Blog
AWS Disaster Recovery Strategies - PoC with Terraform

Intro
A regional failure is an uncommon event in AWS (and other Public Cloud providers), where all Availability Zones (AZs) within a region are affected by any condition that impedes the correct functioning of the provisioned Cloud infrastructure.
Regional failures are different from service disruptions in specific AZs, where a set of data centers physically close between them may suffer unexpected outages due to technical issues, human actions, or natural disasters. In this case, other AZs should still be available, and a workload configured for high availability between AZs should mitigate the events while deploying infrastructure in the original region.
Under the AWS Shared Responsibility model, AWS has clearly defined boundaries between the responsibilities of customers and AWS. While AWS is responsible for the underlying hardware and infrastructure maintenance, it is the customer’s task to ensure that their Cloud configuration provides resilience against a partial or total failure, where performance may be significantly impaired or services are fully unavailable.
This post explores a proof-of-concept (PoC) written in Terraform, where one region is provisioned with a basic auto-scaled and load-balanced HTTP* basic service, and another recovery region is configured to serve as a plan B by using different strategies recommended by AWS.
*For demonstration purposes, we are using HTTP instead of HTTPS. This allows us to simplify our code to focus on the DR topic, avoiding the associated configuration efforts for HTTPS. You should avoid using HTTP for real production scenarios, especially when sensitive data or credentials are transferred through it. You can start using HTTPS on your Application Load Balancer (ALB) by following the official documentation.
Diagram
The project will generate a subset of the following diagram (source: AWS Disaster Recovery Workloads).
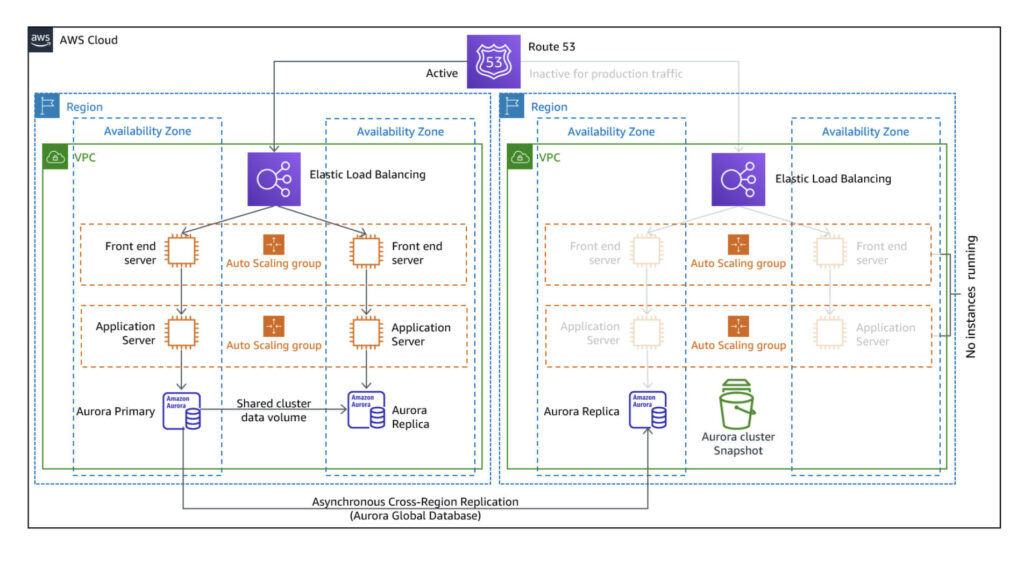
In this PoC, we will create the front-end layer of a three-tier architecture. For simplicity and cost-efficiency on a PoC, backend instances and the storage layer have been omitted. Furthermore, the Route 53 DNS association has not been included for convenience, avoiding the reservation of a domain only for demonstration purposes. In a real scenario, Route 53 should be configured so the primary service is set as the default routing, and the DR Region endpoint is configured as the secondary path when the main one is not in a healthy state.
This diagram is specific to the DR strategy Pilot Light, which will be explained in the next sections. The strategy Warm-standby generates one instance of the front-end layer and one of the application layer. The strategy Multi-site active/activeshows both regions as equal in available resources at any given time. This exercise consists of iterations through each one of them while understanding its differences.
The code
The Terraform code has been divided into two repositories: one to provide the main service infrastructure on a specified region (by default, eu-central-1), and a second repository to provision the backup service on another specified region (by default, eu-west-1). This way, you always have a repository used as the main service and another one to experiment with different types of DR configurations without altering the first one.
The code is publicly available on the links below, with how-to-use documentation.
The idea behind these repositories is to serve as a baseline for different use cases. It can be expanded into a production solution by customizing the code base to your requirements or be used as a live, simplified example to introduce the different DR options to AWS users.
Strategies
Before defining a strategy, we must clarify what is our Recovery Time Objective (RTO) and our Recovery Point Objective (RPO).
RTO is the amount of time your service can be unavailable or in a non-optimal state, based on different factors such as the economic impact, SLA requirements, or its criticality. A service that processes thousands of commercial transactions every hour will have a shorter RTO than a service that performs operations that can be interrupted and resumed at a later stage.
RPO is the acceptable time frame from the last data recovery point. It defines the age limit for the last data backup before the downtime event. A service that relies on data integrity should have a shorter RPO than a service where data can be easily recalculated.
Knowing the desired values for these two concepts will determine the strategy that suits better for your requirements. Using a more complete, expensive solution may not be feasible due to its maintenance effort and budget efficiency. On the other hand, saving too many costs on your recovery solution may result in a critical, perhaps unaffordable impact in the case of a regional event.
AWS suggests four strategies for Disaster Recovery: Backup and Restore, Pilot Light, Warm Stand-by, and Multi-site active/active.
Backup and Restore
As the name implies, Backup and Restore consists of implementing replicas for our storage layer (DBs, EBS...) in an alternate region and restoring it to the latest point of backup after a disaster event occurs.
This strategy is the simplest to implement (especially when using AWS-managed solutions), and it minimizes costs. Nonetheless, it results in the highest RTO as it will depend on the event to be fixed to restore the service. This may result in several hours of downtime, which will only be acceptable in certain use cases, such as non-critical workloads like batch computing activities where availability is not crucial.
Our Terraform PoC does not include a use case for Backup and Restore since it is equivalent to configuring a cross-region replication for each specific service, and therefore belongs to the how-to-use domain of your chosen solution.
Pilot Light
This strategy extends Backup and Restore, and while the storage layer is also replicated in a different region, the backbone of your workload infrastructure is also provisioned. Examples are VPCs, subnets, gateways, load balancers, auto-scaling groups, and EC2 templates.
But while all the previous is available, in Pilot Light computing elements such as EC2 application instances are switched off and only available during a failover or testing.
This strategy improves significantly the RTO and RPO when comparing it to a simple Backup and Restore, decreasing the time to have an active service from hours to minutes (the time it takes to enter failover mode and provision computing layers). As no computing elements are active, this strategy is extremely cost-efficient, having minimal or, in some cases, no cost for networking and infrastructure configuration.
Pilot Light is deployed in our Terraform code by configuring the desired_capacity variable of the auto-scaling group to 0 and applying changes. During failover mode, our service routing should point to the failover region and scale its capacity up to mirror the original configuration (desired_capacity should be changed to 2 in that case).
Warm Stand-by
Warm Stand-by extends Pilot Light, using the same workload infrastructure but including a reduced-capacity version of the computing layer. This ensures that, in the event of a disaster recovery effort, the service is immediately available to customers, although performance will be reduced while the service scales horizontally.
RPO and RTO values will improve when compared to Pilot Light, but there are fixed costs associated with this strategy as it requires having a fully functional, scaled-down version of every layer (including EC2, Lambda functions, and other computing services).
Warm Stand-by is deployed in our Terraform code by configuring the desired_capacity variable to 1 and applying changes. Like in Pilot Light, on failover mode our service routing should point to the failover region and scale its capacity up to mirror the original configuration (desired_capacity should be changed to 2 in that case).
Multi-site active/active
Multi-site active/active is the most complete strategy for disaster recovery. It replicates the original environment at full capacity in another region, acting as a mirrored version that is immediately available at any time.
Therefore, RPO and RTO values will go down to seconds, as only re-routing is required to continue operations as usual. It is also the most expensive option, as it duplicates your resources at a 1:1 ratio at any given time. For this reason, this strategy brings more value to use cases where minutes of downtime result in compliance violations or large economic impacts. As an example, an e-commerce provider that handles thousands of transactions per minute would prefer to implement this strategy, as every moment of downtime translates into a loss of profit.
Multi-site active/active is deployed in our Terraform code by configuring the desired_capacity variable to 2 and applying changes. During failover mode, you only need to change the routing of the service, with no scaling effort associated.
Conclusions
You have now explored how Disaster Recovery strategies work in essence, and what are the criteria to choose one over the others. Please note that, while this PoC has gone over a simplified service, real-world scenarios require an additional effort to enumerate and identify what elements need to be transferred into a failover region and be clear about when and how to do it.
Infrastructure as Code (IaC) is a must if we want to ensure our provisioning is done automatically, fast, and in a reliable way. This way, manual inputs regarding configuration are minimized or, at best, they are not required at all. While in this example we have used Hashicorp’s Terraform, AWS offers CloudFormation as its native IaC solution.
Further reading and additional info:
- AWS offers a DR service called AWS Elastic Disaster Recovery, which helps implement different strategies and cross-region replication.
- AWS maintains a list of documented regional events over the last years as part of their Post-Event Summaries. It helps in understanding which factors can cause a regional failure and how they operate to solve them.
- Disaster Recovery is not High Availability. A service deployed in a single AZ over a single EC2 instance is not highly available, even if it has a DR counterpart in a different region. While this service would be able to survive a regional failure, it will struggle to provide a service in case of a high number of requests or unhealthy instance statuses. Robust architectures prepare for both DR and High Availability, and they complement each other in preparing for the unexpected.
- If you are not sure how to establish your RTO and RPO values, you can start with some questions from this guide.
Written by
Martin Perez Rodriguez
DevSecOps and Cloud specialist at Xebia Security




Contact