Maschinelles Lernen hat eine Vielzahl von Anwendungsmöglichkeiten. Es gibt zahlreiche Probleme, die Machine Learning lösen kann, für große und kleine Unternehmen. Doch obwohl Machine Learning für unzählige Aufgaben eingesetzt wird, ist es keine einfache Lösung. Es erfordert eine Menge Training und Daten, daher sollten Entwickler so gut wie möglich mit der Technologie vertraut sein - selbst wenn das bedeutet, dass sie Prototypen und Proof of Concepts (PoCs) für Brettspiele erstellen müssen!
Beeindruckt von DeepMinds AlphaZero-Erfolg beim Go-Spiel haben wir versucht, einen ähnlichen Ansatz zu verwenden, um KI für das hochgelobte Brettspiel Azul zu implementieren. Wir entdeckten, dass Verstärkungslernen kein notwendiger Bestandteil einer erfolgreichen Lösung ist - und wir lernten auch, dass die Verwendung Ihrer Lieblingstools Sie manchmal in die Irre führen kann.
Kapitel 1: Wo alles gut geht
AlphaGo und AlphaZero - eine Inspiration
Im März 2016 erfuhr die Welt, dass ein von DeepMind entwickelter Algorithmus ein Go-Turnier (ein historisches Spiel aus China) gegen den koreanischen Großmeister Lee Sedol gewonnen hat. Die Gemeinschaft des maschinellen Lernens war schockiert, denn Go gilt als eines der schwierigsten Brettspiele, für das man einen Computerspieler implementieren kann, aufgrund der astronomischen Anzahl möglicher Spielzustände und der sehr großen Verzweigungsrate bei jedem Zug.
Die historische Leistung von DeepMind war das Ergebnis sowohl der innovativen Architektur des neuronalen Netzwerks als auch der millionenschweren Investitionen in die Rechenleistung. Der betreffende Algorithmus wurde später verallgemeinert, um mit weiteren Brettspielen (wie Schach und Shogi) zu arbeiten und - was noch erstaunlicher ist - so überarbeitet, dass er ohne Expertenwissen zu lernen beginnt, tabula rasa, nur in der Lage, zu erkennen, welche Züge für den gegebenen Zustand des Brettes möglich sind.
Wir haben uns von der Einfachheit und Intelligenz des Ansatzes von DeepMind inspirieren lassen und beschlossen, einen eigenen Computerspieler zu entwickeln, der ein Brettspiel spielen kann. Insbesondere wollten wir eine Reihe von Regeln implementieren, aber kein Expertenwissen über erfolgreiche Strategien oder Taktiken einbeziehen.
Azul: Das Brettspiel der Wahl für unseren Software-Agenten

Azul ist ein sehr beliebtes Brettspiel, das bei BoardGameGeek (zum Zeitpunkt der Erstellung dieses Artikels) auf Platz 1 in den Kategorien "Abstrakt" und "Familie" steht - die sich nicht sehr oft überschneiden. Es hat auch den prestigeträchtigen Preis "Spiel des Jahres" im Jahr 2018 gewonnen, neben vielen anderen Auszeichnungen.
Die Regeln sind recht einfach: Die Spieler wetteifern darum, Muster aus bunten Plättchen anzuordnen und dabei Ressourcen aus einem gemeinsamen Vorrat zu ziehen. Punkte gibt es für das Ausrichten von Plättchen in Reihen und Spalten, mit Boni für eine vollständige Reihe, eine vollständige Spalte und ein vollständiges Plättchen-Farbset. Hier erfahren Sie mehr über die Regeln und das Spielprinzip hier.
Für uns ist jedoch wichtig, dass Azul einige wichtige spieltheoretische Kriterien erfüllt, darunter:
- perfekte Information - die Spieler haben keine Geheimnisse, da der Zustand des Spielbretts für alle Spieler jederzeit sichtbar ist
- diskret - die Spieler machen einen genau definierten Zug, abwechselnd, einer nach dem anderen
- deterministisch - für einen bestimmten Spielzustand führt der gleiche Zug immer zum gleichen neuen Spielzustand (mit Ausnahme der zufälligen Auffüllung der Spielsteine nach jeder Runde).
Anders als bei Go oder Dame, wo ein einzelnes Spiel mit einem Sieg einer Seite (oder einem Unentschieden) endet, kann bei Azul die Erfolgsquote auch als Anzahl der vom Spieler erzielten Punkte gemessen werden. In einem etwas vereinfachten Ansatz können wir die Qualität des Agenten als die durchschnittliche Anzahl der Punkte im Selbstspiel messen, anstatt die Gewinnquote gegen einen Gegner zu zählen.
Dieser Ansatz ermöglicht uns auch eine zusätzliche Vereinfachung - wir können das Problem der "offensiven Rivalität" komplett auslassen und nur gegen unseren eigenen Punktestand optimieren. Unser Agent wird nur den gemeinsamen Brettbereich und sein eigenes Unterbrett betrachten und die Position des gegnerischen Unterbretts ignorieren. Aus Erfahrung wissen wir, dass man in Azul die Pläne des anderen Spielers in der Regel durchkreuzen kann, indem man einen suboptimalen Zug macht, der den anderen mehr schadet als uns. Im Allgemeinen ist es schwer, den Grad der Aggression und Wettbewerbsfähigkeit eines Computerspielers zu beurteilen, daher haben wir dieses Problem komplett übersprungen.
Monte Carlo Baumsuche: Eine intelligente Herangehensweise an ein altes Problem
Bei Brettspielen können Sie oft die Zukunft vorhersagen, indem Sie die Antworten Ihrer Gegner auf Ihre Züge erraten, dann Ihre Gegenaktionen erfinden, deren Gegen-Gegenaktionen erraten und so weiter. In der Informatik wird dieser Ansatz als Baumsuchproblem bezeichnet (ein Begriff aus der Graphentheorie). In diesem Fall steht jeder Baumknoten für einen Spielzustand und jede Kante, die die Knoten verbindet, für einen einzelnen Zug. Bei vielen Spielen wächst die Anzahl der möglichen Züge viel zu schnell, so dass selbst die größten Supercomputer nicht in der Lage sind, den gesamten Baum durchzugehen und den optimalen Zug auszuwählen.
Seit den Anfängen der Informatik wurden Algorithmen wie "Minimax" und "Alpha-Beta Pruning" verwendet, um Berechnungen zu erkennen und zu überspringen, die das Ergebnis eines Spielers mit Sicherheit nicht verbessern werden. Diese Einsparungen waren jedoch viel zu gering, um die Vorhersagekraft eines Computers wirklich zu verbessern, so dass moderne Ansätze randomisierte Heuristiken gegenüber deterministischen Algorithmen bevorzugen. Heuristiken bieten nicht immer eine optimale Lösung, aber in der Praxis ermöglichen sie es uns, mit Herausforderungen umzugehen, die außerhalb der Reichweite traditioneller Algorithmen wie Minimax liegen.
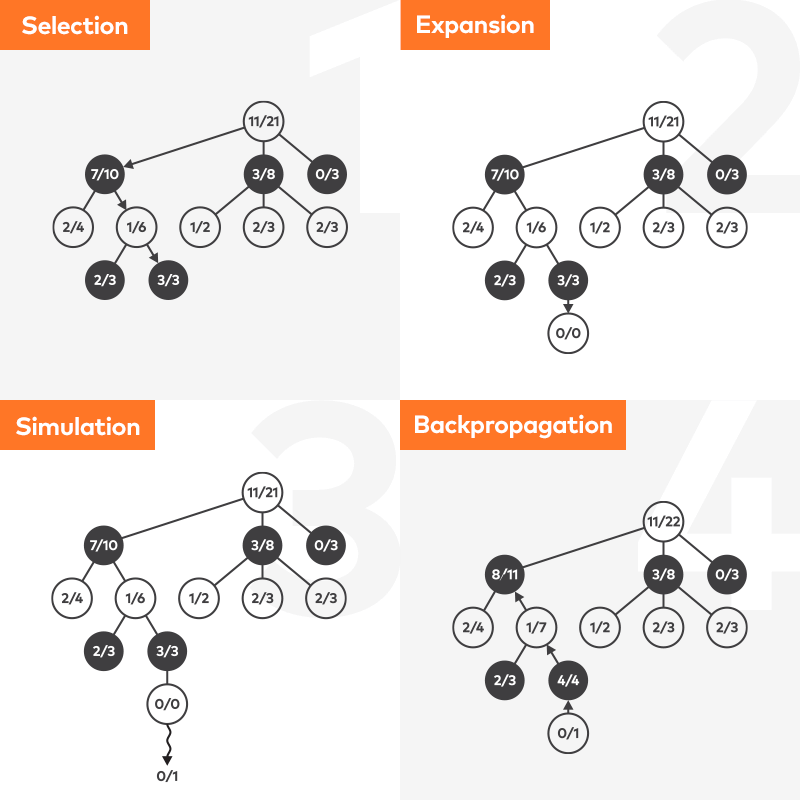
In unserem Ansatz haben wir die Monte Carlo Tree Search (MCTS) verwendet, die - wie der Name schon sagt - den Wert der gegebenen Züge mit Hilfe des Zufalls "errät". Wir werden den Algorithmus nicht vollständig beschreiben, da es bereits viele ausgezeichnete Artikel und Video-Tutorials zu diesem Thema gibt. Es ist nur wichtig zu wissen, dass MCTS kontinuierlich mögliche Spielverläufe von einem bestimmten Zustand aus simuliert und nach jeder Iteration den geschätzten Wert der untersuchten Züge aktualisiert. Eine Simulationsschleife kann entweder nach einer angenommenen Anzahl von Iterationen oder nach Ablauf einer bestimmten Zeitspanne unterbrochen werden.
Alles auf einen Blick - .Net Core Azul mit MCTS
Die meisten Computerimplementierungen von Brettspielen sind sehr ähnlich. Wir können eine Klasse unterscheiden, die den aktuellen Spielzustand festhält. Das bedeutet in der Regel, dass Aufzeichnungen über die Spielfiguren und ihre spezifischen Positionen oder ihr Vorhandensein sowie das Fehlen von Karten, Spielsteinen, aktiven Boni und so weiter geführt werden. Andere Klassen repräsentieren einzelne Spielzüge und KI-Agenten. Es gibt auch eine Arena, die den Spielstatus aktualisiert und die Agenten überwacht, indem sie ihnen erlaubt, alternative Züge auszuführen und sicherstellt, dass kein Agent schummeln kann (z.B. indem er verbotene oder unmögliche Züge macht).
Wir haben uns dafür entschieden, unsere Lösung in .Net Core zu implementieren, teilweise aufgrund persönlicher Vorlieben für die Sprache C# und das Microsoft-Ökosystem, aber auch wegen der einfachen Portierbarkeit auf Linux. Genauer gesagt, war überhaupt keine Portierung erforderlich, da derselbe C#-Code unter Windows und Linux lief - aber dazu später mehr!
Der erste Agent war der "manuelle" Agent, bei dem ein Mensch die Züge machte - dies diente dazu, alle Fehler in der Regelmaschine und fehlerhafte Randfälle zu identifizieren und zu beseitigen. Dann nahmen wir den MCTS-Agenten, der... wie ein totaler Noob spielte und selten über null Punkte kam. Azul verzeiht wirklich keine dummen Spielzüge und die Strafpunkte sind hoch. Bei einer anschließenden Debug-Sitzung stellte sich heraus, dass wir den Fehler gemacht hatten, die MCTS-Abrollphase zuzulassen, bis das Spiel zu Ende war, was zu einer Reihe von zufälligen Neuauffüllungen der Kacheln führte - jede MCTS-Iteration spielte also ein anderes Spiel. Kein Wunder, dass die Ergebnisse nicht zu einem sinnvollen Ergebnis konvergierten!
Die Lösung für das obige Problem bestand darin, den Vorhersagehorizont auf das Ende der aktuellen Phase zu begrenzen. Das bedeutet, dass der Agent keine langfristige Planung vornimmt, sondern sich nur auf das Ziel konzentriert, das hier und jetzt erreichbar ist. Natürlich ist es möglich, eine langfristige Strategie mit gefälschten Zielen und Boni künstlich hinzuzufügen, z.B. indem man eine ungültige Punktzahl für 3 oder 4 Plättchen in einer Farbe gewährt, während die Spielregeln nur einen Bonus für 5 Plättchen vorsehen. Wir haben uns entschieden, diese Option auszulassen und stattdessen zu prüfen, wie hoch die durchschnittliche Punktzahl ist, ohne Hilfe von menschlichen Experten.
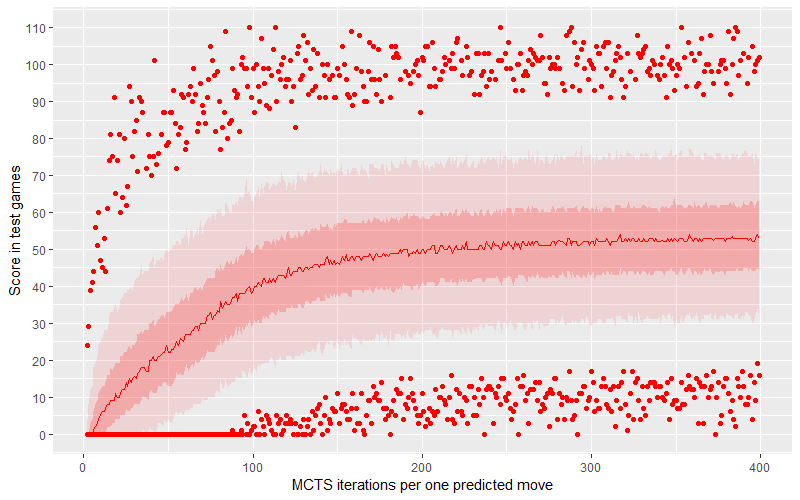
Es stellte sich heraus, dass der MCTS-Agent wirklich gut ist. Wir haben die Anzahl der MCTS-Schleifen als Metaparameter behandelt und die Ergebnisse mit einer Spanne von 2 bis 400 Iterationen und einer Simulation von 1.000 Spielen für jeden Wert überprüft. In der obigen Grafik sehen wir die Beziehung zwischen der Anzahl der Schleifen und der durchschnittlichen Punktzahl. Das dunkle Band ist die mittlere Hälfte der Punkte (2. und 3. Quartil), während das helle Band die mittleren 90 % der Punkte darstellt (wobei 5 % von oben und unten wegfallen - das sind Ausreißer).
Es stellte sich heraus, dass sowohl die mittlere als auch die durchschnittliche Punktzahl in einem durchschnittlichen Spiel 50 Punkte übersteigt, wenn die Anzahl der MCTS-Schleifen (pro einzelnem vorhergesagtem Zug) größer als 225 ist. Wichtig ist hier auch, dass die minimale Punktzahl für simulierte Spiele sogar schon früher über Null steigt... Wir müssen jedoch bedenken, dass die zufälligen Belohnungen und Bestrafungen von Azul schwerwiegend sein können und extreme Punktzahlen nicht so viel über die Stärke des Algorithmus aussagen, wie es auf den ersten Blick scheinen mag.
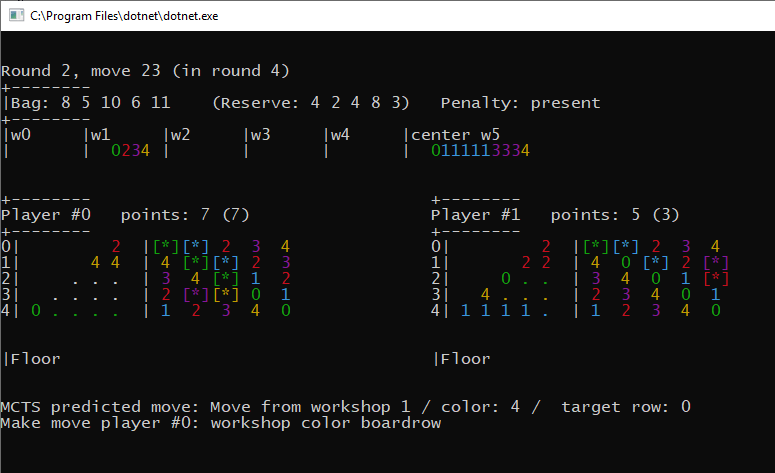
Auch die Leistung entsprach den Erwartungen, denn mit 300 Iterationen pro Zug konnten wir ein komplettes Spiel in 0,5 Sekunden auf einem einzigen CPU-Kern simulieren, was auf einer typischen Entwickler-Workstation (i5 8500, 6 Kerne, für diejenigen, die neugierig sind) zu über 10.000 Spielen pro Stunde parallelisiert werden konnte.
Natürlich haben wir auch Spiele gegen unseren Agenten getestet und wir müssen sagen, dass seine Züge einfach Sinn machen. Der Unterschied zwischen dem Spiel mit einem Menschen kann auch sichtbar sein - Mitspieler schätzen in der Regel eine höhere Punktzahl und mehr Bonusleistungen als ein schnelles Ende. Der Agent tat das Gegenteil; er beendete das Spiel so schnell wie möglich wegen eines kleinen Reihenbonus (ebenfalls eine Bedingung für das Spielende), ohne zu wissen, dass es in der nächsten Runde wertvollere Anreize gibt.
Kapitel 2: Wo wir auf einige Probleme stoßen
Wer braucht schon Python?
Seit Beginn dieser Forschung wollten wir den "magischen" Ansatz des maschinellen Lernens ausprobieren. Wissen Sie, jeder kann verstehen, wie die Baumsuche funktioniert, wohingegen es schwierig ist, neuronale Netzwerke als Konzept zu verstehen und noch schwieriger zu verstehen, wie ein bestimmtes Problem in einem trainierten Netzwerk intern dargestellt wird. Ein neuronales Netzwerk, das Azul spielt, wäre also sicherlich etwas, das ein wenig geheimnisvoll ist.
Wenn Sie die Community für maschinelles Lernen verfolgen oder sich in ihr engagieren, ist Ihnen sicherlich die ungewöhnliche Popularität der Programmiersprache Python aufgefallen. Es ist ein sehr universelles Werkzeug und viele Menschen ohne Informatikhintergrund sind in der Lage, sich schnell die Grundlagen anzueignen, mit dem Prototyping von einfachem Code zu beginnen, ihr Problem zu lösen und mit zunehmenden Fähigkeiten zu Bibliotheken von Drittanbietern zu greifen. Aber wenn Sie bereits jahrzehntelange Erfahrung mit .NET, Java und R haben, hat Python viel weniger zu bieten - zumal die beliebtesten ML-Bibliotheken wie Keras Wrapper und Schnittstellen zu anderen Sprachen haben.
Wir beschlossen, unsere Kenntnisse der Sprache R, die bei vielen Datenwissenschaftlern beliebt ist, zu nutzen und die bestehenden, ausgereiften Keras-Bindings zu verwenden, die in der R-Umgebung verfügbar sind. Durch die Wahl von Tensorflow als Low-Level-Backend für Keras hofften wir, die Leistung der GPU sowohl auf Windows- als auch auf Linux-Rechnern nutzen zu können. R selbst würde in unsere C#-Implementierung eingebettet werden, unter Verwendung einer R.NET-Interop-Bibliothek. Erfahrene Softwareentwickler können hier bereits eine Kette von Abhängigkeiten erkennen: C# ruft die Interop-Bibliothek auf, diese ruft den R-Code auf, dieser ruft den Keras-Wrapper auf, dieser ruft den Python-Code auf, dieser ruft den Tensorflow-Code auf, dieser ruft die CUDA-Bibliothek auf, diese ruft - schließlich - die Ausführung von Berechnungen auf dem Grafikprozessor.
Abhängigkeiten sind schwierig
Da F&E-Projekte nur eine kurze Lebensdauer haben, haben wir uns für eine solche Menge an Abhängigkeiten entschieden, wohl wissend, dass diese sehr anfällig sind. Wir haben eine schnelle Reihe von Proof of Concepts für jede Phase entwickelt und zum Glück hat alles funktioniert. Aber, Kinder, ich muss Sie warnen! Versuchen Sie das nicht in Produktionsumgebungen! Es wird eine Zeit lang funktionieren, kann aber nach jeder zufälligen Aktualisierung einer Komponente leicht zusammenbrechen. Ich habe Sie gewarnt.
Das erste Problem, auf das wir stießen, war das Single-Threading-Modell von R.NET. Das ist zwar nicht schlimm, aber es wäre schön, wenn die MCTS-Agenten in parallelen Threads mit voller Geschwindigkeit laufen würden. In diesem Fall müssten wir Interprozess-Sperren implementieren, was zwangsläufig zu Leistungseinbußen führen würde.
Das zweite Problem war die Kompatibilität der R.NET-Bibliothek mit der Laufzeit der Sprache. Da sich die Entwicklung dieser Bibliothek im Jahr 2017 deutlich verlangsamt hat, war die letzte verfügbare Version (zum Zeitpunkt der Erstellung dieses Artikels) nicht mit der 2018 veröffentlichten R-Laufzeitversion 3.5 kompatibel. Alte R-Versionen sind zwar noch verfügbar, aber es wird mit der Zeit immer schwieriger, sie zum Laufen zu bringen. Aus diesem Grund haben wir uns für R 3.4.4 entschieden.
Das dritte unerwartete Problem schließlich traf uns am härtesten, da wir es in der anfänglichen PoC-Phase nicht bemerkt hatten. Die R.NET-Bibliothek ist in der Lage, R-Aufrufe 30.000 Mal pro Sekunde aufzurufen. Wenn wir jedoch Hunderte von Ein- und Ausgabeparametern zum Aufruf des R-Codes hinzufügen, bricht der Hauptprozess nach einiger Zeit ab und löst eine System.StackOverflowException aus.
Zu unserer anfänglichen Überraschung trat dies sowohl unter Windows als auch unter Linux auf. Soweit wir die Kommentare im Github Bugtracker verstanden haben, ist R nicht in der Lage, die Garbage Collection einer großen Anzahl von unbenannten Objekten zu bewältigen, die von der R.NET Bridge erstellt werden. Schlimmer noch, das Problem trat erstmals 2015 auf und schien ein echter Problemfall zu sein - wir versuchten es mit Drosselung, manuellen GC-Aufrufen sowohl auf R- als auch auf C#-Seite, manuellem Abstimmen der Stackgröße... aber nichts funktionierte. Das Mindeste, was wir tun konnten, war, einen reproduzierbaren Fehlerbericht zu erstellen und auf das Beste zu hoffen. Nach ein paar Wochen wurde das Problem nun bestätigt, aber weder behoben noch für eine Korrektur vorgesehen.
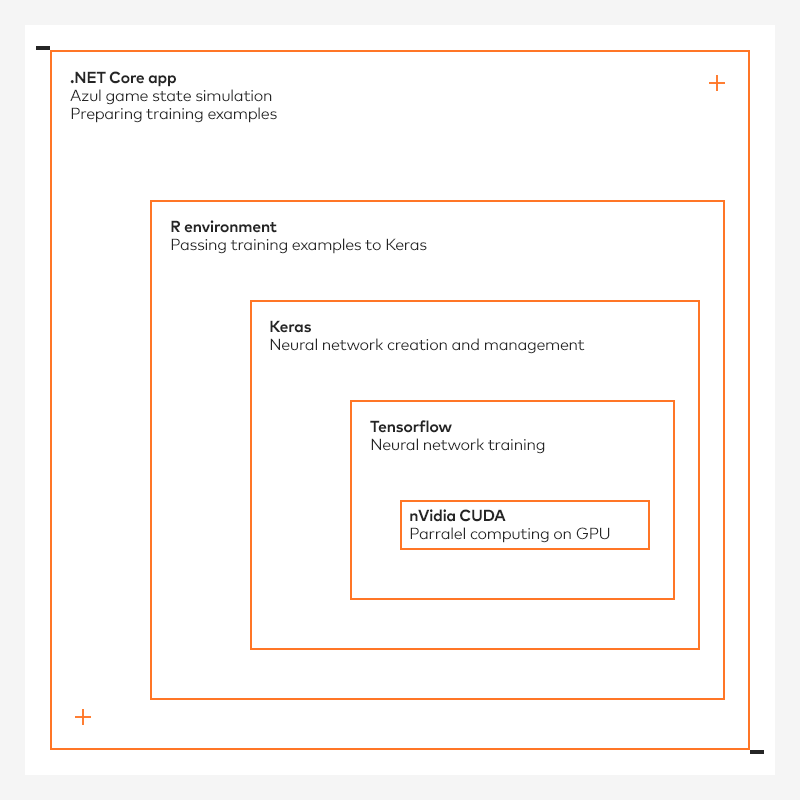
Daher haben wir einen Workaround entwickelt, der noch mehr Abhängigkeiten mit sich brachte. Da das Problem erst auftrat, als wir Tausende von Vorhersageaufrufen erreichten, beschlossen wir, weiterhin eingebettetes R mit Keras zu verwenden, um das NN-Modell zu trainieren, aber später die trainierten Gewichte in eine Datei zu exportieren, sie mithilfe von explizitem Python-Code (eine neue Abhängigkeit!) in das rohe Tensorflow-Protobuf-Format zu konvertieren, sie in eine TensorFlowSharp-Komponente zu laden (eine weitere neue Abhängigkeit!) und mit der Vorhersageinferenz über diese neue Komponente fortzufahren - die glücklicherweise stabiler ist als R.NET.
Auch hier ist die gesamte oben beschriebene Einrichtung sehr anfällig. TensorFlow und TensorFlowSharp hängen von der NVidia CUDA Version ab, Keras hängt von der Tensorflow Version ab, R.NET hängt von der R Version ab und, noch besser, die Hälfte der oben genannten Komponenten hängt von der Python Version ab (oder umgekehrt). Es ist zu erwarten, dass eine Komponente, die hinterherhinkt, Sie dazu zwingt, ganze Versionen des Setups einzufrieren, und dass alle ungepatchten Sicherheitslücken Sie für immer verfolgen werden.
Sie bevorzugen vielleicht C# oder Java, aber wenn Ihr Toolset keine direkten Bindungen zu diesen Sprachen unterstützt, riskieren Sie die langfristige Lebensfähigkeit Ihres Projekts.
Auf der positiven Seite waren wir wirklich beeindruckt von der Kompatibilität der .NET Core-Umgebung sowohl auf Windows- als auch auf Linux-Betriebssystemen. Beide Laufzeiten nahmen NuGet-Abhängigkeiten und Artefakte auf, so dass wir Berechnungen problemlos von der Dev-Box auf einen leistungsfähigeren Linux-Rechner mit mehr RAM und einer RTX 2080 Ti an Bord verlagern konnten. Die Bereitstellung dieser komplexen Lösung funktionierte einfach und manchmal mussten wir nur einige Laufzeitdaten anpassen, z. B. einen Pfad zu einer ausführbaren Python-Datei angeben oder eine gemeinsam genutzte Bibliothek registrieren.
Azul Neuronales Netzwerk Agent
Bei der Entwicklung unseres neuronalen Netzwerks haben wir versucht, den Ansatz des Policy-Netzwerks zu verfolgen, der in der AlphaGo-Studie beschrieben wurde. Bei dieser Methode erhält das Netzwerk den kodierten Zustand des Spielbretts und sagt die Wahrscheinlichkeit voraus, dass ein menschlicher Spieler jeden der 150 verfügbaren Züge ausführt. Der Agent filtert die verbotenen Züge heraus und wählt dann die Option mit der höchsten vorhergesagten Wahrscheinlichkeit.
Anders als bei Schach oder Dame gibt es bei Azul keine strenge geometrische Beziehung zwischen den Teilen des Spielbretts und den Spielsteinbewegungen. In den "Werkstätten" werden die verfügbaren Spielsteine aufbewahrt, während die Spielsteine auch auf die "Pyramide" eines Spielers verschoben werden. Am Ende des Zuges wird ein Spielstein aus jeder abgeschlossenen Pyramidenreihe auf das "Quadrat" des Spielers verschoben, während die restlichen Steine entsorgt werden. Die Farben dieser Spielsteine sind ebenso wichtig, denn die Farbe der Spielsteine, die bereits auf den "Pyramiden" oder "Quadraten" liegen, schränkt Ihre Freiheit beim Platzieren der nachfolgenden Spielsteine ein.
Um solche komplexen Beziehungen aufzudecken, müssen unsere Eingabedaten die vollständigen Daten über den aktuellen Zustand der gemeinsamen Bereiche und des Benutzerbretts des Agenten kodieren (wie wir bereits sagten, kümmert er sich nur um sein eigenes Brett und ignoriert das des Gegners). Wir haben verschiedene Methoden zur Kodierung dieser Informationen verwendet, darunter:
- alles als eine Reihe von booleschen Flags zu kodieren, wobei numerische Werte (z.B. wie viele rote Kacheln gibt es in Workshop #2) im One-Hot-Format kodiert wurden.
- kodiert numerische Werte als Bruchteil des Maximalwerts, der Rest wird als boolesche Flags kodiert.
- Ergänzung der obigen Werte durch zusätzliche Informationen über das Spielbrett (d.h. die Belegung benachbarter Zeilen/Spalten auf dem quadratischen Spielbrett) oder mögliche Züge (d.h. ob ein bestimmter Zug zu einem Farb- oder Spaltenbonus führt)
Je nach Variante haben wir zwischen 125 und 800 Eingabevariablen verwendet. Das mag viel klingen, ist aber nicht allzu viel im Vergleich zu den 7.616 Eingaben für die Kodierung von AlphaZero-Schach oder den über 29.000 für die Kodierung von Shogi.
In Anlehnung an AlphaZero planten wir, MCTS über selbstspielende Spiele einzusetzen, um kontinuierlich neue Trainingsbeispiele zu generieren und das neuronale Netzwerk anhand dieser sich verbessernden Ergebnisse neu zu trainieren. Unsere Ergebnisse blieben jedoch ein wenig hinter den Erwartungen zurück. Wir versuchten es mit vollständig verknüpften Netzwerken, mit oder ohne Dropout-Schichten, mit unterschiedlicher Anzahl versteckter Schichten und Schichtgrößen sowie mit verschiedenen Aktivierungsfunktionen. Unsere Netzwerke, die zunächst mit einigen hunderttausend Trainingsbeispielen trainiert wurden, erreichten eine Genauigkeit von bis zu 45%.
Es scheint, dass das Hauptproblem von Azul mit der Symmetrie zusammenhängt, die oft auf dem Brett zu finden ist - in vielen Fällen gibt es mehrere gleich gute Züge. Die Zufälligkeit der MCTS-Heuristik kann zu unterschiedlichen Empfehlungen für dieselbe Ausgangsstellung führen. Und wenn neuronale Netze mit solchen widersprüchlichen Beispielen trainiert werden, werden sie leider keine Erkenntnisse gewinnen, die " solche Züge sind gleich gut" sondern vielmehr "es gibt hier keine sinnvolle Beziehung, gehen Sie weg", was die Qualität der Vorhersage verschlechtert. Wenn wir zu den Genauigkeitsmetriken TOP3 und TOP5 wechseln, liegt die Antwort des Modells derzeit bei 65 bzw. 75 Prozent.
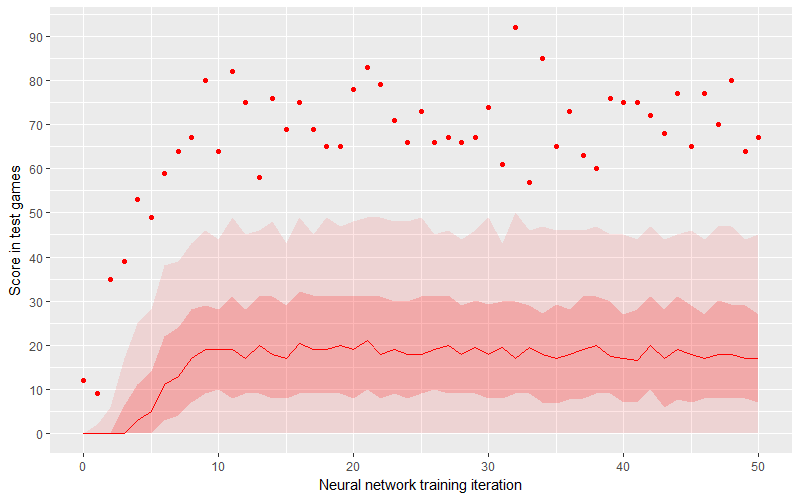
Wie gut spielt das neuronale Netzwerk also? Vielleicht wählt es Züge aus, die genauso gut sind wie die vorbildlichen, nur dass ihm aus irgendeinem Grund Trainingsbeispiele fehlen? Leider ist das nicht der Fall. Die durchschnittliche Punktzahl erreicht 20 Punkte, während die mittlere Hälfte der Punkte zwischen 10 und 30 Punkten liegt. Das bedeutet, dass ein solcher Agent nur mit den jüngsten oder unerfahrensten Spielern konkurrieren kann, denn selbst ein einfaches Training reicht aus, um ihn zu schlagen.
Ein kurzes Experiment mit der xgboost-Bibliothek ergab eine ähnliche Genauigkeit (~40%) für Baummodelle und ~30% für lineare Modelle.
Google AutoML Magie (für einen hohen Preis)
Unter den drei führenden Anbietern von Cloud Computing ist Google Cloud im Bereich des maschinellen Lernens am weitesten fortgeschritten. Schließlich ist Google immer noch das einzige Unternehmen, das Tensor Processing Units (TPUs) auf den Markt gebracht hat, eine Hardware, die speziell für das Training neuronaler Netzwerke entwickelt wurde und schneller ist als jede Graphics Processing Unit (GPUs) auf dem Markt. Wir beschlossen, es mit AutoML-Tabellen zu versuchen, die als "fire and forget"-Lösung für Logistik- und Klassifizierungsprobleme angepriesen wurden. Es stellte sich schnell heraus, dass wir für unseren Fall einen kleinen Workaround vorbereiten mussten, da AutoML nur die Klassifizierung von bis zu 40 Kategorien erlaubt. Wir erstellten daher zwei Klassifikatoren, die jeweils unterschiedliche Umzugsmerkmale ausgaben, und kombinierten die Ergebnisse dann zu einem vollständigen Vorhersagesatz.
Zum Zeitpunkt der Erstellung dieses Artikels befindet sich AutoML Tables noch im Beta-Stadium. Dank eines großzügigen Werbeangebots haben wir nichts bezahlt, um diesen Service auszuprobieren, aber die regulären Preise können ziemlich teuer sein - etwa $20 für eine Stunde ML-Training, mit zusätzlichen Gebühren für die Modellbereitstellung und die Bereitstellung von Vorhersagen.
Mit diesem einzigen PoC konnten wir leicht mehr als hundert Dollar für sieben Stunden Modelltraining ausgeben, dann noch ein paar Dutzend Dollar für die Bereitstellung der Modelle und dann noch einmal 10 Dollar für zwei Stunden Batch-Vorhersageaufträge. Bedenken Sie, dass dies alles für einen Datensatz mit einer halben Million Zeilen galt. Junge, das kann ganz schön teuer werden. Außerdem ist der einzige Trainingsparameter, den Sie ändern können, das Limit für die Trainingsstunden.
Positiv zu vermerken ist, dass Sie durch die Verwendung von AutoML schnell einen Grundwert für die Vorhersage Ihres Datensatzes erhalten. Sie werden immer noch nicht wissen, welches der "besten Modelle aus Googles Zoo" in Ihrem Fall verwendet wurde, aber Sie erhalten schnell ein produktionsreifes Modell, das Sie sofort für Online- und Batch-Vorhersagen verwenden können. In unserem Fall erzielten wir im Wesentlichen die gleichen Ergebnisse wie unser manuell erstelltes neuronales Netzwerk - über 60% Genauigkeit für einzelne Zugmerkmale (d.h. die Farbe der zu ziehenden Steine), etwa 50% für eine Kombination aus zwei Merkmalen und etwas weniger als 40% Genauigkeit für die komplette Zugvorhersage. Wir waren zunächst begeistert von der viel höheren Punktzahl, die in der AutoML-Konsole angezeigt wurde, aber es stellte sich heraus, dass es sich um eine andere Metrik mit einem ähnlichen Namen handelte.
Es ist jedoch erwähnenswert, dass Azure Cloud auch seine eigenen Dienste für automatisiertes maschinelles Lernen anbietet, während AWS stattdessen vorgefertigte Dienste für die gängigsten ML-Anwendungsfälle - Empfehlungen, Prognosen oder Bildanalysen - bewirbt. Wir haben auch Ludwig von Uber ausprobiert, ein Beispiel für ein eigenständiges AutoML-Paket, aber es hat uns keinen Durchbruch gebracht.
Zusammenfassung
Unser Hauptziel bei diesem Projekt war die Entwicklung eines KI-Agenten, der Azul spielen kann. Wir wollten einen Ansatz mit neuronalen Netzwerken ausprobieren, aber wir wollten auch testen, wie bequem es wäre, Python zu überspringen und nur einen .NET-Stack für das maschinelle Lernen zu verwenden.
Hier sind die wichtigsten Ergebnisse:
- Wir haben für Azul eine KI geschrieben, die stark ist und mit der es Spaß macht, zu spielen. Der Arbeitsansatz (Monte Carlo Tree Search) ist jedoch kein Beispiel für maschinelles Lernen im engeren Sinne, d.h. er lernt nicht aus Erfahrung und wird nicht besser, wenn Sie mehr Spiele spielen.
- .NET Core hat sich als sehr flexibel und komfortabel erwiesen, da die gesamte Einrichtung mit mehreren beweglichen Teilen mit sehr wenig Aufwand funktionierte, was bei Multiplattform-Projekten mit so geringen Abhängigkeiten wie geeigneten GPU-Treibern selten der Fall ist.
- Wir haben unsere Vermutung bestätigt, dass die Verwendung vieler komplexer Komponenten (.NET Core, R, Python, Keras, Tensorflow, eine Reihe von Bindungsbibliotheken) in einem Programmierprojekt aus Sicht der Wartung sehr riskant ist - es führt zu mehreren Fehlerquellen. Ein einziges, seltenes Problem in einer Bibliothek eines Drittanbieters kann ein kompletter Showstopper sein.
- ML-Errungenschaften von Weltrang können interessante Forschung inspirieren, selbst wenn die ursprünglichen Methoden nicht direkt auf ein bestimmtes Problem anwendbar sind
Wir gehen davon aus, dass maschinelles Lernen in Zukunft genauso zur Massenware wird wie Hardwarevirtualisierung, VPNs, automatische Ressourcenskalierung oder die Ausführung asynchroner Client-Server-Anwendungen in einem Webbrowser. Was einst eine interessante Neuheit war, dann eine teure Technologie, die einen starken Wettbewerbsvorteil bot, wird schließlich zu einem Teil des täglichen Geschäfts werden, über den niemand mehr nachdenkt. Es wird Spaß machen, diese Entwicklung zu beobachten.
Geschäftsperspektive
Maschinelles Lernen ist immer noch eine sich entwickelnde Technologie, aber die Fähigkeit, das bisher Unlösbare zu lösen, wird mit den heutigen Plattformen und Lösungen immer leichter zugänglich. Wie wir bewiesen haben, können mit dem richtigen Know-how und den richtigen Algorithmen sogar offene Probleme wie das von Azul gelöst werden.
Verfasst von
Xebia Author




Contact