
In diesem Blog beschäftigen sich Simon Karman und Matt Watson mit der Überwachung eines Amazon MSK-Clusters. Amazon MSK ist das von AWS verwaltete Angebot für Apache Kafka. Um Probleme zu erkennen und schnell darauf reagieren zu können, ist es wichtig, den Zustand dieser Cluster zu überwachen.
Wir möchten erkennen, wenn der MSK-Cluster (oder anders gesagt: einer der zugrunde liegenden Broker) aufgrund von Lastproblemen Probleme hat. Denn dies kann dazu führen, dass Produzenten gedrosselt werden, was bedeutet, dass Nachrichten oder Ereignisse verloren gehen können. In einem solchen Fall ist es wichtig, den angeschlagenen Cluster so schnell wie möglich aufzulösen. Deshalb brauchen wir eine Möglichkeit, um zu überprüfen, ob alle Broker optimal laufen, so dass sie die Last der Anfragen von Produzenten und Konsumenten bewältigen können.
In diesem Artikel werden wir die wichtige(n) Kennzahl(en) ermitteln, anhand derer wir feststellen können, dass Makler Probleme haben, und dann die verfügbaren Optionen zur Lösung des Problems aufzeigen.
Identifizieren Sie wichtige Metriken
Um herauszufinden, welche Metrik(en) bei Überlastung eines Clusters verwendet werden könnte(n), haben wir einen Lasttest durchgeführt. Wir begannen mit dem Lasttest (in der Grafik um 14:10 Uhr), um zu sehen, welche Metriken sich signifikant verändern würden. Dabei stellten wir fest, dass sich die Metrik aws.kafka.request_handler_avg_idle_percent mit zunehmender Last signifikant veränderte (wie in der Grafik unten dargestellt).
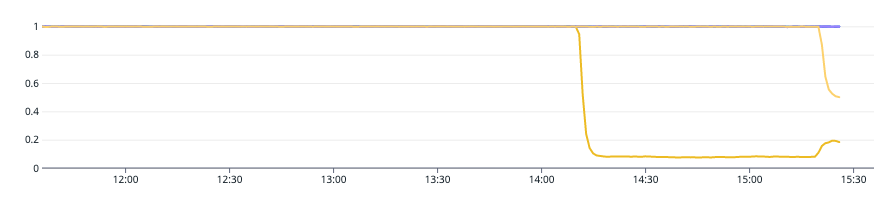
Das Kafka-Thema, das wir für den Lasttest verwendet haben, nutzte nur eine einzige Partition. Das bedeutet, dass ein einziger Broker die gesamte Last erhalten würde, was den Leistungsvergleich mit anderen Brokern vereinfachte. Während des Lasttests sahen wir, dass der einzelne Broker während des Lasttests mit der aws.kafka.request_handler_avg_idle_percent metric gesättigt war. Dies war ein guter Indikator für einen ungesunden Kafka-Broker und einen generell langsamen Kafka-Cluster.
Wenn der prozentuale Leerlauf des Request Handlers konstant unter 0,2 (20%) liegt, ist Ihr Cluster wahrscheinlich überlastet und benötigt eine Kapazitätserhöhung (Quelle: Network and Request Handler Capacity). Aus diesem Grund haben wir in unserem System einen Monitor eingerichtet, der den Wert dieser Metrik mit einem Warnschwellenwert von 0,2 (20%) überwacht.
Lösen Sie einen problematischen Cluster/Broker auf
Sobald Sie festgestellt haben, dass der Cluster oder der Makler Probleme hat, brauchen Sie Mittel und Wege, um die Situation zu lösen.
Am einfachsten ist es, die Brokertypen zu aktualisieren, so dass sie über mehr Speicher und CPU verfügen, oder die Anzahl der Broker im Cluster zu erhöhen. Dies ist jedoch im Allgemeinen nur dann sinnvoll, wenn die Mehrheit der Broker überlastet ist.
Wenn eine Untergruppe von Brokern Probleme hat, könnte dies darauf hindeuten, dass ein Thema nicht korrekt partitioniert ist. In diesem Fall könnte eine Erhöhung der Anzahl der Partitionen dazu beitragen, die Last auf mehr Kafka-Broker zu verteilen und so den Stress für den oder die angeschlagenen Broker zu verringern.
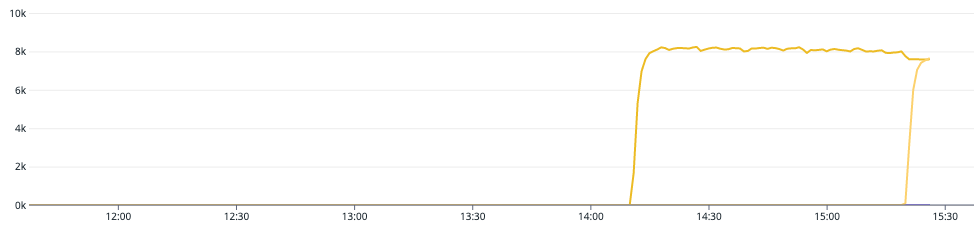
Da das Kafka-Thema, das wir für unseren Lasttest verwendet haben, eine einzige Partition hatte, war ein Broker überlastet. Indem wir die Partitionen auf 2 erhöht haben, konnten wir die Last gleichmäßiger auf die verschiedenen Broker verteilen. Dadurch verringerte sich nicht nur der Druck auf den Request Handler des Brokers (im Diagramm bei 15:15), sondern auch der Durchsatz des Kafka-Clusters stieg, da nun mehrere Broker gleichzeitig die Arbeit dieses Themas erledigen konnten.
Fazit
Wir haben gezeigt, dass die Metrik aws.kafka.request_handler_avg_idle_percent anzeigt, ob ein Broker Probleme hat. Durch die Erstellung von Monitoren können wir daher diese Metrik von jedem Broker verfolgen und sehen, ob ihr Wert unter 0,2 (20%) fällt.
Wenn er unter diesen Wert fällt, können wir entweder (1) die Broker aktualisieren, indem wir mehr Arbeitsspeicher und CPU hinzufügen oder die Anzahl der Broker im Cluster erhöhen, oder (2) überprüfen, ob das Thema korrekt auf alle Broker aufgeteilt wurde.
Verfasst von

Simon Karman
Simon Karman is a cloud engineer and consultant that builds effective cloud solutions ranging from serverless applications, to apis, to CICD pipelines, and to infrastructure as code solutions in both AWS and GCP.
Unsere Ideen
Weitere Blogs



Contact