Spark is the new kid on the block when it comes to big data processing. Hadoop is also an open-source cluster computing framework, but when compared to the community contribution, Spark is much more popular. How come? What is so special and innovative about Spark? Is it that Spark makes big data processing easy and much more accessible to the developer? Or is it because the performance is outstanding, especially compared to Hadoop?
This article gives an introduction to the advantages of current systems and compares these two big data systems in depth in order to explain the power of Spark.
 Distributed computing[/caption]
In the case of parallel computing, all tasks have access to shared data to exchange information and perform their calculations. With distributed computing, each task has its own data. Information is exchanged by passing data between the tasks.
One of the main concepts of distributed computing is data locality, which reduces network traffic. Because of data locality, data is processed faster and more efficiently. There is no separate storage network or processing network.
Apache Hadoop delivers an ecosystem for distributed computing. One of the biggest advantages of this approach is that it is easily scalable, and one can build a cluster with commodity hardware. Hadoop is designed in the way that it can handle server hardware failures.
Distributed computing[/caption]
In the case of parallel computing, all tasks have access to shared data to exchange information and perform their calculations. With distributed computing, each task has its own data. Information is exchanged by passing data between the tasks.
One of the main concepts of distributed computing is data locality, which reduces network traffic. Because of data locality, data is processed faster and more efficiently. There is no separate storage network or processing network.
Apache Hadoop delivers an ecosystem for distributed computing. One of the biggest advantages of this approach is that it is easily scalable, and one can build a cluster with commodity hardware. Hadoop is designed in the way that it can handle server hardware failures.
 Stacks of Spark and Hadoop[/caption]
The storage layer is responsible for a distributed file system that stores data on commodity machines, providing very high aggregate bandwidth across the cluster. Spark uses the Hadoop layer. That means one can use HDFS (the file system of Hadoop) or other storage systems supported by the Hadoop API. The following storage systems are supported by Hadoop: your local file system, Amazon S3, Cassandra, Hive, and HBase.
The computing layer is the programming model for large scale data processing. Hadoop and Spark differ significantly in this area. Hadoop uses a disk-based solution provided by a map/reduce model. A disk-based solution persists its temporary data on disk. Spark uses a memory-based solution with its Spark Core. Therefore, Spark is much faster. The differences in their computing models will be discussed in the next chapter.
Cluster managers are a bit different from the other components. They are responsible for managing computing resources and using them for the scheduling of users' applications. Hadoop uses its own cluster manager (YARN). Spark can run over a variety of cluster managers, including YARN, Apache Mesos, and a simple cluster manager called the Standalone Scheduler.
A concept unique to Spark is its high-level packages. They provide lots of functionalities that aren't available in Hadoop. One can see this layer also as a sort of abstraction layer, whereby code becomes much easier to understand and produce. These packages are
Stacks of Spark and Hadoop[/caption]
The storage layer is responsible for a distributed file system that stores data on commodity machines, providing very high aggregate bandwidth across the cluster. Spark uses the Hadoop layer. That means one can use HDFS (the file system of Hadoop) or other storage systems supported by the Hadoop API. The following storage systems are supported by Hadoop: your local file system, Amazon S3, Cassandra, Hive, and HBase.
The computing layer is the programming model for large scale data processing. Hadoop and Spark differ significantly in this area. Hadoop uses a disk-based solution provided by a map/reduce model. A disk-based solution persists its temporary data on disk. Spark uses a memory-based solution with its Spark Core. Therefore, Spark is much faster. The differences in their computing models will be discussed in the next chapter.
Cluster managers are a bit different from the other components. They are responsible for managing computing resources and using them for the scheduling of users' applications. Hadoop uses its own cluster manager (YARN). Spark can run over a variety of cluster managers, including YARN, Apache Mesos, and a simple cluster manager called the Standalone Scheduler.
A concept unique to Spark is its high-level packages. They provide lots of functionalities that aren't available in Hadoop. One can see this layer also as a sort of abstraction layer, whereby code becomes much easier to understand and produce. These packages are
 Hadoop computational model: Map/Reduce[/caption]
Hadoop computational model: Map/Reduce[/caption]
 Spark computational model: RDD[/caption]
Spark computational model: RDD[/caption]
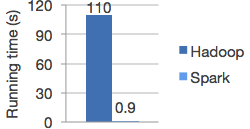 Performance Hadoop vs Spark[/caption]
Behind the scenes, Spark does a lot, like distribute the data across your cluster and parallelizing the operations. Note that doing distributed computing is memory-based computing. Data between transformations are not saved to disk. That's why Spark is so much faster.
Performance Hadoop vs Spark[/caption]
Behind the scenes, Spark does a lot, like distribute the data across your cluster and parallelizing the operations. Note that doing distributed computing is memory-based computing. Data between transformations are not saved to disk. That's why Spark is so much faster.
Parallel computing
First we have to understand the differences between Hadoop and the conventional approach of parallel computing before we can compare the differences between Hadoop and Spark. [caption id="" align="aligncenter" width="638"]Distributed computing[/caption]
In the case of parallel computing, all tasks have access to shared data to exchange information and perform their calculations. With distributed computing, each task has its own data. Information is exchanged by passing data between the tasks.
One of the main concepts of distributed computing is data locality, which reduces network traffic. Because of data locality, data is processed faster and more efficiently. There is no separate storage network or processing network.
Apache Hadoop delivers an ecosystem for distributed computing. One of the biggest advantages of this approach is that it is easily scalable, and one can build a cluster with commodity hardware. Hadoop is designed in the way that it can handle server hardware failures.
Stack
To understand the main differences between Spark and Hadoop we have to look at their stacks. Both stacks consist of several layers. [caption id="" align="aligncenter" width="522"]Stacks of Spark and Hadoop[/caption]
The storage layer is responsible for a distributed file system that stores data on commodity machines, providing very high aggregate bandwidth across the cluster. Spark uses the Hadoop layer. That means one can use HDFS (the file system of Hadoop) or other storage systems supported by the Hadoop API. The following storage systems are supported by Hadoop: your local file system, Amazon S3, Cassandra, Hive, and HBase.
The computing layer is the programming model for large scale data processing. Hadoop and Spark differ significantly in this area. Hadoop uses a disk-based solution provided by a map/reduce model. A disk-based solution persists its temporary data on disk. Spark uses a memory-based solution with its Spark Core. Therefore, Spark is much faster. The differences in their computing models will be discussed in the next chapter.
Cluster managers are a bit different from the other components. They are responsible for managing computing resources and using them for the scheduling of users' applications. Hadoop uses its own cluster manager (YARN). Spark can run over a variety of cluster managers, including YARN, Apache Mesos, and a simple cluster manager called the Standalone Scheduler.
A concept unique to Spark is its high-level packages. They provide lots of functionalities that aren't available in Hadoop. One can see this layer also as a sort of abstraction layer, whereby code becomes much easier to understand and produce. These packages are
- Spark SQL is Spark’s package for working with structured data. It allows querying data via SQL.
- Spark Streaming enables processing live streams of data, for example, log files or a twitter feed.
- MLlib is a package for machine learning functionality. A practical example of machine learning is spam filtering.
- GraphX is a library that provides an API for manipulating graphs (like social networks) and performing graph-parallel computations.
Computational model
The main difference between Hadoop and Spark is the computational model. A computational model is the algorithm and the set of allowable operations to process the data. Hadoop uses the map/reduce. A map/reduce involves several steps. [caption id="" align="aligncenter" width="596"]Hadoop computational model: Map/Reduce[/caption]
- This data will be processed and indexed on a key/value base. This processing is done by the map task.
- Then the data will be shuffled and sorted among the nodes, based on the keys. So that each node contains all values for a particular key.
- The reduce task will do computations for all the values of the keys (for instance count the total values of a key) and write these to disk.
Spark computational model: RDD[/caption]
- Reading input data and thereby creating an RDD.
- Transforming data to new RDDs (by each iteration and in memory). Each transformation of data results in a new RDD. For transforming RDD's there are lots of functions one can use, like map, flatMap, filter, distinct, sample, union, intersection, subtract, etc. With map/reduce you only have the map-function. (..)
- Calling operations to compute a result (output data). Again there are lots of actions available, like collect, count, take, top, reduce, fold, etc instead of only reduce with the map/reduce.
Performance Hadoop vs Spark[/caption]
Behind the scenes, Spark does a lot, like distribute the data across your cluster and parallelizing the operations. Note that doing distributed computing is memory-based computing. Data between transformations are not saved to disk. That's why Spark is so much faster.
Conclusion
All in all Spark is the next step in the area of big data processing, and has several advantages compared to Hadoop. The innovation of Spark lies in its computational model. The biggest advantages of Spark against Hadoop are- Its in-memory computing capabilities that deliver speed
- Packages like streaming and machine-learning
- Ease of development - one can program natively in Scala
Written by
Jan Toebes
Our Ideas
Explore More Blogs




Contact
Let’s discuss how we can support your journey.