Blog
Accelerate Data Processing with Azure SQL Memory-Optimized Tables

Oftentimes, utilizing Azure SQL Server with disk-based tables is adequate and will work well for most applications. I think it’s important to keep in mind there are implications around concurrency which can lead to detrimental effects. Disk-based tables use locks to manage concurrent scenarios which can lead to slow performance when executing multiple operations within a specific time window. There are things you can do like add indexes (whether it’s the clustered or non-clustered variety) to the tables but even this may not be enough.
Perhaps you are building (or looking to build) a highly transactional application which will be reading and writing data to and from a table in rapid succession. One option in this scenario is using memory-optimized tables. They are designed to support large volumes of transactions with consistent low latency. Memory-optimized tables are lock free and store everything in memory leading to much faster data access and eliminating disk read and write operations. This blog article will explore using Azure SQL memory-optimized tables for applications which require a relational data model and highly performant operations.
Highly Performant Application Scenario
Let’s imagine an application which retrieves data from 3rd party RESTful APIs, processes the data and then stores it in an Azure SQL database. Here are a few characteristics of the application:
- Data is processed as fast as possible.
- For each processing iteration, there over 150k rows of data which will either be inserted or updated.
- The data is being read at any time within any frequency by a web API and corresponding web UI.
- The application is only concerned with new data coming from the 3rd party RESTful endpoints.
- There is no need to store data for historical reasons.
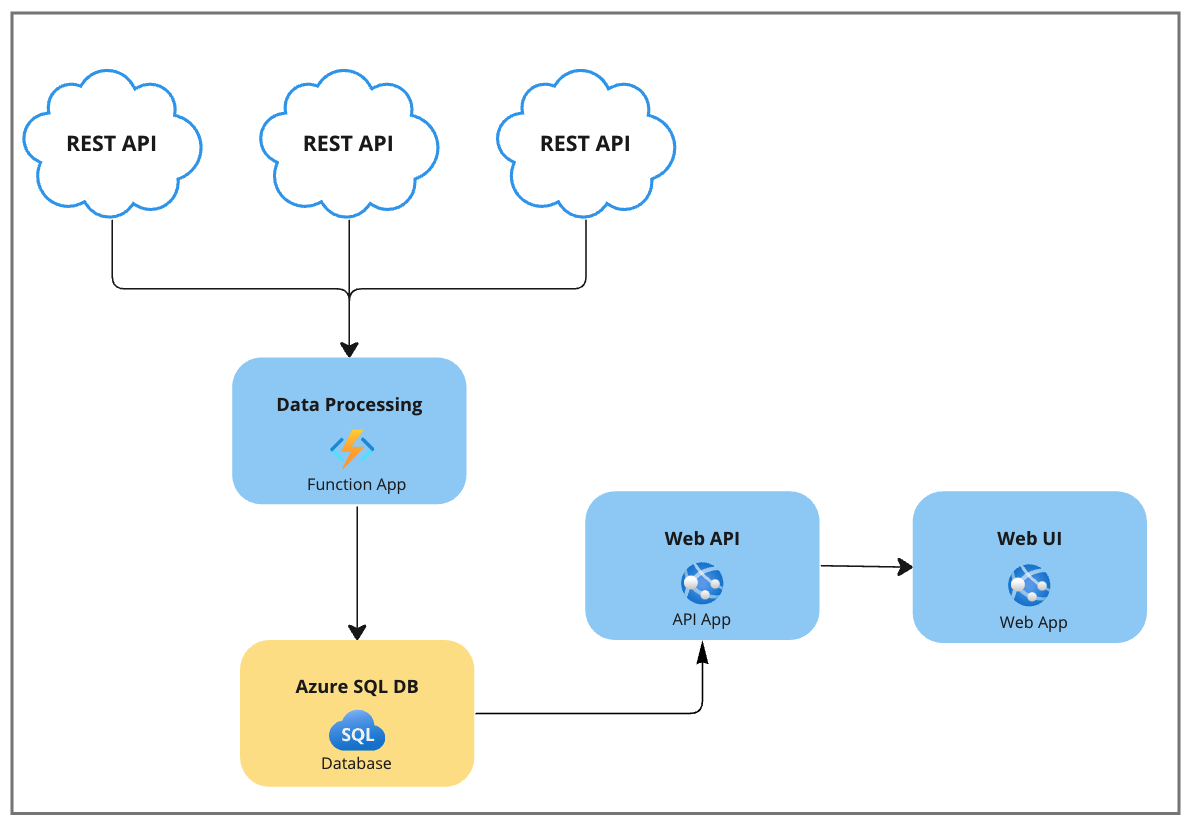
You may be thinking “Is this the right architecture?” or perhaps “we can introduce scaling here”. Putting those thoughts aside, let’s focus specifically on the data transactions themselves given this scenario.
When using disk-based tables in this scenario there are a few options that come to mind to introduce additional performance. The options include:
Kill-and-Fill
Each time the ‘Data Processing’ functions app triggers, we can delete everything in the Azure SQL table and replace it with all new data coming from the RESTful endpoints.
| Pros | Cons |
| Simple Operation(s) | Momentary lapses in data while the kill-and-fill operation is still executing |
| Does not require any complex comparison logic to determine if any existing data has changed | There would be cases where the UI would retrieve incomplete data during the kill-and-fill operation |
| Indexes would have to be reapplied when deleting all data at first | |
| Depending on how much data exists in the table, it could be an expensive operation |
Diff the Data
The incoming data can be compared with existing data and update accordingly. This can either be done by performing an outer join on specific columns of the table or generate a hash key based on specific values and compare one hash key to another.
| Pros | Cons |
| Maintains indexes since some data will always be present in the table | Complex Operations (logic can be performed either in code or using a SQL stored procedure) |
| This operation could become very expensive and add additional latency to the overall process | |
| Higher complexity which leads to errors and edge cases where issues could come up |
Combination of both with Bulk Copy
Another approach could include performing a pseudo kill-and-fill but persisting the last iteration’s data, so the table is never empty. When inserting the data, the SQL Bulk Copy class can be utilized for faster insertion.
| Pros | Cons |
| Faster inserts | Higher Complexity around tracking the data from the last iteration |
| Maintains indexes | Multiple operations could become very expensive and add additional latency to the overall process |
Ultimately each of these options still leave considerable negative impacts. Let’s look at a completely different approach using memory-optimized tables.
Using Memory Optimized Tables
Given the scenario of this application, memory-optimized tables would be a great approach, they can provide up to 30X more performance improvement. They were designed to support large volumes of transactions with regular low latency for individual transactions. One of the primary mechanisms in which this performance improvement is attained is by removing lock and lack contention between concurrently executing transactions. All transactions within memory-optimized tables are also durable. All changes are recorded to the transaction log on disk which provides data redundancy. In addition to the tables themselves, developers can leverage natively compiled stored procedures which further reduce the time taken for transactions by reducing CPU cycles. If we examine the characteristics of the application again, using memory-optimized tables were designed to handle scenarios like this.
Creating and Reading Memory Optimized Tables
There is plenty of documentation Microsoft provides which will illustrate how to create memory-optimized tables. It can be done by using SQL Server Management Studio (SSMS), I’ve included a simple DDL script which shows how to create a table. Notice the ‘MEMORY_OPTIMIZED’ value is set to ‘ON’ and the ‘DURABILITY’ is set on line 20. The options for setting the durability can be seen here.
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[DataProviders]
(
[Id][bigint] IDENTITY(1, 1) NOT NULL,
[DataProvider][nvarchar](50) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL,
[Value][nvarchar](200) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
CONSTRAINT[PK_DataProviders] PRIMARY KEY NONCLUSTERED
(
[Id] ASC
)
)WITH(MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_ONLY)
GODepending on how the data is being accessed from code, you can write queries directly to the memory-optimized tables either by using inline SQL (if raw ADO is being used) or Linq queries (if the Entity Framework is being used). As stated before, for improved performance, natively compiled stored procedures can be used as well.
Natively Compiled Stored Procedures
If we revisit the kill-and-fill approach, we discussed using disk-based tables, the same approach can be used here with memory-optimized tables, but the big difference is the performance. The cons listed above would essentially be eliminated because of the dramatic performance improvement. As an example, the following two code snippets demonstrate how to remove and insert (kill-and-fill) data using natively compiled stored procedures.
Notice the ‘WITH native_compilation’ on line 9 is being used, the details of creating these stored procedures can be found here.
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE PROCEDURE [dbo].[memory_delete]
@lastProcessedDate Datetime,
WITH native_compilation,
schemabinding
AS
BEGIN
atomic WITH (TRANSACTION isolation level = snapshot, language = N'us_english');
DELETE FROM dbo.[Outcomes]
Where Created < @lastProcessedDate;
END
GOThis procedure makes use of a table-valued parameter called ‘memdataproviders’. When invoking the procedure from code, a DataTable object can be constructed in .NET code and passed in as a parameter to the procedure (line 8).
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE PROCEDURE [dbo].[memory_insert]
@memdataproviders dbo.dataproviders readonly
WITH native_compilation,
schemabinding
AS
BEGIN
atomic WITH (TRANSACTION isolation level = snapshot, language = N'us_english');
INSERT INTO [dbo].[DataProviders]
(
[DataProvider] ,
[Value]
)
SELECT
[DataProvider] ,
[Value]
FROM @memoutcomes
END
GOCost
As with anything, something to keep in mind when deciding to use memory-optimized tables is the cost. This type of technology is only available in the Azure SQL Premium and Business critical tiers. The details of the pricing comparisons between each tier can be viewed here.
Conclusion
When building applications, deciding on the best approach can always be challenging. This blog article has explored a specific scenario of a highly performant application processing significant amounts of data continuously as fast as possible. This scenario is applicable to many industries and use cases. If you think about financial instruments, mobile gaming, or ad delivery, it’s clear where this presents itself. Memory-optimized tables can be an excellent approach to managing data processing in Azure while maintaining the best performance possible while using Azure SQL relational databases. Consider using it when facing similar challenges in your application design!
Learn more about how Xpirit can help you transform your business !
Follow me on Twitter here!
Written by

Esteban Garcia
Managing Director at Xebia Microsoft Services US and a recognized expert in DevOps, GitHub Advanced Security, and GitHub Copilot. As a Microsoft Regional Director (RD) and Most Valuable Professional (MVP), he leads his team in adopting cutting-edge Microsoft technologies to enhance client services across various industries. Esteemed for his contributions to the tech community, Esteban is a prominent speaker and advocate for innovative software development and security solutions.
Contact