowledge about normal applications and their building blocks helps you when working on your data pipelines. Keep in mind the basic principles and add data specific functionalities where required. This should be your path to your successful data pipeline.
If you want to learn more about using your organization’s data in an optimal way, check out our other resources:
- DevOps for Data Science - Xebia
- A Data Platform is Just a Normal Platform - Xebia Blog
- DevOps in a Data Science World - Xebia Blog
- Webinar: Doing DevOps in a Data Science World - Xebia
Also, keep an eye on our calendar because in 2022 Q1/Q2 we will host another free Data Breakfast Session.
Written by
Marcel Jepma
Our Ideas
Explore More Blogs




Contact