Zuvor haben wir containerisierte Anwendungen mit Amazon Elastic Container Service (ECS) und AWS Fargate verglichen. Aber es gibt noch mehr Optionen zu besprechen!
Wie Sie sich vielleicht erinnern, haben wir bei unserem Proof of Concept (PoC) neben den beiden oben genannten Diensten auch den Amazon Elastic Container Service für Kubernetes getestet, der kurz als Amazon EKS bezeichnet werden kann. Darüber möchte ich heute sprechen - um die Gültigkeit von Amazon EKS für den gleichen Zweck zu bewerten!
Ein kurzer Rückblick
Falls Sie eine kurze Erinnerung brauchen: Der Geschäftsfall unseres PoCs betraf ein (hypothetisches) Fotografieunternehmen, das sein Portfolio um Bildbearbeitungsdienste erweitern wollte. Die Kunden des Unternehmens, die rund um den Globus ansässig sind, könnten eine große Anzahl von Bildern hochladen, die bearbeitet werden müssen - sie sind davon ausgegangen, dass in einem 30-minütigen Zeitrahmen nicht mehr als 10.000 Bilder zu bearbeiten sind. Dies sollte als extremer Grenzfall betrachtet werden, den das System erleben würde.
Außerdem möchte das Fotogeschäft über eine Infrastruktur verfügen, die effektiv arbeitet, wenn eine große Menge an Uploads stattfindet, und möchte auch nachts nicht zu viel für die Infrastruktur bezahlen, da zu dieser Zeit nicht viele Bilder umgewandelt werden müssen. Und natürlich möchte der Kunde diese neue Lösung schnell implementieren und seine Markteinführungszeit verkürzen.
Das Unternehmen hat von der Verwendung einer Cloud-Lösung gehört und würde solche Funktionen gerne nutzen, aber wie funktioniert das für den Endbenutzer? Nach der Bearbeitung eines Bildes sollten sowohl die ursprüngliche als auch die umgewandelte Version heruntergeladen werden können - vorausgesetzt, die Benutzer löschen sie nicht. Die erste Lösung, die mir in den Sinn kommt, ist serverloses Computing mit AWS Lambda, aber das Unternehmen ist noch nicht bereit für eine solche Innovation. Für die Umwandlung von Bildern hat das Unternehmen bereits drei containerisierte Anwendungen entwickelt, die alle darauf ausgelegt sind, eine große Anzahl von Bildern zu verarbeiten.
Ihre drei Ziele sind:
- um die Intensität in Graustufen umzuwandeln,
- um die Bilder mit einem Wasserzeichen zu versehen,
- um eine Miniaturansicht zu erstellen.
 Abbildung 1 Ein Bild vor und nach der Konvertierung in Graustufen[/caption]
Abbildung 1 Ein Bild vor und nach der Konvertierung in Graustufen[/caption]
 Abbildung 2. Ein Originalbild und ein Bild mit einem PGS Software-Logo als Wasserzeichen[/caption]
Abbildung 2. Ein Originalbild und ein Bild mit einem PGS Software-Logo als Wasserzeichen[/caption]
 Abbildung 3. Ein Originalbild und eine Miniaturansicht[/caption]
Abbildung 3. Ein Originalbild und eine Miniaturansicht[/caption]
Unser Hauptziel war es, eine Cloud-Infrastruktur aufzubauen, die die folgenden Geschäftsanforderungen erfüllt:
- Hochladen und Herunterladen einer großen Anzahl von Bildern auf eine dauerhafte Speicherlösung,
- Verarbeitung von 10 Tausend Bildern in weniger als 30 Minuten,
- Nutzung der vorhandenen containerisierten Anwendungen, je nach Verkehrsaufkommen, um die Kosten durch effektive Nutzung der Infrastruktur zu senken,
- Bilder nach der Umwandlung zu speichern, solange sie auf dem System verbleiben.
Anpassen für Amazon EKS
Für Amazon EKS gab es keine Änderungen am Konzept des Anwendungsfalls oder an der Architektur als Ganzes, so dass die Entscheidung, dieses Szenario zu extrahieren, hauptsächlich durch die Art und Weise motiviert war, wie Kubernetes die Replikation von containerisierten Anwendungsinstanzen handhabt. Die ECS- und Fargate-Autoskalierungsgruppen wurden so konfiguriert, dass die Anzahl der gewünschten Aufgaben als Reaktion auf CloudWatch-Alarme nach oben oder unten angepasst wird. Auf der Grundlage der Anzahl der Nachrichten, die für den Abruf aus der SQS-Warteschlange zur Verfügung standen, wurden Aufgaben zu den Diensten hinzugefügt oder aus ihnen entfernt. In EKS verwendeten wir einen Kubernetes Metrics Server, um Daten zur Ressourcennutzung für die horizontale Skalierung von Containern zu sammeln. Unserer Meinung nach war dieser Unterschied entscheidend genug, um einen weiteren Blogbeitrag zu verfassen - und hier ist er!
Eine Einführung in Kubernetes
Kubernetes (abgekürzt k8s) ist eine Open-Source-Plattform, die die Verwaltung von containerisierten Anwendungen erleichtert, aber auch die Skalierung und die Automatisierung von Bereitstellungen übernimmt. Dies ist zwar eine gute allgemeine Beschreibung, aber lassen Sie uns einen genaueren Blick darauf werfen und auf Funktionen hinweisen, die k8s von anderen unterscheiden:
Dienstsuche und Lastausgleich
Es besteht keine Notwendigkeit, einen externen und/oder unbekannten Service-Ermittlungsmechanismus zu verwenden. Jeder Pod (wenn Ihnen das nicht bekannt vorkommt, denken Sie an einen Container - ich werde Pods später beschreiben) erhält seine eigene IP-Adresse und einen einzigen DNS-Namen für eine Reihe von Containern mit derselben Anwendung. Außerdem kann er den Datenverkehr zwischen den Containern ausbalancieren.
Automatisierte Prozesse zur Verpackung von Behältern, basierend auf Arbeitslast und Auslastung
Kubernetes platziert Container ohne jegliche Hilfe. Es nutzt den Ressourcenbedarf der Anwendung und andere Einschränkungen, ohne dass die Verfügbarkeit darunter leidet.
Speicher-Orchestrierung
Sie können ein beliebiges Speichersystem verwenden, entweder lokal gemountet, bei einem öffentlichen Cloud-Anbieter wie AWS oder ein Netzwerkspeichersystem, wie z.B. ein Network File System (NFS), das eine sehr verbreitete Option ist.
Selbstheilungsfähigkeit und Rollouts zur Bereitstellung
K8s überwacht die bereitgestellte Infrastruktur und ergreift schnell Maßnahmen, wenn es Ausfälle feststellt oder wenn ein Pod nicht auf Gesundheitsprüfungen (die vom Benutzer definiert werden) reagiert. Selbst wenn ein Worker Node ausfällt, müssen Sie containerisierte Anwendungen nicht manuell umplanen. Abgesehen davon bietet Kubernetes nicht nur die Fähigkeit zur Selbstheilung, sondern auch Änderungen, ohne dass alle Container in unserem Einsatz getötet werden müssen. Wenn etwas schief geht, wird der vorherige Zustand wiederhergestellt und ein Rollback durchgeführt.
Geheimnis- und Konfigurationsmanagement
Wenn Sie eine externe Konfiguration oder eine Art von Anmeldeinformationen verwenden möchten, ohne Container neu zu erstellen, können Sie Secrets oder ConfigMaps verwenden.
Batch Job Ausführung
Sie können einen Einzweck-Container als Auftrag ausführen. Dies kann parallel oder mit einigen wenigen hintereinander geschehen, aber auch mit der Verwendung.
Horizontale Skalierung
Wie bereits erwähnt, bietet Kubernetes eine eigene Methode für die automatische Skalierung. Sie kann auf der CPU- oder Speicherauslastung basieren.
Namensräume, Beschriftungen und Anmerkungen
Es ist nicht nötig, mehrere Cluster zu erstellen, um für jede Phase des Entwicklungsprozesses eine eigene Umgebung zu haben. Sie können die von Kubernetes bereitgestellten Namespaces verwenden, so dass jedes Team, das an dem Projekt arbeitet, einen eigenen virtuellen Cluster hat. Alle Ressourcen, die in einem Namespace erstellt werden, existieren und sind nur innerhalb dieses Namespaces sichtbar, es sei denn, Sie verwenden den Namen des gewählten Namespaces als Suffix zusammen mit dem Namen der Ressource, um sie aus einem anderen Namespace zu erreichen (z.B. mynamespace.myresource).
Als nächstes folgen Labels, die helfen können, Teile von Anwendungen zu unterscheiden. Außerdem werden sie von Diensten verwendet, um die gewünschte Anzahl von Container-Replikaten auszuführen, den Zustand zu überprüfen oder die Planung vorzunehmen. Wenn Ihnen Etiketten nicht ausreichen, können Sie auch Anmerkungen verwenden, um Ressourcen mit Metadaten zu versehen, z.B. Namen und Versionen der verwendeten Bibliotheken oder Kontaktinformationen usw.
Dashboard und CLI
Sie können die spezielle K8s Dashboard UI verwenden, um die Arbeitslasten in Ihrer Infrastruktur, den Status oder sogar die Protokolle zu verfolgen - ohne die . Administratoren hingegen werden die Befehlszeilenschnittstelle lieben, die das Erstellen und Bearbeiten von Ressourcen sowie die Verwaltung von Berechtigungen mit einfachen Befehlen ermöglicht.
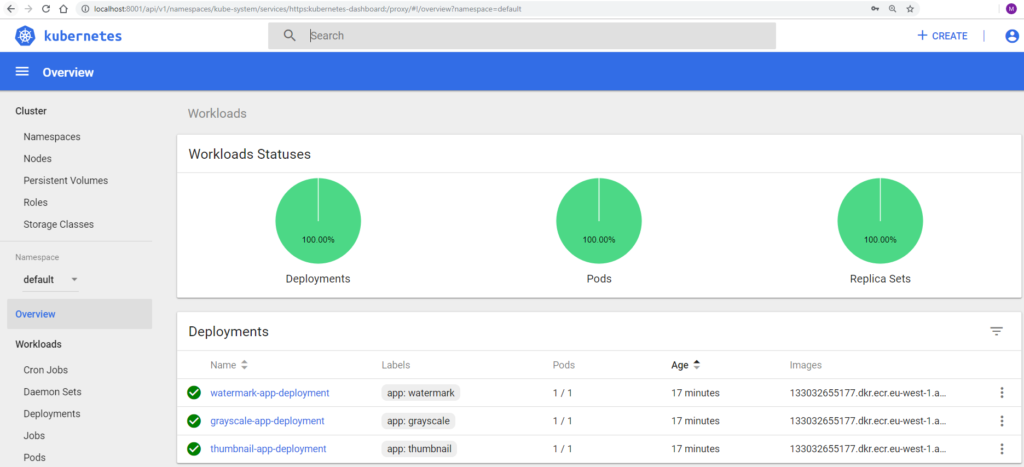
Abbildung 4 Kubernetes Dashboard
Nun ist es an der Zeit, die Objekte vorzustellen, die üblicherweise zum Aufbau einer Infrastruktur mit Kubernetes verwendet werden. Jedes einzelne kann mithilfe einer Manifestdatei erstellt werden, die entweder in JSON, YAML oder über die Befehlszeilenschnittstelle von Kubernetes geschrieben wird. Auf diese Weise wird es einfacher zu verstehen, wie die verschiedenen Funktionen funktionieren und zusammenarbeiten.
Die allererste und grundlegende sind Pods. Diese können als Wrapper für Container - oder sogar mehrere Container - betrachtet werden. Jedem Pod ist eine eigene IP-Adresse zugewiesen und er kann auch über angeschlossene Speicherressourcen verfügen.
Als nächstes haben wir Deployment. Dabei handelt es sich um ein Objekt, das einen gewünschten Status für alle darin deklarierten Pods aufrechterhält. Sie können rollierende Aktualisierungen durchführen oder sogar den Prozess der Bereitstellung von Änderungen unterbrechen, wenn etwas schief gelaufen ist. Es ist auch möglich, im Manifest festzulegen, welcher Prozentsatz des Deployments zu einem bestimmten Zeitpunkt während der Aktualisierungen verfügbar sein muss, sowie die Regeln festzulegen, nach denen die Zeitplanung gehandhabt werden soll.
Daneben gibt es NodeAffinity, das uns hilft, die Knoten zu bestimmen, die wir für die Verarbeitung unserer Pods bevorzugen. PodAffinity & PodAntiAffinity scheinen jedoch noch interessanter zu sein. Mit einer dieser Konfigurationen können Sie festlegen, dass Pod X auf einem Knoten, auf dem bereits Pod Y läuft, eingeplant werden soll oder nicht. Bei der Verwendung von Anti-Affinity möchten wir sicherstellen, dass die angegebenen Ressourcen niemals gemeinsam genutzt werden. Diese Konfigurationen sind sehr hilfreich, wenn Sie fortgeschrittenere Optionen und eine größere Kontrolle benötigen als der einfache NodeSelector, der sich auf die Auswahl des Knotens anhand von Schlüssel-Wert-Paaren aus Labels beschränkt.
Als nächstes folgen die HorizontalPodsAutoscaler. Dabei handelt es sich um Kubernetes-Ressourcen, die die Skalierung unseres Deployments anhand von Daten zur Speicher-/CPU-Auslastung vornehmen. Es ist wichtig, dass Sie die Formel kennen, nach der die entsprechende Anzahl von Replikaten ausgeführt wird:
desiredReplicas = ceil[currentReplicas * ( currentMetricValue / desiredMetricValue )]
Es funktioniert sehr gut und ich habe keine Probleme mit der Effizienz festgestellt. Standardmäßig werden die Informationen über die Ressourcennutzung alle 30 Sekunden abgerufen, aber dies kann durch Ändern eines der Flags von kube-controller-manager verlängert oder verkürzt werden.
Dienste sorgen für den Datenverkehr zwischen Pods oder für die Bereitstellung von . Je nach Ihren Bedürfnissen ist es jedoch wichtig zu wissen, dass es einige Typen gibt, die verwendet werden können, um einen Dienst zu erstellen, der Ihren Anforderungen entspricht:
- ClusterIP Weist unserem Einsatz die IP-Adresse zu, die nur von Objekten innerhalb eines Clusters erreicht werden kann.
- NodePort Neben der Zuweisung der CusterIP wird auch der Portbereich (30000-32767) auf jedem Knoten bereitgestellt, so dass die Anwendung von außen erreicht werden kann.
- LoadBalancer Sie können sogar AWS Load Balancers verwenden, die mit dem Kubernetes-Netzwerk zusammenarbeiten.
ReplicaSet stellt sicher, dass eine angegebene Anzahl von Pods gleichzeitig arbeitet und sorgt dafür, dass, wenn sich etwas in unserer Infrastruktur ändert, ein Pod ausfällt oder ein Knoten verschwindet, ReplicaSet versucht, die fehlenden Pods in der erforderlichen Anzahl wiederherzustellen. Es ist gut zu wissen, dass diese Ressource zusammen mit Deployment erstellt wird.
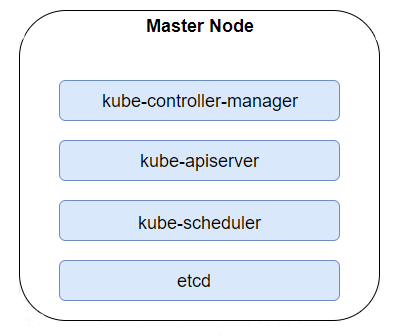
Master-Knoten verfügen über alle Binärdateien, die zur Verwaltung der Infrastruktur benötigt werden. Der Kube-controller-manager ist ein Daemon, der den Zustand eines Clusters mithilfe der mit Kubernetes gelieferten zentralen Kontrollschleifen verfolgt und reguliert. Er verwendet Kube-apiserver , um gemeinsame Daten über Ressourcen zu sammeln und nimmt alle Änderungen vor, die erforderlich sind, um den gewünschten Zustand zu erreichen. Die zweite Binärdatei ist Kube-apiserver, ein Restful-Dienst, der alle Anfragen eines Administrators sowie die Anfragen aus der internen Kommunikation zwischen Nodes und Pods bearbeitet. Außerdem haben wir Kube-scheduler, der sich um die Planung der Ressourcen auf die effizienteste Weise kümmert, unter Berücksichtigung von Speicherkapazität, CPU-/Speicherauslastung und Labels. Der letzte erwähnenswerte Knoten ist ETCD, ein hochverfügbarer Schlüsselwertspeicher mit Informationen über den Zustand eines Clusters.
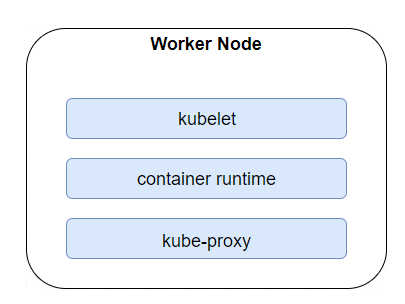
Worker Nodes tragen alle von uns eingesetzten Pods. Ähnlich wie bei den Master-Knoten kann es sich dabei um physische Maschinen, von der Cloud bereitgestellte virtuelle Maschinen (VMs) oder einfach um VMs auf unserem lokalen Server handeln. Neben den containerisierten Ressourcen, die in jedem Cluster bereitgestellt wurden, finden wir auch Binärdateien, die für die Worker bestimmt sind. Kubelet sorgt zum Beispiel dafür, dass jeder Container innerhalb eines Pods läuft, während Kube-proxy die Vernetzung aufrechterhält und Verbindungen weiterleitet. Um Container auszuführen, benötigt Kubernetes eine Container-Laufzeitumgebung. Unter den unterstützten Optionen sind Containerd und natürlich Docker die beliebtesten.
DaemonSets erstellen auf jedem Knoten eine Kopie eines ausgewählten Pods und sorgen dafür, dass dieser immer vorhanden und funktionsfähig ist.
Secrets und ConfigMaps werden verwendet, um die Konfiguration von Images und Anwendungen fernzuhalten. Beide können als Volume gemountet oder als Umgebungsvariable angehängt werden. Erstere können Anmeldeinformationen für die Datenbank oder die Registrierung enthalten, da die Werte in Base64 Message Digest bereitgestellt werden. Die letzteren ConfigMaps können wir als eine Sammlung von Eigenschaften betrachten, die in einen Container injiziert werden können.
Abgesehen von all den oben genannten Funktionen ist es auch interessant zu wissen, dass Borg - Googles internes Orchestrierungsprojekt - der Vorgänger von Kubernetes ist. Viele der Entwickler, die für K8s verantwortlich sind, haben formal über Borg gearbeitet. Es gibt vier geerbte Schlüsselfunktionen
- Schoten
- Etiketten
- Dienstleistungen
- IP pro Pod
Amazon Elastic Container Service für Kubernetes
Als Kubernetes auf dem IT-Markt auftauchte und an Popularität gewann, war es nur eine Frage der Zeit, bis Amazon einen eigenen Service zur Unterstützung von Kubernetes schuf. Kurz gesagt, so wurde der Amazon Elastic Container Service für Kubernetes geboren. Und für uns ist das großartig, denn mit nur wenigen Schritten erhalten wir einen fertigen Cluster mit drei Master-Knoten, standardmäßig einen pro nächstgelegener Availability Zone. Was die Kosten betrifft, so zahlen Sie 0,20 $ pro Stunde, unabhängig davon, ob einer der Master-Knoten neu erstellt werden muss, sowie den Preis für jeden anderen in unserer Infrastruktur verwendeten Amazon-Service.
An dieser Stelle werden Sie sich vielleicht über Worker Nodes wundern. Es ist Sache des Administrators, EC2-Instanzen zuzuordnen, entweder manuell oder über die Autoscaling Group. Es gibt ein entsprechendes System-Image in der Amazon Machine Images Registry, das der VM dabei hilft, als Worker zu dienen.
EKS wird recht häufig aktualisiert, so dass Sie alle neuesten Funktionen nutzen können und sicher sein können, dass die Infrastruktur vor Sicherheitsverletzungen geschützt ist. Um es auf dem neuesten Stand zu halten, müssen Sie sich nur bei der AWS Management Console anmelden und den entsprechenden Cluster und die Version auswählen, auf die Sie es aktualisieren möchten. Es ist so einfach, wie es klingt. Abgesehen von der Wahl, wie mit Worker Nodes umgegangen werden soll, ist der Benutzer auch für die Installation von Diensten verantwortlich, z.B. für die Unterstützung des automatischen Aufrufs, da die Instanzen standardmäßig von jeglicher Art von Arbeitslast befreit sind. Dies kann je nach Anwendungsfall als Vorteil oder Nachteil betrachtet werden.
Die größten Probleme waren jedoch der fehlende Zugriff auf Master-Knoten und Binärdateien. Die Ausführung des Kube-Controller-Managers ist mit dem Setzen von Flags verbunden, die vom Metrics Server verwendet werden. Standardmäßig dauerten die Intervalle zwischen den Überprüfungen der Auslastung 30 Sekunden und bei der Verkleinerung von Pods kann es sogar bis zu 5 Minuten dauern. In unserem Fall, in dem der Spitzenwert bei 10.000 Images in der Warteschlange lag, waren diese Werte nicht zufriedenstellend und in einigen Szenarien kam es vor, dass Container hochskaliert wurden, obwohl die SQS-Warteschlangen leer waren.
AWS Architektur
Lassen Sie uns nun einen genaueren Blick auf die Ressourcen werfen, die innerhalb der Virtual Private Cloud (VPC) für unser Szenario mit Elastic Container Services for Kubernetes bereitgestellt wurden.
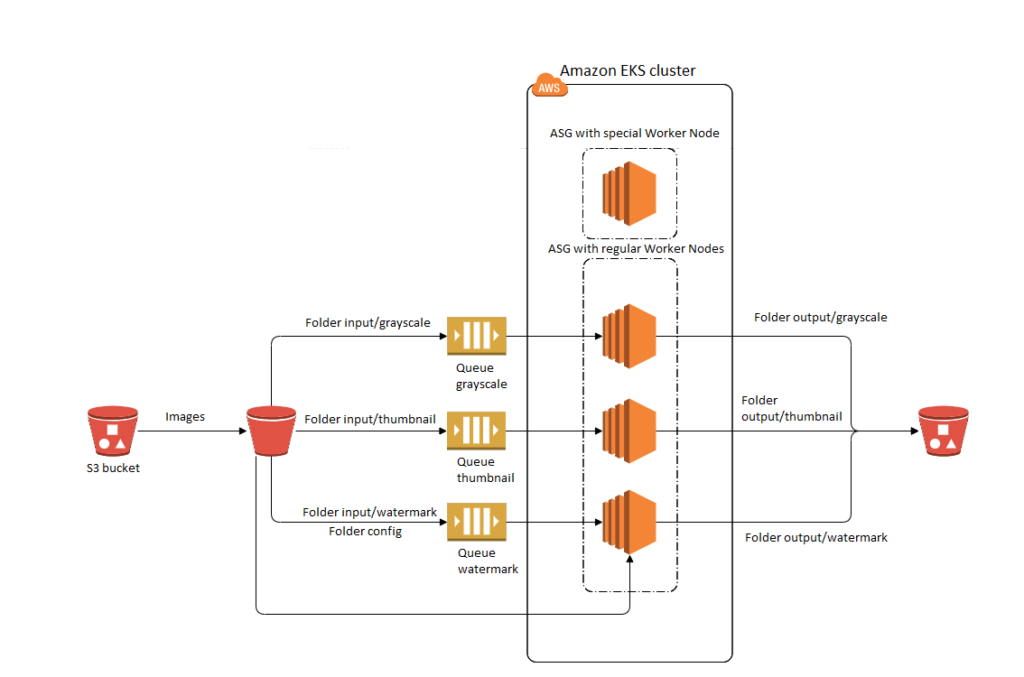
Dies mag zunächst verwirrend sein, da im obigen Diagramm keine Master-Knoten zu sehen sind, aber wie bereits erwähnt, kümmert sich Amazon um diese und verhindert so, dass wir einen Cluster ohne einen einzigen API-Service haben, den wir aufrufen können. Im Übrigen haben wir zwei verschiedene Autoscaling-Gruppen für Worker Nodes. Normalerweise würden Sie eine solche Infrastruktur zweifelsohne als Anti-Musteraber für unser spezielles Szenario und die Notwendigkeit, eine große Anzahl von Bildern in kürzester Zeit zu verarbeiten, bei denen es zu starken Belastungen kommen kann (stellen Sie sich vor, dass in Spitzenzeiten oder bei einer erfolgreichen Werbeaktion oder einem Rabatt Tausende von Benutzern innerhalb weniger Sekunden aktiv werden), war dies ziemlich zufriedenstellend und löste das Problem, ohne dass Daten über die Metriken der Ressourcennutzung verloren gingen.
Wenn die Worker Node-Instanz mit Metrics Server, die für die Skalierung von Pods verwendet wird, beendet würde, dann gibt es im schlimmsten Fall für etwa 1 Minute keine Informationen, die für die Ausführung der optimalsten Anzahl von konvertierenden Apps benötigt werden - was für Anwendungen, denen die Ressourcen ausgehen können, schlecht ist. Als dieser PoC erstellt wurde, konnten wir keine Ratschläge zur Synchronisierung und gemeinsamen Nutzung von Daten zwischen mehreren Metric-Server-Instanzen finden, da dies unser Problem lösen würde. Daher folgten wir einer natürlicheren Methode zur Erstellung eines Clusters mit einer Autoscaling-Gruppe für Worker Nodes.

Abbildung 8 HorizontalPodAutoscalers Informationen aus der CLI.
Nachdem ich nun unseren Ansatz erläutert habe, sehen Sie unten die Ansicht der Worker in einem kalten Zustand ohne jeglichen Datenverkehr. Wichtig ist hier jedoch, dass wir das Label ROLE verwendet haben, um Instanzen zu unterscheiden und Kubernetes mitzuteilen, wo Pods mit Anwendungen bereitgestellt werden sollen und wo die Pods, die für die Verarbeitung von Nutzungsdaten zuständig sind.

Abbildung 9 Worker Nodes im Cluster.
Hier sehen Sie die grundlegende Einrichtung unseres Clusters in der erforderlichen Pods-Konfiguration und -Zuordnung.
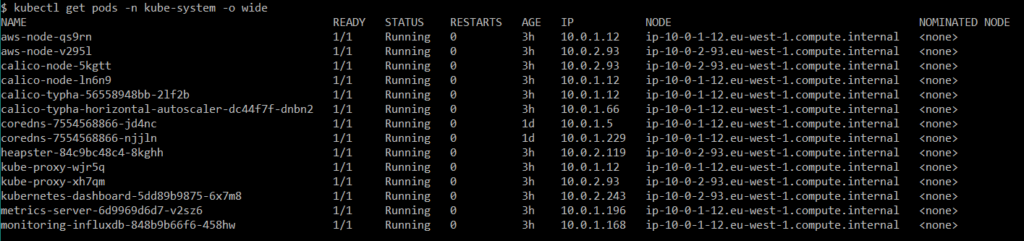
Abbildung 10 Pods aus dem Namespace kube-system.
Abgesehen von aws-node und kube-proxy, sowie calico Pods, kann ich sagen, dass der Rest mehr oder weniger damit zu tun hatte, Autoskalierung und Überwachung richtig zu handhaben und das ist der Grund für die Bereitstellung auf Worker mit einem Label Role, das den Metrikwert hat. Glücklicherweise ist die Dokumentation von K8 leicht verständlich und enthält alle notwendigen Informationen, um einen Metrics Server und Heapster für Dashboard einzurichten.
Konvertieren von Graustufenbildern
Werfen wir nun einen Blick auf eine der Bereitstellungsdateien, die ein Manifest für die Anwendung zur Konvertierung einer Graustufenkopie des Bildes enthält.
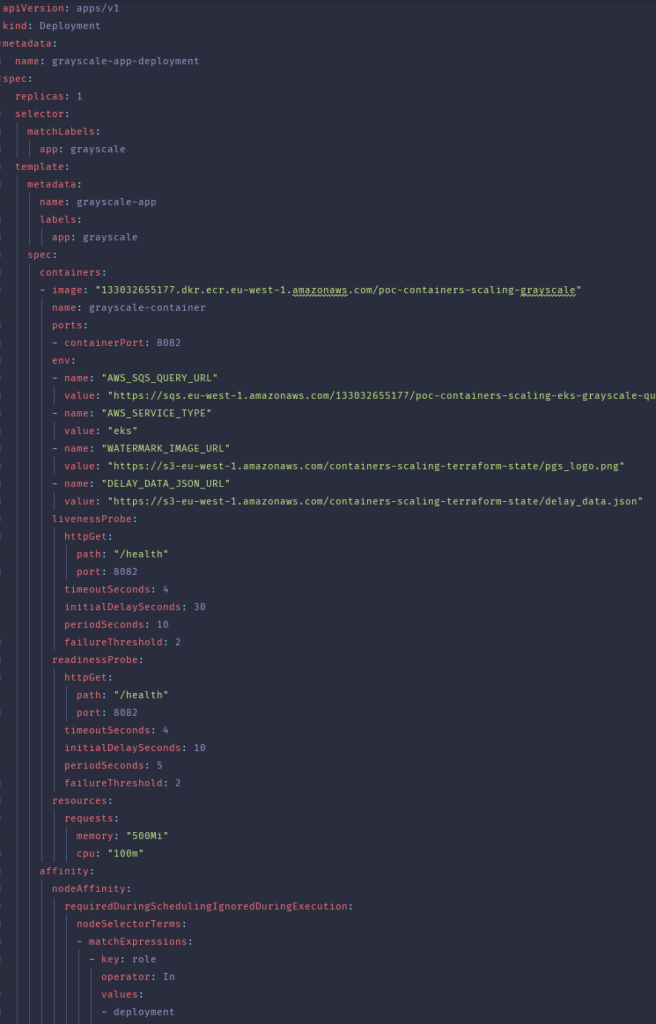
Die Dateien wurden mit Terraform-Vorlagen erstellt, da einige wichtige Werte vom Ergebnis der Einrichtung der Infrastruktur abhängen. Wie Sie vielleicht wissen, können Sie, wenn die Anwendung des Terraform-Plans erfolgreich war, Daten über die erstellten Ressourcen über Terraform-Ausgabewerte erhalten. Der Anfang jeder Datei ist sehr einfach und für jede k8s-Installation gleich. Für interessantere Aspekte haben wir Umgebungsvariablen verwendet, um wichtige Informationen an unsere Anwendungen weiterzugeben und sie nicht hart zu kodieren.
Abgesehen davon ist es nichts wert, dass LivenessProbes hier sehr wichtig waren. Bei starker Belastung halfen sie festzustellen, ob mit dem Container etwas nicht stimmte und ob er den Datenverkehr nicht mehr bewältigen konnte. Wenn in dieser Situation der failureThreshold erfüllt war, wurde der ungesunde Container neu erstellt. Um einen Pod auf dem richtigen Knoten bereitzustellen, haben wir uns für NodeAffinity entschieden. Ein ähnliches Ergebnis ließe sich aber auch mit NodeSelector erzielen, und zwar mit noch weniger Aufwand beim Schreiben der Dateivorlage.
Für die Skalierung von Workers gab es keine Unterstützung für Cloud Watch-Auslastungsalarme für EKS, als wir dies durchführten. Eine unserer Ideen war es, einen AWS Lambda zu erstellen, um Workers auf der Grundlage der Anzahl der Images in der SQS-Warteschlange zu skalieren, aber schließlich entschieden wir uns, dem Bash-Skript einen Abschnitt zur Installation des CloudWatch-Agenten hinzuzufügen, der bei der Initialisierung jeder Worker EC2-Instanz in unserer Infrastruktur angewendet wird. Jetzt sollte viel klarer sein, warum unsere Testszenarien anders waren als die von ECS oder Fargate. Die auf unseren Instanzen installierten Agenten übermittelten ebenfalls jede Minute die gesammelten Daten, wie mit Crontab konfiguriert.
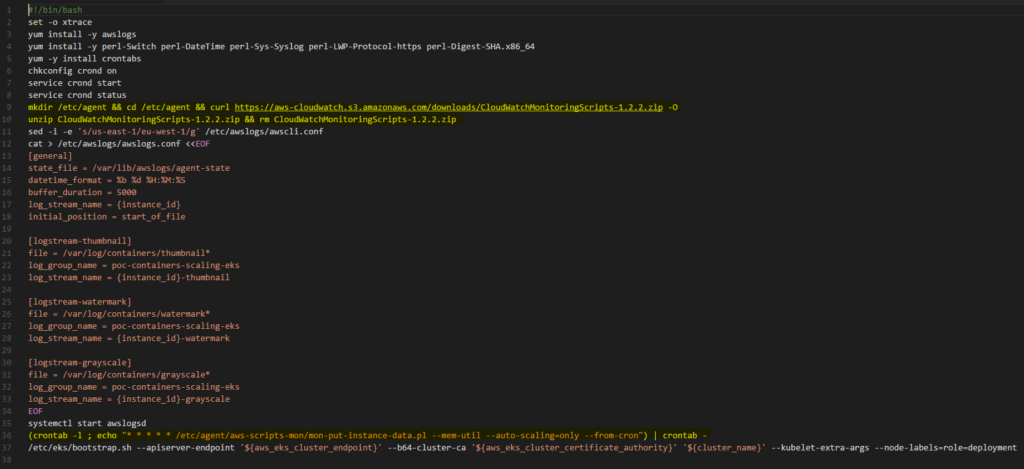
Test-Szenarien
Um die Skalierung des EKS-Clusters zu testen, wurden, wie oben beschrieben, 10.000 Bilder in die entsprechenden Ordner im S3-Bucket hochgeladen. Diese Testfälle wurden in zwei Gruppen unterteilt: INSTANZ/SPEICHER - POD/CPU und INSTANZ/CPU - POD/CPU. Für die Skalierung der Instanzen haben wir CloudWatch-Alarme und auch Agenten verwendet, die bei der Initialisierung auf jedem einzelnen Worker installiert wurden.
Für Pods hingegen haben wir HorizotalPodAutoscalers erstellt. Bereits in der ersten Testphase haben wir festgestellt, dass die Skalierung von Pods auf der Grundlage des Speichers mühelos möglich ist, da in unserem Fall die Bilder nicht parallel konvertiert wurden. Jede Gruppe hat vordefinierte Einstellungen für Cloud Watch Alarme, die für die jeweiligen Szenarien gelten.
Wir haben darauf verzichtet, verschiedene AutoScalingGroup-Schwellenwerte zu testen, da dieser Proof of Concept zu umfangreich wäre und die Ergebnisse schwer zu verarbeiten wären. Kommen wir also zu den eigentlichen Szenarien:
INSTANZ/SPEICHER - POD/CPU
- 100% der Bilder wurden in den Ordner input/watermark hochgeladen. Scale-up-Richtlinie für EKS Worker-Instanzen auf über 65% im Cloud Watch-Alarm eingestellt. Scale-down-Richtlinie für EKS Worker-Instanzen auf unter 45% im Cloud Watch-Alarm eingestellt. Scale-up-Metriken für Pods auf über 70% im HorizontalPodAutoscaler eingestellt.
- 40% der Bilder wurden in den Ordner input/grayscale hochgeladen. 40% der Bilder wurden in den Ordner input/thumbnail hochgeladen. 20% der Bilder wurden in den Ordner input/watermark hochgeladen. Scale-up-Richtlinie für EKS Worker-Instanzen auf über 65% im Cloud Watch-Alarm gesetzt. Scale-down-Richtlinie für EKS Worker-Instanzen auf unter 45% im Cloud Watch-Alarm gesetzt. Scale-up-Metriken für Pods auf über 70% im HorizontalPodAutoscaler gesetzt.
- 40% der Bilder wurden in den Ordner input/grayscale hochgeladen. 40% der Bilder wurden in den Ordner input/thumbnail hochgeladen. 20% der Bilder wurden in den Ordner input/watermark hochgeladen. Scale-up-Richtlinie für EKS Worker-Instanzen auf über 65% im Cloud Watch-Alarm gesetzt. Scale-down-Richtlinie für EKS Worker-Instanzen auf unter 45% im Cloud Watch-Alarm gesetzt. Scale-up-Metriken für Pods auf über 50% im HorizontalPodAutoscaler gesetzt.
- 40% der Bilder wurden in den Ordner input/grayscale hochgeladen. 40% der Bilder wurden in den Ordner input/thumbnail hochgeladen. 20% der Bilder wurden in den Ordner input/watermark hochgeladen. Scale-up-Richtlinie für EKS Worker-Instanzen auf über 65% im Cloud Watch-Alarm gesetzt. Scale-down-Richtlinie für EKS Worker-Instanzen auf unter 45% im Cloud Watch-Alarm gesetzt. Scale-up-Metriken für Pods auf über 30% im HorizontalPodAutoscaler gesetzt.
In der folgenden Tabelle finden Sie die Testergebnisse für die erste Gruppe, z. B. die Dauer der Bildverarbeitung, die Dauer der Skalierung der Pods für jede Bereitstellung und die Anzahl der EKS Worker-Instanzen, die skaliert wurden.
| Dauer [s] Testfall | Dauer der Bildverarbeitung [s] | Graustufen-Pods/Verarbeitungszeit [s] | Thumbnail Pods/Verarbeitungszeit [s] | Wasserzeichen Pods/Verarbeitungszeit [s] | EKS Worker Instanzen skalieren die Dauer zwischen den Alarmen [s] | EKS Worker Instanz maximale Anzahl |
|---|---|---|---|---|---|---|
| 1 | 550 | - | - | 16/550 | 21-121 | 4 |
| 2 | 670 | 8/372 | 4/653 | 4/283 | 20-185 | 4 |
| 3 | 754 | 16/573 | 7/748 | 4/257 | 37-152 | 5* |
| 4 | 650 | 16/342 | 8/646 | 8/344 | 49-15 | 5* |
* Letzte Instanz am Ende oder nach der Verarbeitung hinzugefügt
Wie aus der Tabelle hervorgeht, hatte eine Änderung des Schwellenwerts für den HorizontalPodAutoscaler einen spürbaren Einfluss auf die Testergebnisse. Wir hatten erwartet, dass nach einer Verringerung des Alarmschwellenwerts die Bildverarbeitungszeit geringer sein würde als bei dem größeren Schwellenwert. Vergleicht man die Fälle 1 und 3, wobei der Schwellenwert für den Testfall 3 um 20 % niedriger ist, erhöht sich die Bildverarbeitungszeit im Allgemeinen um fast 200 Sekunden.
Wir können auch feststellen, dass in den Fällen 3 und 4, in denen die Schwellenwerte angemessen bei 50% und 30% lagen, ein Problem bei der Erstellung zusätzlicher Worker-Instanzen nach Abschluss der Bildverarbeitung auftrat. Diese Situation hängt möglicherweise mit der Standardzeit für das Abrufen der Nutzungsdaten des Pods zusammen. Wenn Sie den Schwellenwert auf oder unter 50 setzen, gibt Kubernetes das Signal, ein paar Container hinzuzufügen, auch wenn die Verarbeitung abgeschlossen ist oder der Bedarf an zusätzlichen Pods übertrieben ist.
Es ist auch erwähnenswert, dass Autoscaler für den Einsatz von Graustufen in Szenario 3 und 4 16 Replikate erstellt hat. Das ist etwa zwei Mal so viel wie bei Watermark und Thumbnail. Bei einer ersten Bewertung des Dashboards haben wir festgestellt, dass alle Anwendungen ähnliche Ressourcenanforderungen haben, so dass dieses Missverhältnis einer genaueren Untersuchung bedarf. Das optimalste unter den Testszenarien aus dieser Gruppe scheint eine Konfiguration ähnlich dem zweiten Szenario zu sein - ich würde jedoch vorschlagen, die Skalierungsrichtlinie für den Cloud Watch-Alarm auf etwa 75-80% einzustellen, da 4 Instanzen für 16 Pods etwas zu viel sind und die Kosten unnötig erhöhen.
INSTANZ/CPU - POD/CPU
- 100% der Bilder wurden in den Ordner input/watermark hochgeladen. Scale-up-Richtlinie für EKS Worker-Instanzen im Cloud Watch-Alarm auf über 50% gesetzt. Scale-down-Richtlinie für EKS Worker-Instanzen im Cloud Watch-Alarm auf unter 30% gesetzt. Scale-up-Metriken für Pods im HorizontalPodAutoscaler auf über 70% gesetzt.
- 40% der Bilder wurden in den Ordner input/grayscale hochgeladen. 40% der Bilder wurden in den Ordner input/thumbnail hochgeladen. 20% der Bilder wurden in den Ordner input/watermark hochgeladen. Scale-up-Richtlinie für EKS Worker-Instanzen im Cloud Watch-Alarm auf über 50% gesetzt. Scale-down-Richtlinie für EKS Worker-Instanzen im Cloud Watch-Alarm auf unter 30% gesetzt. Scale-up-Metriken für Pods im HorizontalPodAutoscaler auf über 70% gesetzt.
- 40% der Bilder wurden in den Ordner input/grayscale hochgeladen. 40% der Bilder wurden in den Ordner input/thumbnail hochgeladen. 20% der Bilder wurden in den Ordner input/watermark hochgeladen. Scale-up-Richtlinie für EKS Worker-Instanzen im Cloud Watch-Alarm auf über 50% gesetzt. Scale-down-Richtlinie für EKS Worker-Instanzen im Cloud Watch-Alarm auf unter 30% gesetzt. Scale-up-Metriken für Pods im HorizontalPodAutoscaler auf über 50% gesetzt.
- 40% der Bilder wurden in den Ordner input/grayscale hochgeladen. 40% der Bilder wurden in den Ordner input/thumbnail hochgeladen. 20% der Bilder wurden in den Ordner input/watermark hochgeladen. Scale-up-Richtlinie für EKS Worker-Instanzen im Cloud Watch-Alarm auf über 50% gesetzt. Scale-down-Richtlinie für EKS Worker-Instanzen im Cloud Watch-Alarm auf unter 30% gesetzt. Scale-up-Metriken für Pods im HorizontalPodAutoscaler auf über 30% gesetzt.
Die folgende Tabelle zeigt die Testergebnisse für die zweite Gruppe.
| Dauer [s] Testfall | Dauer der Bildverarbeitung [s] | Graustufen-Pods/Verarbeitungszeit [s] | Thumbnail Pods/Verarbeitungszeit [s] | Wasserzeichen Pods/Verarbeitungszeit [s] | EKS Worker Instanzen skalieren Dauer zwischen Alarmen [s] | EKS Worker Instanz maximale Anzahl |
|---|---|---|---|---|---|---|
| 1 | 1040 | - | - | (12-18)*/1040 | 23-180 | 3** |
| 2 | 623 | 8/506 | 6/377 | 6/228 | 20-145 | 4 |
| 3 | 530 | 8/462 | 6/439 | 8/520 | 53-180 | 5 |
| 4 | 556 | (26-32)*/429 | 8/347 | 6/507 | 54-161 | 6* |
* Letzte Instanz am Ende oder nach der Verarbeitung hinzugefügt ** Problem mit der Skalierungsoptimierung
Wie aus der Tabelle hervorgeht, scheinen die vorbereiteten Testfälle für die Skalierung der Worker-Instanzen (basierend auf der CPU) für die zweite Gruppe von Ergebnissen problematischer zu sein, und im Allgemeinen sieht die Infrastruktur dereguliert aus. Bei Szenario 1 und 4 gab es sogar Probleme mit dem Start der gewünschten Anzahl von Pods. Im ersten Szenario liefen 12, obwohl ursprünglich 18 gewünscht waren, und im zweiten Szenario liefen 26 statt der geforderten 32.
Außerdem wurden diese 32 Instanzen überhaupt nicht benötigt und der gesamte Graustufeneinsatz skalierte von 16 auf 26, nachdem die Bilder verarbeitet worden waren. Bei Szenario 1 war die Verarbeitung recht langsam und das Skalierungsmanagement von Worker funktionierte nicht gut.
Von all diesen Konfigurationen würde ich diejenige aus Testszenario Nummer 3 vorschlagen, aber wie bei der vorherigen Zusammenfassung sind weitere Tests willkommen.
Zusammenfassung
Zusammenfassend lässt sich sagen, dass Amazon EKS eine schnelle Methode zur Erstellung von zuverlässigen Clustern und eine einfache Möglichkeit zur Verwaltung der Infrastruktur bietet, ohne sich mit der Kubernetes-Dokumentation zu befassen. Die Erstellung eines Clusters ist jedoch nicht das Ende unserer Arbeit. Das Zusammenspiel aller Komponenten hat einige Zeit in Anspruch genommen und erforderte auch ein tieferes Wissen über k8s.
Ein weiteres Problem, das bei der Verwendung einer Kubernetes-Lösung auftreten kann, ist die Erstellung einer guten Architektur. Für mich persönlich war dieser PoC der erste Versuch, eine Antwort für ein bestimmtes, vorgegebenes Geschäftsszenario zu finden. Ich bin offen für alle Vorschläge und Kommentare, denn der Austausch von Wissen und Gedanken ist immer ein sehr wichtiger Teil der Technologieentwicklung.
Aus der Sicht des Fotounternehmens sind die wichtigsten Faktoren die Zeit bis zur Markteinführung und die Eliminierung des Verwaltungsaufwands, daher ist die beste Option die Verwendung von AWS Fargate. Die Verwendung von EKS erfordert die Einstellung von jemandem, der sich nicht nur mit AWS Cloud, sondern auch mit Kubernetes selbst auskennt. Wenn Sie so jemanden bereits haben, dann ist AWS EKS sicher eine Überlegung wert, denn die Bearbeitungszeit war fast in jedem Szenario die beste. Wenn Änderungen an der Architektur der Anwendung ins Spiel kommen, würden wir dringend empfehlen, eine serverlose Architektur mit AWS-Diensten und Lambdas zu verwenden.
Geschäftsperspektive
Für jede Lösung gibt es mehr als einen Weg. Je nach Ihren genauen Geschäftszielen und Parametern, wie Kosten und Effizienz, ist es hilfreich, alle verfügbaren Optionen zu kennen, um die effizienteste auszuwählen.
Unsere Ideen
Weitere Blogs




Contact