At GoDataDriven we like to eat burgers. During our GDD Fridays1 we often grab the opportunity to enjoy a nice hamburger for lunch in one of the restaurants nearby our office in Amsterdam. During one of these Fridays we decided that we might as well use our expertise to find the next best restaurant in our never-ending quest for good hamburgers.

The Quest's Landscape
With the goal of making a data-driven choice for our next lunch, we gathered information about restaurants in Amsterdam from an online review website. The data contains ratings, pictures and reviews. All of these are used in this blog to make our decision.
To give you an idea of the data, here is a snapshot of restaurant information:

The reviews for each restaurant are captured in another table:

Equipped with this data we are ready to start our burger quest!
First Stop: Category and Ratings
In our search for a good burger we first turn to the classification tags already present in our data set. There is a total of 161 tags which are used to categorize restaurants, one of which is 'hamburger'. Unfortunately, it turns out only 23 restaurants in Amsterdam have a hamburger tag, making our search very limited. There must be more restaurants that serve a good burger, right?
Second Stop: Elasticsearch
We are pretty sure that there are more than 23 restaurants in Amsterdam where you can eat a nice hamburger. To find these restaurants our plan is to search for burger-related comments. The more people talk about burgers in the comments, the more likely the restaurant has a burger on their menu. We start by installing Elasticsearch and run it as a service:
brew install elasticsearch brew tap homebrew/services brew services start elasticsearch
Now that Elasticsearch is running we can use it as follows in our jupyter notebook:
from elasticsearch import Elasticsearch es = Elasticsearch([{'host': 'localhost', 'port': 9200}])
To do our analysis we first need to think about some pre-processing and the kind of patterns we want to look for. As pre-processing, for example, we strip hyphens and apostrophes and we filter Dutch stop words. Since we are only looking for the 6-letter word 'burger' we tokenize the comments by making 3- and 4-grams of letters for good fuzzy matching. Elasticsearch has a 'fuzziness' feature, but by using 3,4-grams we’ll get an approximation of that which fits our purpose of finding burgers. This means that, next to misspellings, we can also find words that are a variation of the word burger, such as 'lamsburger' or 'kipburger'.
es.indices.put_settings( index='iens_comments', body={ "analysis": { "char_filter": hyphens_and_apostrophes_strip, "tokenizer": ngram_tokenizer, "filter": dutch_stop, "analyzer": analyzer } } )
With our index complete, we can search for the text 'burger' in the reviews as follows:
burger_query = es.search( index='iens_comments', doc_type='iens_review', body={ "query": { "match": { "comment": "burger" } } } )
Instead of Elasticsearch, we could have used some form of regular expressions to look for variations of the word 'burger'. The nice thing about Elasticsearch, besides the fuzzy matching, is that it gives us a score to differentiate between a good and an even better match. To show you an example of Elasticsearch's output, here is the highest scoring match.
Name: Burger Bitch Score: 32.29639 Rating: 2 Comment: "Een burger gedaan samen met mijn 5jarige zoon. Serveerster stelde kinder burger voor. Ik bestelde een gewoon classic/original met als verzoek geen uien en geen augurk. Burgers werden gebracht. En ja hoor vol met uien en augurken zowel als topping als in de saus vies klef broodje erg zoet van smaakt burger uitgedroogd. Me zoon een burger zo klein dat hij zelfs zei papa is dit alles. Friet die er bij zat overladen met zout en eea kruide. Al met bleek einde van de €33 1burger met friet 1 cola 1 miniscule burger met friet en appelsap voor die kwaliteit. Geen burger bitch maar burger bagger."
Although it's not a very positive review, it shows that Elasticsearch serves us well in identifying restaurants that have a hamburger on their menu. We aggregate the review scores per restaurant by taking the maximum score. Below we plotted the distribution of these aggregated scores.

Elasticsearch only returns a maximum of 10,000 best matches, which explains the seemingly arbitrary minimum value around four in our distribution of scores. For our purpose this is no problem since we found that most of these reviews are not burger related. The second hump in the distribution corresponds to a group of restaurants with a significantly higher score. After examining some more reviews manually, we are pretty confident to choose a threshold score of 20 to clasify all higher scoring restaurants as hamburger restaurants. This gives us 335 more candidates in our quest!
As we have seen in the example review above, a high Elasticsearch score does not have to correlate with a high rating. Therefore, it might be nice to also look at the sentiment of the review. This could be done, amongst others, by calling the Google Natural Language API to add sentiment to our search for burgers. For now however, we decide to use the Elasticsearch score only as a tag for a hamburger restaurant, and to use the restaurant's food rating as an indicator of the burger's quality.
Third Stop: Image Recognition
What better way is there to tell if a burger is nice and juicy, than by looking at it? They say a pictures tells more than a thousand words, so let's find all images in our data with a burger on it.
One easy way to do this is by using Google's Vision API. All you need to do is download an API key, create a request, and execute it:
from googleapiclient.discovery import build service = build('vision', 'v1', developerKey=YOUR-API-KEY>) collection = service.images() def make_request(url): return {'image': {'source': {'imageUri': url}}, 'features': [{ 'type': 'LABEL_DETECTION', 'maxResults': 10}]} def execute_request(url): return collection.annotate(body={'requests': make_request(url)}).execute() burger_url = 'https://www.okokorecepten.nl/i/recepten/kookboeken/2014/jamies-comfort-food/jamie-oliver-hamburger-500.jpg' execute_request(burger_url)
What you get back is a list of descriptions, and their likelihood of being on the image:

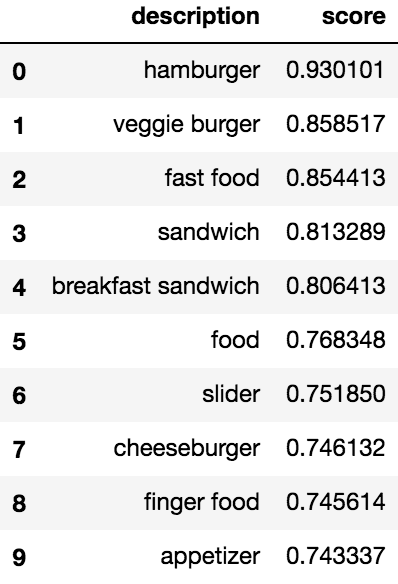
To determine if restaurants advertise their burgers visually, we use the vision API on all images in our restaurant data set, looking for tags of 'hamburger', 'cheeseburger', 'veggie burger', and apparently 'slider' (which can be a sort of mini-burger...). What we found is that veggie burgers are in reality more like salmon-sandwiches in disguise, and that we need a minimal score of around 0.75 to be sure that we are seeing a real hamburger. So let's use this criterion to tag a total of 59 restaurants that have their hamburgers on display. It might sound a bit cheesy, but as we are getting closer to our goal, we are already getting hungry!
On a side note: for the Vision API you get a 1000 calls for free per month. After that it will cost you USD 1.50 per month (see pricing here).
Fourth Stop: Options
Now that we have 3 different ways of determining whether a restaurant sells a hamburger, let's look if there is any overlap. A simple Venn diagram is very instrumental in this:

Indeed we see that there is overlap between the 3 different hamburger tags. For example, there are 27 restaurants with both a hamburger in one of their pictures and with people talking about it in the reviews. There is also one single restaurant that has all 3 possible hamburger tags, which turns out to be Taproom. Looking at all tags together, we see that we have increased the total number of restaurants in our search space from 23 (as provided by the restaurant website) to 333 burger serving restaurants. That sounds a lot more realistic for a city like Amsterdam!
There is one more important dimension in our burger quest that we did not talk about yet: location. We use a nice package called Folium to visualize the candidate restaurants within close range of our office that have a high food rating.
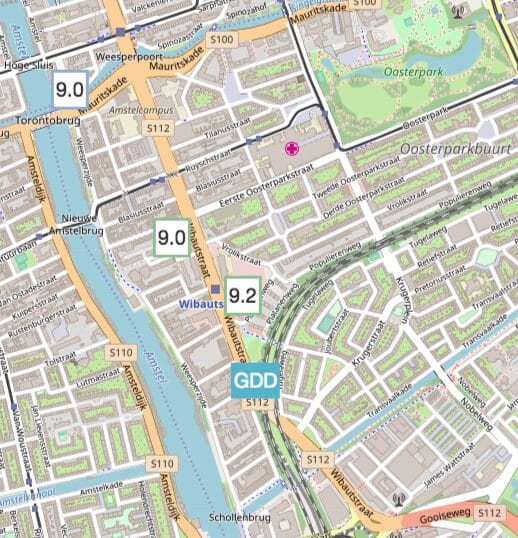
Final Stop: Choice
Now that we have put all ingredients together, the only thing left to do is to choose our next lunch location. Selecting the closest to our office first:
Option: Restaurant C Tag type: Elasticsearch Example review: "Voor lunch geweest. Salade was lekker, visburger van tafelgenoot zag er goed uit. Vriendelijke service, goede prijs kwaliteit."
It turns out that this restaurant, doesn't have burgers on their menu anymore.. bummer! Let's look into the second closest:
Option: India Roti Room Tag type: Elasticsearch Example review: "Een overweldigende gastvrijheid! Een onverwachte en onnederlandse ervaring. Een aanrader voor als je iets zoekt zonder hamburgers, pulled pork, gin-tonic en quinoia!"
Ai! This is a good example of how sentiment analysis could help us narrow down our search even better. This restaurant definitely doesn't have any hamburgers on their menu.. How about the third closest restaurant? This will be the last option at walking distance to our office.
Option: Amstel Brasserie Tag type: Image labelling Example image: Jummie!
The burger looks great, but unfortunately the restaurant is not able to seat us all. It looks like all our work was in vain, but we simply can't accept this as the end of our burger quest. Pragmatic as we are, if we can't get to the best burger we will let it come to us! We used some additional resources2 to find a food truck with the best meat in the country and a mouthwatering selection of burgers on their menu. Below you will find some visual material to determine for yourself how these burgers look.
Was it successful?




Are you interested in Data Science or Data Engineering and do you like burgers as well? Reach out and join us on a GDD Friday, because we are hiring!
For the full code to replicate above analysis, check out our Github3.
Written by

Roel




Contact