
Die Datenverarbeitung mit Spark ist ein Bestandteil fast jeder Datenplattform. Es gibt verschiedene Möglichkeiten, Spark auszuführen und zu verwenden. Sie können Spark im lokalen, Client- oder Clustermodus ausführen, verschiedene Ressourcenmanager wählen oder sich für einen verwalteten Dienst von einem der beliebten Cloud-Anbieter entscheiden. In diesem Blogbeitrag teilen wir unsere Erkenntnisse aus dem Aufbau einer Datenplattform mit Spark unter Verwendung von Kubernetes als Ressourcenmanager.
In diesem Blog schlagen wir eine Architektur für eine Datenplattform vor, bei der Spark auf Kubernetes läuft, Komponenten mit Helm 3 erstellt werden und Argo als Workflow-Scheduler gewählt wird.
Warum Kubernetes als Ressourcenmanager für Spark
Abgesehen davon, dass es sich um eine moderne und hochentwickelte Open-Source-Technologie handelt, gibt es viele weitere Gründe, sich für Kubernetes zu entscheiden. Mit Kubernetes können Sie Cloud-native Anwendungen überall bereitstellen und sie so verwalten, wie Sie es wünschen. Durch die Verwendung von Containern unter der Haube wird Ihre Anwendung unabhängig von der Umgebung, in der Sie sie bereitstellen, konsistent. Kubernetes verwaltet den Lebenszyklus von Anwendungen und kann mit Hilfe von Paketmanagern (z.B. Helm) die Versionierung und das Abhängigkeitsmanagement übernehmen. Aber warum sollten Sie Kubernetes als Ressourcenmanager für Spark verwenden, wenn Yarn immer noch der am häufigsten verwendete ist?
Wann sollten Sie die Verwendung von Kubernetes mit Spark in Betracht ziehen:
- Sie verwenden Kubernetes bereits als Teil Ihrer Infrastruktur. Unabhängig davon, ob Sie Kubernetes vor Ort oder in der Cloud verwenden, ist es logisch, Kubernetes als Spark-Ressourcenmanager zu verwenden, anstatt einen zusätzlichen einzuführen, wenn Sie die erforderliche Infrastruktur bereits haben.
- Andere Elemente Ihrer Datenpipeline wie Warteschlange, Datenbank, Visualisierungstool, KI-Modellanwendungen sind bereits containerisiert, dann können Sie Spark ebenfalls im Container ausführen und die gesamte Pipeline mit Kubernetes verwalten.
- Sie brauchen eine bessere Ressourcenzuweisung. Kubernetes bietet Unterstützung für Quoten, Ressourcenlimits und die Trennung von Namespaces, was besonders wichtig ist, wenn Sie eine direkte Verbindung zwischen den von der Pipeline verwendeten Ressourcen und den Einnahmen aus der Nutzung dieser Pipeline herstellen möchten.
- Sie möchten eine hybride Umgebung nutzen oder suchen nach einem einfachen Weg für die Cloud-Migration. Da Kubernetes in der Cloud genauso läuft wie vor Ort, vereinfacht die Ausführung von Spark mit Kubernetes den Prozess der Migration in die Cloud, ermöglicht hybride Lösungen als Zwischenschritt und gibt Ihnen einen gewissen Spielraum für die Bewertung von Kosten und Ressourcen.
Nichts ist umsonst und der Betrieb von Spark mit Kubernetes als Ressourcenmanager bringt eine Reihe zusätzlicher Komplexitäten mit sich, die Sie berücksichtigen müssen.
Kubernetes Verwaltung
Die größte Komplexität ist die Wartung des Kubernetes-Clusters selbst. Natürlich wird es einfacher, wenn Sie verwaltete Dienste von Cloud-Anbietern nutzen, dennoch liegt ein Großteil des Supports und der Verwaltung in Ihrer Verantwortung. Eine weitere Komplexität ergibt sich aus der frühen Unterstützung von Kubernetes mit Spark (erstmals in Spark 2.4 eingeführt). Mit der Veröffentlichung von Spark 3.0 wird die Kubernetes-Implementierung ausgereifter und robuster, aber die meisten der bestehenden Architekturen sind von Spark 2.4 abhängig und werden aus verschiedenen Gründen noch eine Weile dabei bleiben (die Unterstützung von ML-Bibliotheken ist einer davon).
Benutzerakzeptanz
Die wichtigste und oft unterschätzte Komplexität ergibt sich aus der Benutzerakzeptanz. Je nach Ihrer Implementierung müssen die Benutzer ein gewisses Maß an Wissen über Docker, Kubernetes und Netzwerke mitbringen.
Wie Spark auf Kubernetes funktioniert
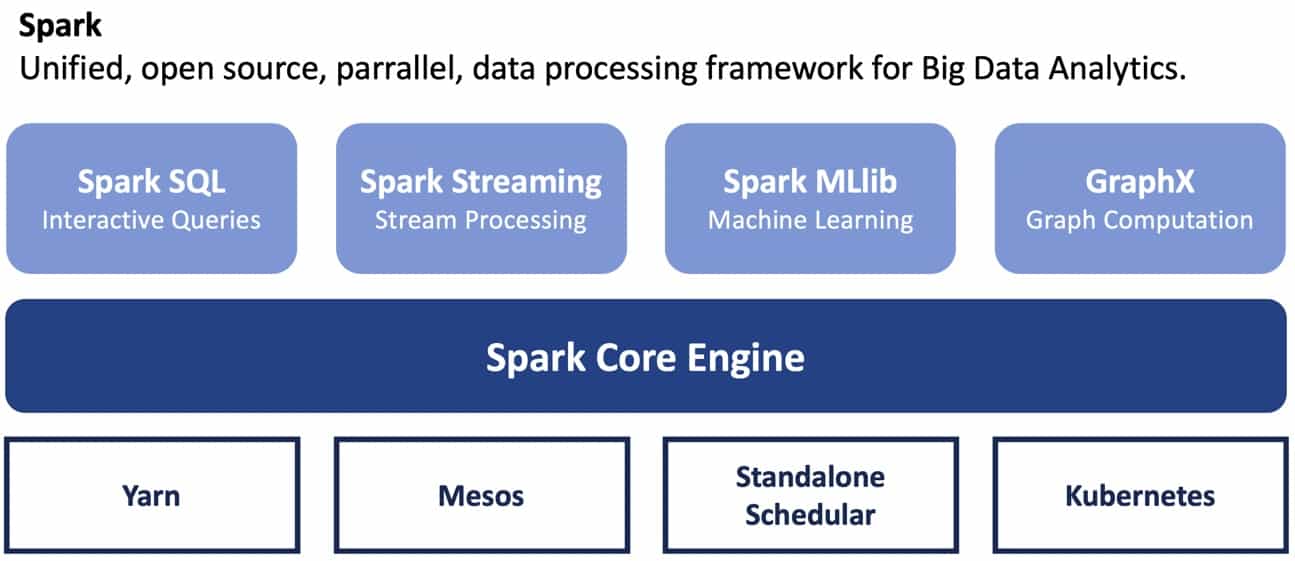
Es gibt 3 Standardmöglichkeiten, Spark-Anwendungen auf Kubernetes auszuführen:
- Client-Modus - wenn der Spark-Treiber lokal ausgeführt wird und die Executors auf Kubernetes laufen;
- Cluster-Modus - wenn sowohl der Treiber als auch die Executors auf Kubernetes laufen;
- Spark-Operator - Controller und CRDs werden auf einem Cluster installiert und erweitern die Standardfunktionen der Kubernetes-API.
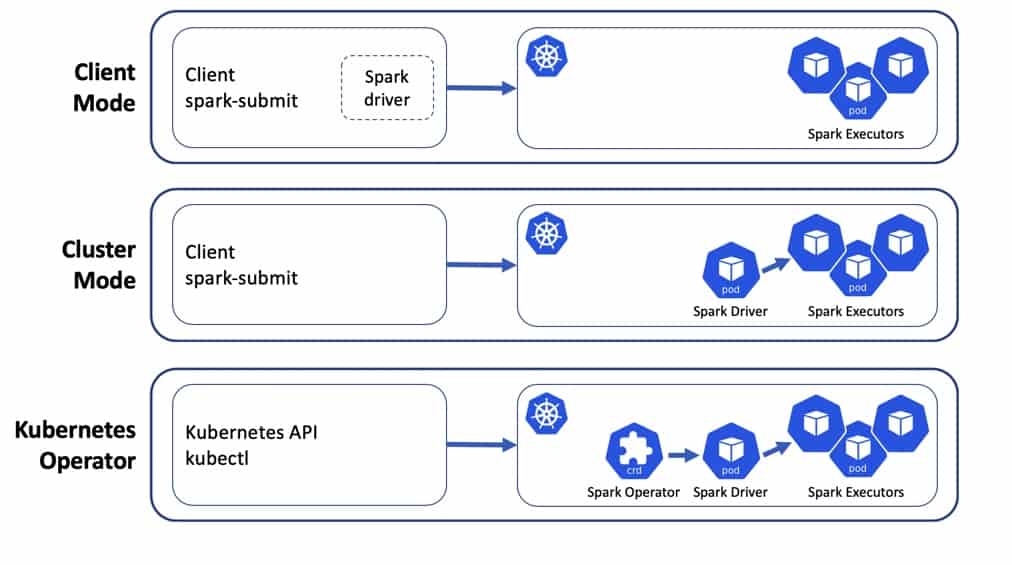
Wenn Sie spark-submit im Client-Modus ausführen, können Sie es direkt mit dem Kubernetes-Cluster verwenden. In diesem Fall sieht der Ablauf folgendermaßen aus:
- Kubernetes führt einen Pod mit einem Spark-Image aus, das über den Standardbefehl
spark-submitverfügt und den Spark-Treiber startet. - Der Treiber fordert die Kubernetes-API an, um Executors-Pods zu erzeugen, die sich mit dem Treiber verbinden und die laufende Spark-Instanz bilden, um eine eingereichte Anwendung zu verarbeiten
- Wenn die Anwendung abgeschlossen ist, werden die Executor-Pods beendet und gelöscht, der Driver-Pod verbleibt im Status "Abgeschlossen".
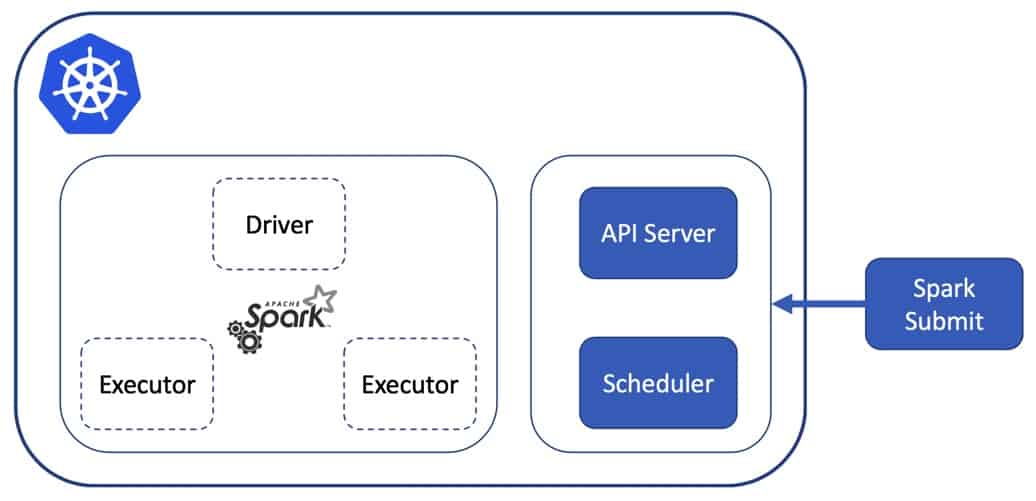
Sie können es auch anders machen, indem Sie einen Pod mit Spark ständig laufen lassen, von dem aus Sie Anwendungen einreichen können. Der Rest des Prozesses ist derselbe, aber Ihr Treiber ist in diesem Fall nur ein Prozess in dem Pod, in dem Spark installiert ist.
Technische Einrichtung
Fall 1: Starten Sie den Treiberprozess als Container-Argument.
In diesem Fall erfolgt die Initiierung einer Spark-Anwendung direkt nach dem Befehl kubectl apply -f spark-pod.yaml oder kubectl run spark-app --image myspark-image ....
apiVersion: apps/v1
kind: Pod
spec:
template:
spec:
containers:
- name: my-spark-application
image: "mycompany/spark-3.0.0:prod"
command: ['/opt/spark/bin/spark-submit my-spark-app.py']Fall 2 - Der Spark-Client-Pod läuft ständig und der Treiberprozess wird über einen ssh-Aufruf gestartet (melden Sie sich beim Pod an oder führen Sie den Befehl remote ssh aus). Die Verfügbarkeit des Pods wird durch das Deployment-Objekt garantiert.
apiVersion: apps/v1
kind: Deployment
spec:
template:
spec:
containers:
- name: my-spark-application
image: "mycompany/spark-3.0.0:prod"
command: ['/bin/bash']Dann meldet sich ein Entwickler/Analytiker/Wissenschaftler über kubectl exec -ti $SPARK_POD bash bei dem Pod an und führt den Befehl /opt/spark/bin/spark-submit my-spark-app.py innerhalb des Pods aus. Der Vorteil dieses Ansatzes ist die Möglichkeit, wie auf Ihrem eigenen Rechner zu arbeiten.
Es ist wichtig zu erwähnen, dass Spark Kubernetes Operator noch nicht offiziell veröffentlicht ist. Sie können ihn hier ausprobieren und beurteilen, ob er etwas ist, das Sie ausprobieren möchten.
Nicht nur Spark: Wo ist der Rest des Ökosystems?
Workflow-Orchestrierung
Als Entwickler oder Datenwissenschaftler verwenden Sie Spark oft im interaktiven Modus während der Erkundungs- und Testphase des Entwicklungsprozesses. Ihr Ziel ist es jedoch, Spark-Anwendungen regelmäßig auszuführen. In realen Beispielen lösen Sie kaum alle Ihre Probleme mit nur einer Spark-Anwendung. In den meisten Fällen müssen Sie Ihre Daten in mehreren Schritten verarbeiten, in ein anderes Format übertragen und in einem anderen Speicher speichern. Um diese Aktionen durchzuführen, benötigen Sie einen Workflow (WF) Orchestrator. Es gibt viele Optionen, die verwendet werden können, aber für diese Implementierung werden wir drei von ihnen in Betracht ziehen: Oozie, Airflow und Argo.
Viele ältere Systeme verwenden Oozie, um Spark-Anwendungen zu automatisieren. Oozie ist ein Workflow-Orchestrator, der gerichtete azyklische Graphen (DAGs) mit spezifischen Aktionen (z.B. Spark-Anwendungen, Apache Hive-Abfragen usw.) und Aktionssets ausführen kann. Es ist möglich, Oozie dazu zu bringen, Spark auf Kubernetes zu verwenden, aber die Ausführung von Oozie selbst auf Kubernetes erfordert eine zusätzliche Implementierung. Sie könnten diese Option in Erwägung ziehen, wenn Sie eine große Menge an Ozzie-Workflows haben und Lift-and-Shift der von Ihnen gewählte Ansatz für die Migration ist.
Airflow ist ein weiteres sehr beliebtes WF-Verwaltungstool. Es ist quelloffen, verwendet Python zur Beschreibung von WF, wird von der Community umfassend unterstützt und verfügt über eine hübsche Benutzeroberfläche. Um Ihre Spark-Anwendungen auf Kubernetes laufen zu lassen, kommunizieren Sie mit dem Kubernetes-Python-Client. Damit können Sie Anwendungen erstellen und verwalten. Airflow selbst kann innerhalb des Kubernetes-Clusters oder außerhalb ausgeführt werden, aber in diesem Fall müssen Sie eine Adresse angeben, um die API mit dem Cluster zu verbinden.
Argo Workflows ist eine Open-Source-Workflow-Engine nur für Container. Sie ist als Kubernetes Operator implementiert. Jeder WF wird als DAG dargestellt, bei dem jeder Schritt ein Container ist. Argo ist außerdem hochgradig konfigurierbar, was die Unterstützung von Kubernetes-Objekten wie Configmaps, Secrets und Volumes erheblich erleichtert. Im Gegensatz zu Airflow, wo die Hauptentwicklungssprache Python ist, verwendet Argo yaml, was gut und schlecht zugleich ist. Die Verwaltung von yamls kann problematisch sein, insbesondere bei der wachsenden Anzahl von Schritten und Abhängigkeiten für eine WF. Die Argo-Benutzeroberfläche ist nicht ausgereift genug, um einen vollständigen WF-Verwaltungslebenszyklus zu bieten. Allerdings erhalten Sie sofort die Rückverfolgbarkeit von Kubernetes, wo kubectl describe und kubectl get verfügbar sind und genügend Informationen liefern.
Es gibt auch andere WF-Orchestrierungs-Tools. Obwohl die Wahl des richtigen Tools vollständig von den Anforderungen und den verfügbaren Ressourcen abhängt, möchten wir uns aus den folgenden Gründen auf Argo Workflows konzentrieren:
- native Kubernetes-Unterstützung;
- Möglichkeit der Wiederverwendung einer bereits implementierten Spark on Kubernetes-Einrichtung;
- Yaml-Definition der WF, die den Code für die Infrastruktur konsistent macht.
Wie Sie Argo-Workflows mit Spark ausführen
Eine der vorgeschlagenen Möglichkeiten ist die Verwendung von WorkflowTemplate-Objekten. Sie ermöglichen es, eine parametrisierbare Vorlage zu registrieren und sie aus einer DAG-Schrittdefinition mit bestimmten Parametern aufzurufen.
kind: WorkflowTemplate
metadata:
name: spark-app-workflow-template
spec:
arguments:
parameters:
- name: sparkJobFilePath
templates:
- name: spark-submit
inputs:
parameters:
- name: sparkJobFilePath
container:
image: mycompany/spark-3.0.0:prod
command: [sh, -c, ]
args: [ "/opt/spark/bin/spark-submit {{ {{ }}inputs.parameters.sparkJobFilePath{{ }} }}" ]Hier ist ein Ausschnitt aus der Definition des Argo Workflows. Er besteht aus einem DAG mit einem Schritt, der auf ein WorkflowTemplate verweist und einen einzigen Parameter übergibt, nämlich den Speicherort der Spark-Anwendungsdatei.
apiVersion: argoproj.io/v1alpha1
kind: Workflow
templates:
- name: template-1
dag:
tasks:
- name: step-1
templateRef:
name: my-spark-app
template: spark-submit
arguments:
parameters:
- name: sparkJobFilePath
value: /mounted/volume/spark-apps/my-spark-app.py
Andere Komponenten
Die aktuelle Einrichtung reicht aus, um Ihre WFs mit Spark auf Kubernetes auszuführen. Wenn Sie zu einer produktionsreifen Lösung übergehen, tauchen weitere Fragen auf:
- wie man auf die Daten zugreift, insbesondere weil das Prinzip der Datenlokalität nicht mehr gilt;
- wie man den Lebenszyklus der Entwicklung implementiert, einschließlich IDEs, Code-Repositories und CI/CD-Prozess;
- wie Sie WFs zu einem bestimmten Zeitpunkt oder auf der Grundlage bestimmter externer Ereignisse planen können
In den meisten Fällen hängt der Datenzugriff stark von Ihrer aktuellen Infrastruktur ab. Der Datenzugriff kann ein Engpass in Bezug auf die Leistung sein, aber auch eine Quelle zusätzlicher Komplexität (wenn Sie beispielsweise alle Daten in einem kerberisierten HDFS-Cluster gespeichert haben, müssen Sie die Token-Propagation für alle Pods implementieren). Wenn Sie außerdem Hive als Metaspeicher verwenden, müssen Sie möglicherweise irgendwo in Ihrer Kubernetes-Umgebung einen Thrift-Server laufen haben, um Ihnen den Zugriff auf Hive zu ermöglichen.
Wenn Sie Spark auf Kubernetes im Client-Modus ausführen, müssen Sie lokal Zugriff auf den Code der Spark-Anwendung haben. In den meisten Fällen ist das kein Problem. Komplizierter wird es, wenn Sie Spark-Anwendungen im Clustermodus ausführen möchten. In diesem Fall müssen Sie Ihren Code in den Pod Ihres Treibers kopieren. Wenn es sich um eine einzelne Anwendung handelt, ist es kein Problem, den Befehl kubectl cp auszuführen, aber es ist äußerst ineffizient, wenn Sie mit einer großen Menge an Code arbeiten müssen und/oder Ihre Anwendung testen. Das Thema GitOps ist derzeit sehr beliebt. Sobald wir Argo Workflows verwenden, macht es Sinn, nach GitOps-Tools im gleichen Stack zu suchen: Argo CD.
Argo CD ist ein deklaratives GitOps Continuous Delivery Tool für Kubernetes. Die Idee hinter Argo CD ist ganz einfach: Es nimmt das Git-Repository als Quelle der Wahrheit für die Definition des Anwendungsstatus und automatisiert die Bereitstellung in der angegebenen Zielumgebung. Es kann auch Aktualisierungen von Zweigen und Tags verfolgen oder an bestimmte Commits angeheftet werden. Es kann auch ein Helm-Diagramm als Einheit für die Bereitstellung verwenden.
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: my-helm-chart
namespace: argocd
spec:
project: default
source:
path: my-helm-chart
repoURL: https://github.com/my-helm-chart
targetRevision: HEADArgo Workflows hilft Ihnen bei der Definition und Ausführung Ihrer WFs, aber was ist mit der Planung von WFs auf der Grundlage externer Ereignisse oder eines bestimmten Datums? In anderen Schedulern ist dies zwar von Haus aus vorgesehen (in Oozie ist es Teil Ihrer WF-Definition, in Airflow wird alles auf der Basis von Cron geplant, aber es gibt auch ein Konzept von Sensoren, mit dem Ihre WF auf bestimmte Ereignisse reagieren kann). Argo Workflows hat keinen Zeitplanungsmechanismus. Dafür müssen Sie die Infrastruktur von Argo Events verwenden.
Argo Events ist ein ereignisbasierter Abhängigkeitsmanager für Kubernetes, mit dem Sie mehrere Abhängigkeiten aus einer Vielzahl von Ereignisquellen wie Webhook, S3, Schedules, Streams usw. definieren und Kubernetes-Objekte nach erfolgreicher Auflösung der Ereignisabhängigkeiten auslösen können.
Ein typisches Beispiel könnte eine Kalenderereignisquelle mit einem Gateway sein:
Gateway registrieren:
apiVersion: argoproj.io/v1alpha1
kind: Gateway
metadata:
name: my-calendar-gateway
spec:
type: calendar
eventSourceRef:
name: calendar-source
processorPort: 9330
template:
metadata:
name: calendar-gateway
spec:
containers:
- name: "gateway-client" // Gateway client manages the event source for the gateway.
image: argoproj/gateway-client:v0.12
command: ["/bin/gateway-client"]
- name: "calendar-events" // Calendar event source
image: argoproj/calendar-gateway:v0.12
command: ["/bin/calendar-gateway"]
subscribers:
http:
- http://my-calendar-sensor.argo-events.svc:9300/Diese Einrichtung reagiert auf die weitere Registrierung des Kalenderereignisses und benachrichtigt die Abonnenten
apiVersion: argoproj.io/v1alpha1
kind: EventSource
metadata:
name: calendar-source
spec:
type: calendar
calendar:
- name: schedule-a
expression: "0 23 * * *"Im Allgemeinen sollten alle genannten Komponenten das Skelett Ihrer Datenplattform bilden. In produktionsreifen Beispielen kann und sollte sie mit verschiedenen Komponenten erweitert werden, um den Zweck zu erfüllen. Zu erwähnen ist der Spark History Service, der nicht Teil der Spark-Anwendung ist und als separate Anwendung installiert werden sollte. Je nach Nutzung dieser Plattform können Sie auch die Verwendung von Jupyter-Notebooks und anderen Tools in Betracht ziehen, aber das würde den Rahmen dieses Blogbeitrags sprengen.
Reduzierung der Komplexität: Helm
Um Spark auf Kubernetes auszuführen, müssen Sie nicht viele Kubernetes-Objekte implementieren. Kurz gesagt besteht Ihr Setup aus Deployment, Configuration Map, pvc, Role Binding und Service-Objekten. Aber wenn die Größe Ihres Systems durch die Einführung weiterer Komponenten wächst, wird die Menge der yaml's in Ihren Projekten schwer zu verwalten. Aus diesem Grund haben wir Helm als Paketmanager für K8s in Betracht gezogen.
Helm unterstützt Sie bei der Verwaltung von Kubernetes-Anwendungen mit Hilfe von Helm Charts, die Sie bei der Definition, Installation und Aktualisierung komplexer Kubernetes-Anwendungen unterstützen. Charts sind einfach zu erstellen, zu versionieren, zu teilen und zu veröffentlichen. Eine wichtige Funktion von Helm ist die Möglichkeit, abhängige Diagramme innerhalb Ihres Diagramms zu verwenden, was die Menge an Copy-Paste drastisch reduziert und die Wartung Ihres Projekts erleichtert.
Wie wird es eigentlich gebaut
Architektur
Hier sehen Sie einen Überblick über die Architektur. Beachten Sie, dass wir nur die wichtigsten Komponenten zeigen. Diese Architektur kann bei Bedarf um weitere Komponenten für das produktionsreife System erweitert werden. Alle Tools, die wir bei unserer Implementierung berücksichtigen, sind Open Source und werden von der Community umfassend unterstützt.
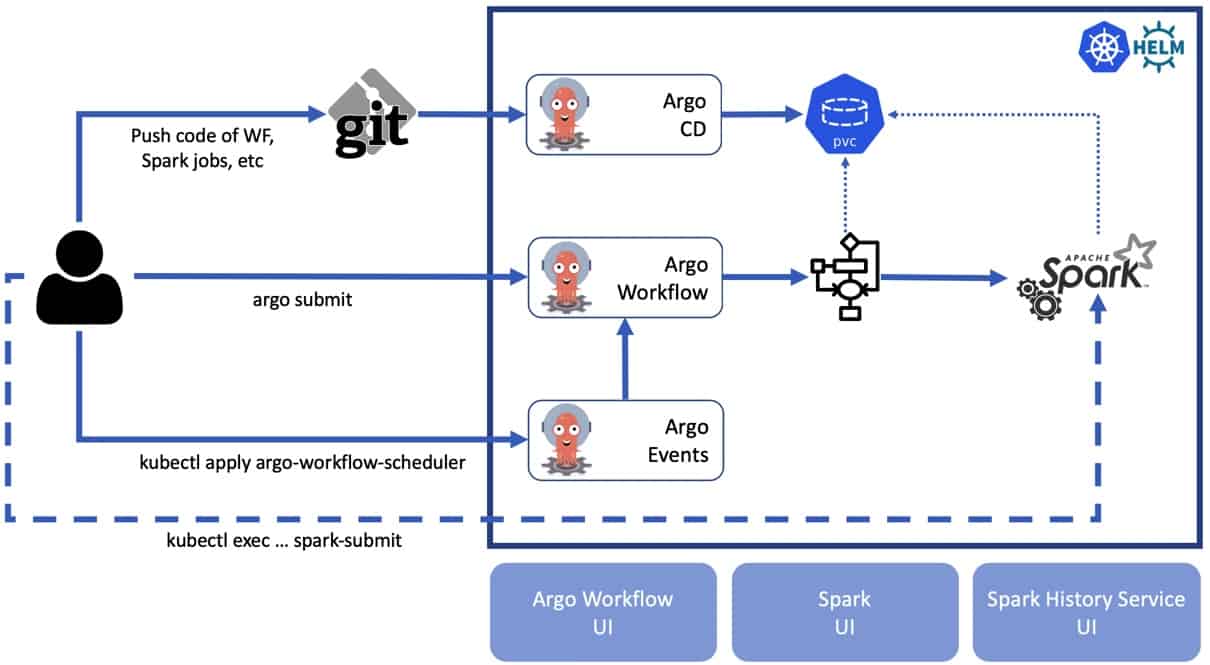
Die endgültige Architektur besteht aus den folgenden Komponenten:
- Spark 3 benutzerdefiniertes Basisbild
- Argo Workflow Controller
- Helm 3 Karten für Spark und Argo
- Integration von Datenquellen
Komponenten
Spark 3.0.0 Basis-Images
PySpark und spark-history-service tailored images sind die Grundlage des Spark-Ökosystems.
Argo Arbeitsablauf
Argo WorkflowTemplate und DAG-basierte Komponenten.
Steuerkarten
Gemeinsame
Dieses Diagramm kann die Grundlage für die Infrastruktur bilden und die meisten anderen Diagramme werden von ihm erben. Sammelt wiederverwendbare Komponenten wie:
- benannte Vorlagen
- Bände
- volumeMounts
- Etiketten
Beispiele für die gemeinsamen Diagrammkomponenten
Bände
Volume als Configmap deklarieren:
{{- define "common.spark-defaults-conf-volume" -}}
- name: spark-defaults-conf
configMap:
name: {{ include "spark-client.cm-name-spark-defaults" . }}
{{- end -}}Deklaration der allgemeinen Art und Weise, das Volume zu mounten:
{{- define "common.spark-defaults-conf-volumeMount" -}}
- name: spark-defaults-conf
mountPath: /opt/spark/conf/spark-defaults.conf
subPath: spark-defaults.conf
{{- end -}}Etiketten
Definition einer generischen Liste von Labels für eine Spark-Anwendung:
{{- define "common.labels" -}}
app: {{ include "common.name" . }}
{{- range $key, $val := .Values.appLabels.custom }}
{{ $key }}: {{ $val }}
{{- end }}
spark.instance: {{ include "common.name" . }}
helm.sh/chart: {{ include "common.chart" . }}
app.kubernetes.io/name: {{ include "common.name" . }}
app.kubernetes.io/instance: {{ .Release.Name }}
app.kubernetes.io/version: {{ .Chart.Version | quote }}
app.kubernetes.io/managed-by: {{ .Release.Service }}
{{- end -}}Spark Client
Grundlage des Spark on Kubernetes-Ökosystems, bietet Deployment, Service und Configmaps für eine einheitliche Spark-Installation. Erweitert von Common Chart.
Spark History Service
Stellt eine Verbindung zur Quelle von eventLogs (HDFS/PVC) her und zeigt Spark-Ereignisprotokolle an. Erweitert von Common chart.
Argo Arbeitsabläufe
Stellen Sie mehrere ArgoWorflow-Definitionen bereit, die sich leicht zu einem DAG kombinieren lassen. Sie können diese leicht überschreiben und Ihren eigenen Workflow über values.yaml des Diagramms bereitstellen. Erweitert das Spark Client-Diagramm und möglicherweise andere Infrastruktur-Diagramme, mit denen Sie verschiedene Workflows ausführen können.
Argo Ereignisse
Kombiniert EventSource- und Gateway-Vorlagen in einem einzigen standardisierten Diagramm.
Integration von Datenquellen
Nach unserer Erfahrung haben wir es mit HDFS und PVC zum Laufen gebracht. Aber jede beliebige Datenquelle ist möglich, da die Konfiguration der Spark-Pakete und die Konfiguration in diesem Setup sehr flexibel ist.
Abschließende Gedanken
Wir haben diese Art von Architektur bei einem unserer Kunden implementiert. Natürlich ist die tatsächliche Implementierung viel komplexer und mit vielen organisationsspezifischen Details gespickt. Bei der Implementierung dieser Architektur ist es wichtig, sich vor Augen zu halten, dass nicht alle Komplexität auf technische Herausforderungen zurückzuführen ist.
Was die technische Seite betrifft, so müssen Sie bedenken, dass viele der Tools, die wir in dieser vorgeschlagenen Architektur verwenden, noch sehr aktiv entwickelt werden. Das bedeutet, dass viele Bugs und Funktionswünsche implementiert werden, aber andererseits ist es schwierig, eine stabile Version des Systems mit so vielen Komponenten zu haben. Ein weiterer wichtiger Punkt ist die Ressourcenzuweisung. Obwohl Kubernetes ein Kernstück Ihres Berechnungssystems bilden kann, ist es nicht speziell für die Herausforderungen von Big Data implementiert. Es gibt Projekte, die einen eher "Big Data"-orientierten Ansatz für die Verwaltung von Ressourcen mit Kubernetes einführen.
Benutzer vs. Betreuer
Ihre Plattform sollte einfach zu pflegen, zu entwickeln und zu erweitern sein, um neue Anwendungsfälle zu unterstützen. Obwohl wir Helm verwendet haben, um die Komplexität der Kubernetes-Deklarationen zu verbergen, sind die Helm-Diagramme selbst immer noch recht komplex. Außerdem sind eine Menge zusätzlicher Konfigurationen/Berechtigungen erforderlich, um alle Komponenten synchron zu halten.
Eine weitere wichtige Frage ist die Benutzerakzeptanz. Um diese Plattform vollständig bedienen zu können, müssen Sie zumindest über Grundkenntnisse in Kubernetes, Helm, Docker und Netzwerken verfügen. Wenn Sie das vermeiden wollen, werden Sie wahrscheinlich versuchen, eine weitere Abstraktionsebene in diese Plattform einzubringen, indem Sie eine Benutzeroberfläche erstellen, die die darunter liegende Kubernetes-API aufruft.
Ungeachtet aller Herausforderungen, auf die Sie stoßen könnten, bringt die vorgeschlagene Architektur eine Menge Vorteile mit sich, insbesondere wenn Sie eine Cloud-native Datenplattform mit allen Vorteilen von Kubernetes darunter wünschen.




Contact