
Background
On my day to day job as a cloud consultant I work a lot with Infrastructure as Code (IaC), and basically everything is IaC nowadays. As my work is focused on AWS, the IaC tools I use are CloudFormation, sometimes Terraform but mostly the AWS Cloud Development Kit (CDK). When writing new infrastructure with CDK pipelines, in the end what comes out after synthesizing your code are CloudFormation templates.
With CloudFormation released since 2011, the vendor AWS and also the community created several tools to check and validate your CloudFormation templates. A couple I personally use in my day to day work are:
-
Cfn-lint is the CloudFormation Linter tool.
-
Cfn-Nag to find security problems inside your templates.
-
pre-commit to check your templates/code before committing on certain hooks.
As there are many blogs around all these cool tools, I will not describe them here. This article is more focussed on how to embed such cool tools inside your CDK pipeline.
Prerequisite
-
Access to an AWS Account with proper rights to deploy resources.
-
CDK knowledge. As I will start with directly talking about CDK and CDK pipelines, knowledge on these topics is a prerequisite. Luckily AWS created workshops on this topics. Please check them out if you want to try out on CDK and CDK pipelines.
Installation
The idea here is to embed tools like cfn-nag and cfn-lint inside your CDK Pipeline to make it more robust and secure. This will make chief information security officers (CISO) happy within an enterprise.
So first let's start with creating a CDK project and work from there.
➜ mkdir cdkpipeline_with_cfn_nag && cd cdkpipeline_with_cfn_nag ➜ cdk init app --language python
This last commando will create a projen project to build our S3 secure bucket construct in.
Real world scenario
In enterprises DevOps teams are often not allowed to deploy resources from their local development machine. The standard is to use CI/CD for that. So code is being pushed to a repository and on pull request a pipeline will run and execute the code to deploy the resources in a Dev, Test, Acceptance and Production environment.
Let's try to mimic the real world scenario in our CDK app. The idea is to create a simple S3 bucket within your AWS account. This bucket will be deployed via CDK pipelines to have the benefits of CI/CD by Infrastructure as Code. Why I've chosen a bucket is because one it is simple, and two there are good cfn-nag findings on a simple bucket. So we can see the outcome of our pipeline.
Go Build
We have our CDK project initialised. Let's first install some dependencies. The project itself is written in python. If you don't want to tag along, you can find a link to the code at the bottom of this blog.
As we are creating a bucket add the cdk aws s3 package:
pip install aws_cdk.aws_s3
Now let's create the bucket within the CDK App. Your CDK project should look like this:
(hashnode) ➜ cdkpipeline_with_cfn_nag git:(main) ls -sla total 56 0 drwxr-xr-x 12 yvthepief staff 384 Aug 25 21:46 . 0 drwxr-xr-x 4 yvthepief staff 128 Aug 25 21:41 .. 0 drwxr-xr-x 12 yvthepief staff 384 Aug 25 21:46 .git 8 -rw-r--r-- 1 yvthepief staff 124 Aug 25 21:46 .gitignore 0 drwxr-xr-x 6 yvthepief staff 192 Aug 25 21:46 .venv 8 -rw-r--r-- 1 yvthepief staff 1658 Aug 25 21:46 README.md 8 -rw-r--r-- 1 yvthepief staff 1357 Aug 25 21:46 app.py 8 -rw-r--r-- 1 yvthepief staff 777 Aug 25 21:46 cdk.json 0 drwxr-xr-x 4 yvthepief staff 128 Aug 25 21:46 cdkpipeline_with_cfn_nag 8 -rw-r--r-- 1 yvthepief staff 5 Aug 25 21:46 requirements.txt 8 -rw-r--r-- 1 yvthepief staff 1017 Aug 25 21:46 setup.py 8 -rw-r--r-- 1 yvthepief staff 437 Aug 25 21:46 source.bat
I will restructure the directories a bit for my own convenience, so start with creating two directories; s3bucket and cdkpipeline.
(hashnode) ➜ cdkpipeline_with_cfn_nag git:(main) mkdir cdkpipeline s3bucket
Create S3 Bucket
Now inside the s3bucket folder create the actual python file which will be used to create the S3 bucket.
(hashnode) ➜ cdkpipeline_with_cfn_nag git:(main) cd s3bucket && touch bucket_stack.py
Open this bucket_stack.py file inside your preferred editor and write some code to actually create a S3 bucket.
from aws_cdk import (
aws_s3 as s3,
core as cdk,
)
class BucketStack(cdk.Stack):
def __init__(self, scope: cdk.Construct, construct_id: str, **kwargs) -> None:
super().__init__(scope, construct_id, **kwargs)
s3.Bucket(self, 'S3Bucket')
What is happening here: first of all we import packages to use CDK and S3 (the aws_s3 package which we installed earlier). Secondly we use the imported package s3 to create the bucket.
We need to update the app.py file inside the root as it is still pointing to the cdk_pipeline_with_cfn_nag folder and stack. So rewrite the app.py file with the following:
#!/usr/bin/env python3 import os from aws_cdk import core as cdk # For consistency with TypeScript code,cdkis the preferred import name for # the CDK's core module. The following line also imports it ascorefor use # with examples from the CDK Developer's Guide, which are in the process of # being updated to usecdk. You may delete this import if you don't need it. from aws_cdk import core from s3bucket.bucket_stack import BucketStack app = core.App() BucketStack(app, "Bucket", # If you don't specify 'env', this stack will be environment-agnostic. # Account/Region-dependent features and context lookups will not work, # but a single synthesized template can be deployed anywhere. # Uncomment the next line to specialize this stack for the AWS Account # and Region that are implied by the current CLI configuration. #env=core.Environment(account=os.getenv('CDK_DEFAULT_ACCOUNT'), region=os.getenv('CDK_DEFAULT_REGION')), # Uncomment the next line if you know exactly what Account and Region you # want to deploy the stack to. */ #env=core.Environment(account='123456789012', region='us-east-1'), # For more information, see https://docs.aws.amazon.com/cdk/latest/guide/environments.html ) app.synth()
Basically we are importing here the created s3bucket folder with the bucket_stack.py file. This will be enough to synthesize the CDK app. If you do that, run cdk synth on the command line, you end up with a nice CloudFormation template with a bucket resource specified.
Resources:
S3Bucket07682993:
Type: AWS::S3::Bucket
UpdateReplacePolicy: Retain
DeletionPolicy: Retain
Metadata:
aws:cdk:path: Bucket/S3Bucket/Resource
The CloudFormation template is also written inside the cdk.out folder. If you would run now locally the cfn-nag command you can see that the cfn-nag tool finds 3 warnings on the template:
(hashnode) ➜ cdkpipeline_with_cfn_nag git:(main) ✗ cfn_nag_scan --input-path cdk.out/Bucket.template.json ------------------------------------------------------------ cdk.out/Bucket.template.json ------------------------------------------------------------------------------------------------------------------------ | WARN W51 | | Resources: ["S3Bucket07682993"] | Line Numbers: [4] | | S3 bucket should likely have a bucket policy ------------------------------------------------------------ | WARN W35 | | Resources: ["S3Bucket07682993"] | Line Numbers: [4] | | S3 Bucket should have access logging configured ------------------------------------------------------------ | WARN W41 | | Resources: ["S3Bucket07682993"] | Line Numbers: [4] | | S3 Bucket should have encryption option set Failures count: 0 Warnings count: 3
Imagine if you have a CDK project with multiple resources working by a complete DevOps team. That list would grow and grow if not handled correctly. So to catch security errors and warnings within the enterprise environment we need to embed cfn-nag inside the CDK pipeline.
CodeCommit Repository
To have the code run automatically when a change has been made, we need to store the code somewhere. I've chosen to use a CodeCommit repository to store the code. Install the package aws_codecommit:
(hashnode) ➜ cdkpipeline_with_cfn_nag git:(main) ✗ pip install aws_cdk.aws_codecommit
Create a python file called repository.py inside the cdkpipeline folder created earlier.
from aws_cdk import (
aws_codecommit as codecommit,
core as cdk
)
class RepositoryStack(cdk.Stack):
def __init__(self, scope: cdk.Construct, construct_id: str, **kwargs) -> None:
super().__init__(scope, construct_id, **kwargs)
# Create codecommit repository to store files
codecommit.Repository(
self, 'Repository',
repository_name='cdkpipeline_with_cfn_nag',
description='Repository for CDK pipeline with CFN Nag'
)
Add this to your app.py file to make it deployable. This is one of the two things which should be deployed from your local machine. The second thing is the creation of the "initial" pipeline. Everything else will be deployed when changes are made to code and pushed to the repository.
< snippit app.py > from cdkpipeline.repository import RepositoryStack < snippit app.py > RepositoryStack(app, 'SourceRepository')
If you run now the command cdk synth inside your terminal you would see a different output. That is because inside the app.py you have defined 2 stacks:
(hashnode) ➜ cdkpipeline_with_cfn_nag git:(main) ✗ cdk synth Successfully synthesized to /Users/yvthepief/Code/Hashnode/cdkpipeline_with_cfn_nag/cdk.out Supply a stack id (Bucket, SourceRepository) to display its template.
Basically you need to add the stack id name with your cdk synth commando to synthesize the template. Deploy the SourceRepository template so that the CodeCommit repository is available.
(hashnode) ➜ cdkpipeline_with_cfn_nag git:(main) ✗ cdk deploy SourceRepository SourceRepository: deploying... SourceRepository: creating CloudFormation changeset... ✅ SourceRepository Stack ARN: arn:aws:cloudformation:eu-west-1:012345678910:stack/SourceRepository/340ef5f0-05e8-11ec-8ea0-02e6d12e35b9
Check in your code inside the newly created repository. I use the python package git-remote-codecommit for that.
(hashnode) ➜ cdkpipeline_with_cfn_nag git:(main) ✗ git remote add origin codecommit::eu-west-1://cdkpipeline_with_cfn_nag (hashnode) ➜ cdkpipeline_with_cfn_nag git:(main) ✗ git commit -a -m "added repository stack and bucket"[main 9051190] added repository stack and bucket 3 files changed, 4 insertions(+), 18 deletions(-) delete mode 100644 cdkpipeline_with_cfn_nag/__init__.py delete mode 100644 cdkpipeline_with_cfn_nag/cdkpipeline_with_cfn_nag_stack.py (hashnode) ➜ cdkpipeline_with_cfn_nag git:(main) ✗ git push origin main Enumerating objects: 15, done. Counting objects: 100% (15/15), done. Delta compression using up to 8 threads Compressing objects: 100% (13/13), done. Writing objects: 100% (15/15), 3.78 KiB | 1.89 MiB/s, done. Total 15 (delta 3), reused 0 (delta 0), pack-reused 0 To codecommit::eu-west-1://cdkpipeline_with_cfn_nag * [new branch] main -> main
So that is that. The repository is created, and the initial code for the CDK S3 bucket stack is pushed. Now add a CDK pipeline.
CDK Pipeline
For the CDK Pipeline we need to create a file cdkpipeline.py in the cdkpipeline folder where also the repository.py file is. The content should be as follows, I've added comments for explanation:
# importing modules
from aws_cdk import (
aws_codecommit as codecommit,
pipelines,
core as cdk
)
# Class for the CDK pipeline stack
class CdkPipelineStack(cdk.Stack):
def __init__(self, scope: cdk.Construct, construct_id: str, **kwargs) -> None:
super().__init__(scope, construct_id, **kwargs)
# Use created repository by name, basically import the repository created via cdk deploy SourceRepository
repository = codecommit.Repository.from_repository_name(self, 'pipeline_repository', 'cdkpipeline_with_cfn_nag')
# Create CDK pipeline
pipeline = pipelines.CodePipeline(
self, "CDKPipeline",
pipeline_name="CDKPipeline",
# Synthezise and check all templates within cdk.out directory with cfn_nag
synth=pipelines.ShellStep("Synth",
# Point source to codecommit repository
input=pipelines.CodePipelineSource.code_commit(repository, "main"),
# Actual commands used in the CodeBuild build.
commands=[
"npm install -g aws-cdk",
"gem install cfn-nag",
"pip install -r requirements.txt",
"cdk synth",
"mkdir ./cfnnag_output",
"for template in $(find ./cdk.out -type f -maxdepth 2 -name '*.template.json'); do cp $template ./cfnnag_output; done",
"cfn_nag_scan --input-path ./cfnnag_output",
]
)
)
Pay attention to the list of commands in the Synth configuration. Within the synth configuration, there are extra commands after the cdk synth.
"mkdir ./cfnnag_output", "for template in $(find ./cdk.out -type f -maxdepth 2 -name '*.template.json'); do cp $template ./cfnnag_output; done", "cfn_nag_scan --input-path $template",
Basically what happens there is that we first make a cfnnag_output directory. And then for every template(file) which can be found in the cdk.out directory, copy the template file to the cfnnag_output directory. After the copy, do a cfn_nag_scan over the output directory. CFN_NAG will scan all the template.json files inside the cfnnag_output directory.
Why we first copy the *.template.json files to a separate directory is because there are more json files in the cdk.out directory created by CDK synth. Secondly if we do the CFN_NAG scan directly in the for loop, CodeBuild will not exit with a failure as it might end up with a correctly template to test as last, and thus the CodePipeline will always succeed. And the whole idea here is to test and let the pipeline run fails on failures output of CFN_NAG
Add the python packages where we are depending on with the import statements:
(hashnode) ➜ cdkpipeline_with_cfn_nag git:(main) ✗ pip install aws_cdk.aws_codecommit aws_cdk.pipelines
Next step is to create a stage, so that the stage which will create the S3 bucket is used by the CDK pipeline. Start with importing the S3 bucket stack created earlier, the bucket_stack.py file, in the cdkpipeline.py file:
from s3bucket.bucket_stack import BucketStack
Also in the cdkpipeline.py add the stage, preferably above the class CdkPipelineStack(cdk.Stack):
# Class for creation of the S3Bucket Stage
class S3BucketStage(cdk.Stage):
def __init__(self, scope: cdk.Construct, construct_id: str, **kwargs) -> None:
super().__init__(scope, construct_id, **kwargs)
# Create the Bucket Stack, which uses the bucket_stack.py to create a S3 bucket
s3_bucket = BucketStack(self, "S3BucketStack")
Now it is time to call the newly created stage inside the CDK pipeline. Add the stage to the pipeline, so below the pipeline definition inside the class CdkPipelineStack:
# Deploy the S3 Bucket Stage
s3Deplpoy = pipeline.add_stage(
S3BucketStage(
self, 'S3BucketStage',
# env=cdk.Environment(
# account="123456789012",
# region="eu-west-1"
)
)
)
If you want to deploy the bucket stack to a different account or region, uncomment the lines to set the env with an account number or region.
CDK Versioning
This CDK Pipelines uses prerelease features of the CDK framework, which can be enabled by adding the following to cdk.json:
{
// ...
"context": {
"@aws-cdk/core:newStyleStackSynthesis": true
}
}
Adjust app.py
The last thing to change is that instead of in the app.py file we now have configured CDK to deploy the SourceRepository and the Bucket, we need to change this to deploy this to the SourceRepository and the CDKPipeline. So start with importing the new created cdkpipeline.py file:
from cdkpipeline.cdkpipeline import CdkPipelineStack
and remove the import of the BucketStack. Now change the BucketStack definition to CdkPipelineStack:
CdkPipelineStack(app, "CdkPipeline")
With the app.py configured to deploy the SourceRepository and the CdkPipeline we finished the CDK configuration.
Commit to CodeCommit
Commit everything to the CodeCommit repository which we already deployed. Because the CDK pipeline is self mutating, after the deployment, it will use this repository as source.
<p>(hashnode) ➜ cdkpipeline_with_cfn_nag git:(main) ✗ git status
On branch main
Untracked files:
(use "git add <file>..." to include in what will be committed)
cdkpipeline/
s3bucket/
nothing added to commit but untracked files present (use "git add" to track)
(hashnode) ➜ cdkpipeline_with_cfn_nag git:(main) ✗ git add -A
(hashnode) ➜ cdkpipeline_with_cfn_nag git:(main) ✗ git commit -a -m "added cdkpipeline to deploy s3bucket"[main e7bac04] added cdkpipeline to deploy s3bucket
4 files changed, 93 insertions(+)
create mode 100644 cdkpipeline/cdkpipeline.py
create mode 100644 cdkpipeline/repository.py
create mode 100644 s3bucket/__init__.py
create mode 100644 s3bucket/bucket_stack.py
(hashnode) ➜ cdkpipeline_with_cfn_nag git:(main) git push origin main
Enumerating objects: 15, done.
Counting objects: 100% (15/15), done.
Delta compression using up to 8 threads
Compressing objects: 100% (12/12), done.
Writing objects: 100% (13/13), 2.36 KiB | 1.18 MiB/s, done.
Total 13 (delta 4), reused 0 (delta 0), pack-reused 0
To codecommit::eu-west-1://cdkpipeline_with_cfn_nag
9051190..b9e5f62 main -> main
Deploy CDK pipeline
With everything in the CodeCommit, we now need to deploy the CdkPipelineStack only one time from the command line. This will setup the CDK pipeline, and because it is self mutating it will update itself when changes to the pipeline are committed to the CodeCommit repository. For example adding extra stages, which could be to other regions or other accounts.
(hashnode) ➜ cdkpipeline_with_cfn_nag git:(main) cdk synth Successfully synthesized to /Users/yvthepief/Code/Hashnode/cdkpipeline_with_cfn_nag/cdk.out Supply a stack id (CdkPipeline, SourceRepository) to display its template. (hashnode) ➜ cdkpipeline_with_cfn_nag git:(main) cdk deploy CdkPipeline This deployment will make potentially sensitive changes according to your current security approval level (--require-approval broadening). Please confirm you intend to make the following modifications: <....SNIPPIT....> (NOTE: There may be security-related changes not in this list. See https://github.com/aws/aws-cdk/issues/1299) Do you wish to deploy these changes (y/n)?
press y and enter to deploy the CDK pipeline.
CdkPipeline: deploying... [0%] start: Publishing f440c606564105ef3cc7d78e8454da66e58d752539fbaa74fc5bc25c379465e2:current_account-current_region [100%] success: Published f440c606564105ef3cc7d78e8454da66e58d752539fbaa74fc5bc25c379465e2:current_account-current_region CdkPipeline: creating CloudFormation changeset... ✅ CdkPipeline Stack ARN: arn:aws:cloudformation:eu-west-1:123456789012:stack/CdkPipeline/28870680-0bd5-11ec-bec5-06eb6afe4d91
Checking CFN_NAG results
So with the CDK pipeline deployed, the first run is automatically initiated. This results in a successful run with as end goal a S3 bucket created. See screenshot below.
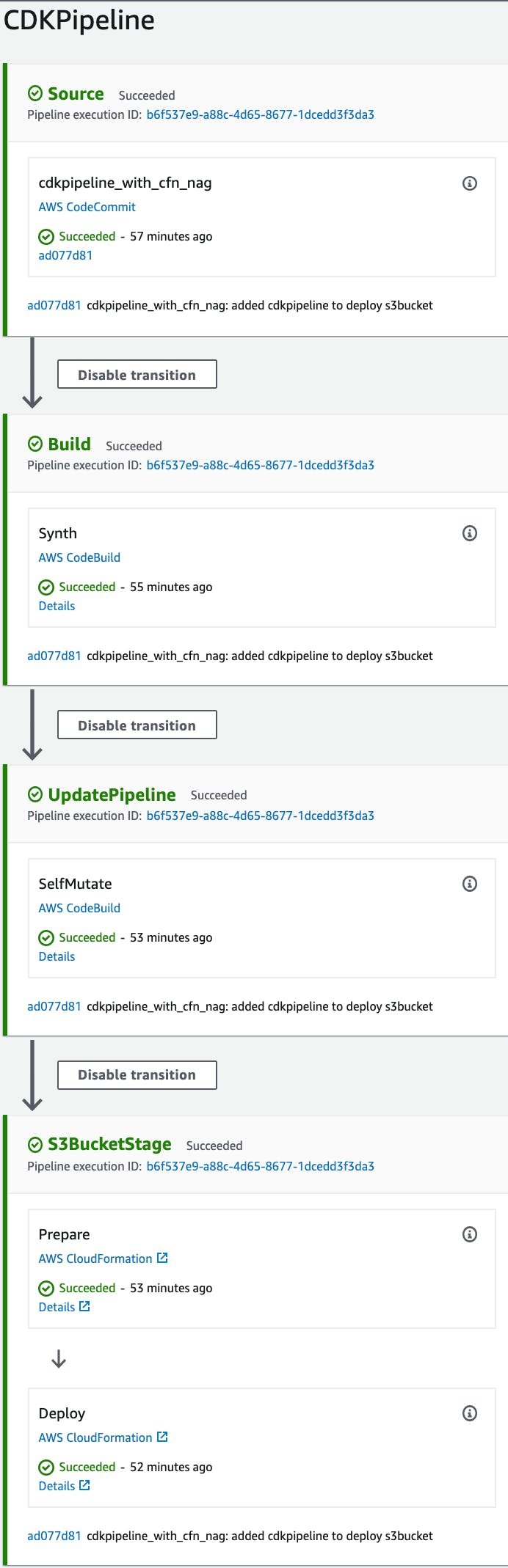
During the run, the CodeBuild phase which is responsible for the generation of the CloudFormation template, our CFN_NAG for loop is executed as well. So all the templates are validated with CFN_NAG. This result can be checked inside the CodeBuild step of the pipeline, just click details in the Synth Stage of the pipeline.
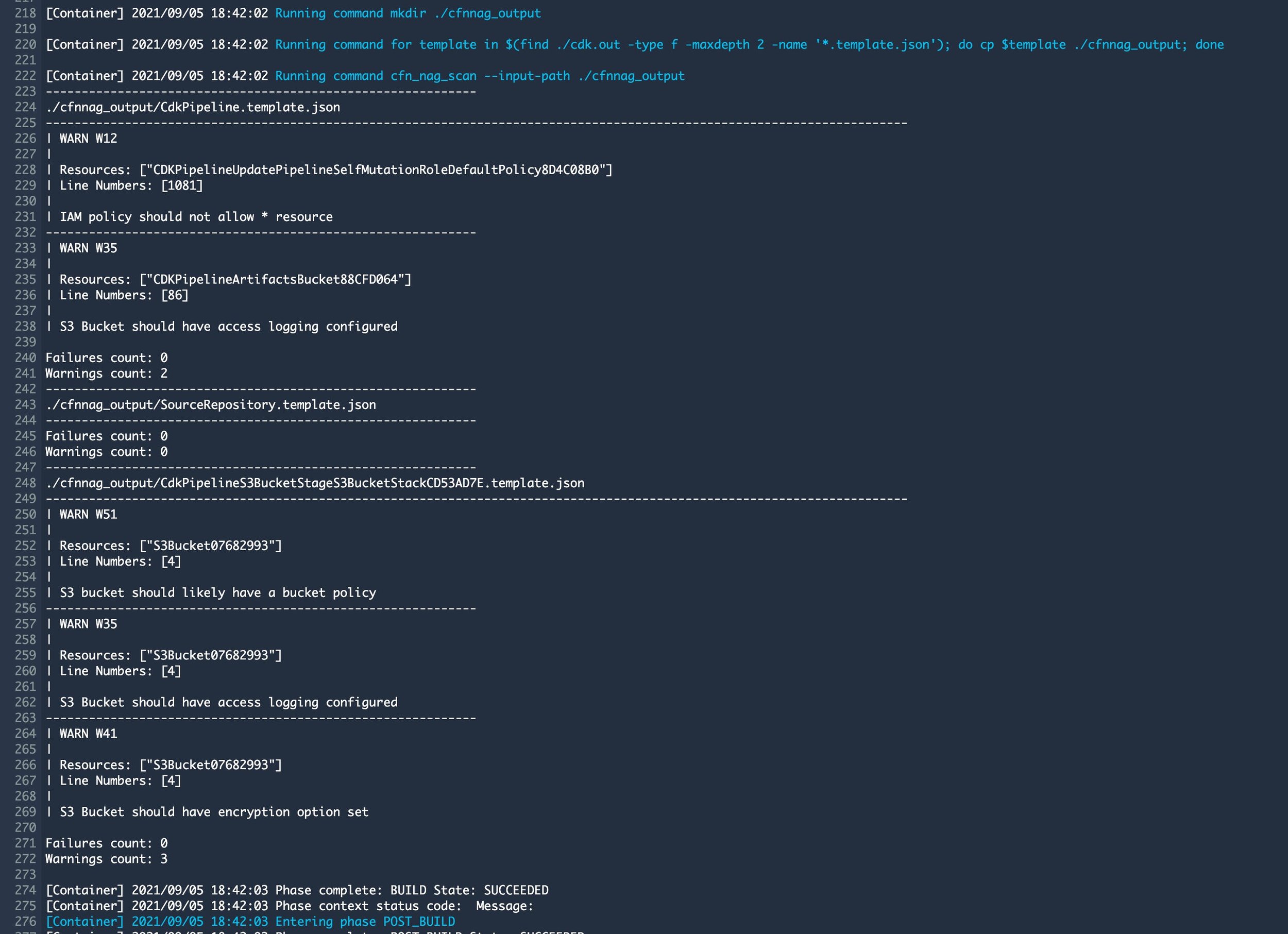
As you can see, two templates are tested and only have warnings. This can be fixed by creating a secure bucket CDK construct which I will describe in a next blog.
Try it yourself
The code can be found in my GitHub. Also make sure to check out his next blog on this topic.
Written by
Yvo van Zee
I'm an AWS Cloud Consultant working at Oblivion. I specialised myself in architecting and building high available environments using automation (Infrastructure as Code combined with Continuous Integration and Continuous Delivery (CI/CD)). Challenging problems and finding solutions which fit are my speciality.




Contact