Blog
RAG auf GCP: Produktionsfähiges GenAI auf der Google Cloud Platform

Einführung
Google Cloud Platform verfügt über ein wachsendes Angebot an verwalteten Diensten, mit denen Sie produktionsreife Retrieval-Augmented Generation-Anwendungen erstellen können. Dienste wie Vertex AI Search & Conversation und Vertex AI Vector Search bieten uns Skalierbarkeit und Benutzerfreundlichkeit. Wie können Sie sie am besten nutzen, um RAG-Anwendungen zu erstellen? Lassen Sie uns das gemeinsam erkunden. Lesen Sie mit!
Abruf Erweiterte Generation
Obwohl der Begriff Retrieval-Augmented Generation(RAG) bereits im Jahr 2020 geprägt wurde, hat die Technik seit dem Aufkommen der Large Language Models(LLMs) einen neuen Aufschwung erfahren. Bei RAG werden LLMs mit Suchtechniken wie der Vektorsuche kombiniert, um eine effiziente Echtzeitsuche nach Informationen zu ermöglichen, die außerhalb des Wissens des Modells liegen. Dies eröffnet viele aufregende neue Möglichkeiten. Während früher die Interaktion mit LLMs auf das Wissen des Modells beschränkt war, ist es mit RAG nun möglich, unternehmensinterne Daten wie Wissensdatenbanken einzubinden. Außerdem können Halluzinationen reduziert werden, indem das LLM angewiesen wird, seine Antwort immer auf der Grundlage von Fakten zu geben.
Warum RAG?
Lassen Sie uns zunächst einen Schritt zurückgehen. Wie genau können wir von RAG profitieren? Wenn wir mit einem LLM interagieren, ist sein gesamtes Faktenwissen in den Modellgewichten gespeichert. Die Modellgewichte werden während der Trainingsphase festgelegt, die eine Weile zurückliegen kann. Das kann sogar mehr als ein Jahr sein.
| LLM | Wissen cut-off |
|---|---|
| Zwilling 1.0 Pro | Anfang 2023 1 |
| GPT-3.5-Turbo | September 2021 [2] |
| GPT-4 | September 2021 [3] |
Wissensabstände ab März 2024.
Außerdem werden diese öffentlich angebotenen Modelle meist auf öffentlichen Daten trainiert. Wenn Sie unternehmensinterne Daten verwenden möchten, besteht eine Option darin, das Modell zu verfeinern oder neu zu trainieren, was teuer und zeitaufwändig sein kann.
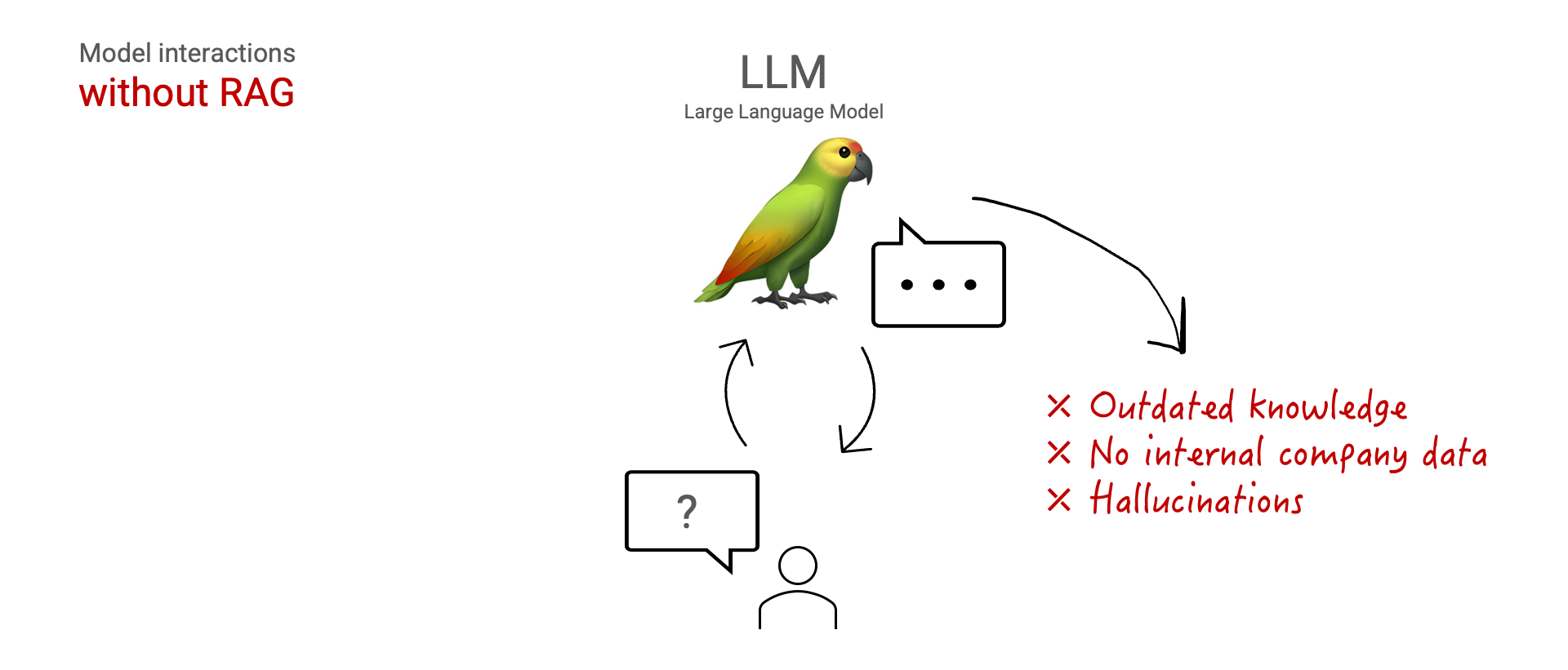
Dies ist auf drei wesentliche Einschränkungen zurückzuführen: Das Wissen des Modells ist veraltet, das Modell hat keinen Zugriff auf interne Daten und das Modell kann Antworten halluzinieren.
Mit RAG können wir diese Einschränkungen umgehen. Angesichts der Frage, die ein Benutzer hat, können zunächst die für diese Frage relevanten Informationen abgerufen werden, um sie dann dem LLM zu präsentieren.
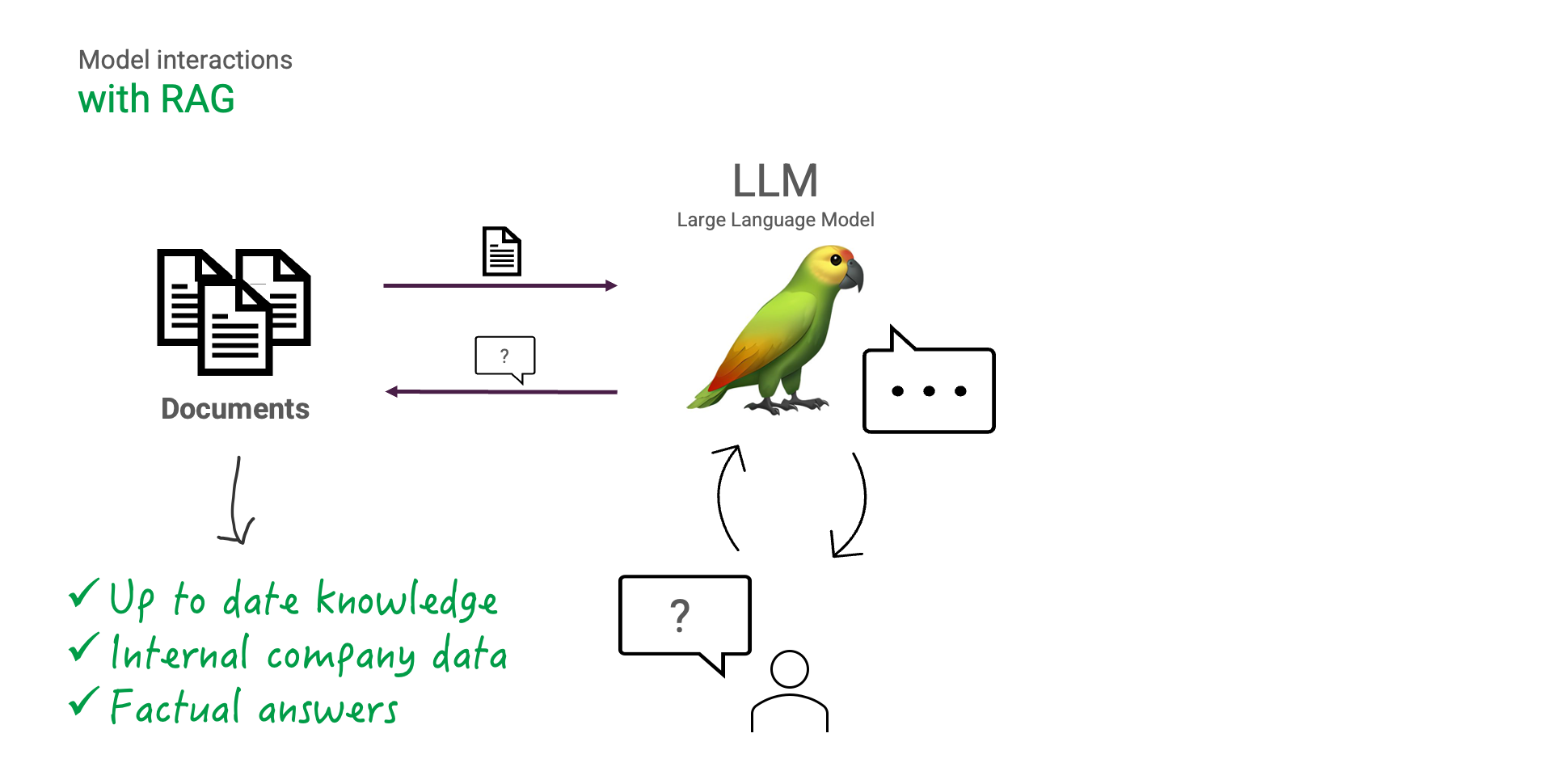
Der LLM kann dann seine Antwort mit den abgerufenen Informationen ergänzen, um eine sachliche, aktuelle und dennoch für den Menschen verständliche Antwort zu erzeugen. Der LLM sollte angewiesen werden, seine Antwort stets auf die abgerufenen Informationen zu stützen, um Halluzinationen zu vermeiden.
Diese Vorteile sind großartig. Aber wie bauen wir eigentlich ein RAG-System auf?
Aufbau eines RAG-Systems
In einem RAG-System gibt es zwei Hauptschritte: 1) Abrufen von Dokumenten und 2) Generierung von Antworten. Während die Dokumentensuche dafür zuständig ist, die relevantesten Informationen zur Frage des Benutzers zu finden, ist die Antwortgenerierung dafür verantwortlich, eine für den Menschen lesbare Antwort auf der Grundlage der im Suchschritt gefundenen Informationen zu generieren. Schauen wir uns beides einmal genauer an.
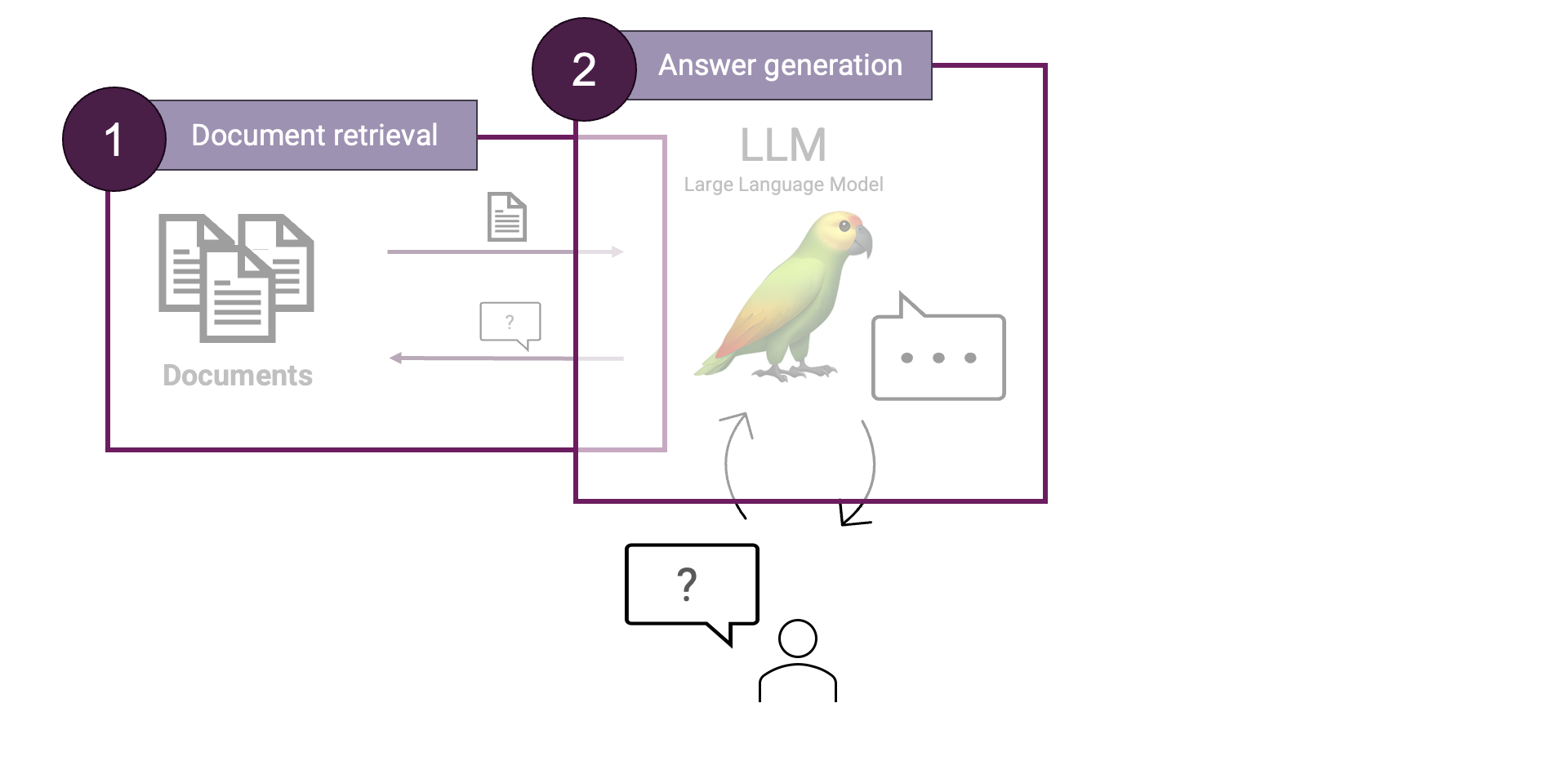
Abrufen von Dokumenten
Erstens: Abrufen von Dokumenten. Die Dokumente werden in Klartext umgewandelt und in Chunks unterteilt. Die Chunks werden dann eingebettet und in einer Vektordatenbank gespeichert. Auch die Fragen des Benutzers werden eingebettet, so dass eine vektorielle Ähnlichkeitssuche möglich ist, um die am besten passenden Dokumente zu finden. Optional kann ein Schritt hinzugefügt werden, um Dokument-Metadaten wie Titel, Autor, Zusammenfassung, Schlüsselwörter usw. zu extrahieren, die anschließend für eine
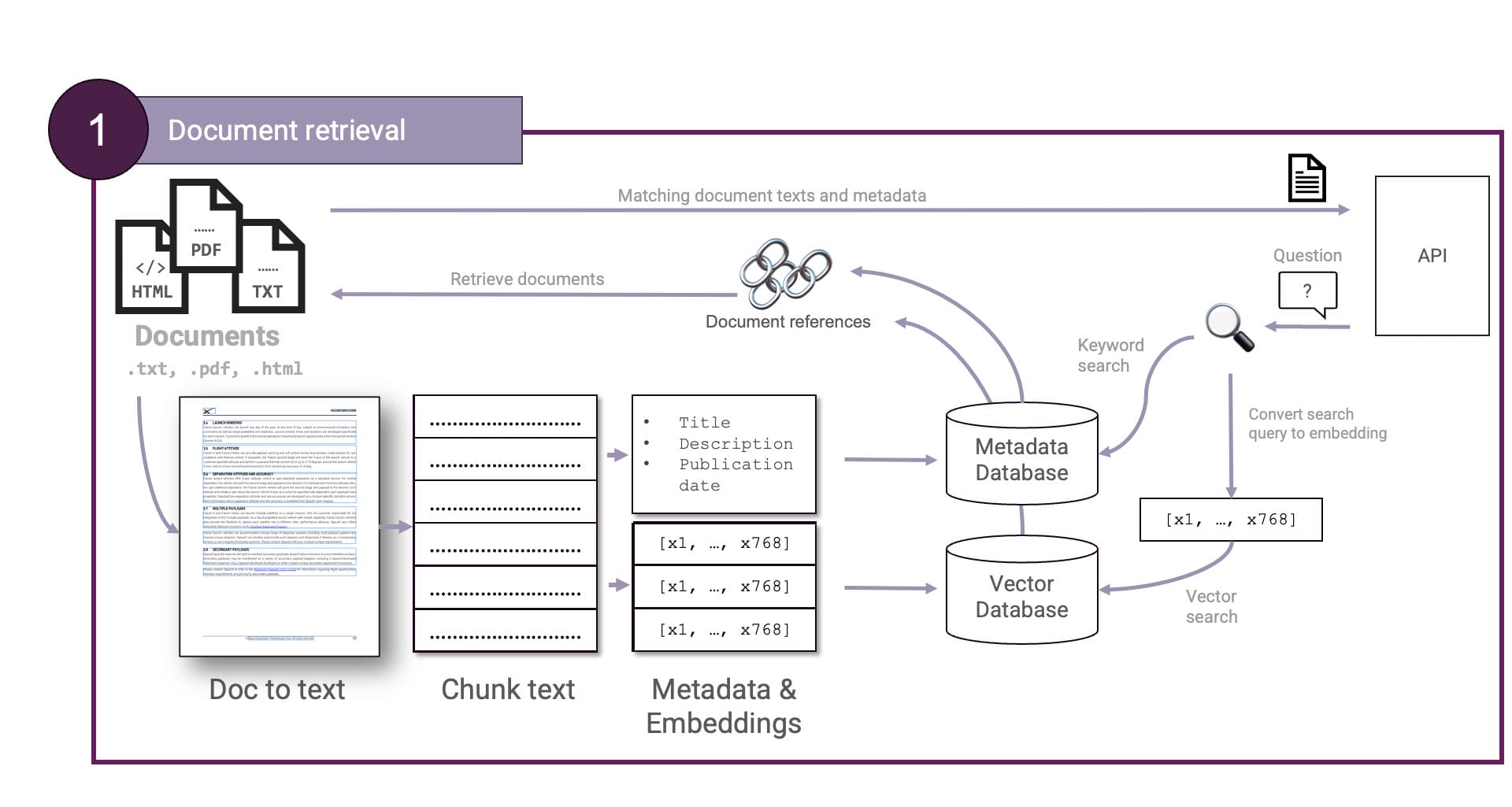
Toll. Aber was ist mit GCP. Wir können Ersteres wie folgt auf GCP abbilden:
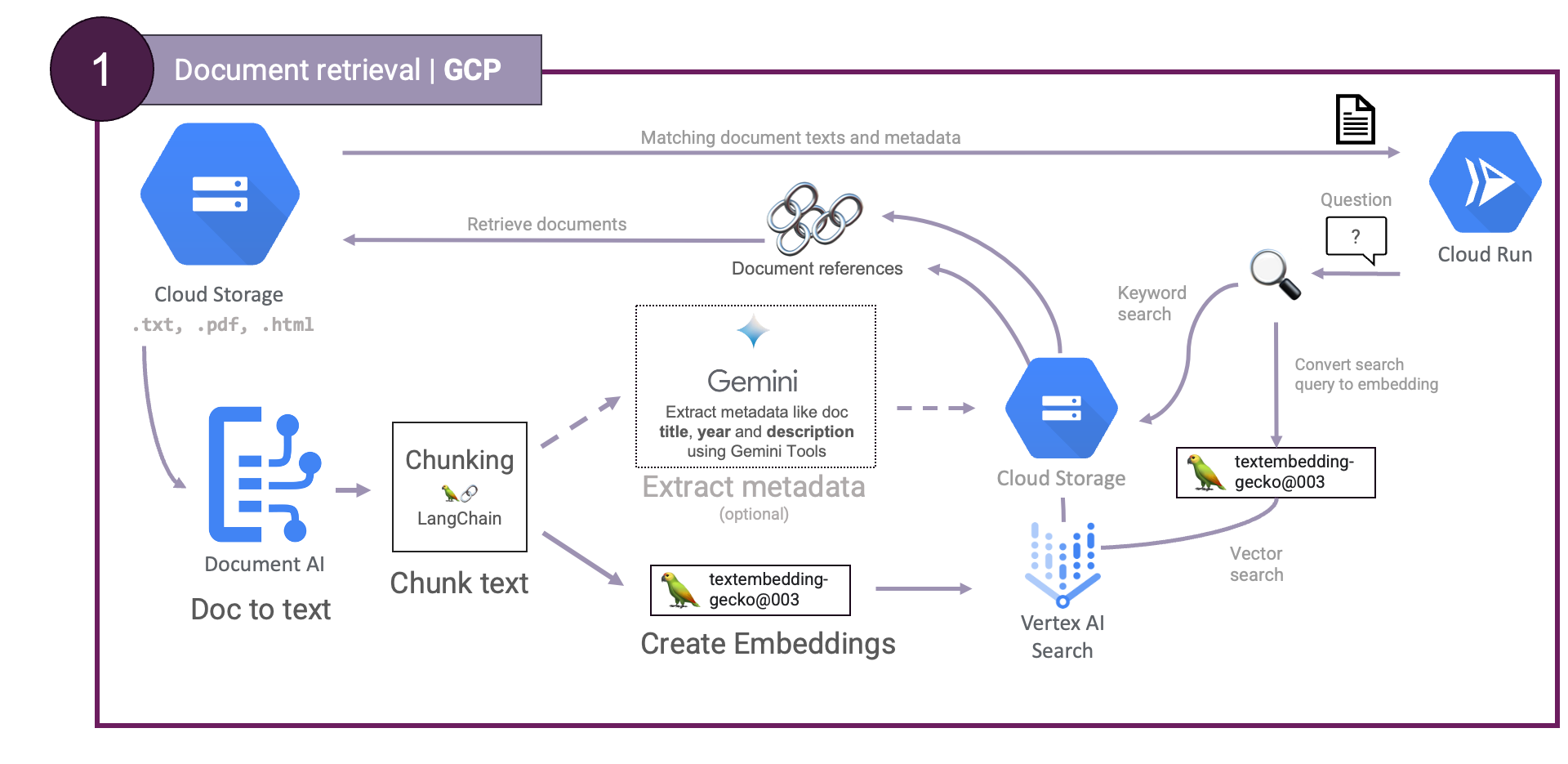
textembedding-gecko und Vertex AI Vector Search.Document AI wird verwendet, um Dokumente zu verarbeiten und Text zu extrahieren, Gemini und textembedding-gecko, um Metadaten bzw. Einbettungen zu generieren und Vertex AI Vector Search wird verwendet, um die Einbettungen zu speichern und eine Ähnlichkeitssuche durchzuführen. Mit diesen Diensten können wir einen skalierbaren Abrufschritt aufbauen.
Antwort Generation
Dann die Erstellung von Antworten. Hierfür benötigen wir einen LLM und weisen ihn an, die bereitgestellten Dokumente zu verwenden. Wir können dies folgendermaßen veranschaulichen:
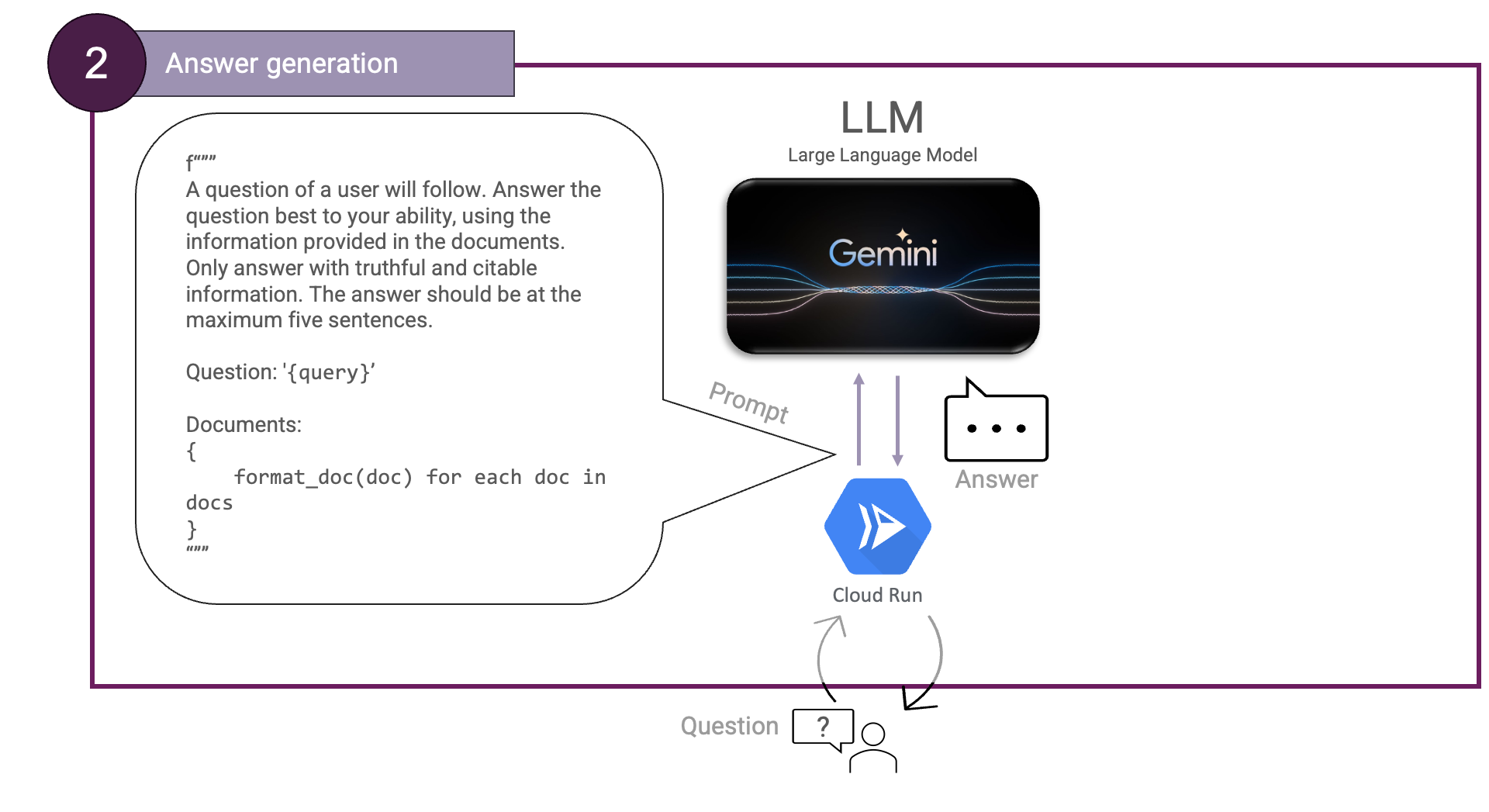
Hier können die Dokumente mit einer beliebigen Funktion formatiert werden, die gültiges Markdown erzeugt.
Wir haben bereits mehrere GCP-Dienste kennengelernt, die uns beim Aufbau eines RAG-Systems helfen können. Welche anderen Angebote hat GCP, um uns beim Aufbau eines RAG-Systems zu helfen, und welche Möglichkeiten gibt es, die Dienste zu kombinieren?
Die RAG-Geschmacksrichtungen auf GCP
Bislang haben wir GCP-Dienste gesehen, die uns beim Aufbau eines RAG-Systems helfen können. Dazu gehören Document AI, Vertex AI Vector Search, Gemini Pro, Cloud Storage und Cloud Run. Aber GCP hat auch Vertex AI Search & Conversation.
Vertex AI Search & Conversation ist ein auf GenAI-Anwendungsfälle zugeschnittener Service, der uns einen Teil der schweren Arbeit abnimmt. Er kann Dokumente einlesen, Einbettungen erstellen und die Vektordatenbank verwalten. Sie müssen sich nur darauf konzentrieren, die Daten im richtigen Format einzulesen. Dann können Sie Search & Conversation auf verschiedene Weise nutzen. Sie können entweder nur Suchergebnisse erhalten, wenn Sie eine Suchanfrage stellen, oder Sie können Search & Conversation eine vollständige Antwort mit Quellennachweisen für Sie erstellen lassen.
Auch wenn Vertex AI Search & Conversation sehr leistungsstark ist, kann es Szenarien geben, in denen Sie mehr Kontrolle wünschen. Werfen wir einen Blick auf diese Ebenen der Verwaltung oder der Kontrolle.
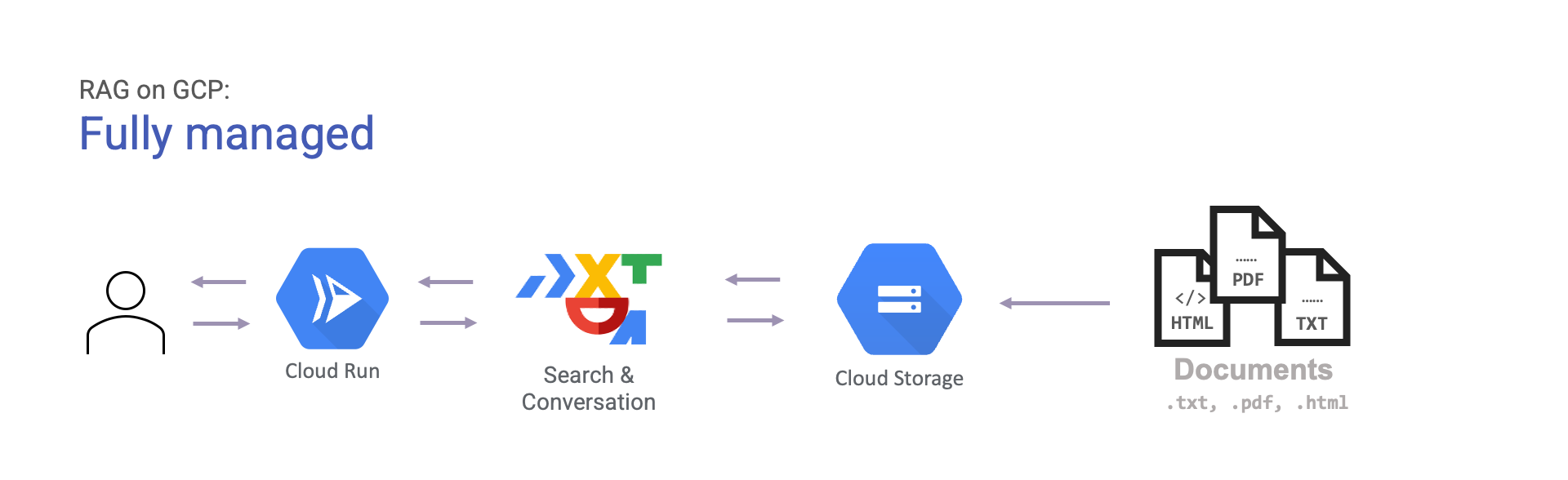
Der einfachste Weg, mit RAG auf GCP zu beginnen, ist die Verwendung von Search & Conversation. Der Dienst kann Dokumente aus verschiedenen Quellen wie Big Query und Google Cloud Storage einlesen. Sobald diese eingelesen sind, kann er für Sie Antworten generieren, die mit Zitaten unterlegt sind. Dies wird einfach wie folgt veranschaulicht:
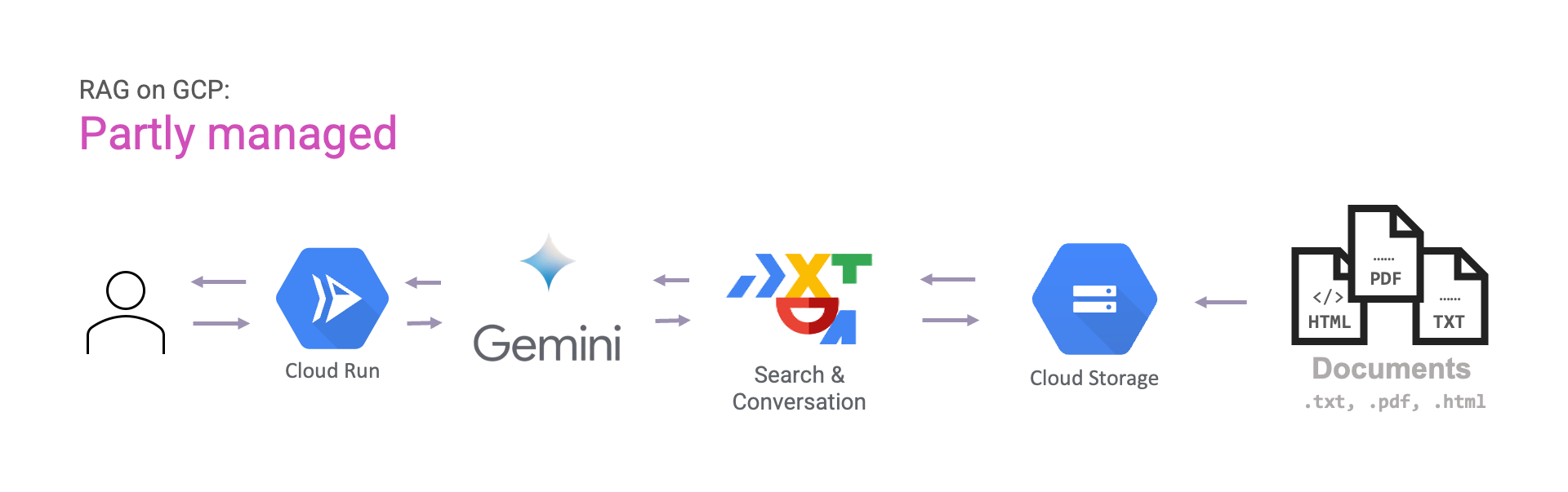
Wenn Sie mehr Kontrolle wünschen, können Sie Gemini für die Generierung von Antworten verwenden, anstatt Search & Conversation dies für uns zu tun. Auf diese Weise haben Sie mehr Kontrolle über die Eingabeaufforderungen, die Sie erstellen möchten.
Und schließlich haben Sie die volle Kontrolle über das RAG-System. Das bedeutet, dass Sie sowohl das Abrufen von Dokumenten als auch die Erstellung von Antworten selbst verwalten müssen. Das bedeutet natürlich mehr manuelle Arbeit bei der Entwicklung des Systems. Die Dokumente können von Document AI verarbeitet, gechunked, eingebettet und ihre Vektoren in Vertex AI Vector Search gespeichert werden. Dann kann Gemini verwendet werden, um die endgültigen Antworten zu generieren.
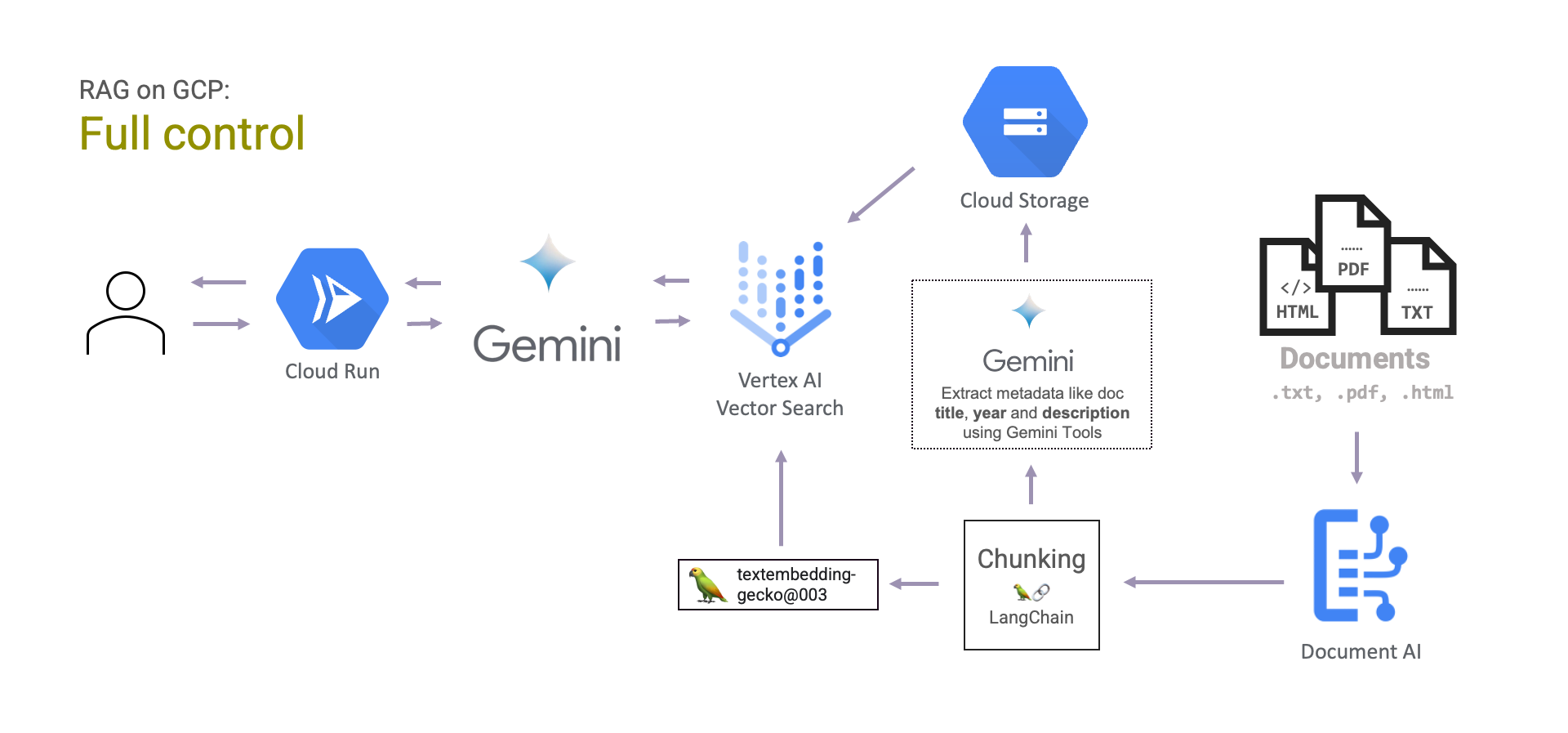
Der Vorteil dabei ist, dass Sie selbst bestimmen können , wie Sie die Dokumente verarbeiten und in Einbettungen umwandeln. Sie können alle von Document AI angebotenen Prozessoren verwenden, um die Dokumente auf unterschiedliche Weise zu verarbeiten.
Berücksichtigen Sie den Kompromiss zwischen einem verwalteten und einem manuellen Ansatz. Stellen Sie sich Fragen wie:
- Wie viel Zeit und Energie wollen Sie investieren, um etwas individuelles für die Flexibilität, die Sie benötigen, zu bauen?
- Brauchen Sie wirklich die Flexibilität Ihrer Lösung, um zusätzliche Wartungskosten in Kauf zu nehmen?
- Verfügen Sie über die technischen Kapazitäten, um eine maßgeschneiderte Lösung zu entwickeln und zu warten?
- Sind die anfänglich investierten Erstellungskosten das Geld wert, das man spart, wenn man keine verwaltete Lösung einsetzt?
So können Sie entscheiden, was für Sie am besten funktioniert ✓.
Schlusswort
RAG ist eine leistungsstarke Möglichkeit, LLMs mit externen Daten zu ergänzen. Dies kann dazu beitragen, Halluzinationen zu reduzieren und sachlichere Antworten zu liefern. Das Herzstück von RAG-Systemen sind Dokumentenprozessoren, Vektordatenbanken und LLMs.
Google Cloud Platform bietet Dienste, die bei der Erstellung produktionsreifer RAG-Lösungen helfen können. Wir haben drei Ebenen der Kontrolle bei der Bereitstellung einer RAG-Anwendung auf GCP beschrieben:
- Vollständig verwaltet: mit Search & Conversation.
- Teilweise verwaltet: verwaltete Suche mit Search & Conversation, aber manuelles Prompt-Engineering mit Gemini.
- Volle Kontrolle: manuelle Dokumentenverarbeitung mit Document AI, Erstellung von Einbettungen und Verwaltung von Vektordatenbanken mit Vertex AI Vector Search.
In diesem Sinne wünsche ich Ihnen viel Glück bei der Einführung Ihres eigenen RAG-Systems. Nutzen Sie die RAG für etwas Gutes! ♡
Foto von Ilo Frey: https://www.pexels.com/photo/photo-of-yellow-and-blue-macaw-with-one-wing-open-perched-on-a-wooden-stick-2317904/
Verfasst von

Jeroen Overschie
Machine Learning Engineer
Jeroen is a Machine Learning Engineer at Xebia.




Contact