Blog
UV: Die technischen Geheimnisse hinter Pythons Geschwindigkeitskönig

UV: Die technischen Geheimnisse hinter Pythons Geschwindigkeitskönig
Die Paketierung von Python war lange Zeit ein Engpass für Entwickler. Langsame Installationen, komplexe Auflösung von Abhängigkeiten und fragmentierte Tools. UV, der neue Paketmanager von Astral (den Machern von Ruff), ändert dies, indem er die Paketierung von Python von Grund auf neu überdenkt.
Dieser Blog ist inspiriert von einem Vortrag, den Charlie Marsh bei Janestreet gehalten hat.
Die traditionellen Python-Paketmanager verstehen
Python-Paketmanager wie pip erfüllen drei Hauptfunktionen: 1. Sie lösen Abhängigkeiten auf (finden heraus, welche Paketversionen zusammenarbeiten) 2. Herunterladen von Paketen 3. Installieren Sie Pakete in isolierten Umgebungen.
Unter der Haube stehen diese Tools vor grundlegenden Herausforderungen, denn: - Sie sind in Python geschrieben und benötigen Python zur Ausführung, wodurch zirkuläre Abhängigkeiten entstehen. - Sie verwenden langsame Algorithmen zur Auflösung von Abhängigkeiten. - Sie führen während der Installation redundante E/A-Operationen durch. - Sie verlassen sich trotz moderner Multi-Core-Hardware auf sequenzielle Verarbeitung.
Diese Architektur führt zu der langsamen Leistung, die Python-Entwickler nur zu gut kennen. Einfache Vorgänge wie das Erstellen einer virtuellen Umgebung oder die Installation von Paketen können bei komplexen Projekten Sekunden oder sogar Minuten dauern.
UV's Architektonische Innovationen
UV überdenkt diesen gesamten Stack von Grund auf und führt mehrere wichtige Innovationen ein, die zu einer 10-100fachen Beschleunigung gegenüber herkömmlichen Tools wie Pip oder Poetry führen. Lassen Sie uns die technischen Geheimnisse hinter diesen Innovationen durchgehen und herausfinden, warum UV schneller ist als die etablierten Tools.
1. Den Python-Abhängigkeitskreislauf durchbrechen
Im Gegensatz zu herkömmlichen Python-Paketmanagern muss Python bei UV nicht vorher installiert werden. UV wird als statische Rust-Binärdatei erstellt und sucht dynamisch nach Python-Interpretern, wenn diese benötigt werden.
UV verwaltet virtuelle Umgebungen durch direkte Dateisystemoperationen, anstatt sich auf das venv-Modul von Python zu verlassen. Bei der Erstellung eines venv/-Verzeichnisses setzt UV eine clevere Optimierung ein: Anstatt Python-Binärdateien zu kopieren (was Festplattenplatz verschwenden würde), erstellt es Hardlinks. Ein Hard Link ist eine Dateisystemfunktion, bei der mehrere Verzeichniseinträge auf dieselben zugrunde liegenden Datenblöcke auf der Festplatte verweisen. Das Ergebnis ist ein Null-Kopier-Overhead.
Pyproject.toml-Dateien werden nativ in Rust geparst, Python-Unterprozesse werden nur dann verwendet, wenn dies für alte setup.py-Dateien unbedingt erforderlich ist (als Rückfallmechanismus). Der herkömmliche Ansatz von pip und anderen Tools sieht vor, dass ein Python-Interpreter gestartet wird, nur um grundlegende Projektinformationen zu lesen. Wenn Sie ein Paket installieren, benötigt das Tool zunächst Hunderte von Millisekunden, um Python zu starten, und lädt dann verschiedene Module, um Ihre pyproject.toml oder setup.py zu analysieren. UV liest und interpretiert pyproject.toml-Dateien mit Hilfe der optimierten Parsing-Bibliotheken von Rust, wodurch die Python-Startzeit entfällt und die Verarbeitung der Metadaten auf Mikrosekunden reduziert wird.
 *Zeit für das Parsen einer einfachen pyproject.toml-Datei mit numpy als einziger Abhängigkeit. UV mit Rust-Parsing-Bibliotheken gegenüber Python-Parsing.
*Zeit für das Parsen einer einfachen pyproject.toml-Datei mit numpy als einziger Abhängigkeit. UV mit Rust-Parsing-Bibliotheken gegenüber Python-Parsing.
Am wichtigsten ist jedoch, dass UV in allen Umgebungen konsistente Ergebnisse liefert. Die gleiche pyproject.toml-Datei führt zu identischen Ergebnissen, egal ob Sie sie unter Windows, Linux oder macOS ausführen.
2. SAT-Auflösung von Abhängigkeiten
Die fehlende Unterstützung von Python für mehrere Versionen macht die Auflösung von Abhängigkeiten zu einem NP-schweren Problem, bei dem die Suche nach kompatiblen Versionen exponentiell zunimmt, je komplexer die Projekte werden. Herkömmliche Tools lösen dieses Problem durch Backtracking, d.h. durch Raten und Überprüfen von Kombinationen, bis eine davon funktioniert. UV verwendet stattdessen einen Conflict-Driven Clause Learning (CDCL) SAT Solver, eine Technologie, die von Hardware-Verifikationssystemen übernommen wurde und mathematisch beweist, ob eine Lösung existiert. Es würde den Rahmen dieses Blogs sprengen, zu erklären, wie CDCL SAT-Solving genau funktioniert, aber wir werden versuchen, es auf einem hohen Niveau zu erklären.
Der Abhängigkeitsauflöser von UV modelliert das Problem mathematisch und behandelt jede mögliche Paketversion als Variable, die entweder einbezogen oder ausgeschlossen werden kann. Die Abhängigkeiten zwischen den Paketen (z.B. "dieses Paket benötigt dieses andere Paket in Version 2.0 oder höher") werden zu logischen Regeln, die alle gleichzeitig erfüllt werden müssen.
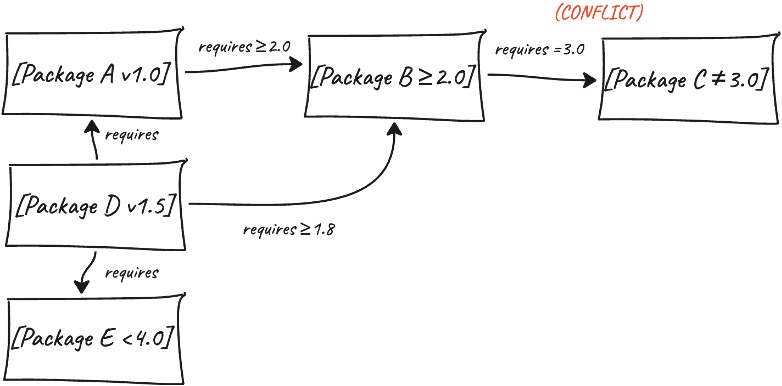
Während der Solver die möglichen Kombinationen auswertet, identifiziert er alle Konflikte, auf die er stößt, und zeichnet sie auf. Wenn er feststellt, dass bestimmte Paketversionen nicht zusammenarbeiten können, verwendet er diese Information, um sofort Millionen anderer ungültiger Kombinationen auszuschließen, ohne jede einzelne zu testen. Dieser Ansatz unterscheidet sich grundlegend von herkömmlichen Methoden, die eine Version nach der anderen testen und bei Problemen zurückgehen.
Für plattformspezifische Anforderungen verwendet UV spezielle Datenstrukturen, so genannte Algebraische Entscheidungsdiagramme. Diese verfolgen und kombinieren effizient Bedingungen wie "nur unter Linux installieren" oder "erfordert Python 3.10+", um sicherzustellen, dass die Lösung in verschiedenen Umgebungen korrekt funktioniert. Nehmen wir also das obige Diagramm und fügen wir systemspezifische Anforderungen hinzu. Wenn UV versucht, dieses Diagramm zu lösen, kann es dann je nach dem System, auf dem wir UV ausführen, bestimmte Spuren überspringen. Nehmen wir an, wir führen es auf Linux aus:
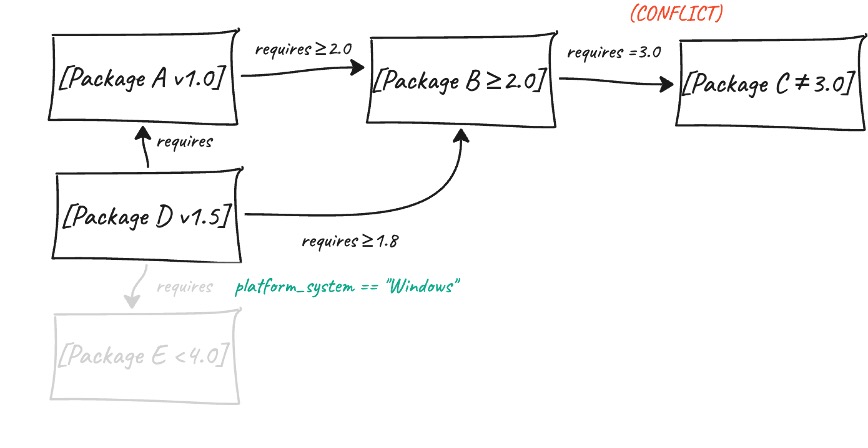
Der Solver findet entweder einen vollständigen Satz kompatibler Versionen, die alle Einschränkungen erfüllen, oder er beweist schlüssig, dass es keine solche Kombination gibt. Im Gegensatz zu anderen Tools, die nach dem Ausprobieren einer begrenzten Anzahl von Möglichkeiten aufgeben könnten.
3. Optimierungen der Installation
Sobald der Resolver von UV die Kombination der Paketversionen ermittelt hat, geht er in eine optimierte Installationsphase über, die darauf ausgelegt ist, die E/A-Vorgänge zu minimieren. Anstatt ganze Wheel-Dateien herunterzuladen, nur um ihre Metadaten zu prüfen, was bei herkömmlichen Paketmanagern häufig ineffizient ist, stellt UV HTTP-Range-Anfragen, um nur die wenigen Kilobytes an Paket-Metadaten abzurufen, die es benötigt, und überspringt so die restlichen 99% einer großen Wheel-Datei wie PyTorch. Eine HTTP-Range-Anfrage fügt der GET-Anfrage einen Header hinzu, der die benötigten Bytes angibt; RANGE bytes=START-END.
Das globale Cache-System von UV bietet die Isolationsvorteile separater Installationen ohne den Speicher-Overhead oder die Schreiblatenz von tatsächlichen Kopien. Alle extrahierten Radinhalte werden in einer optimierten Struktur unter ~/.cache/uv/wheels/ gespeichert. Bei der Installation von Paketen in eine virtuelle Umgebung werden harte Links erstellt, die auf die zwischengespeicherten Dateien verweisen und sie in der neuen Umgebung erscheinen lassen.
UV ermöglicht einen nahezu sofortigen Zugriff auf Paket-Metadaten mit O(1) -Komplexität, indem es langsame Parsing- und Konvertierungsschritte eliminiert. Im Vergleich zu herkömmlichen Methoden, bei denen ganze Datensätze von Grund auf neu verarbeitet werden, macht der Ansatz von UV die Paketinformationen sofort im perfekten Format für die Verwendung verfügbar. UV lädt Paket-Metadaten durch eine Technik namens Zero-Copy-Deserialisierung unter Verwendung von .rkyv-Dateien. Anstatt textbasierte Formate wie JSON zu parsen, was eine langsame Umwandlung von Zeichenketten in Datenstrukturen erfordert, speichert UV die Metadaten in einem speziellen Binärformat, das perfekt dazu passt, wie die Informationen im Speicher verwendet werden. Wenn UV diese Daten benötigt, teilt es dem Betriebssystem einfach mit, dass die Datei direkt in den Speicher des Programms gemappt werden soll, ohne dass ein Parsen oder eine Konvertierung erforderlich ist.
Diese Optimierungen wirken sich besonders bei großen Paketen aus. Die Installation eines Pakets wie PyTorch mit UV dauert in der Regel eher Sekunden als Minuten, da nur das heruntergeladen wird, was tatsächlich benötigt wird, und überflüssige Festplattenoperationen vermieden werden.
4. Parallele Ausführung
UV maximiert die Hardwareauslastung durch eine mehrschichtige parallele Architektur. Auf der E/A-Ebene nutzt UV die asynchrone Tokio-Laufzeitumgebung von Rust, um Netzwerk- und Festplattenoperationen ohne Blockierung zu verarbeiten. Dadurch können mehrere HTTP-Anfragen für Paket-Metadaten gleichzeitig erfolgen, während sich Downloads und Extraktion überschneiden.
Für rechenintensive Aufgaben nutzt UV den Rayon-Thread-Pool, um die Arbeit über alle verfügbaren Kerne zu parallelisieren. Die Auflösung des Abhängigkeitsgraphen, die bei anderen Paketmanagern normalerweise ein sequentieller Prozess wäre, wird zu einem parallelen Vorgang, bei dem verschiedene Zweige des Abhängigkeitsbaums gleichzeitig analysiert werden können. Auch Dateivorgänge wie die Paketinstallation profitieren von diesem Ansatz, da mehrere Dateien parallel und nicht eine nach der anderen verarbeitet werden.
Auf der Speicherebene verwendet UV sperrfreie Datenstrukturen, die den gleichzeitigen Zugriff auf den Cache ohne traditionelle Mutex-Engpässe ermöglichen. Anstatt Threads mit Mutex zu blockieren, nutzt UV atomare Zeiger mit integrierter Versionierung. Jeder CPU-Kern erhält seine eigene Kopie der Cache-Zeile. Wenn ein Thread die im Cache gespeicherten Paketdaten aktualisiert, erstellt er eine geänderte Kopie und verwendet eine einzige atomare Compare-and-Swap-Operation, um die Änderung zu veröffentlichen, während die Leser immer entweder den alten oder den neuen konsistenten Zustand sehen, ohne zu warten.
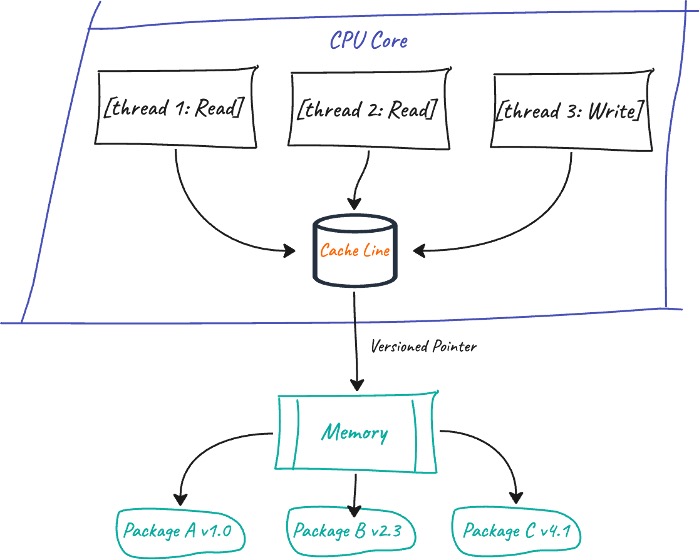
Aktualisierungen der virtuellen Umgebung erfolgen atomar, wodurch die Konsistenz gewährleistet wird und mehrere Threads sicher mit den Umgebungsdaten arbeiten können.
Arbeitsabläufe von Entwicklern verändern
Der kumulative Effekt dieser Innovationen ist mehr als nur schnellere Benchmarks. UV verändert die Art und Weise, wie Entwickler mit Python-Paketen umgehen, grundlegend:
- Virtuelle Umgebungen werden entbehrlich - die Erstellung einer solchen Umgebung dauert nur Millisekunden und ermöglicht Arbeitsabläufe wie die Isolierung von Funktionen pro Zweig.
- Die Auflösung von Abhängigkeiten ist vorhersehbar - keine "funktioniert auf meinem Rechner"-Ungereimtheiten mehr.
- CI-Pipelines beschleunigen sich - Aufträge, die früher Minuten dauerten, werden jetzt in Sekunden erledigt.
- Es wird Speicherplatz gespart - durch Hardlinks werden redundante Kopien von Paketdateien vermieden.
Durch die Beseitigung von Reibungsverlusten bei diesen grundlegenden Vorgängen können sich die Entwickler mit UV auf das Schreiben von Code konzentrieren, anstatt ihre Umgebung zu verwalten. Die Geschwindigkeitsverbesserungen sind nicht nur inkrementell - sie ermöglichen Arbeitsabläufe, die zuvor unpraktisch waren.
Haben Sie Lust, UV auszuprobieren? Die offizielle Dokumentation von Astral macht den Einstieg in die Integration von UV in Ihre Python-Projekte leicht.
Verfasst von
Xebia Author
Unsere Ideen
Weitere Blogs




Contact