Blog
Kedro: der ultimative Wingman für Ihre Datenpipeline über jede Cloud-Plattform

TL;DR: Kedro ist ein Open-Source-Datenpipeline-Framework, das das Schreiben von Code vereinfacht, der auf mehreren Cloud-Plattformen funktioniert. Sein modulares Design zentralisiert Konfigurationen, macht den Code weniger fehleranfällig und ermöglicht es, ihn lokal und in der Cloud auszuführen. Kedro generiert einfacheren
Intro
Wir alle wissen, wie schwierig es ist, unsere Pipelines nahtlos über mehrere Cloud-Plattformen hinweg funktionieren zu lassen, und wie zeitaufwändig es sein kann, den spezifischen Code für jeden Cloud-Stack zu lernen. Genau hier setzt Kedro an.
Bei Null anzufangen oder sich an eine andere Plattform anzupassen, kann sehr mühsam sein, ebenso wie herauszufinden, wie man Code für ein neues Projekt wiederverwenden kann. Und lassen Sie uns gar nicht erst mit der schlechten Dokumentation oder den Tutorials anfangen - oder dem Fehlen solcher -, die ziemlich entmutigend sein können. Und da Cloud-Infrastrukturen (fast) nichts mit der lokalen Ausführung von Code zu tun haben, wird das Testen zu einer echten Herausforderung. In diesem Blog gehen wir der Frage nach, wie Sie die Probleme beim Umgang mit verschiedenen Cloud-Stacks in den Griff bekommen. Verabschieden Sie sich also von der repetitiven und mühsamen Cloud-spezifischen Codierung und begrüßen Sie einen schlankeren und effizienteren Arbeitsablauf!
Die ungerechtfertigten Engpässe
Abgesehen von der steilen Lernkurve bei der Beherrschung der Feinheiten der einzelnen Cloud-Stacks ist die Flexibilität natürlich begrenzt, vor allem wegen der unterschiedlichen proprietären Tools und Workflow-Einschränkungen. Das zwingt Cloud-Nutzer zu zeitaufwändigen Anpassungen, die sich frustrierend anfühlen können.
Eines der großartigen Dinge an Kedro ist, dass es dank der zunehmenden Beteiligung und Beiträge der Community in der Praxis Cloud-agnostisch geworden ist. Unsere Kollegen von GetInData haben sich um alle Schnittstellen zu Plattformen für maschinelles Lernen in der Cloud wie Azure ML, Vertex AI und Sagemaker gekümmert. Das bedeutet, dass Ihr Code einmal geschrieben werden kann - natürlich in Python - und auf praktisch jeder Cloud-Plattform ausgeführt werden kann, was Ihre Pipeline portabler und flexibler macht.
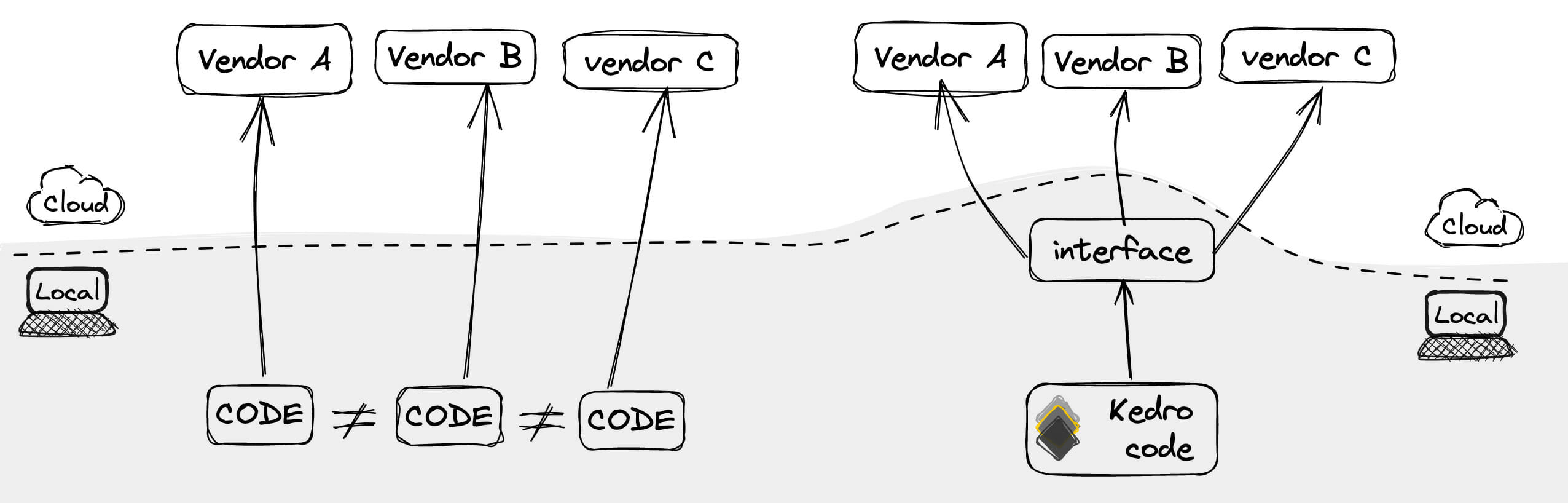
Ob es sich um einen strategischen Schachzug handelt oder einfach nur um eine andere Perspektive, Cloud-Anbieter organisieren ihre Infrastrukturen und Dienste auf ihre eigene Weise. Abgesehen davon sind ähnliche Ressourcen manchmal nicht ganz vergleichbar, weil sie zusätzliche oder fehlende Funktionen haben, was das Design beeinflussen (um nicht zu sagen beeinträchtigen) und zu einer Bindung an den Anbieter führen kann. Ein weiteres Problem besteht darin, dass die Pipeline-Knoten nicht lokal ausgeführt werden können - Debugging und Tests sind beim Programmieren von größter Bedeutung, warum also nicht? Folglich müssen wir diese Einschränkungen im Code umgehen und Cloud-Ressourcen nur bis zu einem gewissen Grad nutzen. So können wir beispielsweise große Datenmengen aus einem Data Lake in den Speicher laden und die restlichen Aufgaben lokal erledigen oder bestimmte Aufträge an die Cloud übermitteln und geduldig auf Verzögerungen bei der Planung warten, während wir an mehreren Tassen Kaffee nippen. Mit anderen Worten: ein respektabler, aber unnötiger Aufwand.
Warum Kedro?
Kedro ist ein Open-Source-Framework für Datenpipelines, das die besten Praktiken der Softwareentwicklung in einen saubereren und konsistenteren Code einbringt. Wie ich bereits erwähnt habe, ist die Community aktiv und die Dokumentation ist sehr gründlich, so dass wir ab und zu neue "Must-Have"-Funktionen sehen werden, die das Framework noch besser machen.
Ich weiß, dass nicht alles Einhörner und Regenbögen sind. Auch Kedro hat eine steile Lernkurve, aber das Gute daran ist, wie gesagt, die Community. Die einfache und ausführliche Dokumentation macht es neuen Benutzern sehr leicht, sich zurechtzufinden und in Zukunft sogar einen Beitrag zu leisten. Apropos Bequemlichkeit: Es könnte klug sein, etwas Zeit in das Erlernen eines einzigen Frameworks zu investieren, das nahtlos auf allen Cloud-Plattformen eingesetzt werden kann, anstatt jedes Mal, wenn sich eine neue Plattform in den Weg stellt, die gleichen Schmerzen zu haben.
Konsistenz und Übertragbarkeit
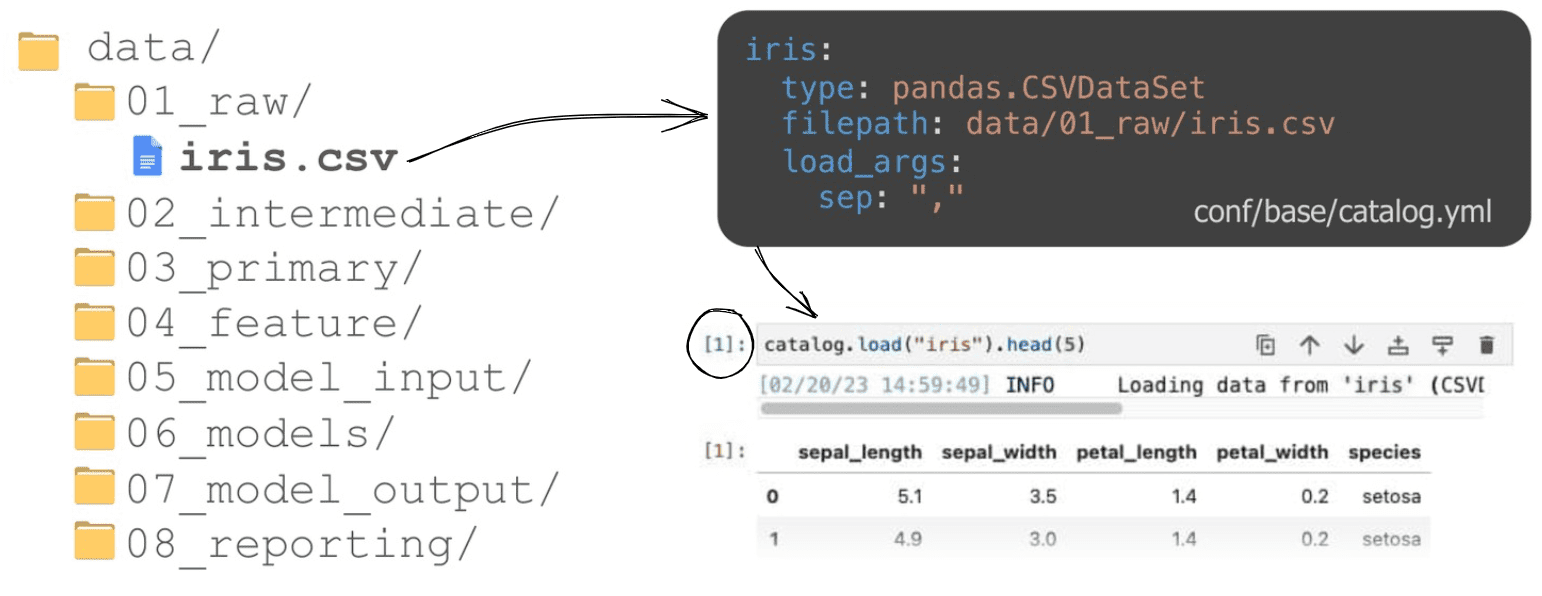
Eine der Funktionen, die jeden Anfänger verblüfft, ist die Art und Weise, wie Artefakte aus einer übergeordneten Perspektive verwendet werden. Mit anderen Worten: Auf jeden Datensatz, jedes trainierte Modell oder jedes andere Artefakt, das entlang der Pipeline erzeugt wird, kann nahtlos zugegriffen werden (oder es kann erstellt werden), indem einfach auf seinen Namen verwiesen wird. Dies sorgt für mehr Konsistenz im Code, da Pfade, Datentypen und bestimmte Konfigurationen in einem Datenkatalog zentralisiert sind. Dadurch wird der Code weniger fehleranfällig. Vorbei sind die Zeiten, in denen wir den Klassiker "it runs on my machine" aufgrund von hart kodierten Dingen verworfen haben.
Dies ist eine gute Nachricht für Fans von Jupyter-Notebooks. Kedro erstellt einen bestimmten Kernel, so dass der Datenkatalog bereits verfügbar ist, ohne dass Sie eine einzige Zeile Code importieren oder ausführen müssen. catalog ist also bereit, ein Artefakt zu laden, die verfügbaren Artefakte aufzulisten, und so weiter. Übrigens, ich höre hier auf. Der Datenkatalog selbst ist bereits ein Thema für eine gesonderte Diskussion, auf die es sich lohnt, besonders aufmerksam zu sein.
Aber das ist noch nicht alles - Kedro rationalisiert auch Ihren Pipeline-Entwicklungszyklus, da derselbe Code sowohl lokal als auch in der Cloud ausgeführt werden kann. Das macht das Debuggen, Testen und die IO-Inspektion für bestimmte Pipeline-Knoten viel einfacher, und Sie können sogar den Pipeline-Fluss und den Code jedes Knotens nebeneinander visualisieren. Und wenn Sie bestimmte Knoten lokal ausführen möchten, ist auch das möglich. Sie müssen nur bei Bedarf in die Cloud wechseln, was Ihnen Zeit und Geld spart.
Textbaustein-Code
Die Verwendung des SDK von der Cloud-Plattform selbst - sagen wir Azure ML, Sagemaker oder Vertex AI - bringt einige Komplexitäten mit sich. Azure ML erfordert die Ausführung von Python-Dateien und die Übergabe von Argumenten über Code, was sich wie ein angepasster CLI-Befehl in Python anfühlen kann. Sagemaker ist weniger technisch, aber die Konfiguration ist immer noch in den Code eingebettet. Auf den ersten Blick mag es verwirrend erscheinen, wie man Konfigurationen und IO mit bestimmten Knoten verknüpft. Vertex AI verfolgt einen anderen Ansatz, indem es die gesamte Pipeline als Funktion behandelt und es dem Codefluss überlässt, die Reihenfolge der Knotenausführungen zu bestimmen, erfordert aber dennoch eine explizite Konfiguration im Code.
Da Konfigurationen und Artefaktdefinitionen entkoppelt und in speziellen Dateien organisiert sind, ist der übrige Kedro-Code sauber und minimal. Was übrig bleibt, ist im Wesentlichen das, was getan werden muss: Definieren Sie Knoten und ihren jeweiligen Code, die IO und die Verbindung zwischen ihnen. Dann muss nur noch ein einfacher CLI-Befehl ausgeführt werden, der angibt, welche Pipeline ausgeführt werden soll. Theoretisch kann es nicht prägnanter sein als das. Das hört sich fast wie Magie an, was ein wenig ärgerlich sein kann, aber wenn Sie sich daran gewöhnt haben, wo alle Informationen sind, ist es vernünftig, ein Framework zu haben, das die technischen Details auf der unteren Ebene handhabt.
Modularer Aufbau
Und nicht zuletzt: Modularität. Dies ist eine weitere nette Funktion, die sich auf den Datenkatalog auswirkt, da der aktuelle Zustand eines Pipeline-Knotens durch sein IO genau abgerufen werden kann. Indem Sie Kernstücke des Codes unabhängig machen, können Sie - mit echten oder sogar Scheindaten - leicht einen bestimmten Knoten testen, wiederverwenden und insgesamt für saubereren Code sorgen.
Das modulare Design von Kedro hört jedoch nicht hier auf. Wenn Sie bei der Verwendung von Kedro auf Engpässe stoßen, sind diese wahrscheinlich auf etwas zurückzuführen, das noch nicht implementiert ist und das als zusätzlicher Beitrag gelöst werden kann, anstatt das zu warten, was bereits vorhanden ist. Nehmen wir an, Sie müssen einen Datensatz laden, aber sein ungewöhnliches Format ist nicht in der
Hallo Welt Kedro
Nachdem Sie bis hierher gelesen haben, können Sie es kaum erwarten, in die Praxis einzutauchen, nicht wahr? Zum Glück haben wir dieses Tutorial für Sie vorbereitet: `
/Kedro-Azureml-Starter/blob/main/tutorial.md). The goal is to refactor a simple train.py` mit dem Iris-Datensatz in die Kedro-Pipelines ein und lassen Sie sie auf Azure laufen.
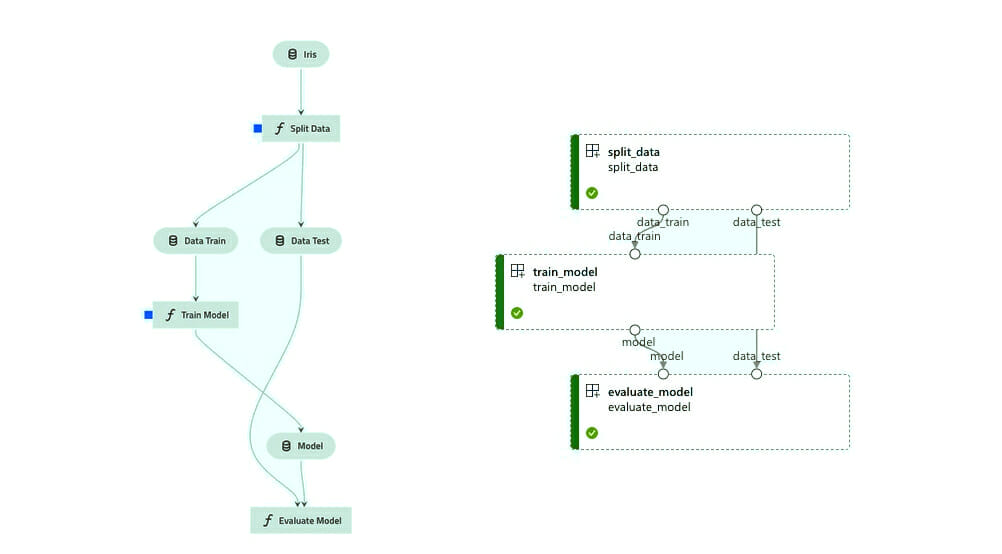
Auch wenn es bei diesem Spielzeugbeispiel ein wenig nach Over-Engineering aussieht, ist es ein guter Ansatz, sich mehr auf die Infrastruktur und die Feinheiten von Kedro und der Cloud zu konzentrieren als auf die Komplexität des Projekts selbst.
Zusammenfassend lässt sich sagen, dass Kedro eine leistungsstarke Lösung für Entwickler ist, die ihre Arbeitsabläufe rationalisieren und die Belastung durch das Schreiben von Cloud-spezifischem Code verringern möchten. Mit seinen Cloud-unabhängigen Funktionen, dem Datenkatalog, der Modularität, der Dokumentation und dem soliden Community-Support vereinfacht Kedro die Entwicklung von Datenpipelines und macht den Code über verschiedene Cloud-Plattformen hinweg portabel und flexibel. Das Design von Kedro sorgt für einen saubereren, konsistenteren und weniger fehleranfälligen Code und ermöglicht es den Benutzern, bestimmte Teile des Codes je nach Bedarf lokal, in der Cloud oder in beiden auszuführen. Wenn Sie Ihre Fähigkeiten bei der Entwicklung von Datenpipelines verbessern und den Prozess der Anpassung von Code an verschiedene Cloud-Plattformen vereinfachen möchten, ist Kedro definitiv eine gute Wahl.
Sind Sie aufgeregt? Verpassen Sie nicht Ihre Chance, bei unserem spannenden Kedro Code Breakfast am 23. Mai in Amsterdam zu lernen, wie man Datenpipelines mit Kedro betreibt. [Registrieren Sie sich jetzt für diese kostenlose Veranstaltung, bevor die Plätze ausgehen!
Verfasst von
Caio Benatti Moretti




Contact