
TLDR; Airbyte is a data-ingestion ELT tool that is attractive due to its open-source, no/low-code and community-driven nature. It decreases the amount of custom engineering required to load and store data. This guide explores its features.
This blog is part of a multi-part series on Airbyte. The first part will introduce the product and follow the local development guide. The following parts will dive into setting up a connection between a source system and destination, and finally deploying Airbyte in the Cloud.
Airbyte
There's a new kid on the block in the ELT space: Airbyte. Founded in 2020 by two French entrepreneurs, Airbyte's vision is to "make data integration pipelines a commodity." It received more than 180 million dollars in funding and the coveted "unicorn status" (startups with an evaluation above 1 billion dollars) in late 2021. The focus is to "unburden the data team from maintaining code for ingestion by providing a 'no-code' tool to connect your source systems to your data warehouse." Airbyte leverages the open-source community to build custom connectors to popular source and destination systems. Currently, they support over 100 connectors and the amount is growing due to the contributions of the community.
The focus is to "unburden the data team from maintaining code for ingestion by providing a 'no-code' tool to connect your source systems to your data warehouse."
Airbyte and the ELT shift
Lately, a growing number of companies are switching from ETL to ELT.
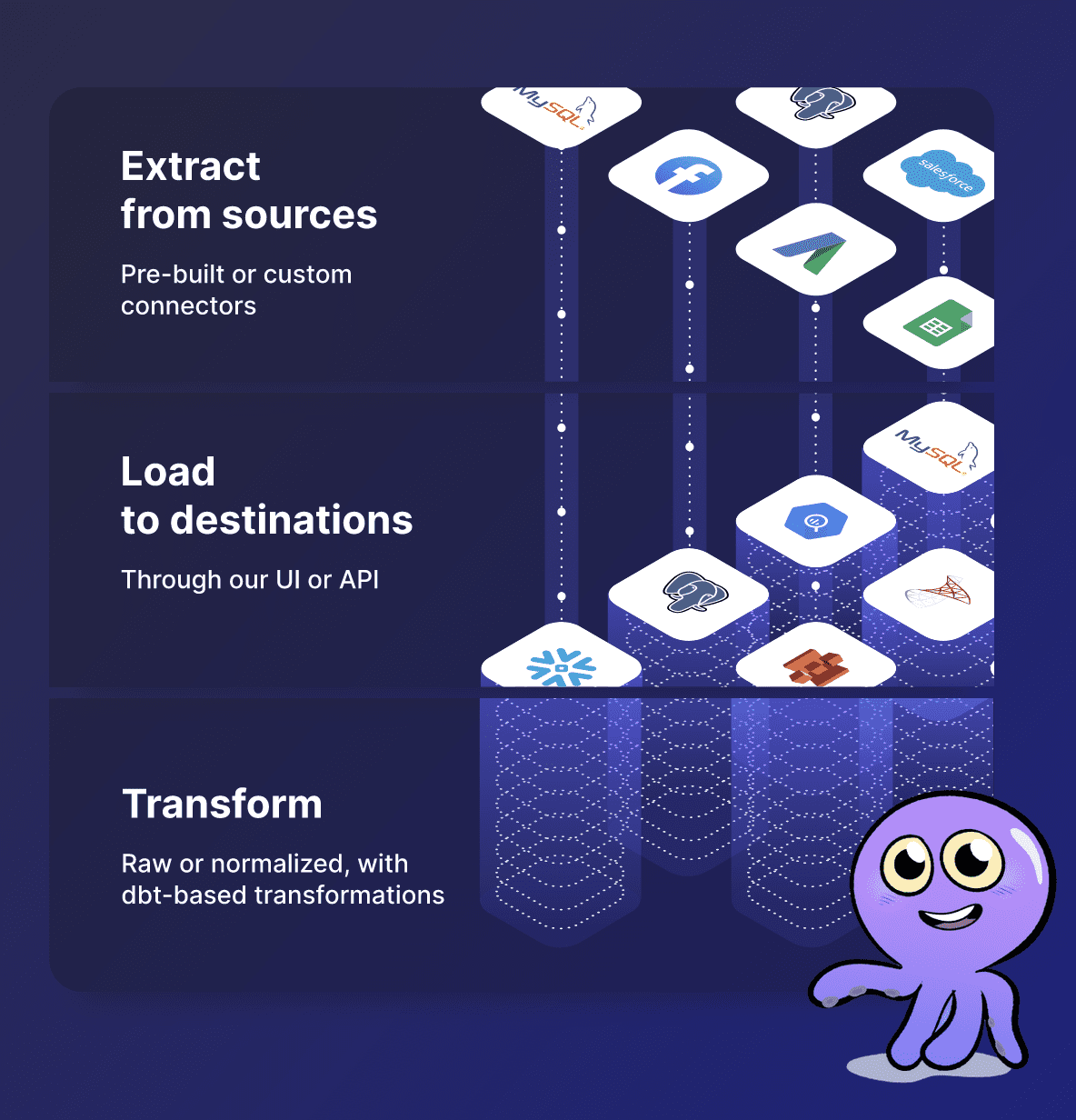
To exactly understand what triggered this shift, we need to look at the history of data ingestion and transformation, but that is something for a future post. The gist of it is: we are starting to move the data from source systems directly into the data warehouse (again) and keeping it there for all transformations. This is called "ELT", short for Extract Load Transform. It's the counter equivalent to "ETL": (Extract, Transform, Load). Airbyte is part of this ELT paradigm. It's designed to seamlessly extract data from a source and load into a data warehouse (although there are more options). Why would you use Airbyte for that, you ask? Because developing and managing bespoke data pipelines rely on costly engineering knowledge. A often used tool like Airflow requires writing custom python code to load and store data. This gives a higher amount of customizability, but can get complex quickly. Airbyte's no-code approach tries to decrease the amount of custom code required. The more you can avoid building and maintaining custom systems for data ingestion and transformation, the greater the amount of time you can spend on creating insights for your actual business. After all, managing data pipelines are only a means to an end. The real value comes from the insights derived from the data.
The more you can avoid building and maintaining custom systems for data ingestion and transformation, the greater the amount of time you can spend on creating insights for your actual business.
Airbyte pitches a no-code/low-code solution to decrease the amount of development required. The target audience seems to be a startup with a small team, lacking the time and money for skilled engineers and complicated bespoke pipelines.
Setting up Airbyte locally
Enough talk. Let's set this thing up. In order to deploy it locally we can follow the Airbyte Local Deployment guide. It requires installation of Git, Docker and Docker-Compose.
Then run these commands:
git clone https://github.com/airbytehq/airbyte.git
cd airbyte
docker-compose upLooking at the contents of the docker-compose file we can see that Airbyte consists out of multiple components: the database, scheduler, worker, server, and orchestrator. We will go more in-depth on these parts later in the series.
For now, we just care about the web interface working. If running docker-compose up worked, the web interface should be available at http://localhost:8000.

Good to go!
Sources and Destinations
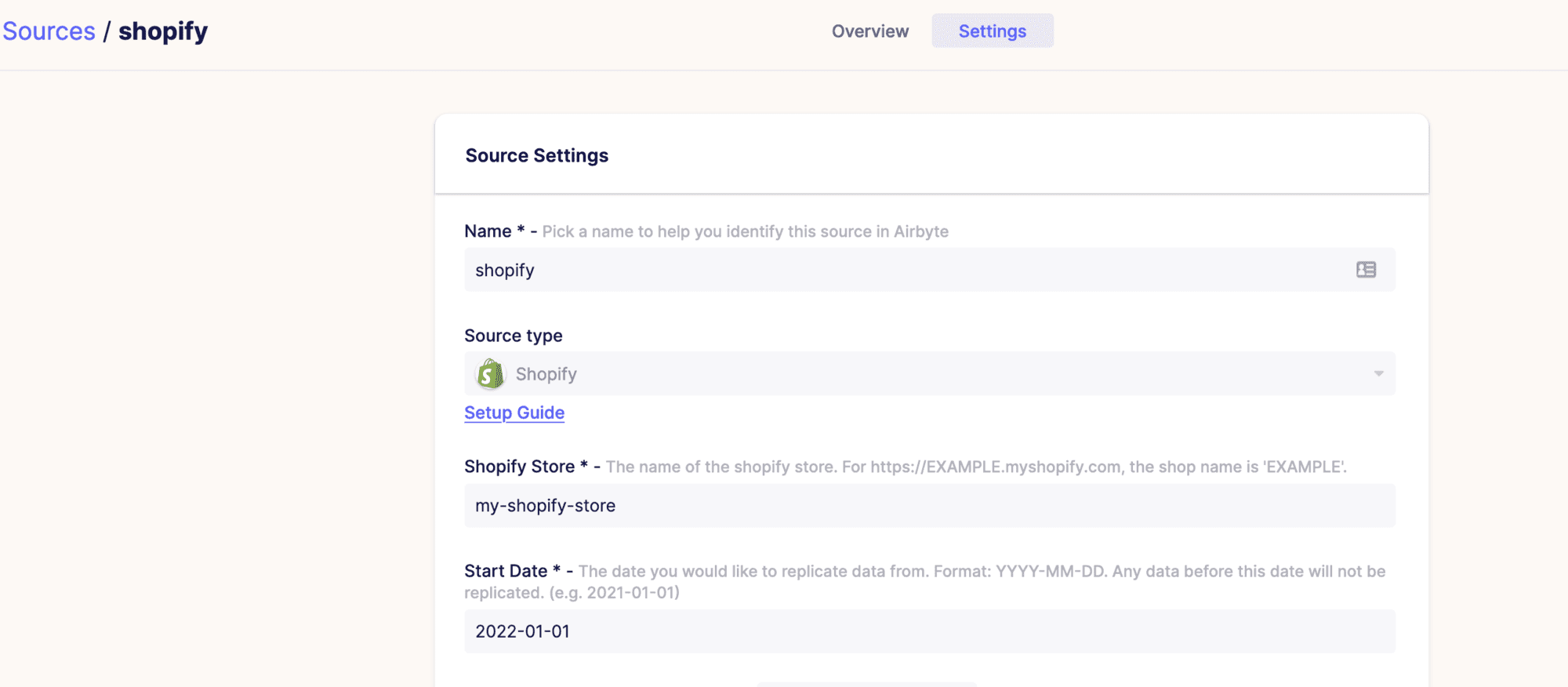
So how do we proceed? The concept is quite straightforward: Airbyte connects to a data Source. A source can be any one of multiple systems, but often it will make sense to connect to a SaaS (Software-as-a-Service) system like Salesforce, Shopify and many others. You select the source, for instance, Shopify, fill in the required connection credentials once, perhaps choose some specific options like only retrieving data from a certain date, and finally verify that Airbyte can connect.
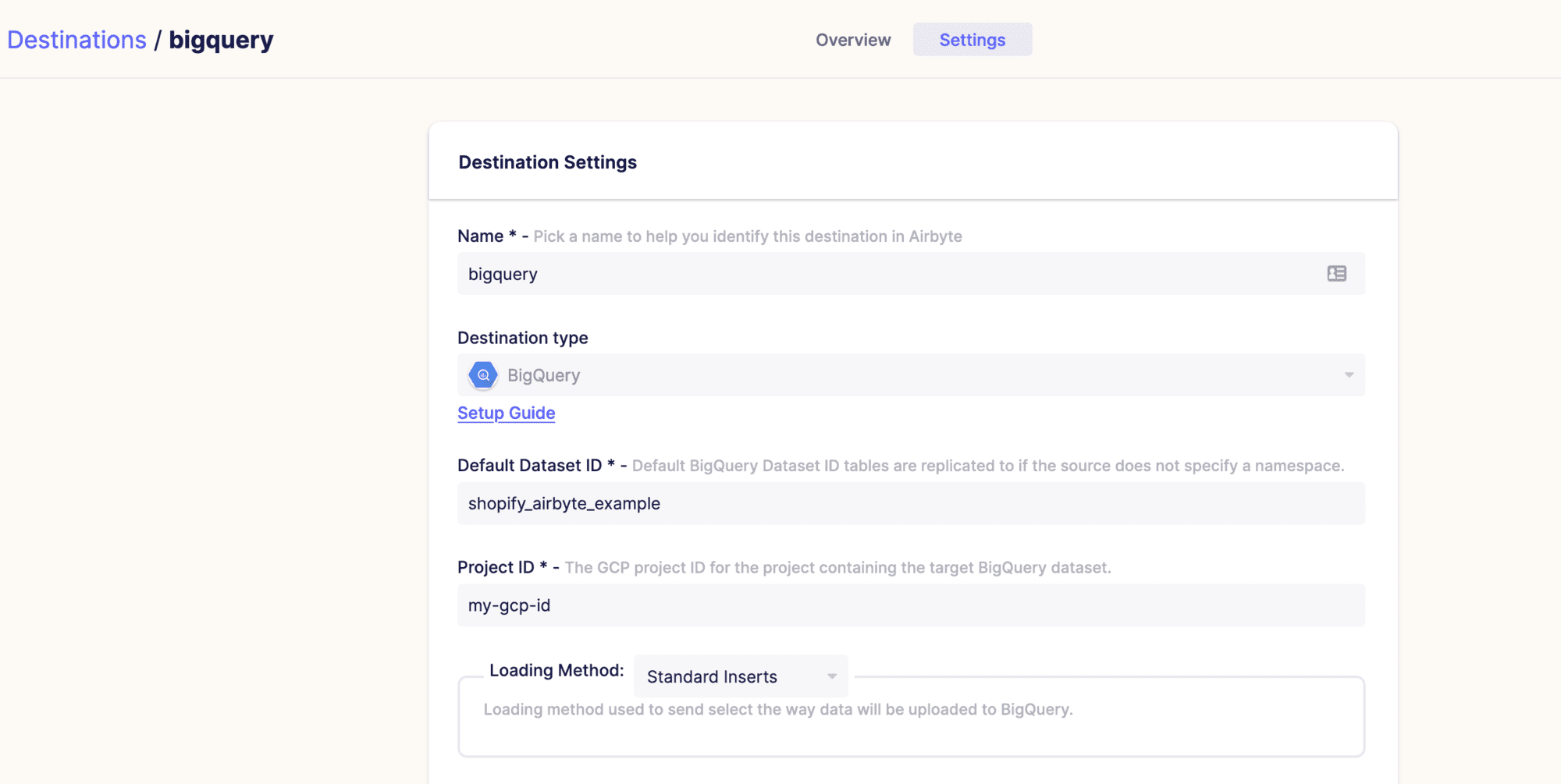
Next Airbyte needs a Destination. Again, this can be any one of multiple types of destinations, but in the ELT flow, it makes sense to use a cloud data warehouse like Google Big Query or Snowflake. And again, you only fill in the credentials, pick some options on how the data should be loaded, and verify.
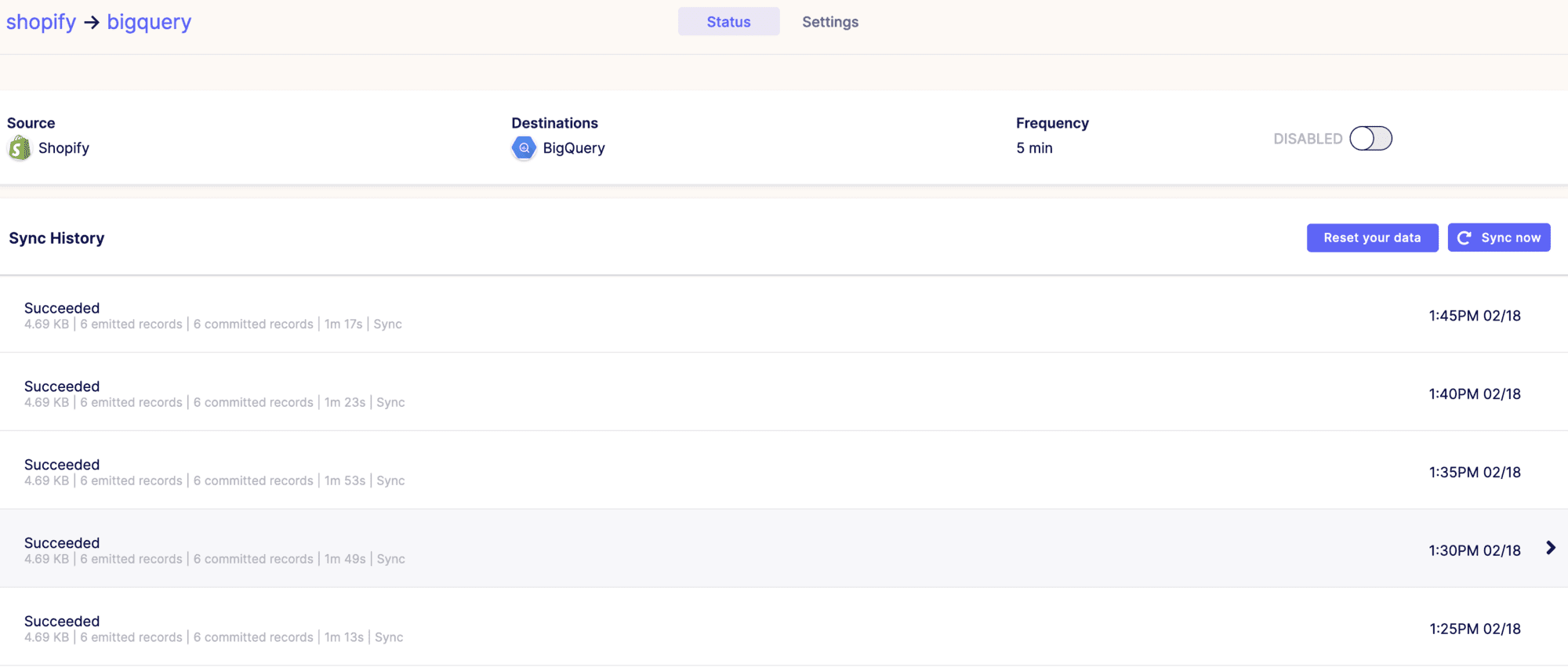
Starting a sync

Now that we have a Source and Destination set-up, we can start running jobs that ingest the data. Airbyte tracks these jobs in the UI, giving you an overview of the Sync History. Airbyte can now start sending data from source to destination, without a single written line of code!
Conclusion
We discussed Airbytes goals of providing a no-code data ingestion workflow with community created connectors. Then we followed the local deployment guide and discussed the Source and Destination connector. Using Airbyte, even a teammember with limited engineering knowledge can create an automated ingestion flow.
Will this fit all use cases? Certainly not, but the beauty of the Airbyte model is that you can contribute to the connector yourself by joining the open-source community. Airbyte boasts you can "build connectors in less than 2 hours" using their Connector Development Kit (CDK). It remains to be seen if it is as easy in practice as they claim, but it's certainly a possibility.
This was just a high-over of Airbyte. We will dive deeper into a data sync next part of the series. Until then!
Written by
Lasse Benninga




Contact