Blog
Chaos Engineering: Why you should break stuff in production on purpose

Have you ever been called out of bed because the application you work on wasn’t working anymore? Or have you spent time on a Saturday doing manual failover tests from one datacenter to another? If you have, you probably are enthusiastic to learn how to avoid this. If you haven’t, you’re either just lucky it hasn’t happened yet, or you made it somebody else’s problem.
Measuring Complex IT landscapes
Application landscapes have evolved over the years and traditional monitoring systems are not capable of checking whether our systems are up or not. How come?
Look at the following architectures from large corporations like Amazon and Netflix. They represent all instances of microservices that run Amazon’s web shop (So no AWS, this is only the online store). Do you think they have a dashboard that shows all servers and instances, showing green or red? I’ll tell you now, they don’t.

Microservice architectures and cloud infrastructure have changed our landscape a lot. We no longer have big servers that we care for as our pets. Instead, we have loads of smaller pieces of infrastructure that are responsible for specific parts of the application workflow. Often these pieces of infrastructure can scale horizontally running multiple instances of the same service.
What we do need to check is whether our application is operating normally? If a microservice is scaled over multiple instances, users might not even notice one of them being down.
Looking at servers being up or not is not the measurement anymore. We need to measure whether users are still able to do what they are supposed to do. Take Netflix for example. They use a great measurement for this, called “The pulse of Netflix”. They use this to measure the amount of play buttons pressed. Netflix has a good understanding of the average streams started. If streams do not start, people will repeatedly press the play button to try again. As a result, the number of clicks increases. If the page with the play button does not even load, the amount of play clicks will decrease. In both cases, Netflix will get alerts of this behavior (or problem).
“In a complex landscape your application is never fully up”
Monitoring user activity and success rate is of key importance when building high-availability applications. Without this you’ll never know whether your application is working or not. Even if you have a small number of servers and all monitoring screens show a green status, this does not guarantee your users have a great experience in your application. A prerequisite for having a distributed, highly available application is having proper logging in place that enables you to query what users are expecting.
How to test for failure?
In the past we’ve tested for infrastructure failure by doing manual failover tests. Enterprises often do full datacenter failovers every 6 months or so. Most of the times these failover tests are executed during the weekend or at other times when it least impacts users.
In the age of cloud computing this feels old fashioned. We no longer have data centers and infrastructure is used as cattle instead of pets. If the infrastructure is broken or is not functioning properly, you just roll out a new one instead of nursing it back to health. We might think we’ve designed our systems to be highly available, self-healing, auto scaling and doing fail overs, but is that working as intended?
What is Chaos Engineering?
A lot of people have heard of the term “Chaos Engineering”. But when you ask them what they think it means, the most frequently heard answer is: “Killing servers randomly in production”. While this certainly causes chaos, this is not what Chaos Engineering is about. This incorrect understanding comes from one of the earliest practices at Netflix. In 2010, before the term Chaos Engineering was coined, Chaos Monkey was born within Netflix. Chaos Monkey did exactly what people nowadays suspect: kill random servers at random intervals. Teams used Chaos Monkey to create applications that needed to be highly available. Surviving Chaos monkey was a great test. Later, Chaos monkey and “Failure Injection Testing” (FIT) turned into the new practice, Chaos Engineering. In 2014 this name was used for the first time for the practice of injecting failure on purpose in order to build better more highly available software. Today there is a website created by the Chaos Community to describe the principles of Chaos Engineering. You can find it at principlesofchaos.org. This website also contains the official description of what we currently mean with Chaos Engineering:
“Chaos Engineering is the discipline of experimenting on a distributed system in order to build confidence in the system’s capability to withstand turbulent conditions in production.”
Chaos engineering is all about doing controlled experiments and NOT about breaking things in production that would cause downtime or failures for your end-users.
Chaos Engineering versus regular testing
Chaos Engineering should be an addition to all the tests you are already doing. You’ll need to have confidence in the quality of your application to use Chaos Engineering as an extra set of experiments to prove the resilience of your application. These kinds of tests can’t be simulated by unit tests or integration tests.
But do we have to do this in production? This is a misconception that people have about Chaos Engineering. Although Chaos Engineering is often executed in production this is probably not the place to start. If you want to do your first experiments it might be possible to do this in an acceptance or test environment, depending on the experiment. As you get more confident over time, or want to test larger parts of your application landscape, production is the only place you can do this because it is often impossible to emulate a fully distributed application landscape in a test or acceptance environment.
This works well in cloud environments where you have control over the infrastructure and it is possible to create an infrastructure on which to execute your experiments while the experiment takes place. If you can redirect a small number of users or specific users (maybe employees or beta testers) to this experiment infrastructure, you can run the experiments there without exposing your entire population to the risk of the experiment.
Is Chaos Engineering for me?
Who wouldn’t want to add “Chaos engineer” as their job title? But is it something you really need? If you are building distributed applications (and who isn’t nowadays) that need to have a high availability or are business-critical, Chaos Engineering is the only way to build this confidence for your application.
How to do your own Chaos Engineering experiments
To know how to do your own experiments, you need to know what to do in these experiments. It all starts with having a system that is in a steady state and that has enough observability to experiment on. No logs or monitors? No go! We can’t do experiments without monitoring what is happening, so having proper logging within the application is a prerequisite.
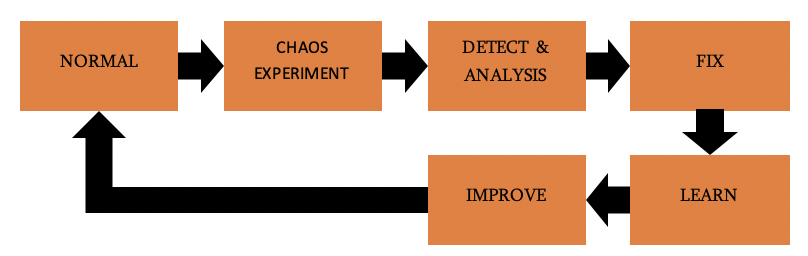
A good way to get started with chaos experiments is to start organizing “Game Days”. It’s a time-boxed event where you get everyone involved in building and running your application to focus on resilience and failure by doing experiments together. The together part here is important. You are responsible together and want to avoid blaming people for things that are going wrong. Organizing a game day will embed the importance of chaos engineering into your culture and you will approve on it over time.
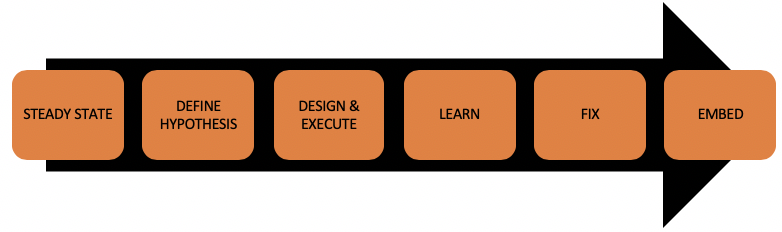
Steady State
The first thing we need to do to run a chaos experiment is to define a steady state. This needs to be an indicator of your application that should work as intended for your end-users. As described earlier, Netflix uses “The pulse of Netflix” for this and you should have something similar for your experiment. This can be a lot simpler than what Netflix is using, depending on the type of experiment and the type of application.
It’s important to measure a business metric instead of a purely technical metric. What we care about is whether our users are affected or not in what way they are affected. There might be a graceful degradation when certain services are down. We always want to design these changes with the end-user in mind, focusing on giving them the best experiences possible.
Hypothesis
The next thing to have is a hypothesis of what failure your application should be able to endure and what the outcome will be. The best way to create a hypothesis is by doing a brainstorm with everyone involved in that part of the application present. This should not only be the engineering team, but anyone who has a part in running your application.
Most of the time, people will have an idea of what “should” happen as part of the design, but having everyone there – from developers, operations, networking, security, architects, and of course the product owner – will allow a good discussion of what the application is really going to do in case of failure. Is there any graceful degradation, will something else take over, or will the application just stop working?
A common way to brainstorm about what failures your application should be able to endure is looking at your steady state and come up with several “What if” questions. What if the database is unavailable? What if the network latency is increased by 100 milliseconds? What if the application node restarts? Everyone can chip in with their own expertise and come up with several scenarios that will affect your steady state.
If you are unsure whether the failure will affect your steady state, if you are unable to come to an agreement of what will happen when failure is injected, or if you are not able to monitor this behavior, stop your experiment here. It’s time to go back to the drawing board and get more information of how your application will respond to failure, or start adding more logging and monitoring.
You might think this is a bad thing but actually it’s a good thing. You’ve learned something about your system and you’re acting before something bad happens, thus making your application more resilient and ready for more experiments in the future.
Design and execute the experiment
Once you’ve created a hypothesis it’s time to create an experiment to test whether your hypothesis is correct. There are several things to keep in mind when designing the experiment. First of all: start as small as possible, thus minimizing the impact when things go wrong. If you are not that confident yet or this is one of your first experiments, acceptance environments might be a good place to start, but most of the times you want to do this in production because that is the only place that really gives confidence after successful experiments.
Start small so that you can minimize the blast radius. Once this is successful, you can increase the blast radiusby adding more users or affecting a larger part of your landscape. Keep monitoring and always have a fail-safe in placeto abort the experiment.
Cloud infrastructure is ideal for these experiments because you can spin up a second environment with ease where you do your experiments without affecting the rest of your application landscape.
Learn
After executing the experiment it’s time to investigate the results and see what you can learn from your observations. It is important here to quantify your results. For example: How soon after injecting the failure were you able to see it on your monitors. How fast were you able to recover?
Fix
After quantifying the results it became easier to compare them with your assumptions or goals. If the results don’t meet your expectations you can start improving your application to become more resilient to these kinds of failure. After you have made your improvements, run the experiment again to see whether the improvements are sufficient.
Embed
If you get more familiar with these chaos experiments you might want to embed them further in your engineering culture. This can be done through continuous chaos like the original chaos monkey that keeps rebooting VM’s at random intervals. If you know that these experiments exist, and you can opt-in to them, it becomes something that is at the top of the minds of development teams right from the start.
Tools to get you started
Chaos Monkey is the original chaos engineering tool created at Netflix. It’s still being maintained and is currently integrated into Spinnaker which is Netflix’s CICD tool. github.com/Netflix/chaosmonkey
Gremlin is a company started by some of Netflix’s and Amazon’s Chaos Engineers who productized Chaos as a Service (CaaS). Gremlin is a paid service that gives you a CLI, agent and website that will help you set up chaos experiments. Gremlin announced a free service a month ago that offers free basic chaos experiments such as turning off machines or simulating high cpu load. gremlin.com
Chaos Toolkit is an open source initiative that tries to make chaos experiments easier by creating an open API and standard JSON format to expose experiments. They have several drivers to execute these experiments on AWS, Azure, Kubernetes, PCF and google cloud. They also offer integrations with monitoring systems and chat such as Prometheus and Slack github.com/chaostoolkit/chaostoolkit
Conclusion
Making applications resilient is no longer something that is relevant only for operations. With cloud infrastructure, developers and engineering teams have become responsible for their complete applications, both at the application level and the infrastructure level. Cloud infrastructure has given us the flexibility and the agility to adapt quickly to new business requirements, but without taking care that you are fully dependent on the resilience of the cloud infrastructure itself. You’ll have to create an architecture that is resilient using these components and the only way to find out whether it is as resilient as you hoped it was is by doing controlled chaos experiments. So start experimenting yourself by organizing a game day in your own company! Are you still a bit scared to take the leap? Let me finish by this great quote from Nora Jones, Senior Chaos Engineer at Slack and co-author of the Chaos Engineering book by O’Reilly
“Chaos Engineering doesn’t cause problems, it just reveals them” – Nora Jones, Chaos Engineering Lead Slack
Written by
Vivian Andringa
Contact