The first time I tried AI for data modeling, the resulting data model looked perfect on paper. Clean schema, right normalization, solid SQL in the dbt project. We handed it the DDL and asked for a Kimball model. What we got was technically correct... and completely wrong.
The problem wasn't the AI. The primary keys in this legacy system (built in the nineties) weren't actually primary keys. Technical constraints had forced the same IDs to be reused over time. An article_code meant different things in different departments, but both versions looked identical: a plain six-digit integer. When real data hit the model, it started generating duplicate rows and the logical cardinality broke. We went back to square one.
This was before the current generation of AI models, and we weren't anywhere near production. We were evaluating whether AI could help with data modeling at all. The verdict that day was no. Not because the AI couldn't write SQL, it was because of the lack of the right context.
Three kinds of context
Data systems carry context in three layers, but only one of them is written down.
The first is explicit: DDL statements, foreign keys, code that joins tables, schema files, documentation. This is the layer AI gets. It's also the only layer that's consistently written down.
The second is implicit: the shape of the data itself. Column names, value patterns, what's present and what's absent. You can infer a lot from this: an article_code that reuses integers across departments tells you something. New generation AI-Models (LLMs), like Opus 4.6, Gemini 3.1 and ChatGpt 5.2, are better at this than before and now they are able to extract a lot more conext from this layer.
The third is human. This is the one that determines whether a model actually works in practice. Tribal knowledge. Business rules. The history of why a column means what it means on Tuesdays but not on other days. The fact that "customer" means something different in the EU database than the US one. The reason there's a gap in the data every year because one country doesn't observe Daylight Saving Time.
Joe Reis has been writing about this convergence for a while. In his Practical Data Modeling series, he puts it directly: "While traditional modeling has focused on technical structure, it often overlooks a key component: shared understanding."
The 2026 State of Data Engineering survey found that 82% of practitioners use AI tools daily, but only 11% say their data modeling is going well. That gap is not a coincidence. It's the missing context layer.
The junior analyst already knows this
When a junior engineer joins a team, you don't hand them the DDL and say good luck. That's day one. After that comes the real onboarding: pair programming sessions where the context that isn't in any Confluence page gets transferred.
Things like:
- "Every year we have a gap in the data because this country doesn't have Daylight Saving Time, so we need to run a backfill."
- "We use three different tables for this because the business wants specific rules per domain."
- "The RED suffix means these tables are used for C-level reporting, but they hold the same data as these other tables."
We expect AI to know all of this just by looking at SQL.
A junior analyst joining a new team spends months reconstructing the human context layer. They ask questions, make mistakes, and slowly build up the picture. That's what onboarding is. AI gets the DDL and a system prompt, and we expect it to work like magic, without the months of context we give every human engineer before we trust them with the system.
I've worked on a project where management had to bring an engineer out of retirement. It was at a Dutch retail company, and he was the only person who still knew how the data was stored in the legacy system: what the codes meant, why the column names looked like cryptic abbreviations (Dutch shorthand from decades earlier). No AI was involved in that project. But the lesson transfers: if the human team couldn't reconstruct that context without him, an AI handed the same schema would have struggled just the same.
You can derive cardinality from code. You cannot derive meaning from structure alone.
Why a better prompt doesn't fix it
The first response to AI modeling failures is usually a better prompt. More detail, more context in the system message, a different framing. I've watched teams spend weeks on this.
It doesn't work. The problem isn't the prompt. The human context layer was never written down, so there's nothing to put in it. You can describe columns. You can't describe what you don't know, for example, if nobody ever wrote that a column means something different on Tuesdays on a blue moon you won't prompt for it.
The distinction that matters here is between prompt engineering and context engineering, a term Andrej Karpathy helped put into circulation in 2025. Prompt engineering is about how you ask. Context engineering is about what information exists before the model sees any question. For data modeling, the failure isn't upstream of the prompt. It's upstream of the data system itself.
Joel Spolsky's Law of Leaky Abstractions states that all non-trivial abstractions, to some degree, are leaky: the underlying complexity bleeds through. Applying this to data modeling means an AI can generate a schema that looks perfect on paper but breaks in production because it doesn't know that your logistics partner handles shipments differently, or that "customer" means something different across regions.
The abstraction hides the unwritten context. Until something breaks.
The methodology: do the conceptual phase first
Data modeling, from the beginning has been divided into three levels: conceptual, logical, and physical. The conceptual level captures the big picture: what are the fundamental concepts, and how do they relate? The logical level defines entities, attributes, and relationships. The physical level translates all of that into actual database objects: tables, columns, indexes. Ralph Kimball's foundational work codified this progression and it remains the bedrock of analytical data modeling today.
As Reis wrote in 2025: "Physical-first modeling is pervasive; it is the default way I see data modeling done today." Teams under pressure shoehorned design work into two-week sprints. Sprints replaced blueprints. The conceptual and logical phases quietly disappeared. And dbt made it even easier to skip them. As Reis wrote in 2023: "I think if you deploy in dbt it's easy to forget that the dbt model is still a data model, easy to stand up, easy to deploy, but when you need to explain it, dbt only gives you a lineage diagram and not how the content relates to each other."
Now AI models and agents need those blueprints to navigate our data systems. Skipping them is like hiring someone to renovate an old house without first asking for the electrical schematics. They'll make holes in the walls. With no blueprints, as a friend of a friend told me, while trying to hang a painting some of those holes will hit gas pipes...
The conceptual phase externalizes the human context layer before a single line of SQL is written:
- Topology: what entities exist and how they relate. Not tables. Concepts.
- Taxonomy: how entities are classified and named, what variations exist, how they connect.
- Ontology: formal definitions, business rules, the constraints that explain why things work the way they do.
- Glossary: agreed terminology that eliminates ambiguity across teams and systems.
Think back to the opening example: topology is the relationship between customer, order, and article. Ontology is the rule that article_code meant different things by department, the constraint nobody had written down. That's what broke the model.
Here's a version of that problem I've seen come up more than once. An international company runs a routine report: customer count by region. The EU returns 12,000. The US returns 4,200. Nobody knows why the ratio looks wrong. The numbers come from the same column, customer_id, in what is supposed to be the same table.
Five minutes on a call with John from US sales settles it. In the EU, a customer is an individual person with a billing relationship. In the US, a customer is a legal entity — a company that's signed a contract. The people inside that company are called clients. Same column name, completely different grain.
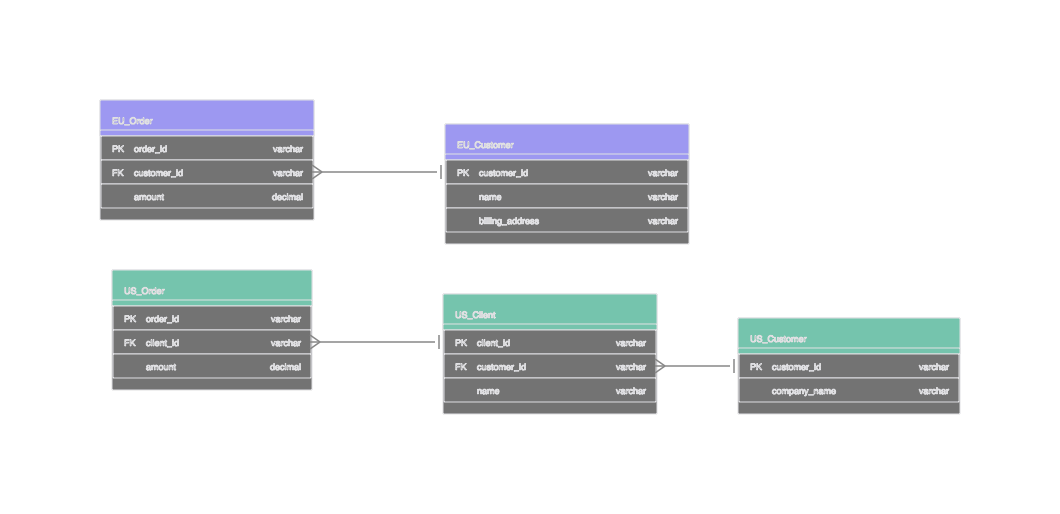
The fix isn't a migration or a refactor. It's three rows in a table:
John had the answer the whole time. Writing it down was the modeling.
These terms come from library science and cataloguing, applied to data modeling through the 1970s and 80s. Even if most teams today think this conceptual layer is a waste of time. Once this layer exists, the written record of your data system finally says what it means, not just what it looks like. AI can work with the full picture. The logical model follows naturally.
The physical implementation (dbt models, staging, marts) becomes close to mechanical. In Fundamentals of Analytics Engineering, we walk through this full progression in Chapter 5 — from conceptual design to logical modeling to physical dbt implementation, using real project patterns as the basis.
What it looks like when it works
A recent project for a travel agency in the Netherlands, aimed to migrate three legacy systems into Databricks on a tight timeline. We started with exploration, stakeholder interviews, and building a shared definition layer before touching the data. When we checked the metadata in the legacy databases, we found more than 2,000 SQL files to review. In the available time, going through all of it manually was close to impossible.
The client's AI policy allowed us to work with metadata and SQL structure, nothing with real customer data. We used Claude Code to scan 2,400 SQL objects in a couple of hours. It proposed an initial taxonomy, topology, and definitions. Those documents became the foundation for a logical data model: entities named by business concept, relationships governed by the rules the business actually followed, constraints made explicit before a single dbt model was written.
Then came the real test. One of the lead stakeholders began pushing back, challenging the design, questioning future-proofing, asking about use cases that hadn't been built yet. "How do you manage upselling?"
We knew exactly what he was pointing at. Because the logical data model existed, built on top of the conceptual layer. The stakeholder was reviewing a model that already spoke his language. His questions weren't gaps in our thinking. Most of them were already covered by the logical model, which only existed because we had built the conceptual foundation first.
The gaps that did surface were genuinely new features, things departing from the current system entirely. Design changes, not missing knowledge. The conceptual phase held under pressure.
The driver of the whole project was future functionality from Marketing: use cases that existed only in stakeholder conversations, nothing written down, everything in the head of the lead marketeer pushing the initiative. Getting a picture of how things ran now was the easy part. The harder part, and the part AI made manageable, was scanning what existed and building a foundation fast enough to have real conversations with stakeholders before the timeline ran out.
The problem does not stop at the project
The methodology above solves the context problem at the project level. But the same gap exists at two other scales, and both are starting to draw solutions.
At the individual level, every AI session starts from scratch. Six months of daily conversations is roughly 19.5 million tokens of lost context. MemPalace, an open-source project released this week by Milla Jovovich and developer Ben Sigman, tackles this directly. It stores every conversation locally in a navigable hierarchy: wings for projects, rooms for topics, halls for memory types. The result is 96.6% recall at near-zero cost, with no cloud dependency or summarization loss.
At the organizational level, the problem is larger. As Timo Dechau observed recently: Claude sessions are personal and isolated. Your context is yours. No knowledge layer spans teams, projects, or time. Data catalogs, semantic layers, and governed glossaries address this when treated as living organizational memory rather than compliance overhead. The conceptual artifacts from the methodology above (topology, taxonomy, ontology, glossary) are the raw material. Shared across projects, they compound.
Neither solves the problem alone. MemPalace gives the practitioner a memory. The organizational layer gives the team one. Both depend on the same foundation: context that was actually written down.
The unlock isn't a better AI
I've seen teams try this with prompts like "give me a Kimball star schema using these tables." The model delivers something. It always does. But what it delivers fills the gaps in the information it was given with assumptions, and sometimes those assumptions surface as hallucinations. We blame the model. The model was doing what it was designed to do with incomplete information.
Kimball's methodology has always started with the conceptual phase. Logical next. Physical last. That sequence exists because each layer depends on the one before it. When teams skip to the physical, the assumptions get baked in silently. When AI skips to the physical, they surface loudly.
The question isn't whether AI can model your data. Every team I've seen try this discovers it can. But only after doing the work that Kimball described in the first place: start with the concepts, agree on what things mean, build the picture before you build the model.
The context was always the job. AI just made it impossible to ignore.
I write about data and AI in practice in Navigating the Data & AI Landscape. The patterns in this post showed up across editions w6, w10, and w11. This post is the framework I was circling around. If it resonated, the newsletter is where the weekly observations land first.
Written by

Ricardo Granados
Our Ideas
Explore More Blogs




Contact