
On the 5th of January AWS announced a new CloudTrail component, AWS CloudTrail Lake. It’s a managed feature composed of different AWS services that allows for a more user friendly experience of CloudTrail. Prior to CloudTrail Lake, the process of setting up queryable CloudTrail logs across organizational accounts wasn’t painful but it was a bit tiring and didn’t make much sense to me.
What is AWS CloudTrail Lake?
By now I suppose you can already guess what CloudTrail Lake is, it’s abstracting away CloudTrail trails, S3 and Athena by providing you with a platform that allows for storing, querying and managing your CloudTrail data. What I really like about CloudTrail Lake is that AWS has implemented the ability for organizations to aggregate logs in a single place across their AWS accounts and multiple regions. This makes CloudTrail Lake a must-have in companies that utilize centralized logging accounts. We can already conclude that this simplifies the CloudTrail implementation as it’s integrating collection, storage, preparation, and optimization for analysis and query in the same product. Next to that, it also removes the need of implementing your own data pipelines in order to query and analyze CloudTrail data.
Setting up the lake
It’s fairly easy to create a CloudTrail Lake, everything is abstracted behind a so called event data store. You can think of this event data store as a immutable storage container wrapped around a CloudTrail trail. At the very moment I’m writing this, creation of the event data store is only available through the console, SDK or CLI, so lets utilize the CLI throughout this article. Time to create the event data store.
aws create-event-data-store
--name my-cloudtrail-lake-data-store
--multi-region-enabled
--retention-period 365
--termination-protection-enabled
You could optionally pass in the
--organization-enabledflag if you want the event data store to collect events logged for an organization in Organizations.The CLI should return you something as following:
{
"EventDataStoreArn": "arn:aws:cloudtrail:us-east-1:123456789012:eventdatastore/EXAMPLE-ee54-4813-92d5-999aeEXAMPLE",
"Name": "my-cloudtrail-lake-data-store",
"Status": "CREATED",
"AdvancedEventSelectors": []
"MultiRegionEnabled": true,
"OrganizationEnabled": false,
"RetentionPeriod": 365,
"TerminationProtectionEnabled": true,
"CreatedTimestamp": "2022-01-09T14:19:39.417000-05:00",
"UpdatedTimestamp": "2022-01-09T14:19:39.603000-05:00"
}
The --retention-period flag represents the retention of the events in the event data store in days, coupled with a default retention window of seven years this helps customers meet their compliance requirements.
Also note how the response contains a AdvancedEventSelectors array in the response. You can optionally configure the support of data events in the event data store. Data events provide visibility into the resource operations performed on or within a resource, these are also known as data plane operations. Think of tracking data events in DynamoDB as for example, PutItem, DeleteItem, and UpdateItem API operations. I’m not including any in my event data store as data events are often high-volume activities.
Great, now that the event data store is created we’re ready to take a dive in the lake .
Time to put your swimming trunks on
That was just a corny wordplay joke, you should’ve put on your SQL trunks. Similar to how you would query CloudTrail logs through Athena, you’ll now use the CloudTrail Lake UI. Every event data store is associated with a ID that’s required when querying it. Now if you’re not a SQL guru like myself you can make use of the sample queries that are designed to help users get started with writing queries for common scenarios. (I just dislike SQL in many ways as per the orthogonality, but that’s heat for another article).
- Head over to your event data store (which can be found under CloudTrail -> Lake in the AWS console).
- Go to Editor.
- Copy the below SQL query, change the
FROM, replace the time range and run it.
SELECT userIdentity, eventTime, eventName, awsRegion, sourceIPAddress FROM fc19d5bd-9dd5-4cbf-9071-4a7546954a7a
where eventTime > '2022-01-09 00:00:00.000' and eventTime < '2022-01-09 23:59:59.999'
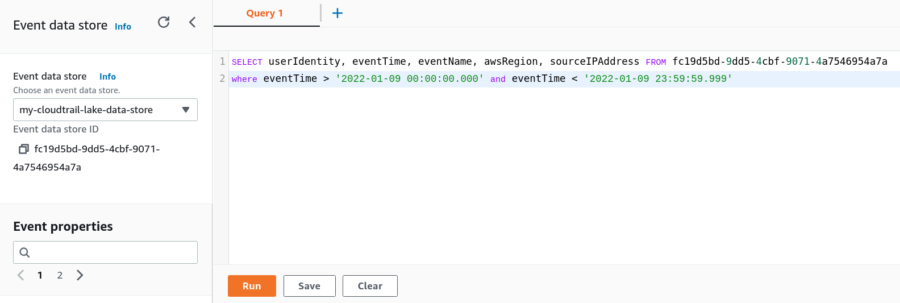
In the top left under ‘Event data store’ you can find event data store ID.
After running the query the results are output at the bottom of the editor. Optionally you can click on
Preferences(cogwheel) to remove columns from the result. All queries that you run are kept a history of (from the last seven days). It’s also good to note that you can save common used queries to save yourself some time.
Benefits over ‘Event History’
CloudTrail Lake queries offer a deeper and more customizable view of events than Event history, or running LookupEvents. An Event history search is limited to a single AWS account, only returns events from a single region, and cannot query multiple attributes. CloudTrail Lake users can run queries across multiple fields and CloudTrail Lake can aggregate events from your organization into a single event data store, and search across all regions at once.
Pricing
With CloudTrail Lake, you are charged for the volume of data that you ingest, the volume of data you scan for analysis, and data storage, if you choose to store it for longer than 7 years. New customers can try CloudTrail Lake for 30 days at no additional cost*. You will have access to the full feature set during this time.
-
Limited to 5GB of ingestion and 5GB data scanned. Data storage included at no charge. Ingesting and storing pricing depends on the volume:
-
First 5TB: $2.5 per GB
- Next 20TB: $1 per GB
- Over 25TB: $0.5 per GB Please bear in mind that running CloudTrail Lake queries are per GB of data scanned.
Written by

Bruno Schaatsbergen
Bruno is an open-source and serverless enthusiast. He tends to enjoy looking for new challenges and building large scale solutions in the cloud. If he's not busy with cloud-native architecture/development, he's high-likely working on a new article or podcast covering similar topics. In his spare time he fusses around on Github or is busy drinking coffee and exploring the field of cosmology.




Contact