Blog
Vertex-KI-Pipelines: Cache-Komplexität einfangen

Vertex AI Pipeline-Zwischenspeicherung
Die Zwischenspeicherung ist eine nützliche Funktion, die von vielen Tools bereitgestellt wird, auch von Vertex AI Pipelines. Das Zwischenspeichern bietet die Möglichkeit, das zu speichern, was später benötigt wird, um wiederholte Berechnungen zu überspringen. Das Überspringen von Berechnungen reduziert die Kosten und beschleunigt die Entwicklung. Vertex AI speichert die Ausgabe von Pipelineschritten in den Vertex ML Metadaten mithilfe eines Cache-Schlüssels. Wenn die Zwischenspeicherung für einen Pipelineschritt aktiviert ist, wird der Cache-Schlüssel verwendet, um eine frühere Pipelineschritt-Ausführung zu finden. Die Ausführung des Pipelineschritts Ihrer aktuellen Pipeline wird übersprungen und die im Cache gespeicherte Ausgabe wird verwendet. Nur Pipelines mit demselben Namen teilen sich den Cache.
Der Cache-Schlüssel ist ein eindeutiger Bezeichner, der als Kombination der folgenden Pipelineschritt-Eigenschaften definiert ist:
- Die Eingaben des Pipelineschritts: Diese Eingaben umfassen den Wert der Eingabeparameter und die ID des Eingabe-Artefakts.
- Die Ausgabe des Pipelineschritts: Diese Ausgabedefinition enthält Namen von Ausgabeparametern und Namen von Ausgabeartefakten.
- Spezifikation der Komponente:
- das Bild
- Befehle (einschließlich ihrer Reihenfolge)
- Argumente (einschließlich ihrer Reihenfolge)
- Umgebungsvariablen
Die Zwischenspeicherung kann auf Ebene der Pipeline-Aufgabe oder des Auftrags aktiviert werden. Die Zwischenspeicherung auf Pipeline-Ebene hat drei mögliche Optionen:
- True: Zwischenspeicherung für alle Pipelineschritte in diesem Lauf aktivieren
- False: Deaktivieren der Zwischenspeicherung für alle Pipelineschritte in diesem Lauf
- Keine: Verschieben Sie die Zwischenspeicherung auf Pipelineschritte in diesem Lauf
Die Zwischenspeicherung auf Stufenebene hat zwei mögliche Optionen:
- True: Zwischenspeicherung für einen Pipelineschritt aktivieren
- False: Zwischenspeicherung für einen Pipelineschritt deaktivieren
Standardmäßig ist der Pipeline-Cache auf Auftragsebene so konfiguriert, dass er auf die Step-Ebene verschoben wird. Die Zwischenspeicherung ist standardmäßig auf der Ebene der Pipeline-Steps aktiviert. Dies führt dazu, dass die Zwischenspeicherung standardmäßig für alle Steps in einer Pipeline aktiviert ist.
Beispiele
Wir können verschiedene Arten der Zwischenspeicherung verwenden. Schauen wir uns die drei Optionen gemeinsam an:
Caching aktiviert
Wir können die Zwischenspeicherung auf Pipeline-Ebene aktivieren, wie Sie im unten stehenden Skript sehen können. Wir haben den Cache auf der Ebene der Pipelineschritte deaktiviert. Der Cache wurde jedoch verwendet, weil wir ihn auf Pipeline-Job-Ebene überschrieben haben.
import google.cloud.aiplatform as aip
from kfp.v2 import compiler, dsl
@dsl.component()
def add(x: int, y: int) -> int:
return x + y
@dsl.pipeline(
name="test-pipeline"
)
def test_pipeline():
x = add(1, 2)
x.set_caching_options(False)
y = add(x.output, 3)
compiler.Compiler().compile(
pipeline_func=test_pipeline,
package_path="test.json",
)
job = aip.PipelineJob(
project=GCP_PROJECT_ID,
location=GCP_REGION,
display_name="test-pipeline",
template_path="test.json",
pipeline_root=f"{GCS_BUCKET}/pipeline",
enable_caching=True,
)
job.submit(service_account=SERVICE_ACCOUNT)
Im ersten Durchlauf sehen wir, dass beide Schritte ausgeführt werden. Dies wird durch die grünen Häkchen neben den Schritten angezeigt.
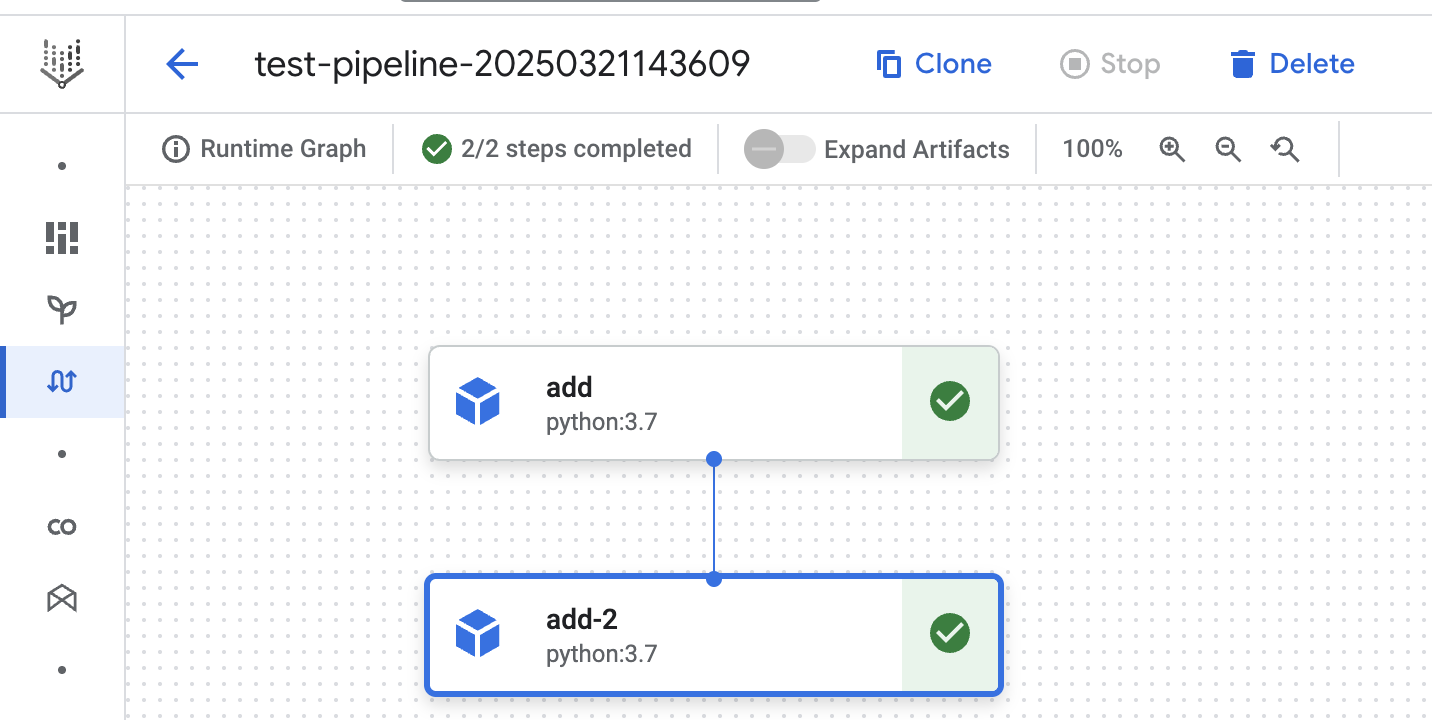
Im zweiten Durchlauf sehen wir, dass beide Schritte das gecachte Ergebnis verwenden. Sogar der Schritt (unter Verwendung der Methode
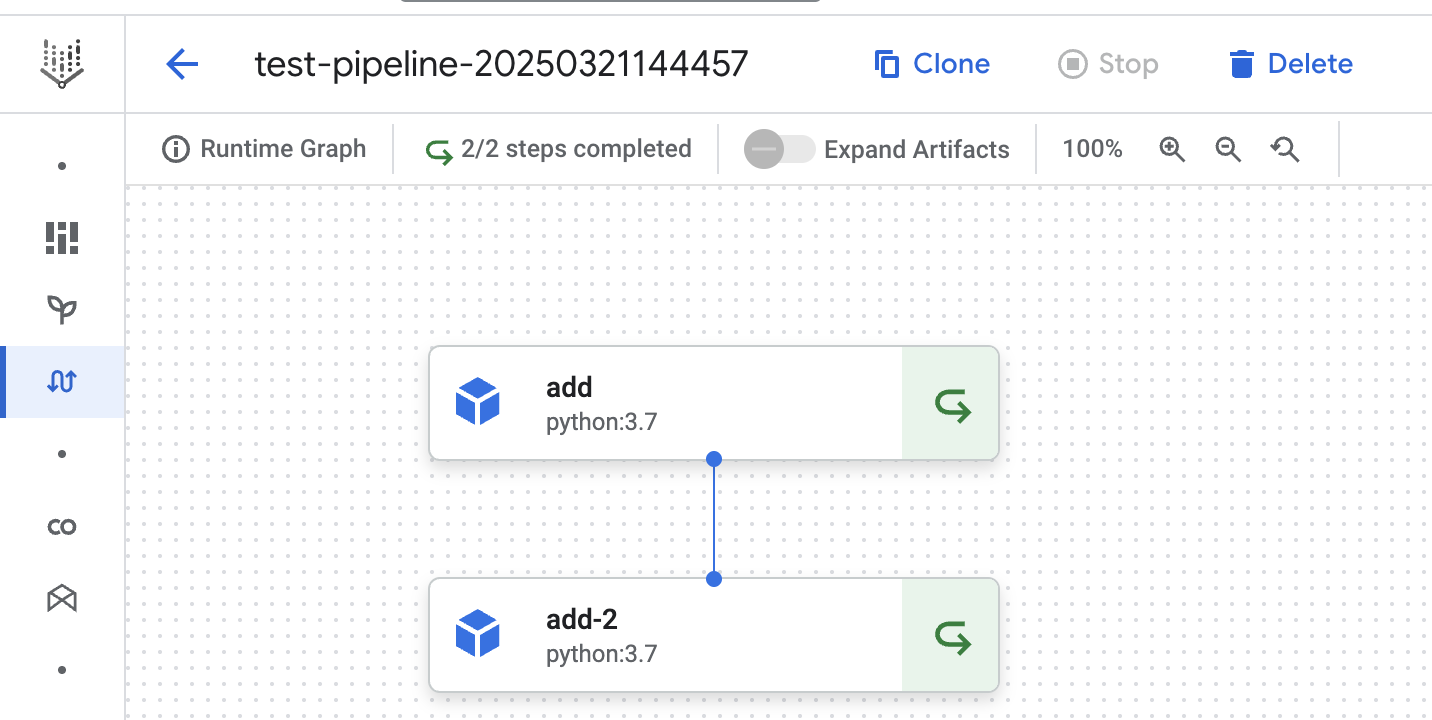
Caching deaktiviert
Wenn wir den Pipeline-Cache deaktivieren, können wir dasselbe Verhalten beobachten. Die Einstellung für die Pipeline-Job-Ebene überschreibt die Einstellung für die Step-Ebene. Sehen Sie sich das folgende Python-Skript an, in dem der Cache deaktiviert und der Cache auf Pipeline-Schrittebene aktiviert ist.
import google.cloud.aiplatform as aip
from kfp.v2 import compiler, dsl
@dsl.component()
def add(x: int, y: int) -> int:
return x + y
@dsl.pipeline(
name="test-pipeline"
)
def experimentation_pipeline():
x = add(1, 2)
x.set_caching_options(True)
y = add(x.output, 3)
compiler.Compiler().compile(
pipeline_func=experimentation_pipeline,
package_path="test.json",
)
job = aip.PipelineJob(
project=GCP_PROJECT_ID,
location=GCP_REGION,
display_name="test-pipeline",
template_path="test.json",
pipeline_root=f"{GCS_BUCKET}/pipeline",
enable_caching=False,
)
job.submit(service_account=SERVICE_ACCOUNT)
Wir können sehen, dass beide Schritte im dritten Pipeline-Lauf unten ausgeführt werden. Dies zeigt, dass der Cache für keinen der Schritte verwendet wird. Sie hätte den Schritt aus den vorherigen Durchläufen wiederverwenden können, aber wir haben Vertex AI angewiesen, dies nicht zu tun.
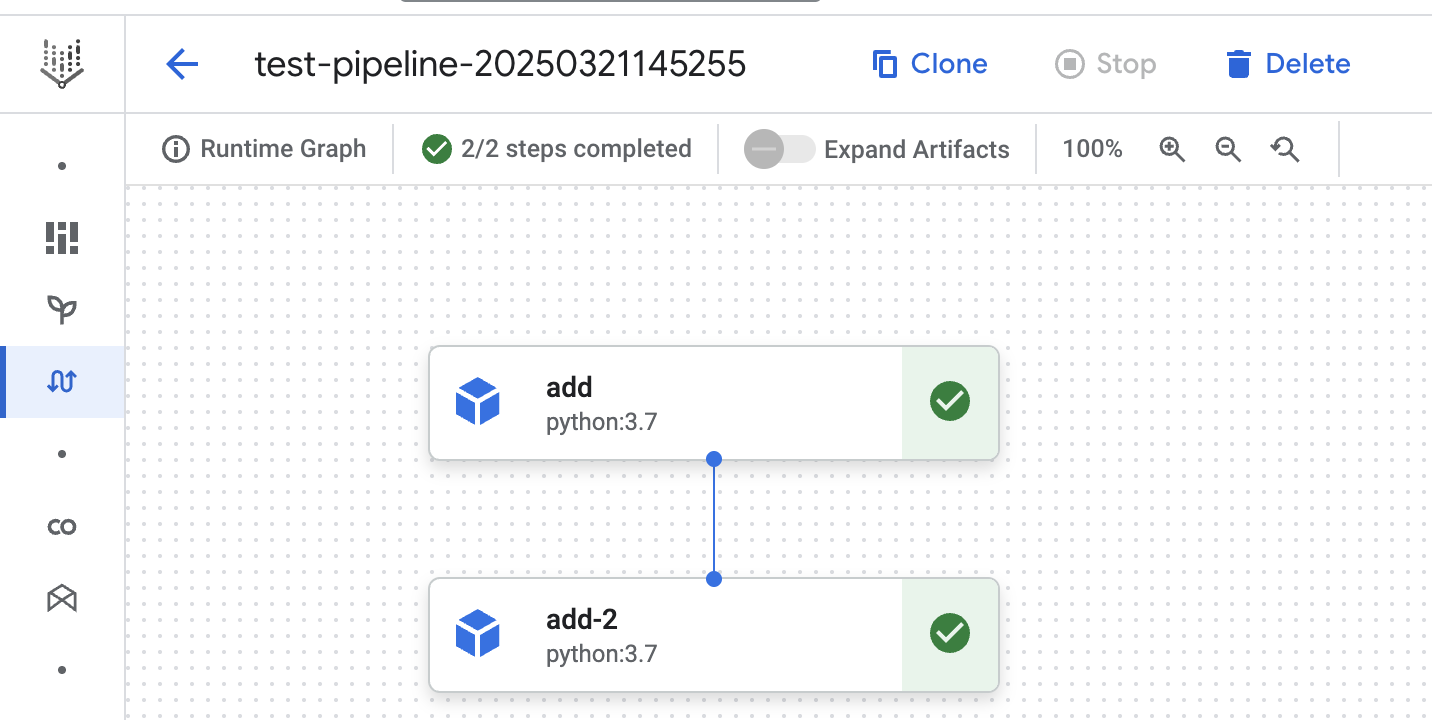
Zwischenspeicherung aufgeschoben
Zwischenspeicherung verschieben ist die dritte Option. Sie weist die Vertex AI-Pipelines (enable_caching = None) an, die Zwischenspeicherung ausdrücklich auf die Pipelineschritte zu verschieben. Vertex AI-Pipelines verschieben die Zwischenspeicherung standardmäßig auf die Pipelineschritte. Außerdem ist die Zwischenspeicherung bei Pipelineschritten
Die Zwischenspeicherung wird in dem folgenden Skript explizit aufgeschoben.
import google.cloud.aiplatform as aip
from kfp.v2 import compiler, dsl
@dsl.component()
def add(x: int, y: int) -> int:
return x + y
@dsl.pipeline(
name="test-pipeline"
)
def experimentation_pipeline():
x = add(1, 2)
x.set_caching_options(True)
y = add(x.output, 3)
compiler.Compiler().compile(
pipeline_func=experimentation_pipeline,
package_path="test.json",
)
job = aip.PipelineJob(
project=GCP_PROJECT_ID,
location=GCP_REGION,
display_name="test-pipeline",
template_path="test.json",
pipeline_root=f"{GCS_BUCKET}/pipeline",
enable_caching=None,
)
job.submit(service_account=SERVICE_ACCOUNT)
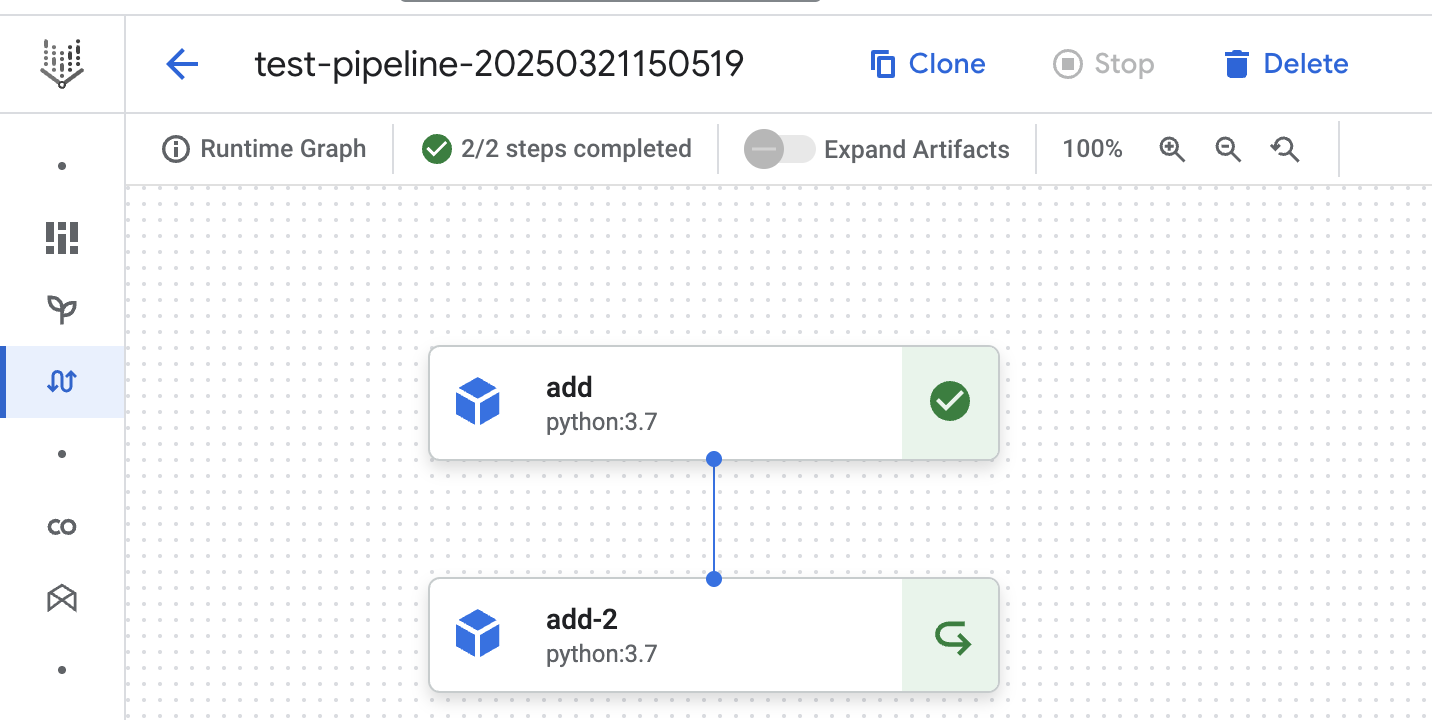
In diesem vierten Lauf können wir sehen, dass der Pipelineschritt-Cache für beide Schritte verwendet wird. Wir haben den ersten add Schritt ausdrücklich so konfiguriert, dass er den Cache verwendet. Das Ergebnis des vorherigen Pipeline-Laufs wird im ersten add Schritt verwendet. Das Gleiche gilt für den zweiten add-2 Schritt, da der Cache standardmäßig aktiviert ist.
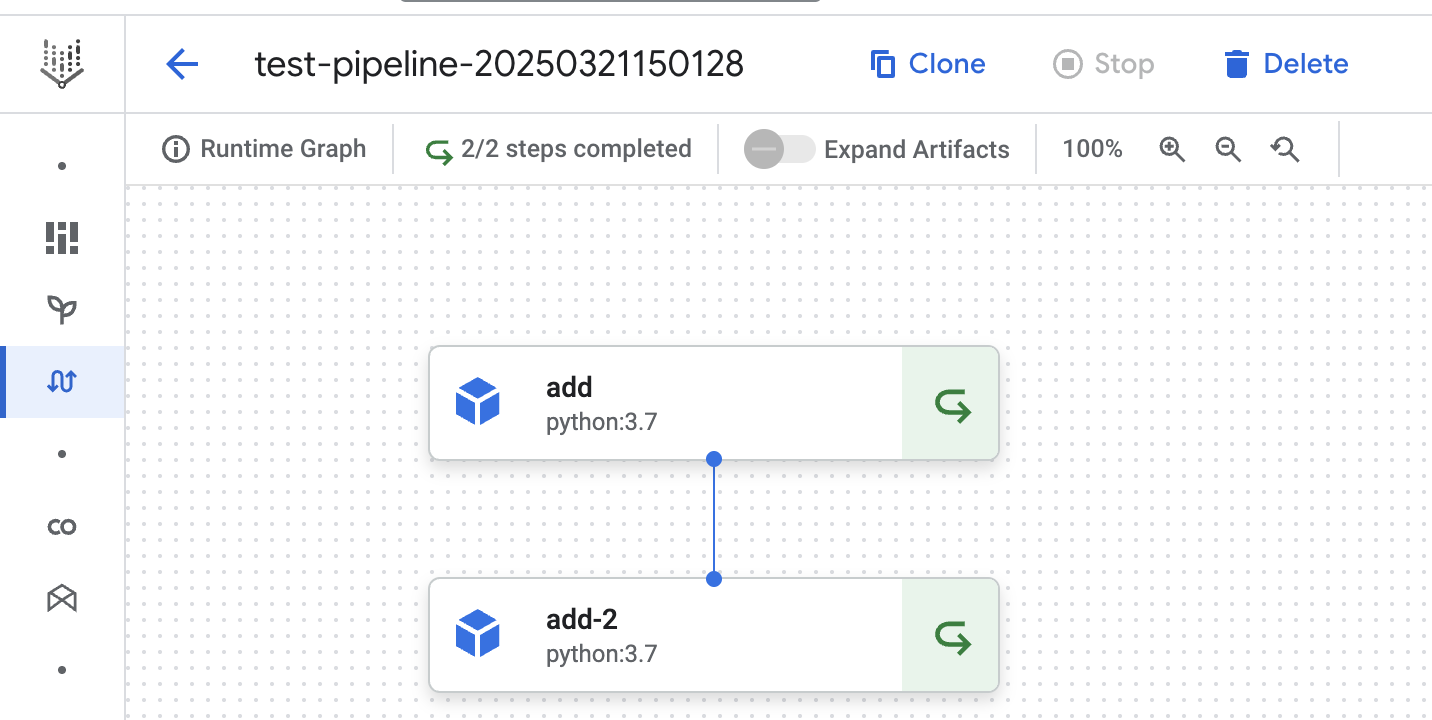
@dsl.component()
def add(x: int, y: int) -> int:
return x + y
@dsl.pipeline(
name="test-pipeline"
)
def experimentation_pipeline():
x = add(1, 2)
y = add(x.output, 3)
y.set_caching_options(False)
compiler.Compiler().compile(
pipeline_func=experimentation_pipeline,
package_path="test.json",
)
job = aip.PipelineJob(
project=GCP_PROJECT_ID,
location=GCP_REGION,
display_name="test-pipeline",
template_path="test.json",
pipeline_root=f"{GCS_BUCKET}/pipeline",
enable_caching=None,
)
job.submit(service_account=SERVICE_ACCOUNT)
In der Ausführung unten sehen wir, dass das zwischengespeicherte Ergebnis aus dem ersten Schritt verwendet wird. Der zweite Schritt der Pipeline wird ausgeführt.
Caching Vorbehalte
Wenn Sie die Zwischenspeicherung in Vertex AI Pipelines aktivieren, müssen Sie einige Einschränkungen beachten. - Vertex AI-Pipelines behaupten, dass Pipelineschritte den Cache nicht verwenden, wenn sich das Bild ändert. Dies ist richtig, wenn Sie den Bildnamen oder das Bild-Tag ändern. Dies funktioniert jedoch nicht, wenn Sie ein neues Bild mit demselben Tag pushen. Nehmen wir an, Sie verwenden das Bild test-image pushen, können Sie davon ausgehen, dass dieses neue Bild in Ihrem Pipelineschritt verwendet wird. Dies ist jedoch nicht der Fall. Vertex AI prüft die zugrunde liegende SHA256-Summe (bestimmt die Eindeutigkeit des Bildes) nicht mit dem letzten Bild mit dem Tag 1.2.3. - Vertex AI-Pipelines können keine Änderungen in externen Daten (z.B. BigQuery (BQ) Daten) erkennen. Sie kennt zwar die Datenquelle, aber nicht die Daten in dieser Quelle. Nehmen wir an, der erste Schritt in Ihrer Pipeline hängt von einem BQ-Datensatz ab und hat die Zwischenspeicherung aktiviert. Wenn Sie die Pipeline erneut ausführen, wird der erste Schritt trotz einer Änderung Ihrer Datenabhängigkeit übersprungen.
Fazit
Aus den oben genannten Gründen würde ich empfehlen, den Cache auf Pipeline-Ebene standardmäßig zu deaktivieren. Pipeline-Caching ist hilfreich, wenn Sie dieselbe Pipeline mehrmals kurz hintereinander ausführen. Nehmen wir an, Sie trainieren ein maschinelles Lernmodell mit demselben Funktionssatz und probieren verschiedene Modelle aus. In diesem Fall möchten Sie Ihre Merkmalsberechnungen wiederverwenden und nur den Trainingsschritt ausführen. Wenn Sie eine Produktionspipeline ausführen, werden Ihre Pipelineschritte bei jedem Durchlauf eindeutige Ausgaben haben. Daher würden Sie die Zwischenspeicherung in dieser Pipeline deaktivieren, um die oben genannten Vorbehalte zu vermeiden.
Banner Bild von Pixabay
Verfasst von
Roy van Santen




Contact