
Seit ich Zugang zu GitHub Copilot habe, bin ich von seinen Fähigkeiten wirklich begeistert. Es liefert mir ständig mögliche Vervollständigungen für meinen Code und Text. Sie sind vielleicht nicht immer perfekt, aber oft gut genug, um als Ausgangspunkt zu dienen und zu verhindern, dass ich unter dem Syndrom der weißen Seite leide. Ich bin auch ein eifriger Benutzer von Obsidian, einer Anwendung zur Erstellung von Notizen, bei der ich oft auf das gleiche Syndrom der weißen Seite stoße. Das führte oft dazu, dass ich meine längeren Notizen entweder in meiner IDE mit Copilot schrieb oder ich zögerte und die Notiz (oder den

Vielleicht fragen Sie sich, was es braucht, um ein Copilot-ähnliches Plugin für Obsidian zu implementieren. Es stellt sich heraus, dass es auf drei Fragen hinausläuft:
- Wie erhalten wir Fertigstellungen?
- Wie können wir sicherstellen, dass die erzielten Abschlüsse die Art von Abschlüssen sind, die wir wollen?
- Wie können wir eine wartbare Softwarearchitektur für ein solches Plugin entwerfen?
Erlangung von Abschlüssen
Was Copilot so leistungsfähig macht, ist die Tatsache, dass seine Vorhersagen den Text vor und nach Ihrem Cursor mit einbeziehen. Wenn Sie sich ein wenig mit Transformatoren auskennen, finden Sie das vielleicht etwas seltsam, denn autoregressive Transformatoren wie GPT-3 berücksichtigen bei ihren Vorhersagen nur die vorherigen Token. Wie zwingen Sie also ein auf autoregressiven Transformern basierendes Modell dazu, den Text vor und nach dem Cursor in seiner Vorhersage zu berücksichtigen? Dieses Problem lässt sich mit einer cleveren, prompten Technik lösen. Wir sagen dem Modell, dass wir ihm einen Text im Format <text_before_cursor> <mask/> <text_after_cursor>, geben und seine Aufgabe darin besteht, mit den logischsten Wörtern zu antworten, die <mask/> ersetzen können. Im Plugin tun wir dies mit der folgenden Eingabeaufforderung:
Your job is to predict the most logical text that should be written at the location of the `<mask/>`.
Your answer can be either code, a single word, or multiple sentences.
Your answer must be in the same language as the text that is already there.
Your response must have the following format:
THOUGHT: here you explain your reasoning of what could be at the location of `<mask/>`
ANSWER: here you write the text that should be at the location of `<mask/>`
Dann geben wir dem Modell den Text vor und nach dem Cursor, der etwa so aussehen könnte:
# The Softmax <mask/>
The softmax function transforms a vector into a probability distribution such that the sum of the vector is equal to 1
Das Modell wird dann etwa so antworten:
THOUGHT: `<mask/>` is located inside a Markdown headings. The header already contains the text "The Softmax" contains so my answer should be coherent with that. The text after `<mask/>` is about the softmax function, so the title should reflect this.
ANSWER: function
Der Text nach THOUGHT: ermöglicht es dem Modell, ein wenig über den Kontext um den Cursor herum nachzudenken, bevor es die Antwort in den Bereich ANSWER: schreibt. Dies ist ein Prompt-Engineering-Trick namens Chain-of-Thought. Die Idee dahinter ist, dass ein Modell, das seine Überlegungen erklärt, eher eine kohärente Antwort schreibt, da es dem Aufmerksamkeitsmechanismus mehr Orientierung bietet. Für unseren Anwendungsfall funktioniert dies bemerkenswert gut. Wir interessieren uns hauptsächlich für den Abschnitt ANSWER:, da er die eigentliche Vervollständigung enthält. Dank des Präfixes ANSWER: können wir diesen Text mit Hilfe von regex extrahieren, und genau das tun wir im Plugin.
Das Modell kontextabhängig machen
Dank der obigen Systemabfrage haben wir nun eine Möglichkeit, Vervollständigungen aus dem Modell zu erhalten. Bei der Verwendung der obigen Systemabfrage ist mir jedoch aufgefallen, dass das Modell oft allgemeine Textvervollständigungen unabhängig von der Position des Cursors generiert. Selbst in Python-Codeblöcken erzeugte das Modell zum Beispiel lieber englische Textvervollständigungen als Python-Code. Das ist nicht das, was wir wollen. Wir Menschen erwarten z.B. unterschiedliche Arten von Vervollständigungen an verschiedenen Stellen des Cursors:
- Wenn sich der Cursor innerhalb eines Python-Codeblocks befindet, erwarten wir einen Abschluss mit Python-Code.
- Wenn sich der Cursor innerhalb eines mathematischen Blocks befindet, erwarten wir eine Vervollständigung mit Latex-Formeln.
- Wenn sich der Cursor innerhalb einer Liste befindet, erwarten wir ein neues Listenelement.
- Wenn sich der Cursor innerhalb einer Überschrift befindet, erwarten wir eine neue Überschrift, die den Inhalt des Absatzes darstellt.
- Etc.
Ihnen fallen sicher noch viele weitere Beispiele und Erwartungen ein. Wenn Sie all diese Erwartungen in der System-Eingabeaufforderung kodieren, würde diese sehr lang und komplex werden. Stattdessen ist es einfacher, einen Ansatz mit wenigen Beispielen zu verwenden. Bei diesem Ansatz geben wir dem Modell einige Beispiel-Eingabe- und Ausgabepaare vor, die dem Modell implizit zeigen, was wir in der Antwort für den gegebenen Kontext erwarten. Wenn sich der Cursor beispielsweise in einem Mathematikblock befindet, geben wir die folgende Beispieleingabe:
# Logarithm definition
A logarithm is the power to which a base must be raised to yield a given number.
For example, $2^3 =8$; therefore, 3 is the logarithm of 8 to base 2, or in other words $<mask/>$.
In Kombination mit der folgenden Beispielausgabe:
THOUGHT: The <mask/> is located inline math block.
The text before the mask is about logarithm.
The text is giving an example but the math notation still needs to be completed.
So my answer should be the latex formula for this example.
ANSWER: 3 = log_2(8)
Mit Beispielen wie diesen können wir dem Modell implizit zeigen, welche Art von Antworten wir an bestimmten Cursorpositionen erwarten. Sie haben aber auch noch einen anderen großen Vorteil. Die Eingabeaufforderung und die Beispiele können dynamisch und kontextspezifisch sein. Wenn sich der Cursor beispielsweise in einem Code-Block befindet, werden nur die wenigen Beispiele für Code-Blöcke angezeigt. Befindet sich der Cursor in einem Mathe-Block, wählen wir nur die wenigen Beispiele aus, die sich auf Mathe- und Latex-Formeln usw. beziehen. Auf diese Weise können wir das Modell kontextabhängig machen, ohne den gesamten Kontext in eine lange Systemansage zu kodieren. So können wir die Länge der Eingabeaufforderung, die Komplexität und die Kosten für die Inferenz reduzieren.

Ein weiterer netter Nebeneffekt dieses Ansatzes mit wenigen Beispielen ist, dass die Benutzer die Art der erwarteten Vervollständigungen anpassen können. Vielleicht möchte ein Benutzer, dass das Modell in seiner Muttersprache schreibt? Oder der Benutzer möchte vielleicht, dass das Modell Aufgaben in seinem eigenen Stil erstellt. Alles, was Sie tun müssen, ist, eine Beispieleingabe und eine Modellantwort für einen bestimmten Kontext zu schreiben, und das Modell wird lernen, Aufgaben in Ihrem Stil zu generieren. Dadurch ist das Modell sehr flexibel und kann an die Bedürfnisse des Benutzers angepasst werden. Deshalb ermöglicht das Plugin den Benutzern, die vorhandenen Beispiele zu bearbeiten oder über das Einstellungsmenü eigene Beispiele hinzuzufügen.
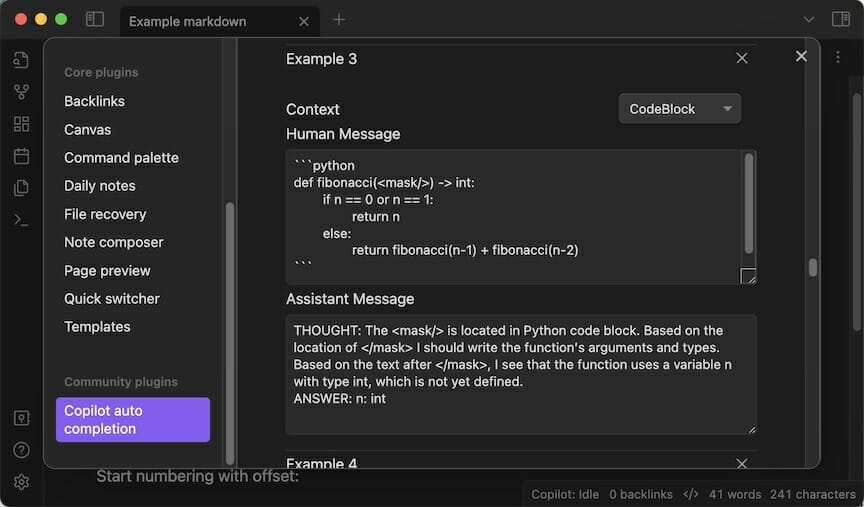
Plugin-Architektur
Wir haben jetzt eine Möglichkeit, Vervollständigungen aus dem Modell zu erhalten und eine Methode, um sicherzustellen, dass das Modell die Art von Vervollständigungen erzeugt, die wir erwarten. Nun bleibt eine große Frage: Wie können wir dies in eine IDE wie Obsidian integrieren, ohne den Code unnötig komplex zu machen? Der Code für ein solches Plugin kann schnell komplex werden, weil es auf viele verschiedene Ereignisse hören und in verschiedenen Situationen unterschiedliche Aktionen für dasselbe Ereignis durchführen muss. Wenn der Benutzer zum Beispiel die Taste Tab drückt, können viele Dinge passieren:
- Wenn das Plugin einen Abschluss anzeigt, sollte das Plugin den Abschluss einfügen.
- Wenn der Benutzer nur tippt, sollte das Plugin nichts tun, damit das Standardverhalten von Obsidian übernommen wird.
- Wenn eine Vorhersage in der Warteschlange steht, sollte das Plugin die Vorhersage abbrechen, da der Vorhersagekontext veraltet ist, während das Standardverhalten von Obsidian weiterhin gilt.
- Etc.
Wie Sie sehen, kann das Verhalten des Plugins mit nur einem einzigen Ereignis als Beispiel schnell komplex werden, während wir noch viele weitere Ereignisse behandeln müssen. Wenn Sie nicht aufpassen, haben Sie am Ende ein hochkomplexes Plugin voller if-else-Anweisungen, das unmöglich zu pflegen und zu erweitern ist. Glücklicherweise gibt es für dieses Problem eine Lösung: das State Machine Design Pattern.
Wenn Sie darüber nachdenken, hat das Plugin fünf verschiedene Situationen (oder Zustände), in denen es sich befinden kann:
- Leerlauf: Das Plugin ist aktiviert und wartet auf ein Benutzerereignis, das eine Vorhersage auslöst.
- In der Warteschlange: Ein Auslöser wurde erkannt und das Plugin wartet, bis die Auslösungsverzögerung abgelaufen ist, bevor es eine Vorhersage trifft. Diese Verzögerung ist erforderlich, um die Anzahl der API-Aufrufe (und die Kosten für die Schlussfolgerungen) zu minimieren.
- Voraussagen: Eine Vorhersageanfrage an den API-Anbieter und wartet auf die Antwort.
- Vorschlagen: Ein Abschluss wurde erstellt und dem Benutzer angezeigt, der ihn annehmen oder ablehnen kann.
- Deaktiviert: Das Plugin ist deaktiviert, und alle Ereignisse werden ignoriert.
Abhängig von dem aufgetretenen Ereignis geht das Plugin von einem Zustand in einen anderen über, wie in der Abbildung unten dargestellt.
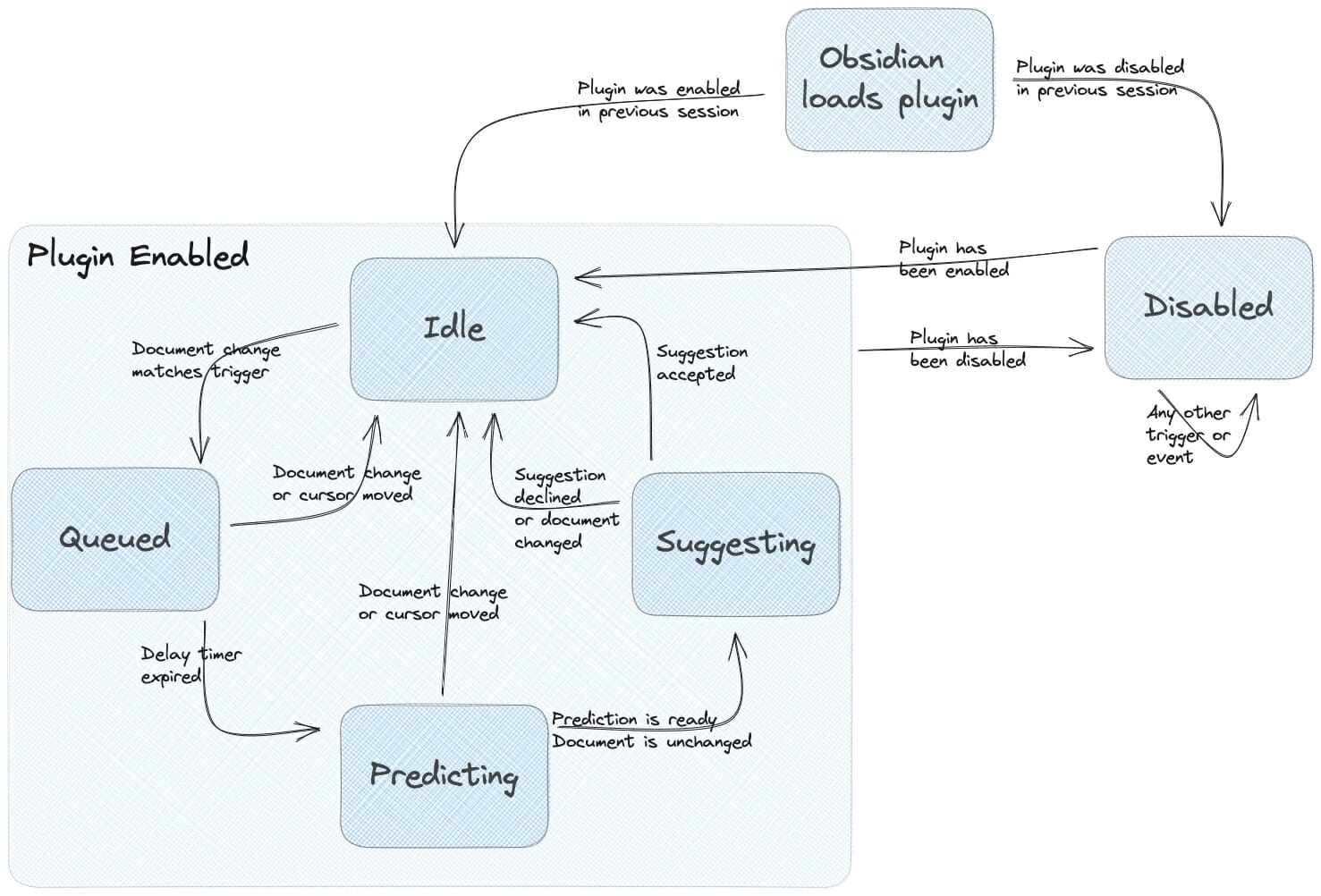
Der große Vorteil dieses Ansatzes ist, dass wir den gesamten zustandsspezifischen Verhaltenscode an einem Ort zusammenfassen. Zum Beispiel ist der gesamte Code für das Verhalten im Ruhezustand in der Klasse IdleState zusammengefasst. Dieser Code ist viel einfacher zu verstehen und zu interpretieren als viele, möglicherweise verschachtelte, if-else-Anweisungen. Ein weiterer großer Vorteil ist, dass Sie das Verhalten des Plugins in einem Zustandsdiagramm wie dem oben abgebildeten visualisieren können, was es neuen Entwicklern erleichtert, das Verhalten des Codes zu erklären. Dadurch ist die Codebasis des Plugins viel einfacher zu pflegen und zu erweitern.
Einpacken
Sie haben nun ein grundlegendes Verständnis davon, wie das Obsidian Copilot Plugin funktioniert und was es braucht, um es zu entwickeln. Jetzt fragen Sie sich vielleicht: "Wie gut funktioniert es?" und "Hilft es wirklich, das Syndrom der weißen Seiten zu vermeiden?" Natürlich habe ich dieses Plugin verwendet, um diesen Blogbeitrag zu schreiben, und da Sie dies lesen, kann ich wohl mit Sicherheit sagen, dass es mir geholfen hat, das Syndrom der weißen Seite zu vermeiden. Es könnte sich also lohnen, es selbst einmal auszuprobieren. Sie finden das Plugin im Obsidian Community Plugin Store und den Code auf GitHub sowie den Originalbeitrag hier. Viel Spaß!
Verfasst von
Jordi Smit




Contact