
Das maschinelle Lernen beginnt langsam zu reifen, aber viele Unternehmen stehen noch immer vor großen Herausforderungen. Es gibt zwar eine riesige (und wachsende) Menge neuer Algorithmen, neuronaler Netzwerkarchitekturen und Bibliotheken, aber der praktische Einsatz steckt noch in den Kinderschuhen.
Es gibt jedoch eine Menge neuer Hoffnung für Unternehmen, die maschinelles Lernen einsetzen möchten. So wie DevOps die Entwicklung und Bereitstellung von Software revolutioniert hat, möchte ich hier eine ähnliche Lösung vorstellen: das treffend benannte MLOps.
Der aktuelle Stand von ML
Maschinelles Lernen ist eine sehr neue Technologie - eine, die bereits für viele von Vorteil ist - aber wie bei jeder Technologie gibt es eine bekannte Entwicklungsgeschichte...
Der derzeitige Stand von Projekten zum maschinellen Lernen erinnert mich an die Anfänge der Softwareentwicklung - vor etwa 10-15 Jahren - als wir anfingen, richtige Entwicklungsprozesse einzuführen. Wenn ich zurückblicke, ist es mir peinlich, wie wir damals Softwareprojekte durchgeführt haben. Als Softwareentwicklungsgemeinschaft haben wir enorme Fortschritte gemacht, was die Produktivierung unseres Codes, die Verwendung eines GIT-Repositorys, CI/CD-Pipelines, ordnungsgemäße Tests auf vielen verschiedenen Ebenen (Unit, Integration, E2E, Mutation ...) usw. angeht. Kurz gesagt, es wurden bereits viele wichtige Erfolge erzielt, aber es liegt noch viel vor uns.
Es ist auch sehr aufregend, heutzutage im Bereich Data Science zu arbeiten, denn ich bin sicher, dass wir mit MLOps große Verbesserungen erzielen und unseren Bereich voranbringen können.
Was ist MLOps?
MLOps, was so viel bedeutet wie "Machine Learning Operations", ist eine Entwicklungspraxis, die DevOps ähnelt, aber von Grund auf für die Best Practices des maschinellen Lernens entwickelt wurde. Genauso wie DevOps darauf abzielt, regelmäßige, kürzere Releases bereitzustellen, ist auch MLOps bestrebt, jeden Schritt des Lebenszyklus der ML-Entwicklung zu verbessern.
In der Tat sind viele Faktoren aus DevOps hier direkt anwendbar. Am wichtigsten ist, dass der Fokus auf Continuous Integration/Continuous Delivery direkt auf die Modellerstellung angewandt wird, während die regelmäßige Bereitstellung, Diagnose und Weiterbildung auch in einem häufigen Prozess erfolgen kann, anstatt auf einen großen Upload in viel langsameren Abständen zu warten.
MLOps & Bereitstellung von ML-basiertem Wert
Wie jede Lösung wird auch Machine Learning (ML) an seinem Erfolg und Wert gemessen.
Einige Unternehmen fragen nach den neuesten und ausgefallensten Dingen, wie z.B. automatisches Modell-Retraining. Die typische erste Reaktion auf eine solche Anfrage ist, einen Schritt zurückzutreten und mit Fragen zu beginnen wie: "Können Sie einfach wiederholen, was Ihr Datenwissenschaftler gestern gemacht hat?"
Irgendwie erwarten wir natürlich, dass, wenn wir Codeversionierung, kontinuierliche Integration usw. in unseren Softwareprojekten haben, dies automatisch auch für unsere Modelle zur Verfügung steht. Das ist eines der größten Missverständnisse: dass alles, was wir tun, "nur" das Trainieren eines Modells ist:

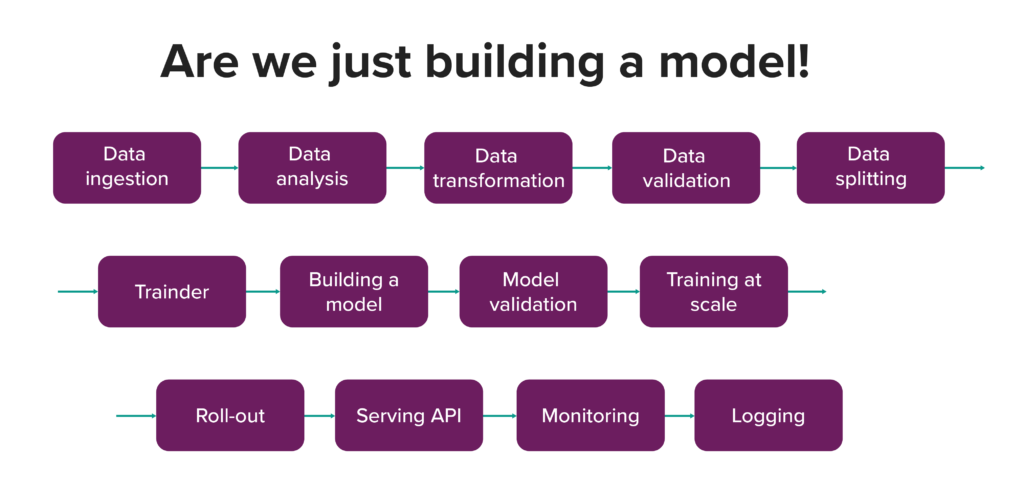
Die Erwartungen sind eine Sache, aber die Realität sieht oft anders aus. Ein beliebteres Szenario aus dem wirklichen Leben ist ein Gespräch mit dem CTO, bei dem er etwas in der Art von "Hey, wir haben ein paar Datenwissenschaftler eingestellt: "Hey, wir haben einen Haufen Datenwissenschaftler eingestellt, die den ganzen Tag mit Jupyter-Notizbüchern auf ihren lokalen Rechnern spielen, und wenn es an der Zeit ist, sie einzusetzen, haben wir keine Ahnung, wo der Code ist. Meistens ist er nicht einmal eingecheckt. Sie behaupten, dass sie so viele tolle Sachen machen, aber wir können keinen geschäftlichen Nutzen daraus ziehen.
Wenn Sie in Erwägung ziehen, mit MLOps zu beginnen, würde ich zunächst vorschlagen, Ihren Reifegrad zu bewerten, sowohl in Bezug darauf, wie Sie an Ihren Modellen arbeiten, als auch darauf, wie sie in Produktionsumgebungen eingesetzt werden.
Wichtige Werte für maschinelles Lernen
Was wollen wir also mit maschinellem Lernen erreichen? Das ist schließlich das Endziel, das MLOps effizienter erreichen möchte. Für die meisten Unternehmen können wir die Werte auf drei wichtigen Ebenen oder Stufen bestimmen:
Wiederholbarkeit - das bedeutet, dass Sie Ihre Arbeit am Modell so weit automatisiert haben, dass Sie jedes Experiment, das Ihr Data Science Team bereits durchgeführt hat, jederzeit wiederholen können.
Produktivsetzung - auf dieser Stufe sollten Sie in der Lage sein, das Modell automatisch in die Produktion zu überführen, indem Sie nicht nur die Bereitstellung, sondern auch Canary Deployments, Tests, Fallbacks, Überwachung usw. automatisiert haben.
Geschäftlicher Nutzen - auf dieser Ebene sollten Sie in der Lage sein, den Einfluss jeder einzelnen Modellversion in Bezug auf Geschäftskennzahlen zu messen. Wenn Sie z.B. eine neue Empfehlungsmaschine auf einer Einzelhandelswebsite oder für eine kleine Benutzergruppe einsetzen, müssen Sie im Modell-Repository automatisch sehen, dass die Konversionsrate oder die Verkaufszahlen durch diesen Einsatz um X% beeinflusst wurden.
Ähnliche Beispiele finden wir in allen Ecken der Industrie:
- Muss Ihre Fertigungs- oder Produktionsanlage über zahlreiche Parameter hinweg optimiert werden? Automatisierung kann bei der Bewältigung großer Arbeitslasten helfen, mit denen manuelle Tätigkeiten nicht mithalten können (und für die größten Vorgänge in zahlreichen Anlagen gibt es Mesh Twin Learning).
- Versucht Ihr Finanzunternehmen, bei Online-Betrügereien den Überblick zu behalten? Automatisierung ist wichtig, um sich über neue Herausforderungen zu informieren, auf neuere Versionen zu aktualisieren und dem Feld voraus zu sein. Und außerdem müssen Sie wissen, ob es funktioniert hat!
- Und so weiter. Sie können es sich denken...
Um dies zu ermöglichen, sollten Sie sowohl die Datenverwaltung als auch die Analyse neuer Datensätze, die im System verfügbar werden, berücksichtigen. Es ist gut zu wissen, ob die neuen Daten denen ähneln, die wir bereits haben, oder ob sie anders verteilt sind und ob es sich lohnen könnte, das Modell damit neu zu trainieren. [blog_post_contact_form ga_event_category="manufacturing_nordics" ga_event_label="blog-contact-form" header="Need help with Industry 4.0?" thank_you="Thank you! We'll be in touch!" button_text="send"]
Personas im Prozess
Eine der größten Herausforderungen im MLOps-Prozess liegt in den vielen Positionen und Hüten, die damit verbunden sind. Sie müssen in der Lage sein, die Anforderungen Ihres Dateningenieurs zu erfüllen und sicherstellen, dass Sie die Datensätze erhalten, bereinigen, versionieren und pflegen können, was bei ereignisbasierten Echtzeitsystemen noch schwieriger wird. Und das ist nur die erste Person!
Der nächste auf der Liste ist Ihr Data Scientist, der manchmal wirklich mehr Wissenschaftler als Ingenieur ist, damit er oder sie Experimente durchführen und viele Hypothesen testen kann. Schließlich brauchen Sie jemanden, der das Modell in Ihr Produkt einbaut und sicherstellt, dass die Ergebnisse Ihrer Experimente auch in der realen Welt übereinstimmen. An dieser Stelle kommt der ML Engineer ins Spiel.
Da so viele Menschen beteiligt sind, muss der Prozess so effizient und straff wie möglich sein...
Erstellen der MLOps Pipeline
Es gibt eine Vielzahl von Tools, die beim Aufbau einer effizienten MLOps-Pipeline helfen können. Sie können zum Beispiel den Open-Source-Weg gehen und Tools wie Airflow, Kubeflow und Jenkins verwenden, gepaart mit ein paar eigenen Skripten.
Ebenso haben alle großen Cloud-Anbieter ihre eigenen DevOps-Tools, die durch einige Open-Source-Komponenten erweitert werden können, um eine vollständige MLOps-Lösung aufzubauen.
In diesem Artikel möchte ich jedoch eine andere Option vorstellen, nämlich TensorFlow TFX: eine End-to-End-Plattform für den Einsatz von ML-Pipelines.
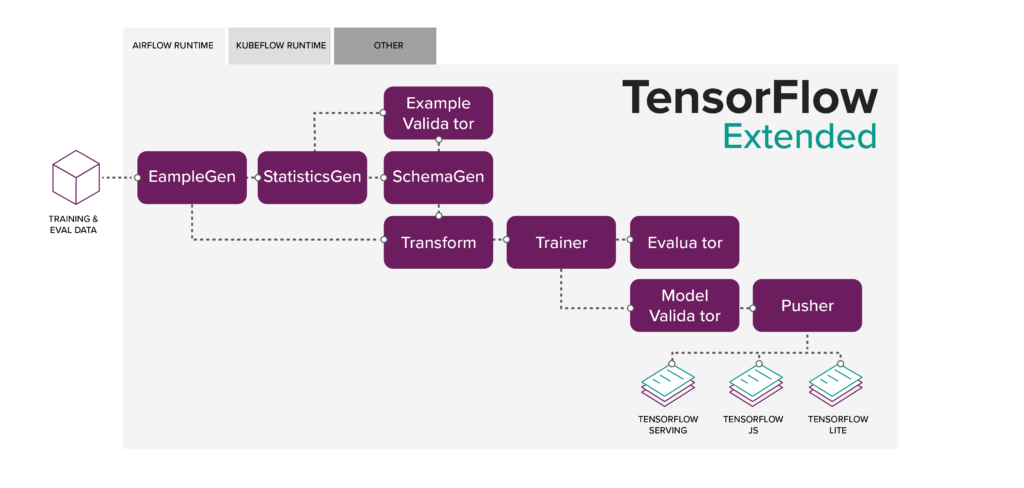
Seine größte Stärke ist, dass Sie nicht nur auf der Google Cloud Platform (GCP) laufen, sondern auch Apache Airflow oder Kubeflow als Laufzeitumgebung verwenden können.
Ein weiterer sehr geschätzter Aspekt ist das Konzept des Metadatenspeichers, der Folgendes enthält:
- Trainierte Modelle (Modelle, Daten & Bewertungsmetriken)
- Ausführungsaufzeichnungen (Laufzeitkonfigurationen sowie Inputs + Outputs)
- Verfolgung der Abstammung über alle Ausführungen hinweg (z.B. um zu allen Eingaben eines bestimmten Artefakts zurückzukehren)
In der Abbildung oben sehen Sie außerdem, wie jede atomare Operation gehandhabt wird. Sie haben einen Treiber und einen Publisher (die bei Bedarf überschrieben werden können), die das Abrufen und Speichern von Daten im Metadatenspeicher übernehmen, sowie einen Executor, der die Geschäftslogik eines bestimmten Schritts schreibt.
Dies ermöglicht die folgenden Anwendungsfälle:
- Visualisierung der Abstammung eines bestimmten Modells
- Visualisierung eines datenspezifischen Modells, das in einem bestimmten Lauf trainiert wurde (mit aufgeschnittenen Bewertungsmetriken, die Sie unten sehen können)
- Vergleich mehrerer Modellläufe
- Datenstatistiken für verschiedene Modelle vergleichen
- Übertragungen von Modellen, die vor einiger Zeit ausgeführt wurden
- Wiederverwendung von zuvor berechneten Ergebnissen.
Mein Favorit ist die aufgeschnittene Auswertungsmetrik, mit der Sie analysieren können, wie sich bestimmte Teile des Datensatzes auf Ihre Ergebnisse auswirken.

Eine weitere Funktion, die wir vor allem in der Anfangsphase eines Projekts häufig nutzen, ist die Möglichkeit, zuvor berechnete Ergebnisse wiederzuverwenden (da sie im Metadatenspeicher gespeichert sind). Mit diesem Ansatz müssen Sie bei einem Trainingsauftrag mit mehreren Schritten, der in der Regel mehrere Wochen dauert, nicht wieder von vorne anfangen, wenn etwas schief geht.
Zusammenfassung
Wo ist MLOps also am nützlichsten? Wenn Sie ein einzelner Forscher sind, der an seiner Dissertation oder einem kleinen Lieblingsprojekt arbeitet, brauchen Sie Ihr Leben nicht mit MLOps zu verkomplizieren. Wenn Sie jedoch mit irgendeinem Produktionssystem arbeiten, empfehle ich Ihnen dringend, es auszuprobieren.
Wenn Sie Hilfe bei der Auswahl einer geeigneten Lösung benötigen oder sich bereits für eine Lösung entschieden haben und Probleme bei der Implementierung haben, kontaktieren Sie uns bitte.
Geschäftsperspektive
Maschinelles Lernen muss kein langer Entwicklungszyklus sein. MLOps kombiniert die besten Elemente von DevOps und passt sie an die Entwicklung, die Freigabe und das Training von ML-Modellen an, um unmittelbare Vorteile und schnellere Freigaben für alle wichtigen Algorithmen des maschinellen Lernens zu erzielen - all dies ermöglicht es Unternehmen, solche fortschrittlichen Lösungen schneller als je zuvor zu implementieren.
Unsere Ideen
Weitere Blogs




Contact