Blog
Redis OM Spring ist 10x schneller - Wie ich zu diesem Open Source Repository beigetragen habe

Alles begann damit, dass ich den Vortrag von Brian Sam-Bodden auf der Spring IO 2022 besuchte, der mich sehr neugierig darauf machte, wie leistungsfähig Redis als primäre Datenbank sein könnte. Der Hauptgrund war die Geschwindigkeit. Ein Schreibvorgang dauert weniger als eine Millisekunde, da die Daten in Redis im Speicher abgelegt sind.
Ich musste das testen. Und da ich Kotlin und Spring verwende. Warum nicht Redis OM Spring verwenden, die Bibliothek, für die Brian in seinem Vortrag plädiert hat und zu der er den größten Beitrag leistet?
Was ich nicht wusste, war, dass diese Neugierde mich zu meinem ersten Open-Source-Beitrag führen würde. Ein Beitrag, der Redis OM Spring half, Daten 10 Mal schneller zu persistieren.

 Das hat meine Neugierde noch mehr geweckt. Ich hatte gerade erst mit Redis angefangen und wusste nicht einmal, was Pipelining ist. Also beschloss ich, das Thema für einen Moment zu vergessen und mich zunächst mit Redis Server, Redis CLI und Redis Insight zu beschäftigen.
Redis OM Spring bietet eine großartige Benutzerfreundlichkeit. Die Abstraktion ist so gut gelungen, dass ich in der Lage war, loszulegen und Redis zu verwenden, noch bevor ich verstanden hatte, wie Redis funktioniert. In diesem Stadium war es jedoch wichtiger, die Grundlagen von Redis zu verstehen.
Und so habe ich es getan. Ich lernte ein paar Dinge, begann mit der lokalen Ausführung von Redis, lernte dann die Grundlagen von Redis CLI, Redis Insight, wie Daten auf der Festplatte persistiert werden, Pipelining, Transaktionen und ein paar andere Dinge. Es ist noch ein langer Weg, aber genug, um mit dem Pipelining auf der Kotlin-Seite zu beginnen.
Das hat meine Neugierde noch mehr geweckt. Ich hatte gerade erst mit Redis angefangen und wusste nicht einmal, was Pipelining ist. Also beschloss ich, das Thema für einen Moment zu vergessen und mich zunächst mit Redis Server, Redis CLI und Redis Insight zu beschäftigen.
Redis OM Spring bietet eine großartige Benutzerfreundlichkeit. Die Abstraktion ist so gut gelungen, dass ich in der Lage war, loszulegen und Redis zu verwenden, noch bevor ich verstanden hatte, wie Redis funktioniert. In diesem Stadium war es jedoch wichtiger, die Grundlagen von Redis zu verstehen.
Und so habe ich es getan. Ich lernte ein paar Dinge, begann mit der lokalen Ausführung von Redis, lernte dann die Grundlagen von Redis CLI, Redis Insight, wie Daten auf der Festplatte persistiert werden, Pipelining, Transaktionen und ein paar andere Dinge. Es ist noch ein langer Weg, aber genug, um mit dem Pipelining auf der Kotlin-Seite zu beginnen.
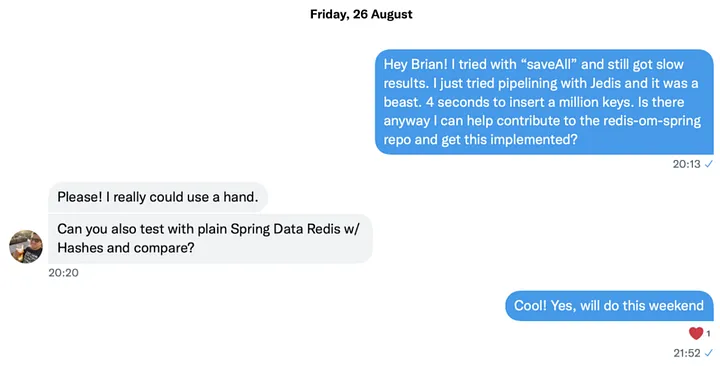 Brian bat mich, auch einen Vergleich mit Spring Data Redis anzustellen. Er wollte verstehen, ob dies etwas ist, was Redis OM Spring geerbt hat.
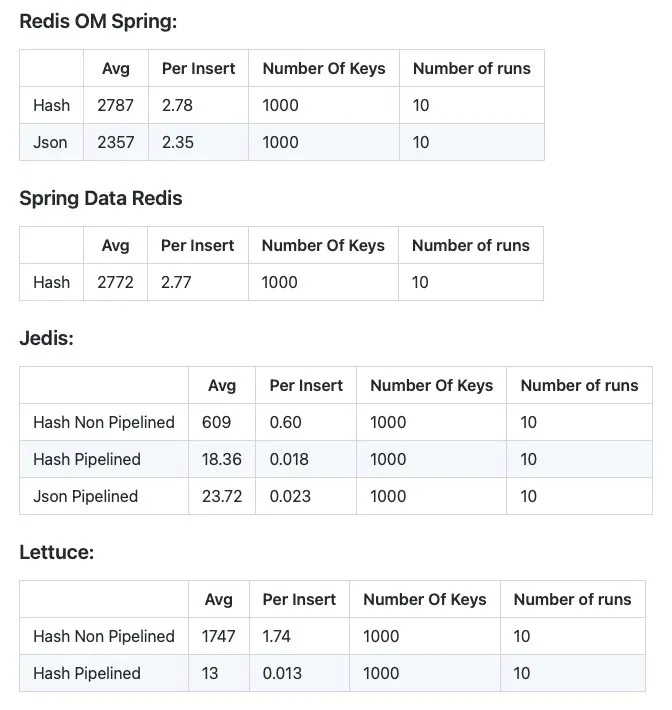
Diese Ergebnisse teilte ich mit ihm und auch in meinem GitHub-Repository(siehe hier):
Brian bat mich, auch einen Vergleich mit Spring Data Redis anzustellen. Er wollte verstehen, ob dies etwas ist, was Redis OM Spring geerbt hat.
Diese Ergebnisse teilte ich mit ihm und auch in meinem GitHub-Repository(siehe hier):
 Bei dieser Übung nutzte ich auch die Gelegenheit, tiefer in die Spring Data Redis- und Redis OM Spring-Implementierungen einzutauchen, was es mir ermöglichte, mit Brian ein Gespräch darüber zu führen, wo ich anfangen sollte.
Brian wies mich auf die richtigen Stellen im Code hin, die ich umgestalten sollte:
Bei dieser Übung nutzte ich auch die Gelegenheit, tiefer in die Spring Data Redis- und Redis OM Spring-Implementierungen einzutauchen, was es mir ermöglichte, mit Brian ein Gespräch darüber zu führen, wo ich anfangen sollte.
Brian wies mich auf die richtigen Stellen im Code hin, die ich umgestalten sollte:
 Das Problem war, dass Redis OM Spring die saveAll-Methoden von Spring Data Redis erbte. Und Spring Data Redis führte eine Einfügung nach der anderen durch und profitierte nicht von der Pipelining-Funktion.
Redis OM Spring erlaubt es uns, sowohl Hashes als auch Dokumente zu manipulieren. Daher mussten wir diese Methode an zwei verschiedenen Stellen überschreiben: SimpleRedisEnhancedRepository und SimpleRedisDocumentRepository.
Das Problem war, dass Redis OM Spring die saveAll-Methoden von Spring Data Redis erbte. Und Spring Data Redis führte eine Einfügung nach der anderen durch und profitierte nicht von der Pipelining-Funktion.
Redis OM Spring erlaubt es uns, sowohl Hashes als auch Dokumente zu manipulieren. Daher mussten wir diese Methode an zwei verschiedenen Stellen überschreiben: SimpleRedisEnhancedRepository und SimpleRedisDocumentRepository.
 com.redis.om.spring.ops.RedisModulesOperations[/caption]
Mit einer Instanz von Jedis in der Hand war ich bereit, die saveAll-Methode zu überschreiben und die neue, schnellere Lösung zu implementieren.
Um diese Aufgabe zu bewältigen, müsste ich jedoch Backward Engineering betreiben und ein wenig besser verstehen, wie Spring Data Redis und Redis OM Spring funktionieren.
com.redis.om.spring.ops.RedisModulesOperations[/caption]
Mit einer Instanz von Jedis in der Hand war ich bereit, die saveAll-Methode zu überschreiben und die neue, schnellere Lösung zu implementieren.
Um diese Aufgabe zu bewältigen, müsste ich jedoch Backward Engineering betreiben und ein wenig besser verstehen, wie Spring Data Redis und Redis OM Spring funktionieren.
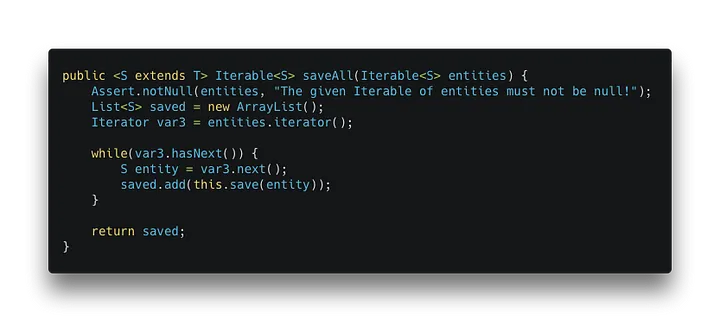 org.springframework.data.keyvalue.repository.support.SimpleKeyValueRepository[/caption]
Die Speichermethode überprüft, ob die Entität neu ist und ruft die Insert- oder Update-Methode der KeyValueOperations auf.
[caption id="" align="aligncenter" width="720"]
org.springframework.data.keyvalue.repository.support.SimpleKeyValueRepository[/caption]
Die Speichermethode überprüft, ob die Entität neu ist und ruft die Insert- oder Update-Methode der KeyValueOperations auf.
[caption id="" align="aligncenter" width="720"]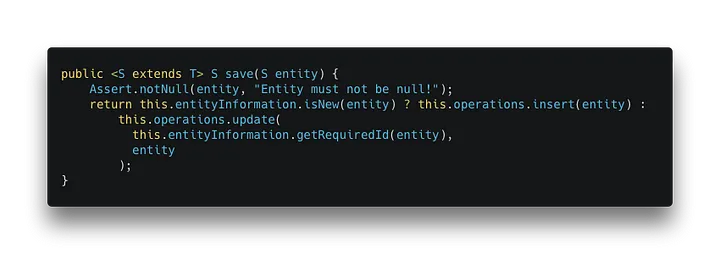 org.springframework.data.keyvalue.repository.support.SimpleKeyValueRepository[/caption]
Die Insert-Methode erzeugt einen neuen Schlüssel, während die Update-Methode den bereits vorhandenen Schlüssel abruft. Unabhängig davon, welche Methode aufgerufen wird, rufen beide am Ende die Put-Methode des KeyValueAdapters auf.
[caption id="" align="aligncenter" width="720"]
org.springframework.data.keyvalue.repository.support.SimpleKeyValueRepository[/caption]
Die Insert-Methode erzeugt einen neuen Schlüssel, während die Update-Methode den bereits vorhandenen Schlüssel abruft. Unabhängig davon, welche Methode aufgerufen wird, rufen beide am Ende die Put-Methode des KeyValueAdapters auf.
[caption id="" align="aligncenter" width="720"]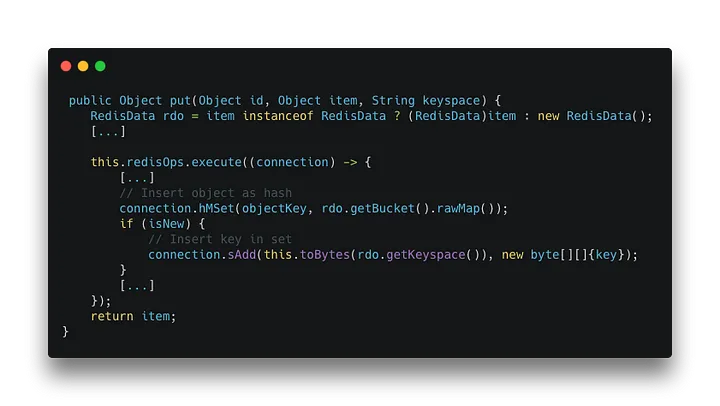 org.springframework.data.keyvalue.repository.support.SimpleKeyValueRepository[/caption]
Die Put-Methode fügt nicht nur einen Schlüssel ein. Sie fügt zwei ein! Einer ist Ihr eigentliches Objekt und der andere ist der Schlüssel als Mitglied der Menge, die alle IDs in der spezifischen Schlüsselmenge enthält.
All dies ist wichtig, um zu verstehen, wie Redis OM Spring funktioniert.
org.springframework.data.keyvalue.repository.support.SimpleKeyValueRepository[/caption]
Die Put-Methode fügt nicht nur einen Schlüssel ein. Sie fügt zwei ein! Einer ist Ihr eigentliches Objekt und der andere ist der Schlüssel als Mitglied der Menge, die alle IDs in der spezifischen Schlüsselmenge enthält.
All dies ist wichtig, um zu verstehen, wie Redis OM Spring funktioniert.
 com.redis.om.spring.repository.support.SimpleEnhancedRedisRepository[/caption]
com.redis.om.spring.repository.support.SimpleEnhancedRedisRepository[/caption]
 com.redis.om.spring.repository.support.SimpleRedisDocumentRepository[/caption]
com.redis.om.spring.repository.support.SimpleRedisDocumentRepository[/caption]
Zusammenfassung
- Einleitung (Wie ich mich entschied und die Chance bekam, einen Beitrag zu leisten)
- Meine Hände werden schmutzig
- Spring Data Redis verstehen (einen Schritt zurückgehen)
- Redis OM Spring verstehen (tiefer eintauchen)
- Überschreiben der saveAll-Methode
- Fazit
Einführung
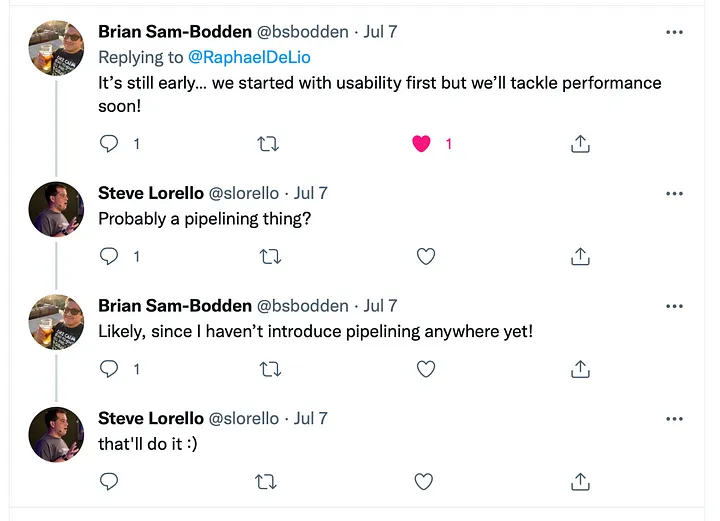
Meine ersten Tests waren etwas frustrierend, die Geschwindigkeit für das Einfügen von 10 Tausend Datensätzen lag bei 35 Sekunden, nicht gerade umwerfend. Also habe ich getwittert: https://twitter.com/raphaeldelio/status/1544781772776423430?s=61&t=lj_QjBsploDve48wDphaVg Dieser Tweet löste einen Thread aus, in dem Brian Sam-Bodden und Steve Lorello mitteilen, dass es wahrscheinlich um Pipelining geht. Außerdem sagte Brian, dass sie sich zuerst um die Benutzerfreundlichkeit und dann um die Leistung kümmern würden.
Das hat meine Neugierde noch mehr geweckt. Ich hatte gerade erst mit Redis angefangen und wusste nicht einmal, was Pipelining ist. Also beschloss ich, das Thema für einen Moment zu vergessen und mich zunächst mit Redis Server, Redis CLI und Redis Insight zu beschäftigen.
Redis OM Spring bietet eine großartige Benutzerfreundlichkeit. Die Abstraktion ist so gut gelungen, dass ich in der Lage war, loszulegen und Redis zu verwenden, noch bevor ich verstanden hatte, wie Redis funktioniert. In diesem Stadium war es jedoch wichtiger, die Grundlagen von Redis zu verstehen.
Und so habe ich es getan. Ich lernte ein paar Dinge, begann mit der lokalen Ausführung von Redis, lernte dann die Grundlagen von Redis CLI, Redis Insight, wie Daten auf der Festplatte persistiert werden, Pipelining, Transaktionen und ein paar andere Dinge. Es ist noch ein langer Weg, aber genug, um mit dem Pipelining auf der Kotlin-Seite zu beginnen.
Die Architektur von Redis OM Spring
Redis OM Spring basiert auf Spring Data Redis, das wiederum auf Jedis oder Lettuce aufbaut, zwei verschiedenen Treibern für die Verbindung von Java mit einem Redis-Server. Lettuce scheint leistungsfähiger zu sein, da es asynchrone Aufrufe und Clusterisierung ermöglicht, mit denen ich mich noch nicht beschäftigt habe. Jedis ermöglicht das Pipelining von Befehlen - alles, was ich brauchte. Ich habe mich für Jedis entschieden. Jedis ist sehr einfach zu bedienen. Sie senden die Befehle so, wie Sie sie auch an den Server senden würden. Um zum Beispiel einen einfachen String-Schlüssel zu setzen, müssen Sie nur Folgendes tun:jedis.set("key", "value");Pipeline pipeline = jedis.pipelined();
pipeline.set("key1", "value1");
pipeline.set("key2", "value2");
pipeline.sync();Meine Hände werden schmutzig
Wie Brian vorgeschlagen hat, habe ich damit begonnen, einen Getter für den Redis-Client in RedisModulesOperations zu implementieren: [caption id="" align="aligncenter" width="496"] com.redis.om.spring.ops.RedisModulesOperations[/caption]
Mit einer Instanz von Jedis in der Hand war ich bereit, die saveAll-Methode zu überschreiben und die neue, schnellere Lösung zu implementieren.
Um diese Aufgabe zu bewältigen, müsste ich jedoch Backward Engineering betreiben und ein wenig besser verstehen, wie Spring Data Redis und Redis OM Spring funktionieren.
Spring Data Redis verstehen
Wenn Sie die saveAll-Methode in Spring Data Redis mit einer Sammlung von Entitäten aufrufen, durchläuft sie die Entitäten und ruft die Speichermethode für jede einzelne von ihnen auf: [caption id="" align="aligncenter" width="720"] org.springframework.data.keyvalue.repository.support.SimpleKeyValueRepository[/caption]
Die Speichermethode überprüft, ob die Entität neu ist und ruft die Insert- oder Update-Methode der KeyValueOperations auf.
[caption id="" align="aligncenter" width="720"] org.springframework.data.keyvalue.repository.support.SimpleKeyValueRepository[/caption]
Die Insert-Methode erzeugt einen neuen Schlüssel, während die Update-Methode den bereits vorhandenen Schlüssel abruft. Unabhängig davon, welche Methode aufgerufen wird, rufen beide am Ende die Put-Methode des KeyValueAdapters auf.
[caption id="" align="aligncenter" width="720"] org.springframework.data.keyvalue.repository.support.SimpleKeyValueRepository[/caption]
Die Put-Methode fügt nicht nur einen Schlüssel ein. Sie fügt zwei ein! Einer ist Ihr eigentliches Objekt und der andere ist der Schlüssel als Mitglied der Menge, die alle IDs in der spezifischen Schlüsselmenge enthält.
All dies ist wichtig, um zu verstehen, wie Redis OM Spring funktioniert.
Redis OM Spring verstehen
In Redis OM Spring haben wir zwei neue Schlüsseladapter implementiert. Einen für Enhanced Hash-Operationen und einen weiteren für JSON-Operationen. Wir haben auch zwei neue Repositories implementiert. Eines für Enhanced Hash-Operationen und ein weiteres für JSON-Operationen. Die Schlüsseladapter werden die Put-Methode überschreiben. Allerdings überschrieben die Repositories nicht die saveAll-Methoden der ursprünglichen Implementierung. Wie wir bereits gesehen haben, ruft die ursprüngliche saveAll-Methode die ursprüngliche save-Methode auf. Das bedeutet, dass wir eine Entität nach der anderen eingefügt haben. Daher mussten wir die saveAll-Methoden in den Repositories überschreiben, um die Befehle in die Pipeline einfügen zu können. Die Implementierung des erweiterten Key Adapters für Hash-Operationen in Redis OM Spring war sehr ähnlich wie bei Spring Data Redis. Bei den JSON-Operationen hingegen war es etwas schwieriger. Der Grund dafür ist Spring Data Redis unterstützt keine Operationen in JSON. Dies ist einer der vielen Vorteile von Redis OM Spring. Die Implementierung der Put-Methode im Key Adapter für JSON-Operationen stützt sich auf eine dritte Bibliothek: die JRedisJSON-Bibliothek (Sie können sie hier einsehen), die die Funktionalität von Jedis um JSON-Befehle erweitert. Leider konnte ich die bereits in der Bibliothek implementierten Methoden nicht wiederverwenden, da sie nicht vom Pipelining profitierten. Ich musste die Implementierung kopieren, die im Wesentlichen darin bestand, benutzerdefinierte Befehle über Jedis an Redis zu senden. Ich habe zwei Iterationen gebraucht, um zu dem Stadium zu gelangen, in dem sich die Methoden derzeit befinden. Im ersten Durchgang habe ich weder die Verfallszeit der Schlüsselwerte noch die Verarbeitung der Audit-Anmerkungen berücksichtigt.Audit-Anmerkungen
Dies ist eine coole Funktion von Redis OM Spring, mit der Sie verfolgen können, wann eine Änderung an einer Entität erfolgt. Sie müssen Ihre Entitätsklassen mit Auditing-Metadaten ausstatten, um von dieser Funktion zu profitieren. Erfahren Sie hier mehr.Überschreiben der saveAll-Methode in Redis OM Spring
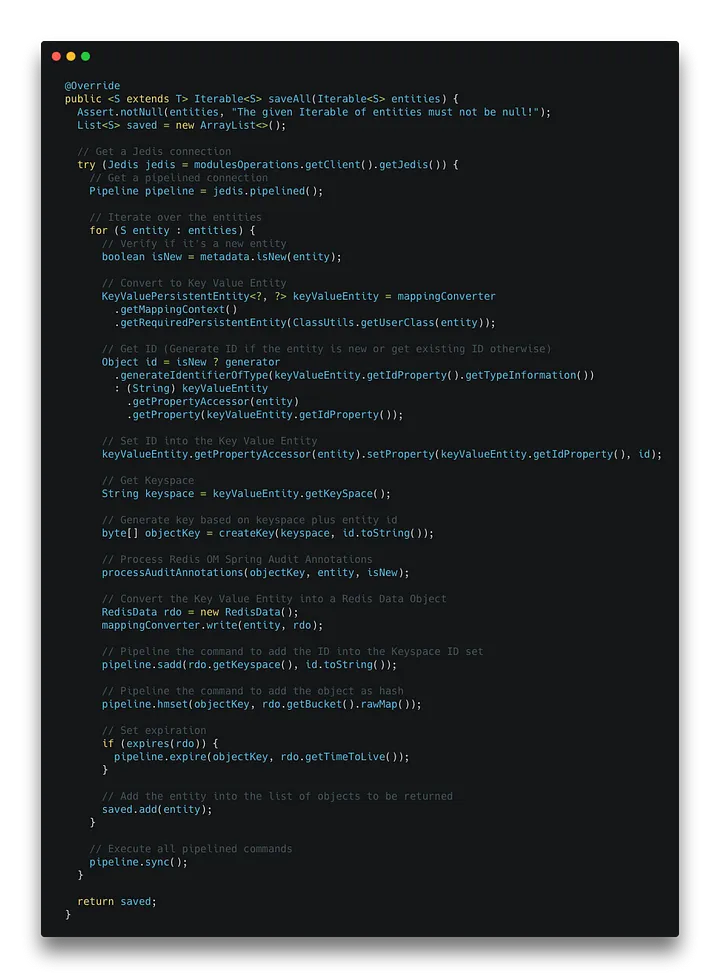
Mit einem etwas besseren Verständnis von Spring Data Redis und Redis OM Spring war ich in der Lage, die Methoden in Redis OM Spring zu überschreiben. Ich müsste die Methode in zwei verschiedenen Repositories überschreiben: SimpleRedisEnhancedRepository und SimpleRedisDocumentRepository. Ich habe mich entschieden, mit dem Repository für Hash-Operationen, SimpleRedisEnhancedRepository, zu beginnen. SimpleRedisEnhancedRepository Die Implementierung der Methode ist ziemlich einfach. Die saveAll-Methode empfängt eine Iterable von Entitäten. Wir erhalten eine Jedis-Verbindung, starten eine Pipeline und iterieren über die Entitäten. In der Iteration prüfen wir, ob die Entität neu ist, erstellen gegebenenfalls einen neuen Schlüssel, verarbeiten die Audit-Anmerkungen und leiten die Befehle zum Einfügen des Schlüssels in die Schlüsselmenge des jeweiligen Schlüsselraums und des Objekts als Hash ein. Dann prüfen wir, ob für das Objekt eine Verfallszeit definiert ist und führen den Befehl aus, um sie festzulegen. Schließlich, nachdem wir alle Objekte durchlaufen haben, führen wir die Befehle in der Pipeline aus. [caption id="" align="aligncenter" width="720"] com.redis.om.spring.repository.support.SimpleEnhancedRedisRepository[/caption]
SimpleRedisDocumentRepository
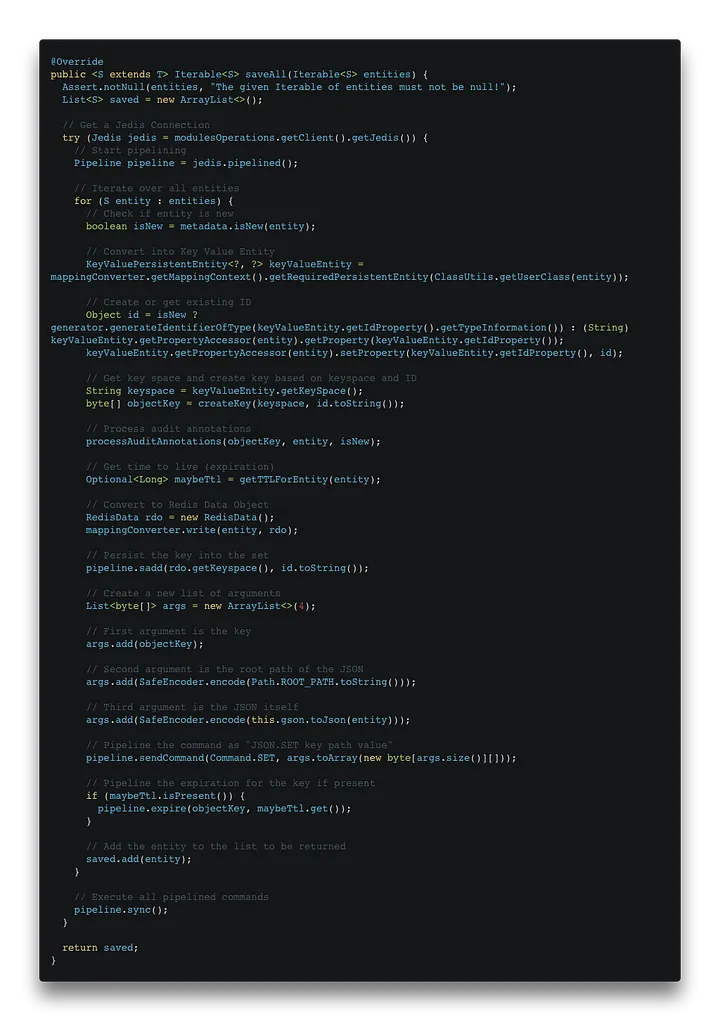
Kurz gesagt, das Überschreiben der saveAll-Methode ist im Grunde dasselbe wie das Hash-Repository. Die Methode saveAll empfängt eine Iterable von Entitäten. Wir erhalten eine Jedi-Verbindung, starten eine Pipeline und iterieren über die Entitäten. In der Iteration prüfen wir, ob die Entität neu ist, erstellen gegebenenfalls einen neuen Schlüssel, verarbeiten die Audit-Anmerkungen und leiten die Befehle zum Einfügen des Schlüssels in den Schlüsselsatz des jeweiligen Schlüsselraums und des Objekts als JSON weiter. Dann prüfen wir, ob für das Objekt eine Verfallszeit definiert ist und führen den Befehl aus, um sie festzulegen. Schließlich, nachdem wir alle Objekte durchlaufen haben, führen wir die Befehle in der Pipeline aus. [caption id="" align="aligncenter" width="720"] com.redis.om.spring.repository.support.SimpleRedisDocumentRepository[/caption]
Testen Sie
Da wir neue Funktionen implementiert haben, ist es wichtig, sie testen zu lassen. Redis OM Spring ist bereits ziemlich gut getestet. Ich habe jedoch neue Tests implementiert, um die Verfallszeit der Schlüsselwerte und die Verarbeitung von Audit-Anmerkungen bei Verwendung der saveAll-Methode für beide Repositories zu testen. Ich werde hier nicht auf die Implementierung der Tests eingehen, aber Sie können sie im Merge selbst überprüfen, indem Sie hier klicken.Fazit
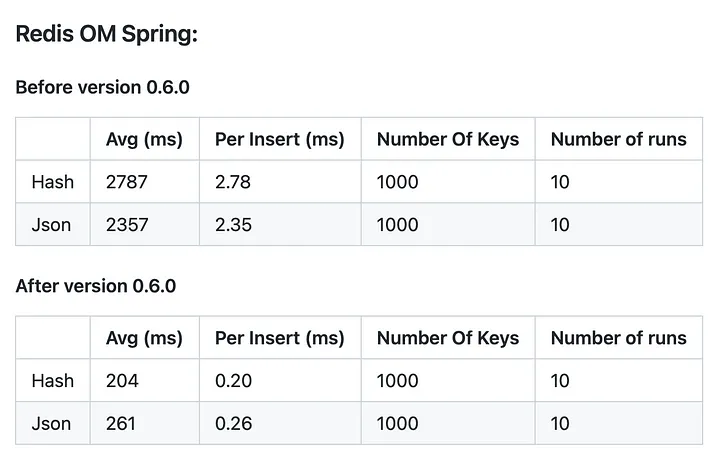
Ich habe die PRs geöffnet, und sie wurden von Brian überprüft und dann zusammengeführt. Mit der Implementierung der saveAll-Methoden konnten wir eine deutliche Verbesserung bei den Einfügungen feststellen. Das Einfügen ist jetzt etwa 10 Mal schneller als vorher. Diese bessere Leistung wurde erreicht, weil in der vorherigen Implementierung saveAll die Elemente iterativ nacheinander gespeichert hat. Bei der neuen Implementierung werden nun alle Befehle in einer Pipeline zusammengefasst und erst dann ausgeführt. So nutzen Sie die Leistung der Jedis voll aus. Diese Funktion wurde in Version 0.6.0 veröffentlicht, und Sie können die Ergebnisse der neuen Implementierung unten sehen:
Links zu Zusammenführungen:
Verfasst von

Raphael De Lio
I talk about technology
Unsere Ideen
Weitere Blogs




Contact
Let’s discuss how we can support your journey.