Blog
Organisieren Sie keine Schnitzeljagden in Ihrer Cloud-Infrastruktur

Ein CloudWatch-Alarm wird ausgelöst. Was nun? Ich bin nicht der erste, der Ihnen sagt, dass Beobachtbarkeit für Ihre Cloud-Infrastruktur unerlässlich ist. Sie sind noch nicht fertig, wenn Sie CloudWatch Alarme eingerichtet haben!
Wer wird auf diese Alarme reagieren?
Das Beobachten einiger Metriken und das Auslösen eines Alarms, wenn ein bestimmter Schwellenwert überschritten wird, ist nur der Anfang! Sie müssen sich auch überlegen, wer handeln soll, wenn dieser Alarm ausgelöst wird. In manchen Fällen können Sie Ihre Maßnahmen automatisieren. Denken Sie zum Beispiel an eine hohe CPU-Last auf Ihren Anwendungsservern. Der CloudWatch-Alarm wird dann ausgelöst, und Sie können Ihren Cluster hochskalieren.
Diese automatischen Abhilfemaßnahmen funktionieren sehr gut für alle bekannten Probleme, die schief gehen können. Sie können sie erkennen und Abhilfemaßnahmen erstellen, die Sie auf der Grundlage dieser CloudWatch-Alarme auslösen.
Aber in manchen Fällen brauchen Sie einfach einen Menschen, der online geht und herausfindet, was passiert ist. In diesem Fall möchten Sie nicht auf eine Schnitzeljagd in Ihrem AWS-Konto gehen, um das Problem zu finden. Sie wollen einen klaren Ausgangspunkt und von dort aus eine Anleitung in die richtige Richtung.
CloudWatch Dashboards
CloudWatch-Dashboards können Sie bei Produktionsproblemen in die richtige Richtung leiten. Nehmen wir zum Beispiel an, wir haben eine SQS-Warteschlange, die Nachrichten enthält. Eine Lambda-Funktion verarbeitet diese Nachrichten. Wenn der Prozess fehlschlägt, versucht er es erneut und übergibt die Nachricht nach drei Versuchen an die Dead-Letter-Queue.
Wenn sich eine oder mehrere Nachrichten in der Dead-Letter-Warteschlange befinden, wird ein CloudWatch-Alarm ausgelöst und wir wissen, dass in unserer Anwendung etwas schief gelaufen ist.
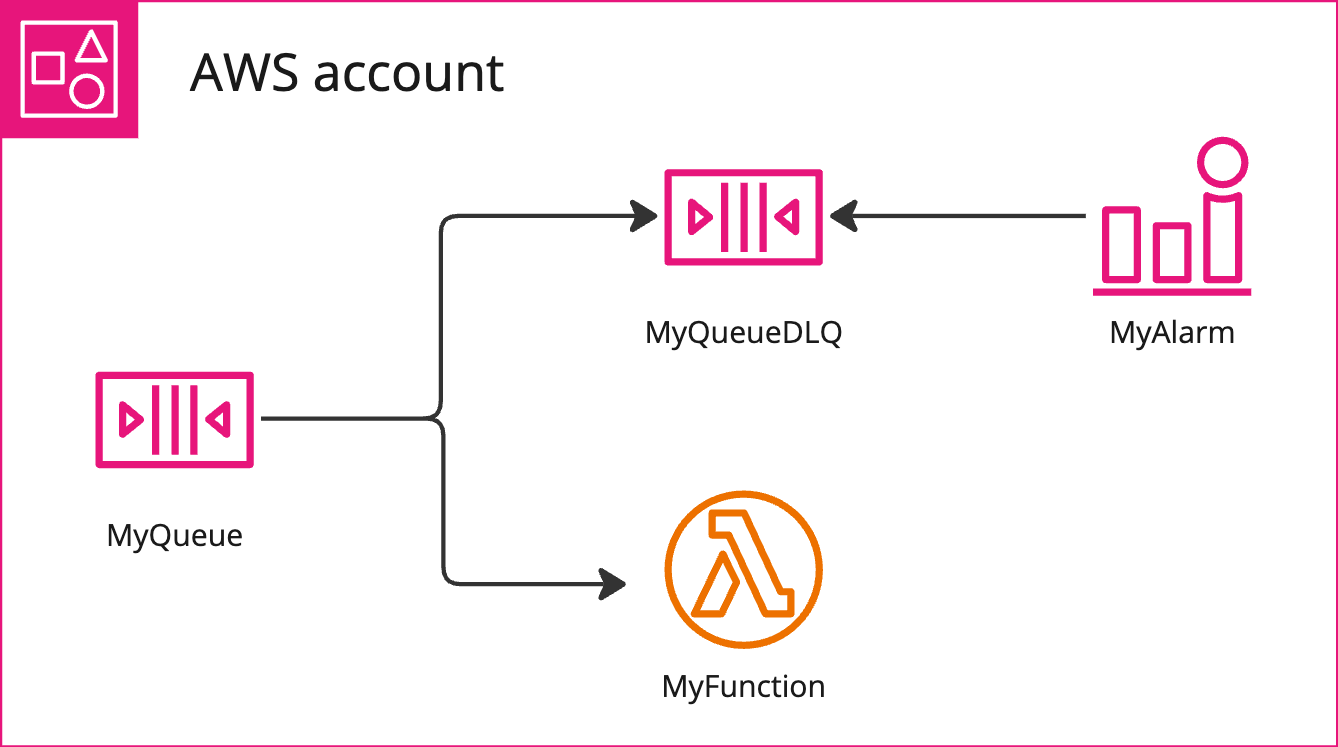
Dieser Alarm kann ein SNS-Thema auslösen, und von dort aus können Sie einen Techniker erreichen, der das Problem untersuchen kann. Ein Dashboard, das diese Komponenten anzeigt, macht es einfach, zu dem Problem zu navigieren.
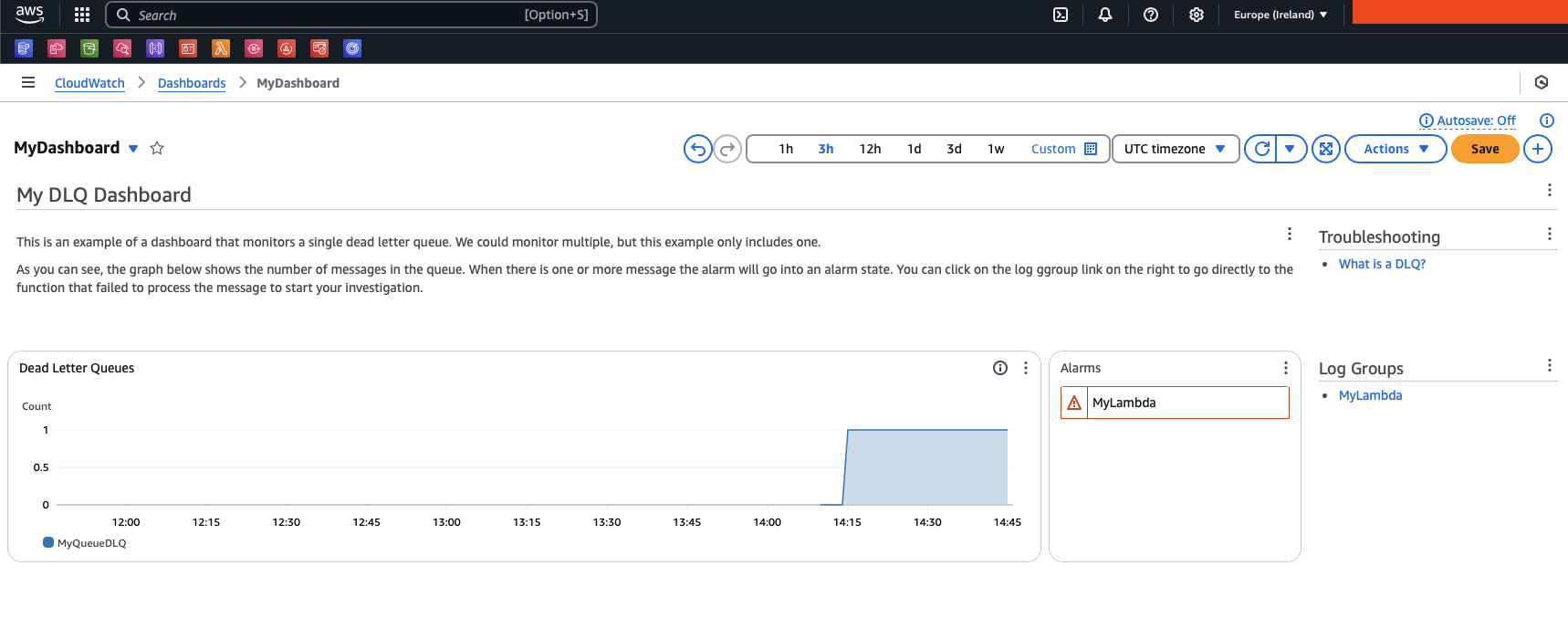
Hier sehen Sie die Dead-Letter-Warteschlangen aus unserer Anwendung. MyLambda befindet sich in einem Alarmzustand. Rechts sehen Sie einen Link, der Sie direkt zur LogGroup dieser Funktion führt.
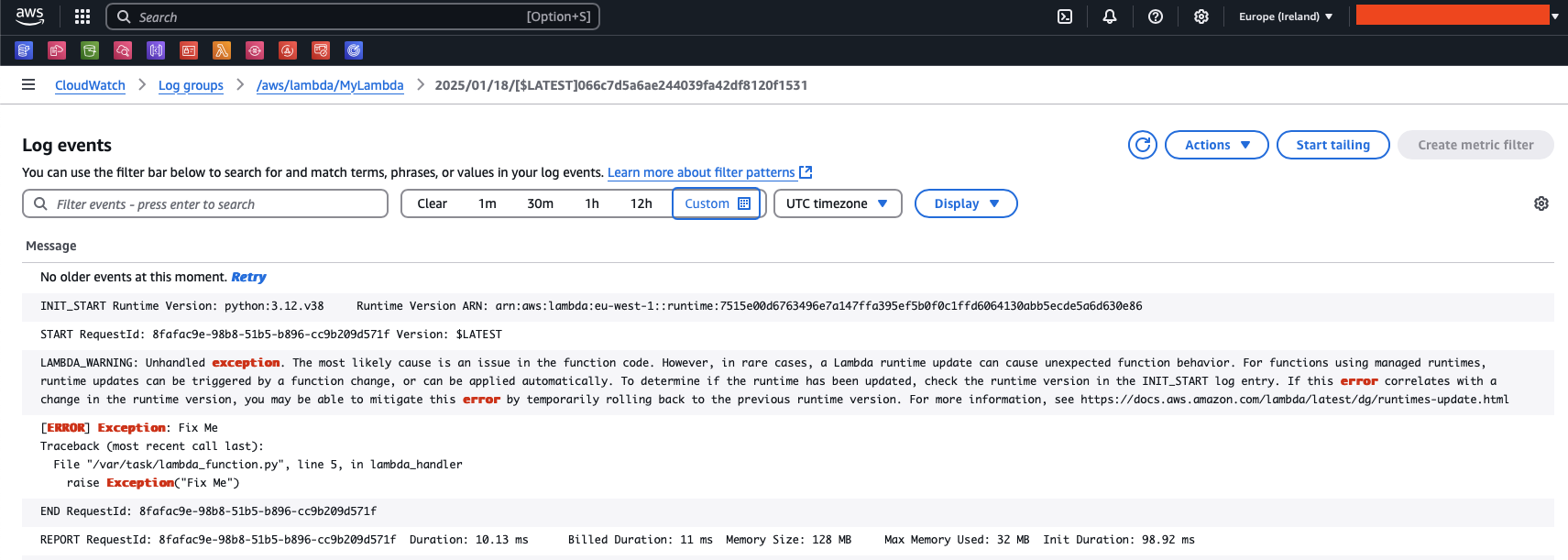
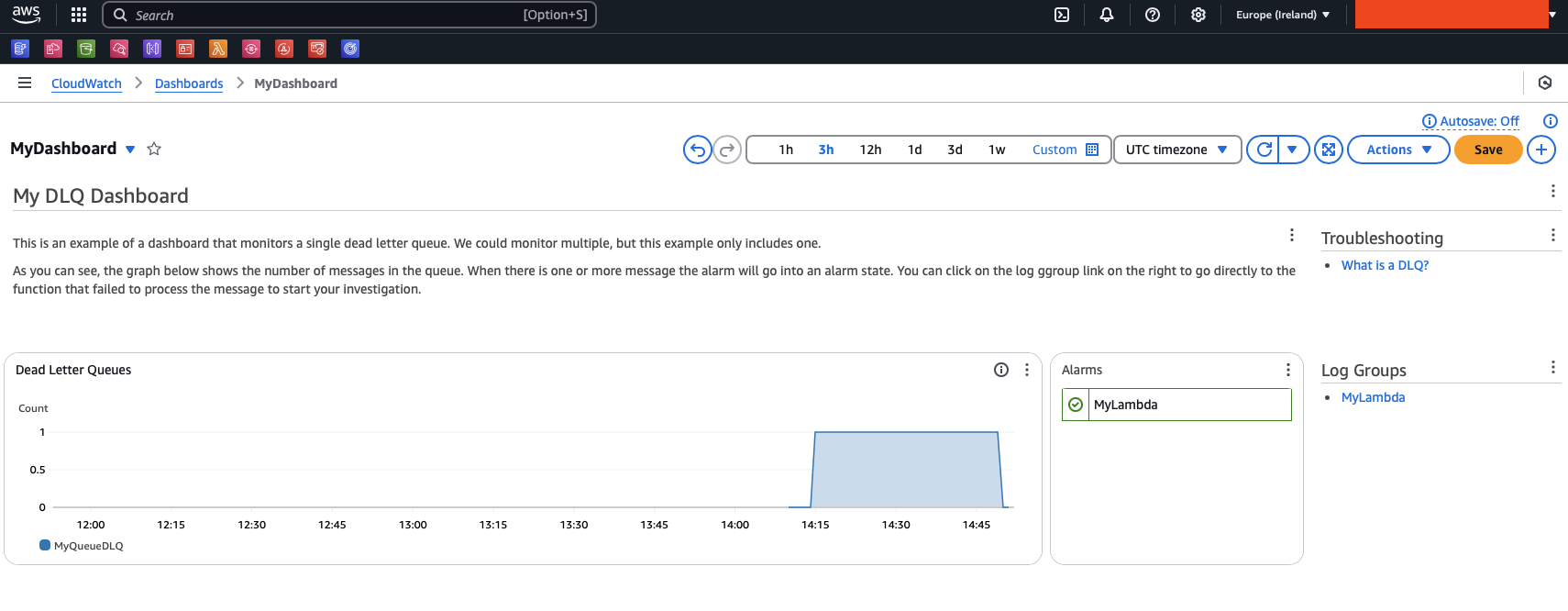
Es stellte sich heraus, dass jemand einen Code mit einer Ausnahme veröffentlicht hatte. Wir haben den Code korrigiert und damit begonnen, die Nachrichten in der Dead-Letter-Warteschlange zurück in die ursprüngliche Warteschlange zu leiten. Die Lambda-Funktion verarbeitet die Nachrichten nun wie vorgesehen und der Alarm wird wieder in einen OK-Status versetzt.
Fazit
Wenn Sie eine Cloud-Infrastruktur aufbauen, müssen Sie auch daran denken, was schief gehen kann. Planen Sie Ausfälle ein, entwickeln Sie automatische Abhilfemaßnahmen für alle bekannten Ausfälle und schalten Sie eine Person ein, wenn unbekannte Probleme auftreten. Aber seien Sie nett zu Ihrem Kollegen und schicken Sie ihn nicht auf eine Schnitzeljagd. Führen Sie ihn zu den Problemen und stellen Sie den Kontext zu den Fehlern in einem CloudWatch Dashboard dar.
Foto von Gill Heward.
Verfasst von

Joris Conijn
Joris is the AWS Practise CTO of the Xebia Cloud service line and has been working with the AWS cloud since 2009 and focussing on building event-driven architectures. While working with the cloud from (almost) the start, he has seen most of the services being launched. Joris strongly believes in automation and infrastructure as code and is open to learning new things and experimenting with them because that is the way to learn and grow.




Contact