
Aktualisiert am 22-08-2019: Der Blog wurde aktualisiert, um die neueste Version von Apache Druid und Superset zu verwenden.
In der heutigen Welt wollen Sie so schnell wie möglich von Ihren Kunden lernen. Dieser Blog gibt eine Einführung in die Einrichtung von Streaming-Analysen mit Open-Source-Technologien. Wir verwenden Divolte und Apache {Kafka, Superset, Druid}, um ein System einzurichten, das Ihnen ein tieferes Verständnis für das Verhalten Ihrer Kunden ermöglicht.
Wenn Sie Ihre Analysen in einem Streaming-Verfahren durchführen, können Sie das Verhalten Ihrer Kunden kontinuierlich analysieren und darauf reagieren. Zum Beispiel:
- Wenn wir ein neues Experiment mit A/B-Tests durchführen, möchten wir das Experiment überwachen und die Möglichkeit haben, entweder Experiment A oder B vorzeitig zu beenden, wenn die Ergebnisse zeigen, dass eines der beiden Experimente deutlich besser abschneidet als das andere.
- Alle Aktionen der Benutzer auf Ihrer Online-Website sagen etwas über ihre Absichten aus. Wenn wir in der Lage sind, die Daten sofort zu verarbeiten, können wir die Inhalte auf jeden Benutzer zuschneiden.
- Sammeln Sie allgemeine Informationen über die Nutzung der Anwendung, um Ihre nächsten Iterationen der Anwendung auszurichten.
Dieser Stack kann eine Alternative für z.B. Google Analytics sein und ermöglicht es Ihnen, alle Daten direkt in Ihrer eigenen Umgebung zur Verfügung zu haben und Ihre Daten außerhalb von Drittanbietern zu halten. Die Ereignisse werden von Divolte erfasst, mit Kafka in eine Warteschlange gestellt, in Druid gespeichert und mit Superset visualisiert.
Bevor ich in die Tiefe gehe, möchte ich auf die verwendeten Komponenten eingehen. Dann folgt eine Erklärung, wie Sie das Programm einrichten und mit den Tools spielen können.
Divolte
Divolte Collector ist eine skalierbare und leistungsstarke Anwendung zum Sammeln von Clickstream-Daten und zum Veröffentlichen dieser Daten in einer Senke, wie Kafka, HDFS oder S3. Divolte wurde von GoDataDriven entwickelt und der Öffentlichkeit unter der Apache 2.0 Open Source Lizenz zur Verfügung gestellt.
Divolte kann als Grundlage für den Aufbau von grundlegenden Webanalyse-Dashboards, Echtzeit-Empfehlungsmaschinen oder Banner-Optimierungssystemen verwendet werden. Durch die Verwendung eines JavaScript-Tags im Browser der Kunden sammelt es Daten über deren Verhalten auf der Website oder in der Anwendung. Sie haben die volle Kontrolle darüber, was Sie erfassen möchten und was nicht.
Kafka
Apache™ Kafka ist ein schnelles, skalierbares, dauerhaftes und fehlertolerantes Publish-Subscribe-Messaging-System. Kafka ist bekannt für seinen hohen Durchsatz, seine Zuverlässigkeit und Replikation. Kafka funktioniert gut in Kombination mit Apache Flink und Apache Spark für die Echtzeitanalyse und das Rendering von Streaming-Daten.
In diesem Setup wird Kafka zum Sammeln und Puffern der Ereignisse verwendet, die dann von Druid aufgenommen werden. Wir benötigen Kafka, um die Daten aufzubewahren und als Puffer zu fungieren, wenn es zu einer Häufung von Ereignissen kommt, wie z.B. bei der Ausstrahlung einer Fernsehwerbung.
Druide
Apache™ Druid ist ein Open-Source-Analysedatenspeicher, der für Business Intelligence (OLAP)-Abfragen auf Ereignisdaten entwickelt wurde. Druid bietet eine geringe Latenz bei der Echtzeit-Datenaufnahme aus Kafka, eine flexible Datenexploration und eine schnelle Datenaggregation.
Druid übernimmt die Verarbeitung der Daten und bringt sie in die von uns gewünschte Form. Bestehende Druid-Implementierungen sind auf Billionen von Ereignissen und Petabytes von Daten skaliert, so dass wir uns um die Skalierung keine Sorgen machen müssen. Druid wurde ursprünglich von Metamarkets entwickelt, wurde aber von Snap, der Muttergesellschaft von Snapchat, aufgekauft. Die Datenbank war bereits quelloffen, wurde aber noch quelloffener, als die Software zur Apache Software Foundation verschoben wurde.
Druid versteht sich nicht als Datensee, sondern als Datenfluss. Während die Daten von den Benutzern oder Sensoren oder was auch immer erzeugt werden, fließen sie in die Anwendungslandschaft. Dort werden sie verarbeitet und fließen in Ihre Datenbank, wo sie direkt für Abfragen zur Verfügung stehen. Wie bei Hive/Presto-Konfigurationen führen Sie oft stündliche oder tägliche Batch-Prozesse durch, aber mit Druid stehen die Daten zur Abfrage bereit, sobald sie in die Datenbank gelangen. Für mich steht dies im Zusammenhang mit dem Konzept der letztendlichen Konsistenz. Im Fall von Druid ist dies eine Sache von Millisekunden, bei der historischen Einrichtung mit nächtlichem ETL kann dies bis zu einem Tag dauern. Dies könnte Ihnen einen erheblichen geschäftlichen Nutzen bringen, wenn Sie in einem Markt tätig sind, in dem Sie schnell handeln müssen.
Auch die Geschwindigkeit der Datenaufnahme ist mit Druid beeindruckend. Jüngste Benchmarks zeigen eine Geschwindigkeitsverbesserung von 90%-98% gegenüber Apache Hive.
Superset
Apache™ Superset ist eine Webanwendung zur Datenexploration und -visualisierung und bietet eine intuitive Schnittstelle zur Erkundung und Visualisierung von Datensätzen und zur Erstellung interaktiver Dashboards. Ursprünglich von Airbnb entwickelt, aber jetzt im Rennen, um ein Apache™ Projekt zu werden.
Erste Schritte
Was macht mehr Spaß, als ein Proof of Concept auf dem eigenen Rechner laufen zu lassen? Mit Docker ist es einfach, eine lokale Instanz des Stacks einzurichten, damit wir ihn ausprobieren und die Möglichkeiten erkunden können.
Um das System einzurichten, beginnen wir mit dem Klonen des Git-Repositorys:
git clone https://github.com/Fokko/divolte-kafka-druid-superset.git cd divolte-kafka-druid-superset git submodule update --init --rekursiv
Wir müssen das git-Submodul initialisieren und aktualisieren, weil wir auf den Kafka-Container meines lieben Kollegen Kris Geusebroek angewiesen sind. Das sind ausgezeichnete Images und warum sollten wir uns die Mühe machen, sie selbst zu entwickeln, wenn sie von der Masse gepflegt werden? Die anderen Images, wie Divolte, Druid und Superset, ziehen wir einfach aus der öffentlichen Docker-Registry.
Als Nächstes müssen wir die Images lokal erstellen und dann starten wir sie. Ich persönlich mag es, die alten Zustände der Bilder explizit zu entfernen, um sicher zu sein, dass es keinen alten Zustand gibt:
docker-compose rm -f && docker-compose build && docker-compose up
Da wir die Images von Grund auf neu erstellen, kann dies eine Weile dauern. Nachdem Sie den Befehl docker-compose up ausgeführt haben, werden die Dienste gebootet. Es kann einige Zeit dauern, bis alles läuft.
Nach ein paar Sekunden können wir einen Browser starten und die Dienste überprüfen:
| Dienst | URL |
|---|---|
| Divolte | http://localhost:8290/ |
| Druid Einheitliche Konsole | http://localhost:8888/ |
| Druiden-Vermächtnis-Konsole | http://localhost:8081/ |
| Superset | http://localhost:8088/ |
| Anwendungsbeispiel | http://localhost:8090/ |
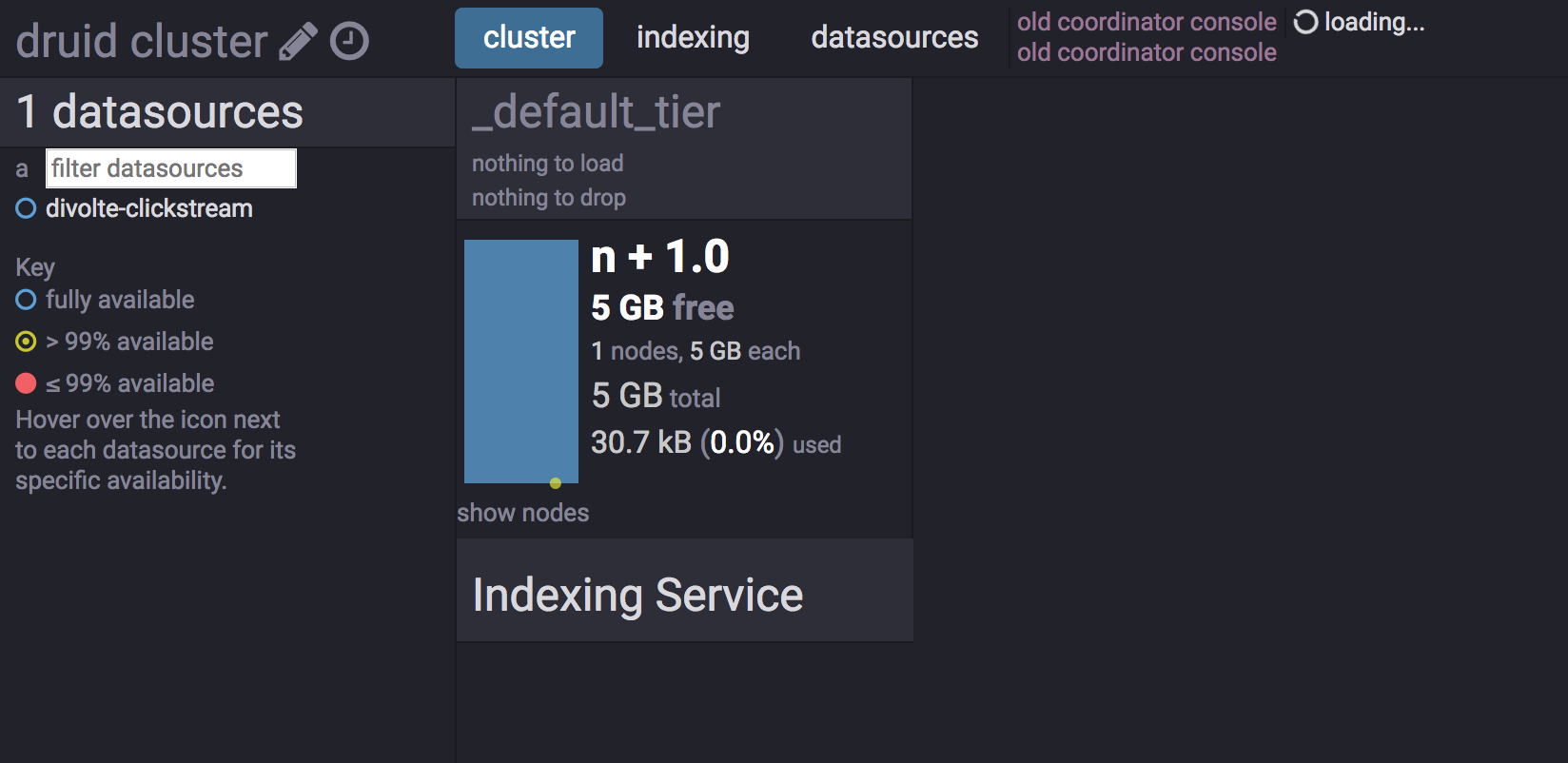
Als nächstes müssen wir Druid mitteilen, dass es auf das richtige Kafka-Thema hören soll. Dies geschieht, indem wir eine Supervisor-Spezifikationsdatei im JSON-Format mit curl an den Indizierungsdienst senden:
curl -X POST -H 'Content-Type: application/json' -d @supervisor-spec.json http://localhost:8081/druid/indexer/v1/supervisor
{"id": "divolte-clickstream"}
Wenn Sie curl nicht installiert haben, können Sie den Streaming-Auftrag auch über die neue Benutzeroberfläche erstellen. Dies geschieht unter
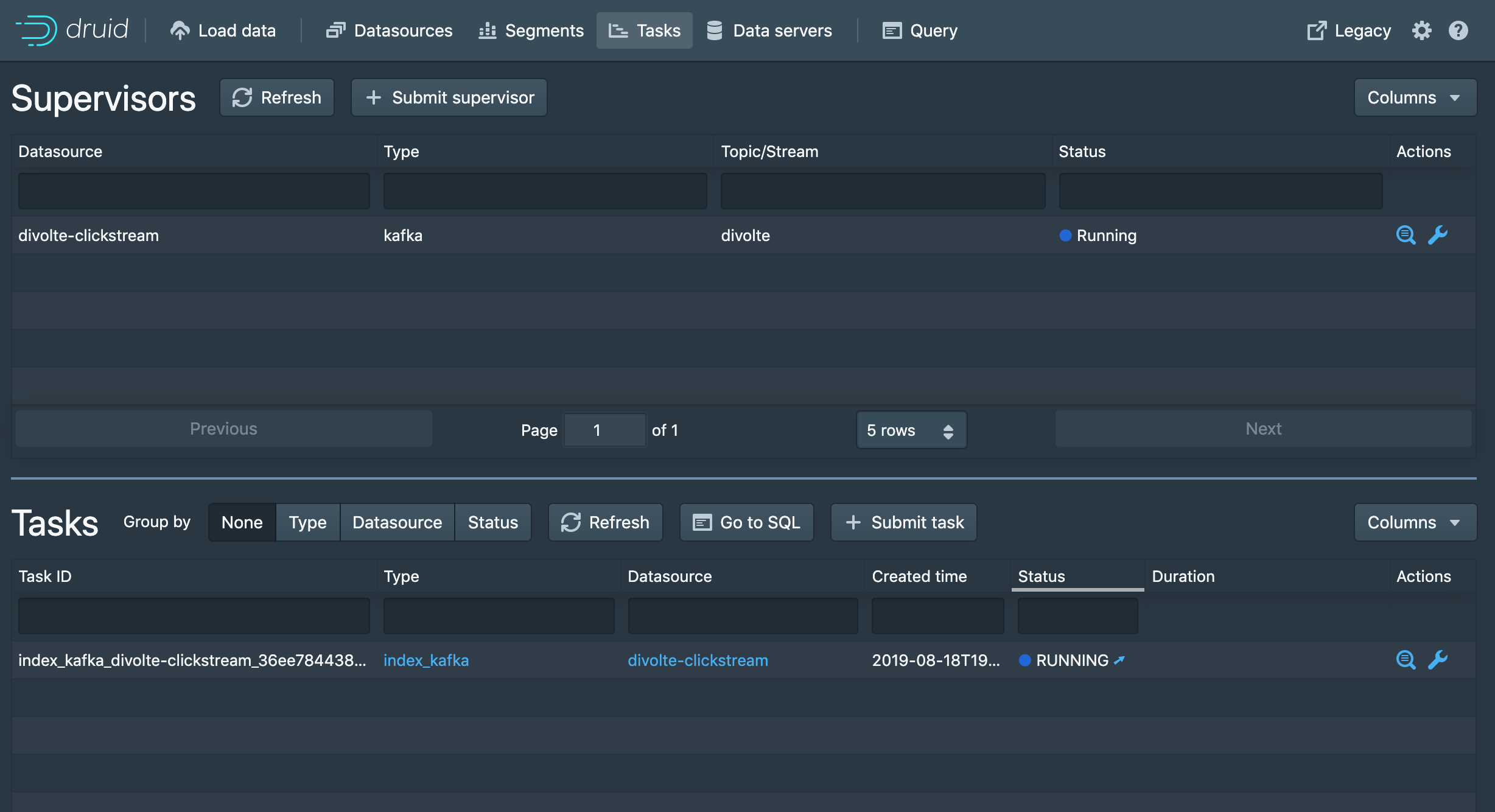
Wie Sie vielleicht bemerken, ist die Druid Restful API sehr skriptfähig und lässt sich gut mit Orchestrierungswerkzeugen wie Apache Airflow integrieren. Für den Fall, dass Sie eine bestimmte Wiederherstellung der Tabelle deaktivieren möchten, wenn sich das Schema ändert, oder wenn Sie eine Batch-Ingestion durchführen möchten.
Wir verwenden eine leicht modifizierte Version des Standardschemas von Divolte Avro. Divolte kann vollständig an die eigenen Bedürfnisse angepasst werden. Für diese Demo haben wir ein zusätzliches Feld namens technology hinzugefügt, das wir zur Demonstration unserer Beispielanwendung verwenden. Für das Schema muss eine in Groovy geschriebene Mapping-Funktion vorhanden sein, mit der die Felder auf der Grundlage der Eingaben gefüllt werden. Wenn Sie sich unsere mapping.groovy ansehen, werden alle Felder aus den Metadaten gefüllt, mit Ausnahme der Technologie, die explizit über ein EventParameter angegeben wird.
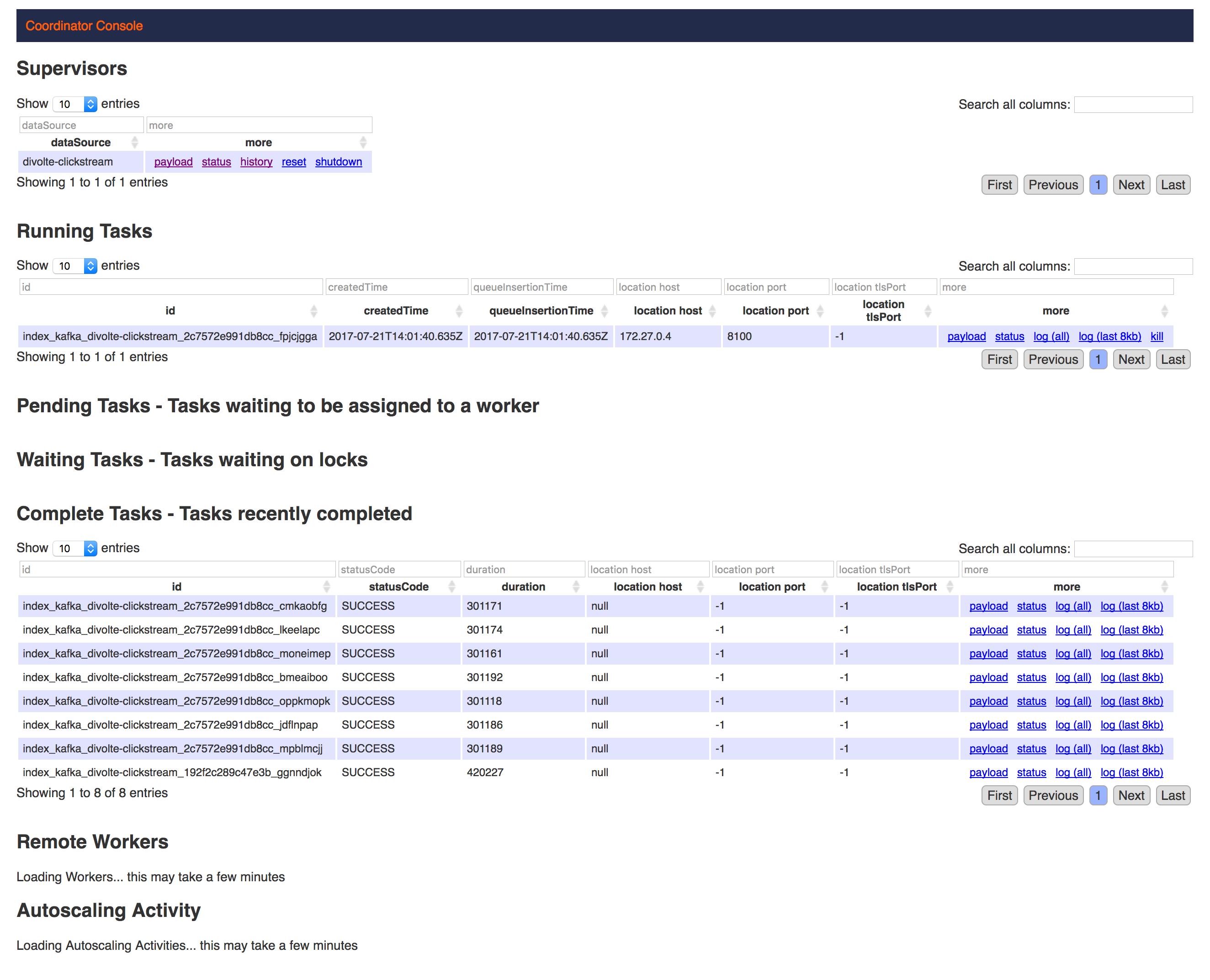
Auf der Indizierungskonsole können wir sehen, dass etwa alle fünf Minuten ein Job gestartet wird. Alle neuen Ereignisse, die über Kafka eingehen, werden direkt im Speicher indiziert und auf dem Heap gehalten. Nach einer bestimmten Zeitspanne werden die Ereignisse auf dem tiefen Speicher, z.B. HDFS oder S3, persistiert. Bevor die Daten gespeichert werden, werden sie in Segmente (standardmäßig 500 MB) gechunked und die Bitmap-Indizes werden berechnet und neben den Daten gespeichert.
Es ist konfigurierbar, wann Bilder in den tiefen Speicher übertragen werden und dies sollte je nach Situation ausgewählt werden. Je höher der Durchsatz, desto kürzer die Zeitspanne. Sie möchten nicht zu viele Ereignisse im Speicher halten, aber Sie möchten auch nicht zu oft persistieren, da kleine Dateien einen Overhead für das Dateisystem bedeuten.
Werfen wir einen Blick auf unsere Beispielanwendung, die in der Lage ist, Ereignisse an Divolte abzufeuern. Divolte unterstützt nicht nur Webanwendungen, sondern auch Desktop-, mobile oder sogar eingebettete Anwendungen - solange Sie in der Lage sind, eine HTTP-Anfrage an Divolte zu senden.
Besuchen Sie die App und klicken Sie auf alle Technologien, die Sie mögen. Das Anklicken erzeugt Ereignisse, die wir später visualisieren werden.

Wenn Sie auf eines der Logos der Technologien klicken, wird die Aktion im Hintergrund mithilfe von Javascript an Divolte weitergeleitet:
// Das erste Argument ist der Ereignistyp; das zweite Argument ist ein JavaScript-Objekt // mit beliebigen Ereignisparametern, die weggelassen werden können divolte.Signal(myCustomEvent'., { param: 'foo', otherParam: 'bar' })
Weitere Informationen zur Konfiguration von Divolte finden Sie im ausgezeichneten Divolte-Leitfaden für weitere Informationen.
Nun, da wir Divolte, Kafka und Druid konfiguriert und einige Ereignisse ausgesendet haben, ist es an der Zeit, Superset zu konfigurieren. Gehen Sie bitte auf Local host Link, da wir unten alle Felder mit druid ausfüllen können, da dies der Alias im mitgelieferten docker-compose ist:
Als nächstes müssen wir die Druid-Datenquelle explizit aktualisieren, indem wir eine bestimmte URL localhost:8088/druid/refresh_datasources/ öffnen, die Sie auch im Menü von Superset finden. Dadurch wird der Druid-Koordinator kontaktiert und nach den verfügbaren Datenquellen und den entsprechenden Schemata gefragt.
Zunächst müssen wir einen neuen Benutzer anlegen:
$ docker-compose exec Obermenge Obermenge-init Benutzername [admin]: Fokko Vorname des Benutzers [admin]: Fokko Nachname des Benutzers [Benutzer]: Driesprong E-Mail [admin@fab.org]: fokko.driesprong@xebia.com Das Passwort: Wiederholen Sie für Bestätigung:
Jetzt ist alles geladen und wir können mit der Erstellung unseres ersten Slice beginnen. Ein Slice in Superset ist ein Diagramm oder eine Tabelle, die in einem oder mehreren Dashboards verwendet werden kann.
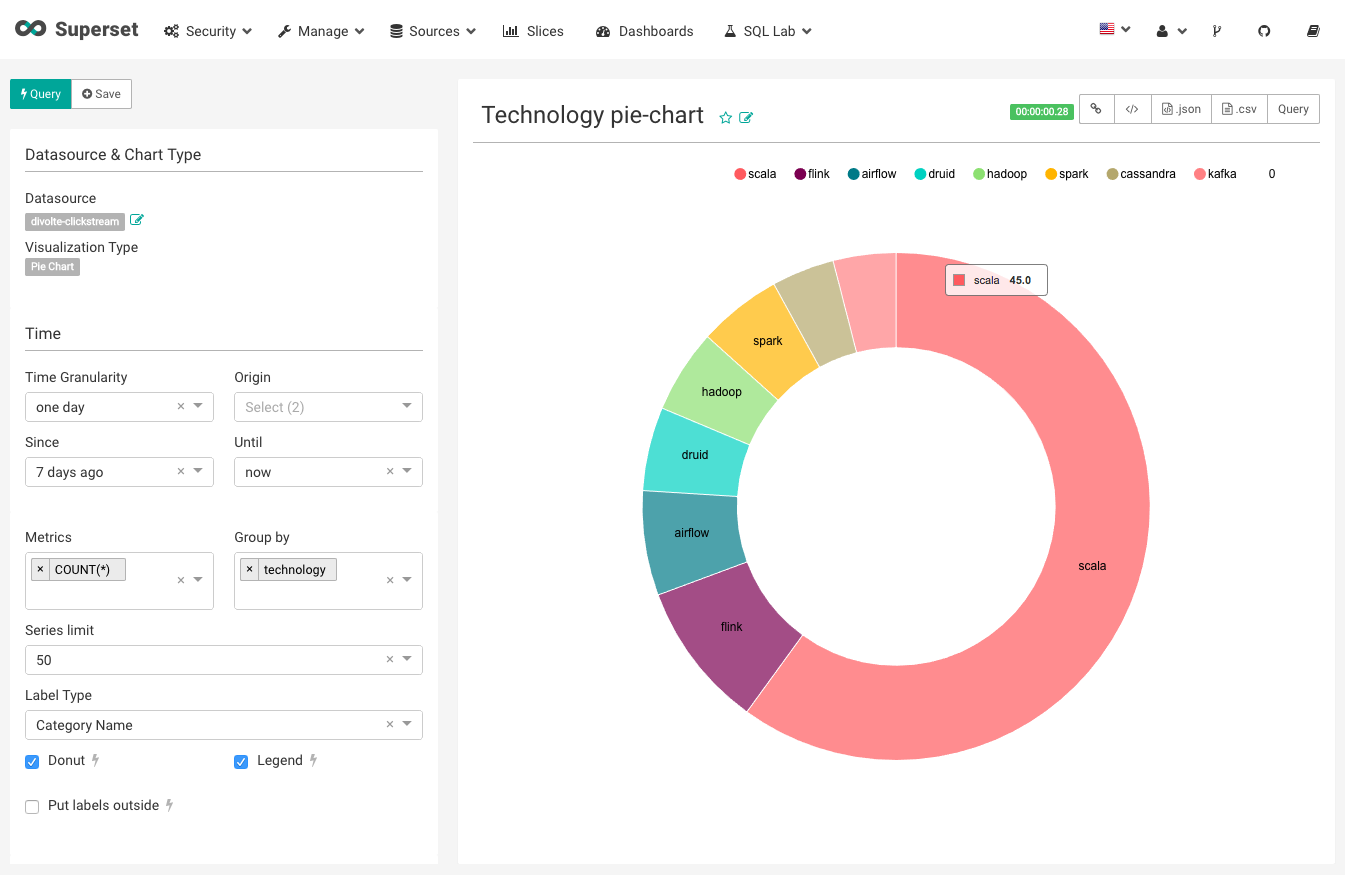
Nachdem Sie ein einfaches Donut-Diagramm wie oben erstellt haben, können Sie die von Divolte in Superset gesammelten Daten leicht visualisieren. Für mich zeigt sich, dass Druid bei weitem die beliebteste Technologie ist! Klicken Sie weiter auf die Logos, um zu sehen, wie sich Ihr Dashboard sofort verändert.
Dies ist natürlich ein sehr einfaches Beispiel, aber mit Druid ist es einfach, die Aktivität jeder Technologie im Laufe der Zeit grafisch darzustellen. Auch recht komplexe Verarbeitungsaktivitäten lassen sich mit Superset leicht visualisieren, wenn Sie Divolte Event richtig implementieren.
Dieses Beispiel zeigt den Stack aus Divolte, Kafka, Druid und Superset. Wenn Sie dies in die Produktion überführen wollen, hilft Ihnen dieses Set von Docker-Images nicht weiter: Sie müssen einen richtigen Kafka- und Druid-Cluster einrichten. Superset benötigt nicht viele Ressourcen, da Druid die schwere Gruppierung und Filterung der Daten übernimmt. Divolte ist dafür bekannt, dass es mit einer einzigen Instanz viele Anfragen bewältigen kann, aber es ist auch möglich, dies hinter einem umgekehrten Proxy wie Nginx oder HAproxy unterzubringen.
Während ich diesen Blog schrieb, habe ich einige Pull Requests eingereicht, nämlich 3174, 3252 und 3266. Das zeigt die Schönheit von Open-Source-Software: Wenn Sie auf Probleme stoßen, gehen Sie dem Kaninchenbau auf den Grund, finden den Fehler, bringen eine Korrektur ein und machen die Welt noch schöner.
Außerdem haben wir zusammen mit einem unserer Kunden einen Scala-Client für Apache Druid entwickelt, der der Öffentlichkeit zugänglich gemacht wurde. Die ING-Bank benötigte eine bequeme Möglichkeit, Abfragen zu erstellen, und so entstand das Scruid-Projekt = (Scala + Druid).
Lernen Sie Spark oder Python in nur einem Tag
Entwickeln Sie Ihre Data Science-Fähigkeiten. **Online**, unter Anleitung am 23. oder 26. März 2020, 09:00 - 17:00 CET.
Sie möchten praktische Erfahrungen mit A/B-Tests sammeln?
Nehmen Sie an unserem Kurs A/B-Tests und Experimente teil, in dem Sie alles lernen, was Sie brauchen, um perfekte A/B-Tests einzurichten und durchzuführen.



Contact