Blog
Vereinfachen Sie Ihre Workflow-Bereitstellung mit Databricks Asset Bundles: Teil II

Im letzten Blogbeitrag haben wir Databricks Asset Bundles als einheitliche Lösung für die Verwaltung und Bereitstellung von Daten-Workflows auf Databricks vorgestellt. Wir haben erläutert, wie Bundles es Benutzern ermöglichen, Komponenten - wie Notebooks, Bibliotheken und Konfigurationsdateien - in einer einzigen und vereinfachten Befehlszeilenschnittstelle zu konsolidieren, um Ressourcen über den Lebenszyklus des Bundles hinweg nahtlos zu validieren, bereitzustellen und zu löschen.
Nachdem wir nun die Funktionsweise von DABs im Allgemeinen verstanden haben, wollen wir uns nun den praktischen Aspekten zuwenden und erfahren, wie wir das Tool nutzen können, um automatisierte Bereitstellungen in mehreren Umgebungen zu erleichtern, benutzerdefinierte Variablen für unser Projekt zu verwenden, persönliche Rechenleistung hinzuzufügen, um die Bereitstellungstests zu beschleunigen, und zu lernen, wie man mit verschiedenen Arten von Databricks-Ressourcen interagiert und diese bereitstellt, z. B. schemas auf Unity Catalog.
Isolierung des Einsatzes: Umgang mit mehreren Benutzern und Umgebungen
Während der Entwicklung einer neuen Datenpipeline ist es üblich, Tests durchzuführen, um zu prüfen, ob alle Abhängigkeiten korrekt funktionieren. Je nachdem, wie Ihre Datenplattform eingerichtet wurde, verfügen Sie als Dateningenieur/Wissenschaftler möglicherweise über eine Entwicklungsumgebung, um Ihre Pipeline zu testen, und eine Akzeptanz-/Produktionsumgebung, um die Daten bereitzustellen und für die Endbenutzer verfügbar zu machen. Die Verwaltung der Bereitstellung in mehreren Umgebungen kann mühsam sein, insbesondere wenn mehrere Benutzer denselben Arbeitsbereich für die Entwicklung verwenden. Die Wahrscheinlichkeit, dass eine Person die Arbeit der anderen überschreibt oder die Daten in der falschen Umgebung bereitstellt, steigt. Im vorigen Beitrag haben wir die Isolierung der Bereitstellung etwas gestreift. Wir haben gesehen, wie Bundles dies auf natürliche Weise erreicht, indem es alle Ressourcen Ihres Projekts in einem separaten Ordner bereitstellt, der Ihrem Benutzernamen zugeordnet ist. Lassen Sie uns nun unsere YAML-Zielkonfiguration erweitern, um mehrere Umgebungen hinzuzufügen, d.h. über die Entwicklungsumgebung hinaus wollen wir Staging- und Produktionsziele hinzufügen.
Bis jetzt haben wir unsere Zielumgebung wie unten gezeigt konfiguriert.
targets:
dev:
default: true
mode: development
workspace:
host: https://adb-xxxxxxxxxxxxxx.xx.azuredatabricks.net/
Hier gibt es zwei wichtige Konfigurationen:
Erstens bedeutet der Parameter default, dass jedes Mal, wenn Sie Bundle-Befehle ausführen, standardmäßig diese Umgebung und folglich auch deren Konfigurationen verwendet werden. Wir können also einfach den Befehl databricks bundle deploy ausführen, um auf dem Ziel dev zu verteilen.
Zweitens gibt mode: development einige voreingestellte Konfigurationen an, um anzuzeigen, dass es sich um ein Entwicklungsziel handelt. Schauen wir uns ein Beispiel an.
Wenn Sie den Befehl deploy ausführen:
# -> deploy command's output
# Name: ingestion_demo
# Target: dev
# Workspace:
# Host: https://adb-xxxxxxxxxxxxxx.xx.azuredatabricks.net/
# User: victor.deoliveira@xebia.com
# Path: /Workspace/Users/victor.deoliveira@xebia.com/.bundle/ingestion_demo/dev
#
# Validation OK!
Sie können sehen, dass die Isolierung stattfindet, da alle Artefakte unseres Bundles unter dem Namen meines Arbeitsbereichsordners bereitgestellt werden. In der Benutzeroberfläche können Sie den verteilten Auftrag überprüfen:
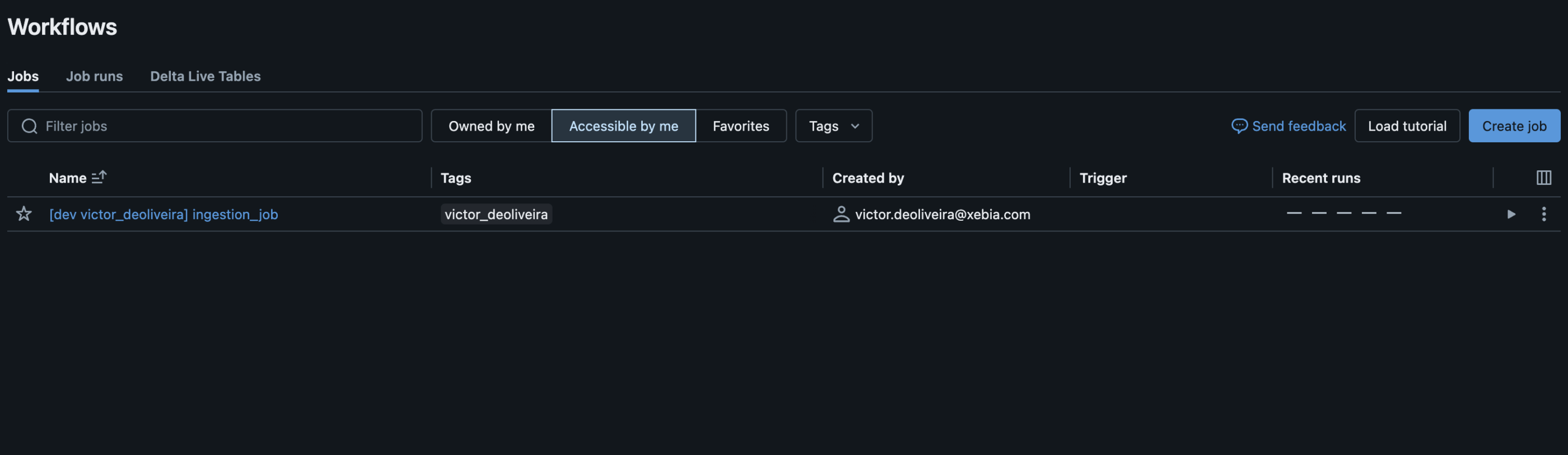
Hier können Sie sehen, dass mein Auftrag mit einem Suffix für das Ziel und den Benutzernamen bereitgestellt wurde. Dies ist eine der vorgegebenen Voreinstellungen im Modus Entwicklung. Standardmäßig werden auch alle Zeitpläne und Auslöser für die bereitgestellten Ressourcen angehalten und die Delta Live Tables-Pipeline als development: true eingestellt, neben anderen Funktionen. Die vollständige Liste finden Sie hier.
Diese einfache Funktion ist ungeheuer nützlich. In einem früheren Projekt mussten wir diese Voreinstellungen in unserem benutzerdefinierten Bereitstellungscode implementieren, aber jetzt geschieht dies direkt aus der Box heraus. Mehrere Teammitglieder können im selben Arbeitsbereich zusammenarbeiten, ohne Gefahr zu laufen, die Arbeit der anderen zu löschen.
Nehmen wir an, Sie testen auch Ihre CI/CD-Pipeline (wir werden dieses Thema in Zukunft behandeln) und möchten sie in einem Staging/Acceptance-Arbeitsbereich bereitstellen, um sicherzustellen, dass alles wie erwartet funktioniert. Sie können die Bundle-Konfiguration einfach ergänzen:
targets:
dev:
default: true
mode: development
workspace:
host: https://<development-workspace-id>.azuredatabricks.net/
staging:
workspace:
host: https://<staging-workspace-id>.azuredatabricks.net/
Da staging nicht Ihr Standardziel ist, müssen Sie es direkt in Ihrem Bereitstellungsbefehl angeben. Sie können zum Beispiel Ihre CI/CD-Pipeline so konfigurieren, dass sie ausgeführt wird:
databricks bundle deploy --target staging
Und wenn wir in einem Szenario sind, in dem wir nur eine Arbeitsbereich-Umgebung haben? Ganz einfach, Sie können eine Vorgabendefinition verwenden, wie anhand eines Beispiels besser erklärt wird:
targets:
dev:
default: true
mode: development
workspace:
host: https://<development-workspace-id>.azuredatabricks.net/
staging:
presets:
name_prefix: "stg_"
workspace:
host: https://<development-workspace-id>.azuredatabricks.net/
Dies führt zu folgendem Ergebnis:
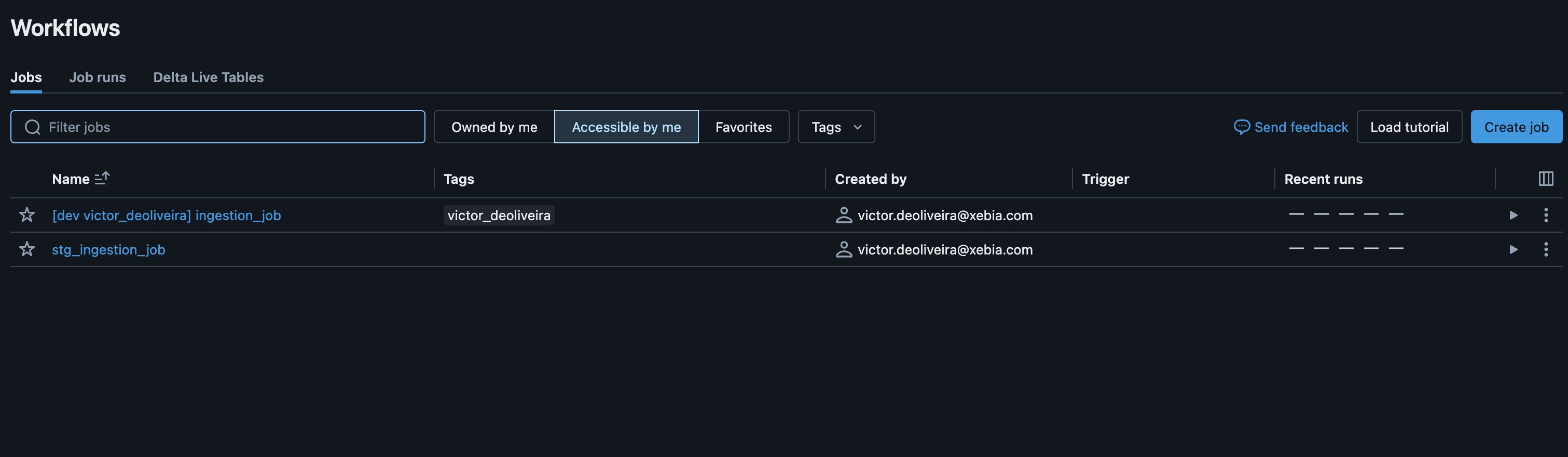
sehen, haben alle Ressourcen, die bereitgestellt werden, ein Präfix "stg_" zur Unterscheidung zwischen den Zielbereitstellungen. Dies kann äußerst nützlich sein, wenn Sie keine zusätzlichen Kosten für die Einrichtung eines speziellen Arbeitsbereichs und einer Infrastruktur für eine Staging-Umgebung haben möchten. Sie können einen einzigen Arbeitsbereich verwenden, der als Entwicklungs- und Staging-Umgebung dient.
Neben name_prefix haben Voreinstellungen weitere konfigurierbare Werte. Hilfreich ist trigger_pause_status, wo Sie die Werte PAUSED oder UNPAUSED definieren können. Sie können dies zu Ihrer Staging-Umgebung hinzufügen, um Aufträge mit dem Trigger-Status UNPAUSED zu verteilen, damit sie nicht nach einem Zeitplan ausgeführt werden und nur Ihr Produktionsziel für die Ausführung geplanter Aufträge übrig bleibt. Zum Beispiel:
targets:
dev:
default: true
mode: development
workspace:
host: https://<development-workspace-id>.azuredatabricks.net/
staging:
presets:
name_prefix: "stg_"
trigger_pause_status: PAUSED
workspace:
host: https://<development-workspace-id>.azuredatabricks.net/
Bei Xebia Data haben wir diese Konfiguration in einem kürzlich durchgeführten Projekt eingesetzt, bei dem wir Staging als Testumgebung verwenden und Aufträge nicht nach Plan, sondern nur in der Produktion ausführen müssen. Dadurch werden unnötige Cloud-Kosten vermieden.
Denken Sie daran, dass wir die Staging-Umgebung auch so konfigurieren könnten, dass sie mode: development verwendet. Dadurch würde PAUSED automatisch auf alle bereitgestellten Ressourcen angewendet. In diesem Szenario möchten wir jedoch nur diese Voreinstellung ändern und nicht alle Voreinstellungen im Entwicklungsmodus verwenden.
Schließlich haben Sie auch eine mode: production.
targets:
dev:
default: true
mode: development
workspace:
host: https://<development-workspace-id>.azuredatabricks.net/
staging:
presets:
name_prefix: "stg_"
trigger_pause_status: PAUSED
workspace:
host: https://<development-workspace-id>.azuredatabricks.net/
production:
mode: production
workspace:
host: https://<production-workspace-id>.azuredatabricks.net/
Der Produktionsmodus enthält auch einige Konfigurationen, die Sie sofort verwenden können. Es wird überprüft, ob alle Delta Live Tables, die bereitgestellt werden, als development: false markiert sind. Außerdem wird überprüft, ob die aktuelle Verzweigung die Hauptverzweigung ist (oder der Name der Verzweigung, die Sie für die Produktion verwenden möchten).
Sie können Ihre Ressourcen in der Produktion einsetzen, indem Sie sie ausführen:
databricks bundle deploy --target production
Es ist wichtig anzumerken, dass Sie diesen Befehl unter Ihrem Benutzernamen ausführen und ihn bei Bedarf in der Produktion einsetzen können. Wir empfehlen jedoch dringend, dass Sie Ihre Pipelines über eine CI/CD-Anwendung wie Github Actions oder Azure DevOps in Nicht-Entwicklungsumgebungen einsetzen.
Verschwenden Sie keine Zeit mehr mit dem Warten auf den Start Ihres Job-Clusters
Databricks rät davon ab, Allzweck-Compute für Aufträge zu verwenden, insbesondere wenn Sie Ihre Aufträge in Produktionsumgebungen einsetzen. Im vorigen Beitrag hatten wir unsere Auftragsressourcen wie folgt definiert:
resources:
jobs:
...
new_cluster:
node_type_id: Standard_DS3_v2
num_workers: 1
spark_version: 15.3.x-cpu-ml-scala2.12
Die obige Definition bedeutet, dass jedes Mal, wenn wir diesen Auftrag auslösen, ein neuer Cluster initialisiert wird, was der empfohlene Ansatz ist. Wir möchten jedoch unsere Workflow-Logik während der Entwicklung schneller testen, und Wartezeiten sind frustrierend. Nehmen wir an, wir haben einen größeren Cluster für die Entwicklung zur Verfügung oder einfach einen aktiven, den Sie direkt für die Ausführung Ihres Auftrags verwenden können. Mit Bundles können Sie einen benutzerdefinierten Cluster für die Ausführung Ihrer Pipelines konfigurieren. In der YAML-Datei können wir ein Feld cluster_id zu unserem dev Ziel hinzufügen, wie zum Beispiel:
targets:
dev:
default: true
mode: development
workspace:
host: https://<development-workspace-id>.azuredatabricks.net/
cluster_id: <your-cluster-id>
staging:
presets:
name_prefix: "stg_"
workspace:
host: https://<staging-workspace>.azuredatabricks.net/
Tipp: Sie können Ihre cluster_id für Ihren Compute in der Benutzeroberfläche abrufen. Klicken Sie einfach auf Ihren Cluster, suchen Sie nach den drei Punkten oben rechts, und sehen Sie die JSON-Definition
Führen Sie dann den Befehl deploy aus:
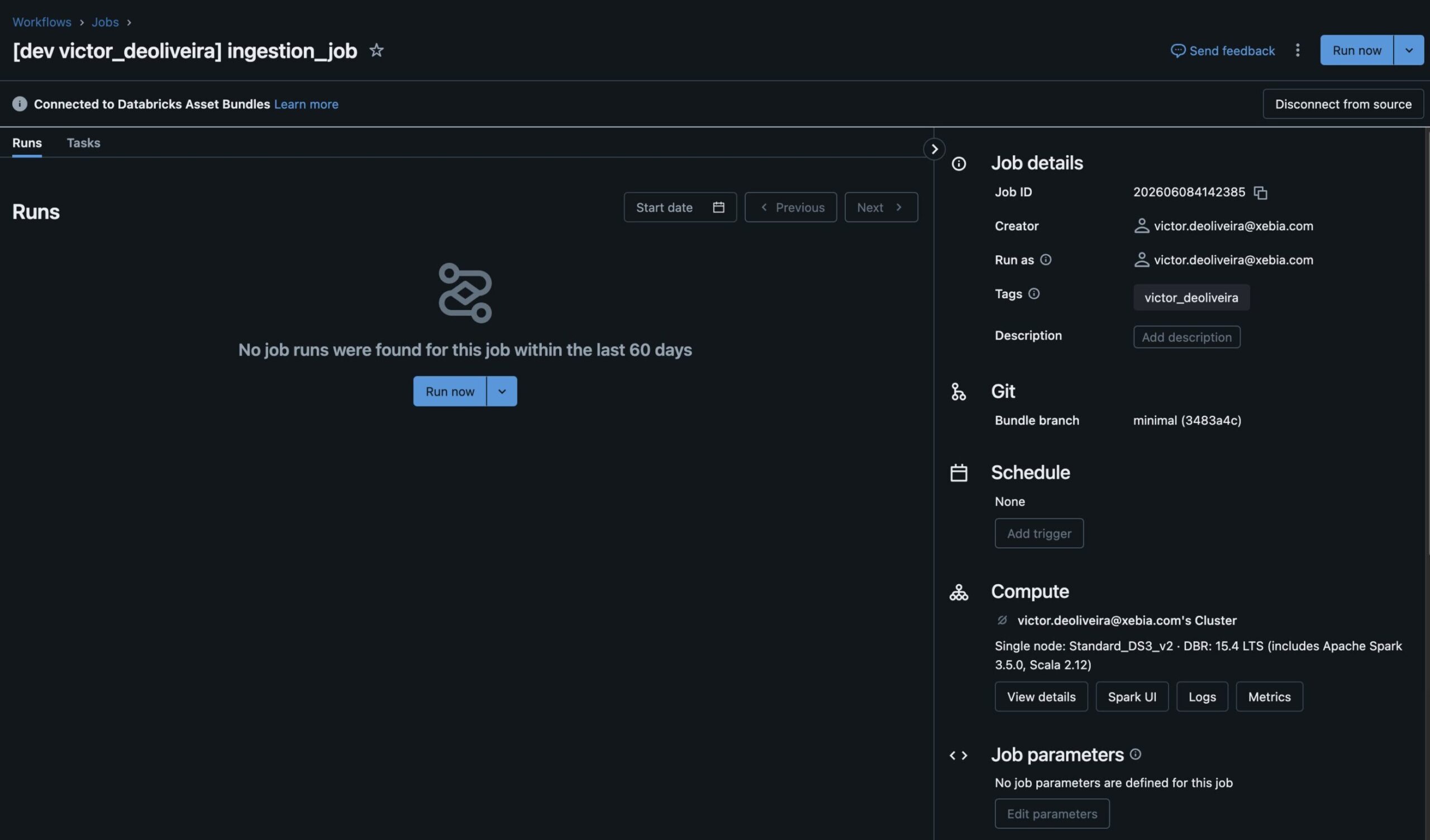
Wie Sie sehen, setzen Bundles die Clusterkonfiguration in der Ressourcendatei außer Kraft, um Ihren persönlichen Computer zu verwenden. Daher kann ich meine Anwendung direkt nach der Bereitstellung testen, ohne darauf warten zu müssen, dass alle Abhängigkeiten installiert sind oder der Job-Cluster gestartet wird. Darüber hinaus wird bei der Bereitstellung auf anderen Zielen, z. B. einer Produktions-/Staging-Umgebung, weiterhin ein in den Ressourcenkonfigurationen definierter Job-Cluster verwendet - ohne dass zusätzlicher Code oder manuelle Eingriffe erforderlich sind.
Parametrisierung mit Variablen und Substitutionen
Sie können die Konfiguration Ihres Projekts weiter anpassen, indem Sie Ersetzungen und Variablen verwenden. Wenn Sie zum Beispiel das Ziel als Parameter an Ihre Anwendung übergeben müssen, können Sie dies ganz einfach mit {$bundle.target} tun, wie im Folgenden gezeigt wird:
resources:
jobs:
ingestion_job:
name: ingestion_job
tasks:
- task_key: main
python_wheel_task:
package_name: ingestion
entry_point: ingestion
named_parameters:
...
env: ${bundle.target}
libraries:
- whl: ../dist/*.whl
new_cluster:
node_type_id: Standard_DS3_v2
num_workers: 1
spark_version: 15.3.x-cpu-ml-scala2.12
Sie können auf den Bundle-Namen und die Ressourcenkonfiguration zugreifen, indem Sie z.B. die gleiche Syntax ${bundle.name}, ${resources.<variable>} verwenden. Neben eingebauten Variablen können Sie auch benutzerdefinierte Variablen verwenden. Sie müssen in Ihrer Datei databricks.yml ein High-Level-Mapping variables definieren und über ${var.<your-variable-name>} darauf zugreifen. Nehmen wir an, unsere Anwendung muss in einen bestimmten Katalog schreiben, der von der Zielumgebung abhängt. Für Staging/Production gibt es beispielsweise bestimmte Kataloge, während ich für Testzwecke einen persönlichen Sandbox-Katalog namens victor_sandbox verwenden möchte. Sie beginnen damit, dass Sie Ihrer Datei databricks.yml folgendes hinzufügen:
variables:
output_catalog:
default: victor_sandbox
Wenn wir diese Variable dann an unsere Anwendung übergeben:
resources:
jobs:
ingestion_job:
name: ingestion_job
tasks:
- task_key: main
python_wheel_task:
package_name: ingestion
entry_point: ingestion
named_parameters:
...
env: ${bundle.target}
output_catalog: ${var.output_catalog}
libraries:
- whl: ../dist/*.whl
new_cluster:
node_type_id: Standard_DS3_v2
num_workers: 1
spark_version: 15.3.x-cpu-ml-scala2.12
Standardmäßig ist die Variable der victor_sandbox Katalog. Aber in Staging/Production wollen wir auf Staging- und Produktionskataloge zugreifen. In unserer Datei databricks.yml tun wir das:
[...]
targets:
staging:
variables:
output_catalog: <staging-catalog-name> # e.g., ml_features_stg
production:
variables:
output_catalog: <production-catalog-name> # e.g., ml_features
[...]
Mit dieser Konfiguration werden bei jeder Bereitstellung unter einem bestimmten Ziel diese Variablen für die catalog verwendet.
Organisieren Sie Ihr Projekt, indem Sie die Aufträge in mehrere Dateien aufteilen
Der nächste Schritt in unserem Anwendungsfall besteht darin, weitere Quellen in unsere Ingestion-Jobs einzubinden. Mit Bundles müssen wir nicht unbedingt zusätzliche Job-Definitionen in dieselbe YAML-Datei einfügen. Wir können sie dort aufteilen, wo es sinnvoll ist, und so das Projekt einfacher verwalten.
Nehmen wir zum Beispiel an, dass wir jetzt drei Tabellen einlesen. In unserer ingestion_job.yaml Definition können wir hinzufügen:
resources:
jobs:
ingestion_job_marketing:
name: ingestion_job
tasks:
- task_key: main
python_wheel_task:
package_name: ingestion
entry_point: ingestion
named_parameters:
env: ${bundle.target}
input_source: mysql
input_schema: marketing
input_table: metrics
output_catalog: ${var.catalog}
output_schema: marketing
output_table: metrics
libraries:
- whl: ../dist/*.whl
new_cluster:
node_type_id: Standard_DS3_v2
num_workers: 1
spark_version: 15.3.x-cpu-ml-scala2.12
ingestion_job_finance:
name: ingestion_job
tasks:
- task_key: main
python_wheel_task:
package_name: ingestion
entry_point: ingestion
named_parameters:
input_source: mysql
input_schema: finance
input_table: results
output_catalog: ${var.catalog}
output_schema: finance
output_table: results
libraries:
- whl: ../dist/*.whl
new_cluster:
node_type_id: Standard_DS3_v2
num_workers: 1
spark_version: 15.3.x-cpu-ml-scala2.12
Wir können dies in zwei Dateien aufteilen, die jeweils eine einzelne Auftragsdefinition enthalten (vergessen Sie nicht, dass sie eindeutig sein müssen, sonst überschreiben sie sich gegenseitig).
resources:
jobs:
ingestion_job_marketing:
name: ingestion_job_marketing
tasks:
- task_key: main
python_wheel_task:
package_name: ingestion
entry_point: ingestion
named_parameters:
env: ${bundle.target}
input_source: mysql
input_schema: marketing
input_table: metrics
output_catalog: ${var.catalog}
output_schema: marketing
output_table: metrics
libraries:
- whl: ../dist/*.whl
new_cluster:
node_type_id: Standard_DS3_v2
num_workers: 1
spark_version: 15.3.x-cpu-ml-scala2.12
resources:
jobs:
ingestion_job_finance:
name: ingestion_job
tasks:
- task_key: main
python_wheel_task:
package_name: ingestion
entry_point: ingestion
named_parameters:
input_source: mysql
input_schema: finance
input_table: results
output_catalog: ${var.catalog}
output_schema: finance
output_table: results
libraries:
- whl: ../dist/*.whl
new_cluster:
node_type_id: Standard_DS3_v2
num_workers: 1
spark_version: 15.3.x-cpu-ml-scala2.12
Tipp: Prüfen Sie als Übung, wie Sie eine komplexe Variable erstellen und die Clusterdefinition zu einer Standardvariablen in der Datei
databricks.ymlmachen können, um die Ausführlichkeit der Ressourcendefinitionen zu verringern.
Sie können beide Dateien unter resources/ speichern und sie dann an Ihre databricks.yml Datei übergeben:
bundle:
name: ingestion_demo
include:
- ./resources/*.yml
...
Nach der Anwendung von Deploy:
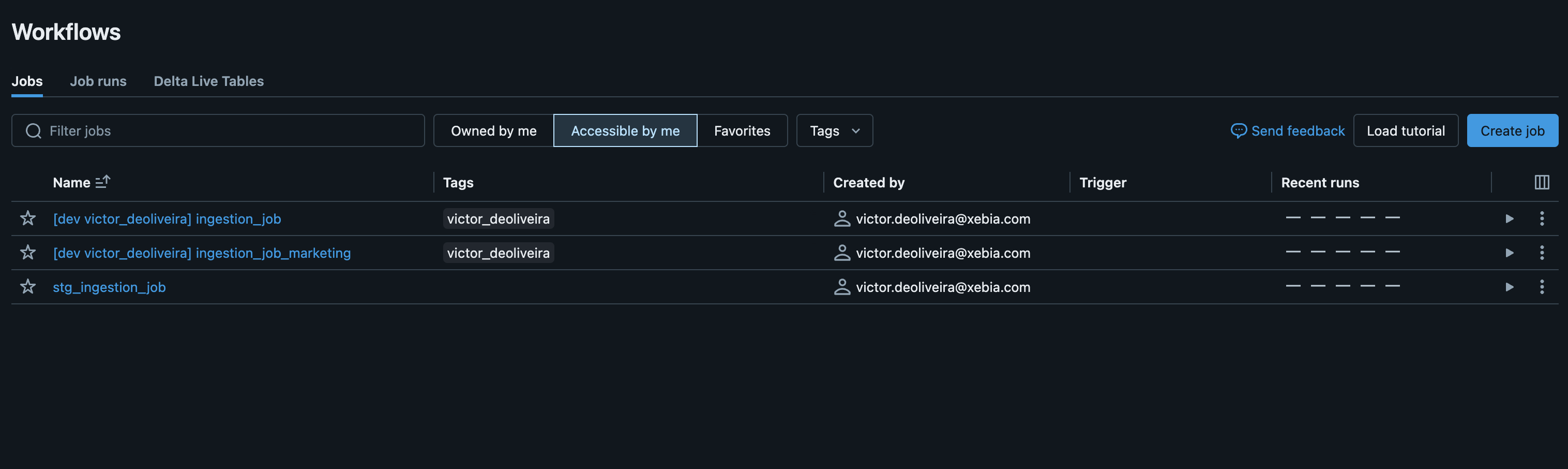
Wir können dies bei Bedarf auf weitere Aufträge ausdehnen und so unser Projekt mit einer YAML-Datei pro Auftrag einfacher gestalten.
Jenseits von Jobs als Ressourcen
Bislang haben wir für unsere Ressourcendefinitionen jobs verwendet, um unsere Python-Aufgaben zu verteilen. Sie können jedoch mit Bundles herumspielen, um Ressourcen über Aufträge hinaus bereitzustellen. Wir können zum Beispiel einen einfachen Integrationstest erstellen, um unsere Anwendung durchgängig auf Databricks auszuführen, indem wir nur Bundle-Befehle verwenden. Nehmen wir an, Sie haben eine Quelltabelle, die Sie als Teil Ihres Integrationstests verwenden möchten. Dann können Sie unter Ressourcen die folgende Datei mit dem Namen test_ingestion_job.yml erstellen:
resources:
jobs:
ingestion_job_integration:
name: ingestion_job_integration
tasks:
- task_key: hello_world
python_wheel_task:
package_name: ingestion
entry_point: ingestion
named_parameters:
env: ${bundle.target}
catalog: ${var.output_catalog}
source_table: mssql.schema.test_table
libraries:
- whl: ../dist/*.whl
new_cluster:
node_type_id: Standard_DS3_v2
num_workers: 1
spark_version: 15.3.x-cpu-ml-scala2.12
Ein wichtiger Schritt unseres Integrationstests besteht darin, unsere Anwendung und die zugehörigen Ressourcen bereitzustellen, sie aber auch zu zerstören, nachdem die Aufgabe abgeschlossen ist. Wir möchten die Methoden setUp und tearDown erstellen und dies sicher tun. Lassen Sie uns daher ein Ziel mit dem Namen test erstellen und es mit dem Suffix test_.
targets:
test:
presets:
name_prefix: "test_"
Jetzt liest unsere Anwendung die Daten aus der Quelle und schreibt sie in eine Tabelle unter dem angegebenen <catalog>.<schema> auf Databricks. Der Katalog wird unser Sandbox-/Entwicklungskatalog sein und wird extern für Ihr Projekt bereitgestellt. Wir müssen jedoch noch ein Schema erstellen. Das können wir mit Spark machen, aber es gibt auch die Möglichkeit, Bundles zu verwenden, die das für uns erledigen.
resources:
jobs:
ingestion_job_integration:
name: ingestion_job_integration
tasks:
- task_key: main
python_wheel_task:
package_name: ingestion
entry_point: ingestion
named_parameters:
env: ${bundle.target}
catalog: ${var.catalog}
source_table: mssql.schema.test_table
libraries:
- whl: ../dist/*.whl
new_cluster:
node_type_id: Standard_DS3_v2
num_workers: 1
spark_version: 15.3.x-cpu-ml-scala2.12
schemas:
integ_schema:
name: _integ_schema
catalog_name: ${var.catalog}
comment: This test schema was created by DABs.
Wenn Sie dann den Befehl deploy ausführen, wird das Schema zusammen mit dem Auftrag mithilfe von Bundles erstellt, wie in der folgenden Abbildung dargestellt.
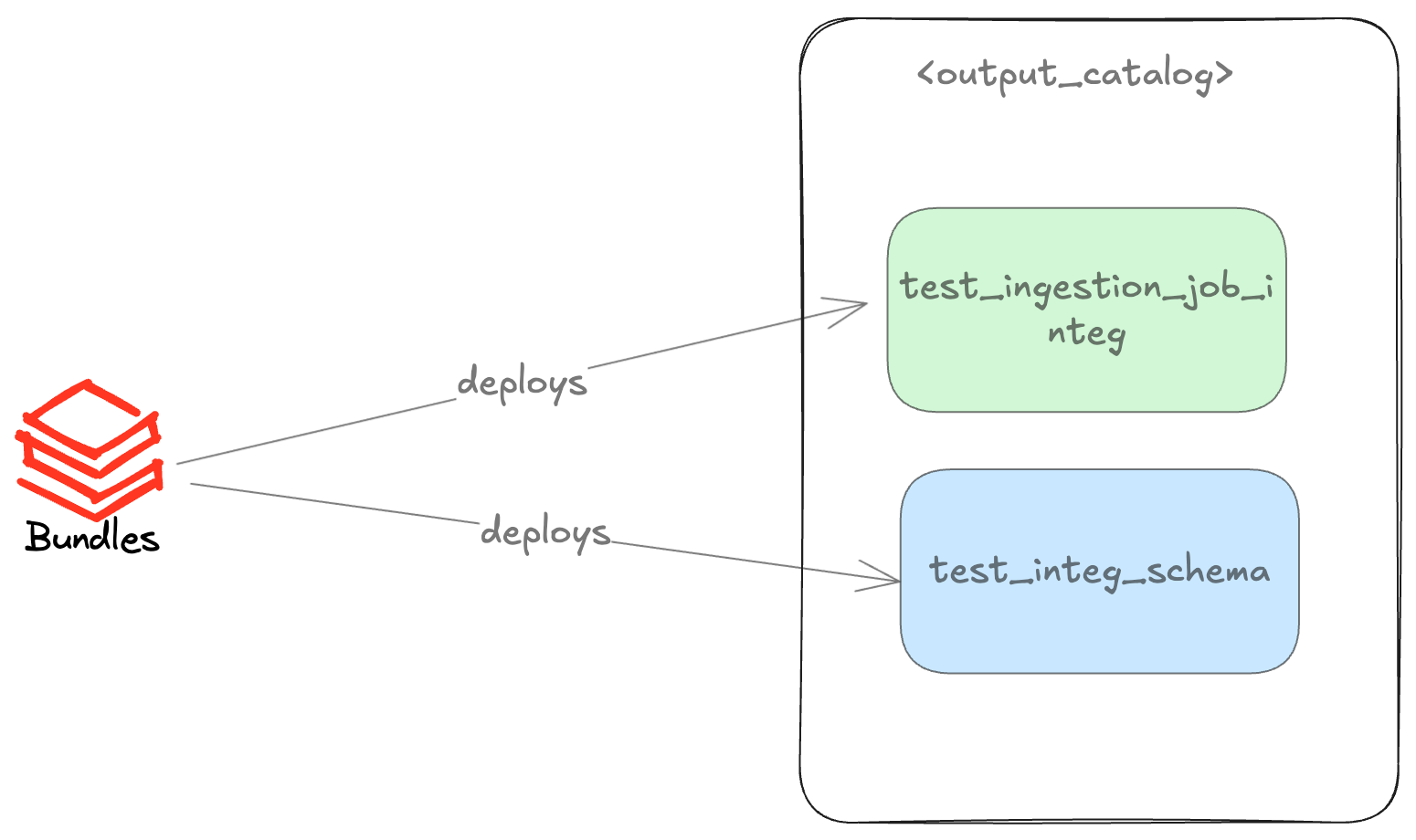
Als nächstes können Sie Ihre Pipeline ausführen. Wenn der Befehl erfolgreich ausgeführt wird, können Sie destroy anwenden, um alle Ihre Ressourcen herunterzufahren, einschließlich des erstellten Schemas und aller darunter liegenden Tabellen. Mit ein paar zusätzlichen Schritten haben wir schnell einen Integrationstest auf Databricks durchgeführt. Das Beste daran ist, dass dafür kein zusätzlicher Code erforderlich ist.
Tipp: Vielleicht fragen Sie sich, was passiert, wenn ein Lauf fehlschlägt und die Zerstörungsaufgabe nie erreicht wird. Sie können Ihre CI/CD-Pipeline ganz einfach so einrichten, dass der Befehl destroy immer ausgeführt wird und alle Ressourcen bereinigt werden, wenn der "Test" beendet ist.
Neben Schemata können Bundles auch andere Ressourcen bereitstellen, z. B. Experimente, Modelle, Dashboards usw. Die vollständige Liste finden Sie hier.
Fazit
In diesem Blogbeitrag haben wir untersucht, wie Sie Ihre Workflow-Bereitstellung mit Databricks Asset Bundles vereinfachen können. Indem wir die Leistungsfähigkeit von Databricks nutzen, können wir Ressourcen in verschiedenen Umgebungen wie Entwicklung, Staging und/oder Produktion effizient und mit minimalem Aufwand verwalten und bereitstellen. DABs ermöglichen eine einfache Konfiguration und Differenzierung zwischen den Umgebungen und stellen sicher, dass die Ressourcen angemessen verwaltet und die Kosten kontrolliert werden. Darüber hinaus haben wir gezeigt, wie Sie die Funktionalitäten mit voreingestellten Konfigurationen erweitern, benutzerdefinierte Variablen verwenden und Ihre Aufträge sogar auf Ihrem eigenen Cluster ausführen können, um während der Entwicklung schneller zu iterieren. Mit diesen Tools und Techniken können Sie Ihre Entwicklungs- und Bereitstellungsabläufe verbessern und sie effizienter und robuster machen.
Im letzten Blogbeitrag werden wir die Integration von Bundles in unsere CI/CD-Pipelines besprechen. Dadurch entfällt die Bereitstellung in Produktionsumgebungen von Ihrem lokalen Rechner aus, und Sie erhöhen die Reife Ihres Projekts, indem Sie Praktiken anwenden, die Entwicklern helfen, Fehler in der Produktion zu vermeiden.
Verfasst von
Victor De Oliveira
I appreciate feedback: https://www.linkedin.com/in/victor-de-oliveira-b0634449/
Unsere Ideen
Weitere Blogs




Contact