Einführung
Bei der Datenmodellierung handelt es sich um den Prozess der strukturierten Darstellung der Geschäftsprozesse eines Unternehmens. Sie beschreibt detailliert die Beziehungen zwischen Entitäten, welche Einschränkungen gelten und wie die Daten in einem Data Warehouse gespeichert werden sollen. Die Datenmodellierung ist von grundlegender Bedeutung für eine effiziente Datenbankentwicklung und -pflege und letztlich für genaue Geschäftseinblicke.
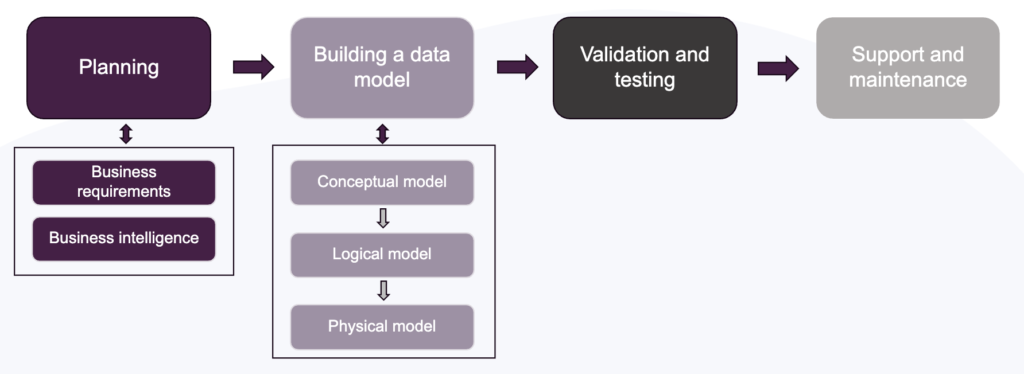
Die Entwicklung eines Datenmodells beginnt mit der Planung und Erfassung der Geschäftsanforderungen. Sobald die Erwartungen klar sindDer nächste Schritt ist die Erstellung des Datenmodells selbst, beginnend mit dem konzeptionellen Modell, dann dem logischen Modell und schließlich dem physischen Modell. Danach folgen die Validierung und das Testen sowie die laufende Unterstützung und Pflege.
Eines der beliebtesten Frameworks für die Datenmodellierung ist die dimensionale Modellierung. Es gibt sie schon seit Jahrzehnten, populär gemacht durch Ralph Kimballs Einführung von Das Data Warehouse Toolkit im Jahr 1996. Da der Schwerpunkt auf Einfachheit und Symmetrie liegt, ist es nach wie vor für eine Vielzahl von Anwendungsfällen, Branchen und Datenstapeln relevant.
Aber was genau ist dimensionales Modellieren? Was sind das für Techniken? Schauen wir uns einige Kernkonzepte an und wie sie mit dem vorgestellten Lebenszyklus zusammenhängen.
Zentrale Konzepte
Nach der Methodik von Kimball sind die vier Schritte zur Entwicklung eines Dimensionsmodells folgende:
- Wählen Sie den Geschäftsprozess aus;
- Identifizieren Sie das Getreide;
- Identifizieren Sie die Abmessungen;
- Identifizieren Sie die Fakten;
Schritt eins bedeutet, dass Sie einen Prozess auswählen, der für Ihre Interessengruppen relevant ist. In Schritt zwei wird die atomarste Ebene der Informationen ermittelt, die in der Faktentabelle gespeichert werden müssen. In Schritt drei müssen Sie angesichts der skizzierten Faktentabelle die Dimensionen identifizieren, die mit ihr verbunden sind. In Schritt vier schließlich werden die numerischen Fakten skizziert, mit denen die Zeilen der Faktentabelle gefüllt werden.
Dimensionstabellen enthalten beschreibende Attribute einer Geschäftseinheit und haben normalerweise einen Primärschlüssel (PK), der eine Zeile eindeutig identifiziert. Faktentabellen enthalten numerische und messbare Daten, die Geschäftsereignisse darstellen, wobei jede Zeile eine Ereignisbeobachtung darstellt. Faktentabellen haben Spalten mit Fremdschlüsseln (FK), die mit Dimensionstabellen verknüpft werden können.
Bezogen auf den oben dargestellten Lebenszyklus können diese vier Schritte mit den folgenden verbunden werden Planung und Aufbau eines Datenmodells Blöcke.
Stellen wir uns vor, dass Xebia Data unser Kerngeschäftsmodell untersuchen möchte: den Verkauf von Beratungsprojekten - der Geschäftsprozess, an dem wir interessiert sind. Was den Kern betrifft, so sind wir an täglichen Aufzeichnungen von Rechnungszahlungen interessiert, da verschiedene Kunden zu unterschiedlichen Zeitpunkten zahlen können. Was jetzt noch bleibt, ist die Identifizierung der Dimensionen und Fakten.
Im Lebenszyklus eines Datenmodellierungsprojekts haben wir gesehen, dass die Erstellung eines Modells eine konzeptionelle, eine logische und eine physische Phase umfasst. Das konzeptionelle Modell ist eine übergeordnete Darstellung der Geschäftsprozesse eines Unternehmens und enthält keine technischen Details der Daten, z. B. wie sie gespeichert werden. Das logische Modell hingegen erweitert das konzeptionelle Modell zu einer detaillierteren Darstellung und definiert Entitäten, Attribute und Beziehungen. Das physische Modell schließlich legt den Schwerpunkt auf spezifische Optimierungen für die Datenbank und die physische Speicherung der Daten.
Mit unserem Xebia Data Geschäftsprozess könnte ein vereinfachtes konzeptionelles Modell aussehen:
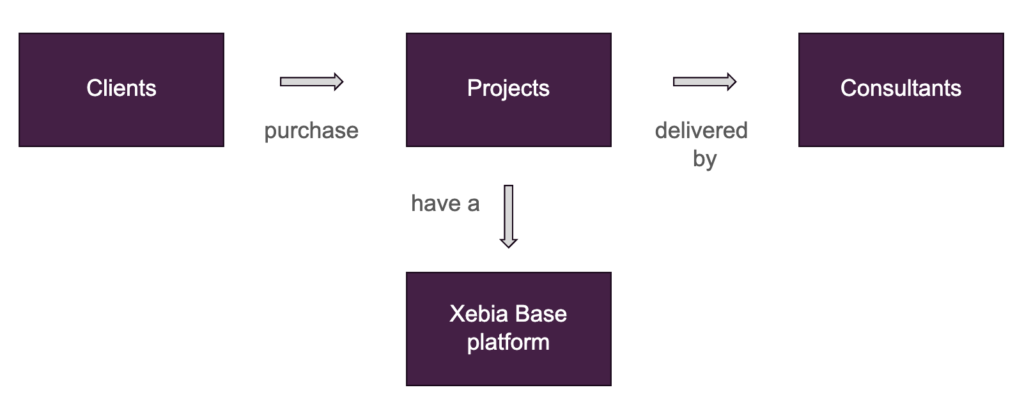
Die nächste Phase besteht darin, das konzeptionelle Modell in ein logisches Modell zu übersetzen. In dieser Phase wird in der Regel festgelegt, welches Datenmodellierungs-Framework verwendet werden soll. Ein beliebtes Beispiel ist der Star-Schema-Ansatz von Kimball. Bei Star Schema wird eine zentrale Faktentabelle über FKs mit Dimensionstabellen verknüpft. In unserem Beispiel könnte eine mögliche Faktentabelle eine Rechnungsumsatztabelle sein, in der der Prozess des Kaufs (der Bezahlung) einer Rechnung durch einen Kunden verfolgt wird. Wenn Sie sich das konzeptionelle Modell ansehen, können Sie außerdem Dimensionstabellen wie Berater, Projekte, Kunden, Xebia Basisplattformen und Daten würden einen relevanten Kontext zu diesen Käufen liefern.
Unser Star-Schema-Modell hätte dann die folgende Struktur:
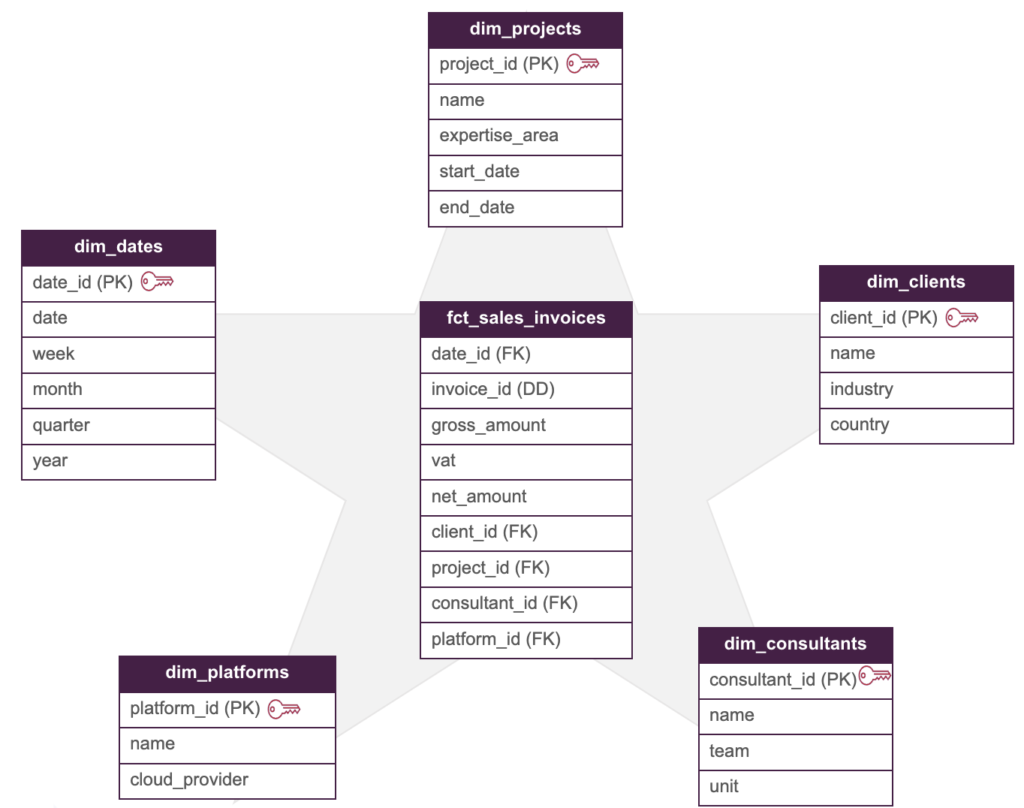
Wobei der Rechnungsidentifikator (invoice_id) eine degenerierte Dimension ist.
Die Beziehung zwischen den Dimensionstabellen und der Faktentabelle wäre eins-zu-viele: Das bedeutet, dass ein Datensatz (PK) in einer Dimensionstabelle mit vielen Datensätzen (FK) in der Faktentabelle verbunden ist, was zu unserem logischen Modell führt:
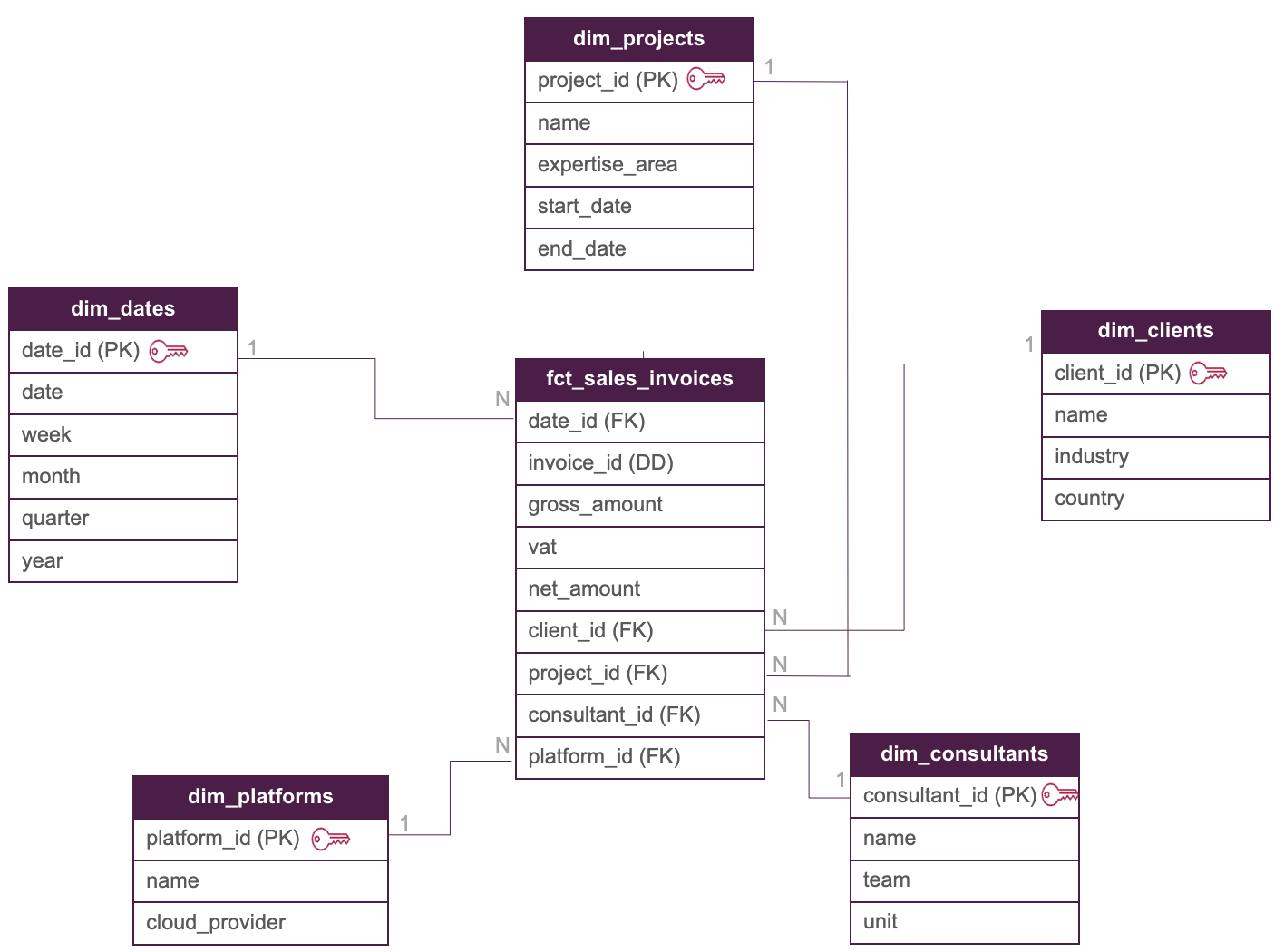
Betrachtet man den Lebenszyklus eines Datenmodellierungsprojekts, so ist der nächste Schritt im Aufbau eines Datenmodells ist die Entwicklung der physischen Implementierung. In dieser Phase ist es wichtig, die richtigen Datentypen, Spaltenbeschränkungen und angemessene Tests zu definieren, um die Integrität des Modells sicherzustellen. Aber was können Sie verwenden, um all diese Anforderungen zu erfüllen?
Wie dbt die dimensionale Modellierung unterstützen kann
dbt ist ein SQL-gestütztes Datenumwandlungstool, das bewährte Softwareentwicklungsverfahren in Analyse-Workflows unterstützt. Mit dbt werden Rohdaten in konsumierbare Datensätze umgewandelt, und die Umwandlungen können getestet, versionskontrolliert und durch ein umfassendes Modell und eine Abstammung auf Spaltenebene nachverfolgt werden. Anstatt Daten in einem BI-Tool oder in Notebooks zu modellieren, können Ingenieure und Analysten die Funktionen von dbt nutzen, um versionskontrollierten SQL-Code zu entwickeln.
Mit dbt wird die Implementierung des physischen Modells zu einem rationalisierten und skalierbaren Prozess. Die generischen Tests der Modelle können in yaml-Dateien konfiguriert werden, was die Validierung, das Testen und die Wartung sehr einfach macht. Mit dem weit verbreiteten dbt Projektstruktur von Staging-, Zwischen- und Marts-Modellen können die Transformationen, die für die Bereitstellung von Dimensions- und Faktentabellen erforderlich sind, in modulare Schichten unterteilt werden. Dimensions- und Faktentabellen werden dann häufig in Marts abgelegt, wo sie BI-Tools und Geschäftsanwendern zur Verfügung gestellt werden.
Oft ist ein Mart-Modell eine SQL-Abfrage, die eine Reihe von Spalten aus einem Zwischenmodell auswählt. In unserem Beispiel für ein Beratungsunternehmen könnte die Tabelle dim_clients in dbt wie folgt definiert werden:
{{
config(materialized = "table")
}}
SELECT
client_id,
name,
industry,
country
from {{ref('int_clients_joined_addresses')}}
Dabei wäre int_joined_clients_addresses ein Zwischenmodell, das verschiedene Staging-Tabellen verbindet, um die notwendigen Informationen für unsere Dimensionstabelle zu extrahieren.
In der yaml-Datei des Modells können Datentypen und Tests konfiguriert werden. Unten sehen Sie ein Beispiel dafür, wie die yaml-Datei der Tabelle dim_clients eingerichtet werden könnte:
version: 2
models:
- name: dim_clients
description: This table contains all Xebia Data's clients.
columns:
- name: client_id
data_type: int
description: Primary key of this table.
tests:
- unique
- not_null
- name: name
data_type: string
description: The name of the client.
- name: industry
data_type: string
description: The industry of the client.
- name: country
data_type: string
description: The country of the client.Wobei client_id (PK) durch die generischen dbt-Tests auf Nullwerte und Eindeutigkeit getestet wird nicht_null und einzigartig .
Obwohl unser fiktives Xebia Star Schema-Modell recht einfach aussieht, gibt es in realen geschäftlichen Anwendungsfällen mehrere Arten von Fakten und Dimensionen. Fakten können zum Beispiel sein additiv, semi-additiv und nicht-additiv. Darüber hinaus gibt es sogar die Möglichkeit, eine faktenlose Faktentabellen! Sie können sich vorstellen, dass mit dem Wachstum eines Unternehmens auch dessen Prozesse und Komplexität zunehmen. Daher ist die Definition eines robusten Analyse-Workflows unerlässlich, um genaue und zuverlässige Erkenntnisse zu gewinnen.
Vor- und Nachteile der dimensionalen Modellierung
Wie bereits erwähnt, ist einer der Hauptvorteile der dimensionalen Modellierung ihre Einfachheit. Aufgrund ihrer Symmetrie und intuitiven Struktur ist sie eine Darstellung, die für verschiedene Arten von Beteiligten leicht verständlich ist. Darüber hinaus kann sie durch ihre Flexibilität und Erweiterbarkeit neue Geschäftsanforderungen erfüllen, wenn Unternehmen wachsen.
Auf der anderen Seite gibt es auch einige Nachteile. Mehrdeutigkeit kann bei der Identifizierung und Abbildung von Geschäftsprozessen eine Herausforderung darstellen, insbesondere wenn es keinen eindeutigen Dateneigentümer gibt. Da der Ansatz von Kimball auf kritischen Geschäftsanforderungen basiert, bietet er außerdem nicht von Anfang an einen vollständigen Überblick über die gesamten Unternehmensdaten.
Diese lassen sich wie folgt zusammenfassen:
Vorteile
- Einfachheit, leicht zu verstehen für das Unternehmen
- Inkrementeller Ansatz bedeutet geringere Vorlaufkosten
- Erweiterbar, Fokus auf die Datenbedürfnisse der Abteilung möglich
Benachteiligungen
- Ambiguität kann eine Herausforderung sein
- Datenredundanz
- Unvollständig aufgrund des geschäftskritischen Ansatzes
Dennoch bleibt es ein leistungsfähiges Framework, das für eine Vielzahl von Anwendungen - Einzelhandel, E-Commerce, Bankwesen, Inventarisierung u.a. - eingesetzt werden kann. Datenteams und Unternehmen können es an ihre eigenen Bedürfnisse anpassen, indem sie bei Bedarf Zugeständnisse machen und diese Nachteile abmildern.
Fazit
In diesem Blog haben wir gelernt, dass es die dimensionale Modellierung von Kimball schon seit vielen Jahrzehnten gibt. Dennoch ist sie für die heutigen Datenherausforderungen nach wie vor relevant. Aufgrund seiner Einfachheit und Symmetrie mit Dimensionen, Fakten und Star Schema kann es von geschäftlichen und technischen Benutzern leicht übernommen und verstanden werden.
Wir haben auch gesehen, dass Transformations-Workflows in Verbindung mit dbt leicht nachverfolgt und getestet werden können, was die Validierung und Wartung erleichtert. Mit dbt wird die Einfachheit der dimensionalen Datenmodellierung in großem Maßstab ermöglicht.
Gehören Sie zu einem Unternehmen, das sich mit der Implementierung von Best Practices für die Datenmodellierung und -transformation befasst? Unsere Analytik-Ingenieur-Berater helfen Ihnen gerne - einfach contact und wir werden uns bald bei Ihnen melden. Oder sind Sie ein Analyst, Analytiker oder Dateningenieur und möchten mehr über Kimball und dbt erfahren? Sehen Sie sich unser Data Warehousing und Datenmodellierung Kurs bei der Xebia Academy.
Wir wünschen Ihnen viel Erfolg bei der Datenmodellierung!
Verfasst von
Taís Laurindo Pereira
Taís is one of the co-authors of Fundamentals of Analytics Engineering. She has worked with analytics & data science since 2018 for a diverse range of companies - from big corporations to scale-ups. Since 2023, she has been working as a consultant at Xebia, implementing analytics engineering solutions at different clients. Besides working as a consultant, she also gives trainings about various data analytics tools and topics. With a mixed academic background in engineering and business, her mission is to contribute to data democratization in organizations through analytics engineering best practices.
Contact