Blog
Die überraschende Wirkung des Datenkatalogs von Kedro

Vor kurzem habe ich Kedro entdeckt, ein Python-Framework für Data Engineering und Wissenschaft. Als ich damit spielte, stellte ich fest, dass es auf einigen interessanten Designentscheidungen beruht. Die Designentscheidung, die mir am meisten auffiel, ist die Entkopplung zwischen Daten und Pipeline-Logik. Diese Entscheidung klingt vielleicht nicht nach einer großen Sache, aber sie bringt einige unerwartete Vorteile mit sich, die ich nicht erwartet hatte. In diesem Blogbeitrag werde ich erörtern, wie Kedro diese Entkopplung erreicht und welche Vorteile dies für Ihren Data Science-Workflow haben kann.
Das Problem der verstreuten IO-Logik
In einem typischen Data Science-Projekt werden Sie viel Zeit mit dem Schreiben von IO-Code verbringen. Zum Beispiel den Code zum Herunterladen und Parsen von Datensätzen oder den Code, der die Ein- und Ausgabe Ihrer Pipelineschritte verarbeitet. Wenn Sie dabei nicht sehr rigoros vorgehen, wird Ihr IO-Code wild und verstreut über Ihr Projekt. All dieser verstreute IO-Code macht es schwer, den Überblick über alle Daten zu behalten, die durch Ihr Projekt fließen, und er erschwert die Wiederverwendung dieses Codes. Anfangs denken Sie vielleicht, dass dies keine große Sache ist, aber es kann zu einem erheblichen Wartungsproblem werden, wenn Ihr Projekt wächst.
Wie geht Kedro mit dem Problem der verstreuten IO-Logik um?
Kedro vermeidet das Problem der verstreuten IO-Logik, indem es die gesamte IO- und datenbezogene Logik an einem einzigen Ort sammelt, den es Datenkatalog nennt. Dadurch müssen Sie die IO-Logik nur einmal schreiben und können sie in Ihrem gesamten Projekt wiederverwenden. In den meisten Fällen müssen Sie diese IO-Logik nicht selbst schreiben, da Kedro über Implementierungen für die meisten gängigen Datentypen und Speichersysteme verfügt. Das macht den Einstieg in den Datenkatalog sehr einfach. Ein weiterer Vorteil dieser IO-Logik an einem Ort ist, dass es sehr einfach ist, alle in Ihrem Projekt verwendeten Daten und Artefakte zu registrieren und zu verfolgen. Alles, was Sie tun müssen, ist, Kedro die folgenden Informationen zur Verfügung zu stellen, und Kedro weiß, wie diese Daten geladen oder geschrieben werden können:
- Der Name der Daten oder des Artefakts.
- Wo wird der Datensatz gespeichert. Ist er lokal, in einer Datenbank, in einem Blob-Speicher usw. gespeichert?
- Der Typ des Datensatzes. Damit wird Kedro mitgeteilt, welche IO-Logik verwendet werden soll.
- Optional zusätzliche Informationen, die die IO-Logik benötigen könnte, wie z.B. Anmeldeinformationen, welcher Separator verwendet werden soll, usw.
In einem Kedro-Projekt stellen Sie all diese Informationen normalerweise in einer YAML-Konfiguration bereit. Sie können zum Beispiel einen CSV-Datensatz und ein Pickle-Modell-Artefakt registrieren, indem Sie der Datei conf/base/catalog.yml Folgendes hinzufügen:
# A CSV file stored locally
iris:
type: pandas.CSVDataSet
filepath: data/01_raw/iris.csv
# A pickle sklearn model stored in Azure blob storage
model:
type: pickle.PickleDataSet
filepath: abfs://data/06_models/model.pkl
credentials: azure_storageVorteile der Entkopplung von Daten und Pipeline-Logik
Diese ganze Konfiguration, um Daten lesen und schreiben zu können, hört sich nach viel Arbeit an, aber sie ist sehr mächtig. Dank des Datenkatalogs können wir unsere Daten mit deklarativem und nicht mit imperativem Code laden oder speichern. Bei deklarativem Code sagen Sie dem Computer nur, was er tun soll, und nicht, wie er es tun soll. Diese Änderung vereinfacht den Code, den Sie schreiben müssen, erheblich. Das Laden und Speichern eines Datensatzes zum Beispiel wird so einfach wie:
your_dataset = catalog.load("<dataset_name>")
... # Do something fancy using your data
catalog.save(your_updated_dataset, "<dataset_name>")Diese Änderung mag trivial klingen, aber sie hat einige interessante und unerwartete Vorteile für Ihren Data Science Workflow.
Konsistenter Datenaustausch
In einem Kedro-Projekt ist "Das funktioniert auf meinem Rechner" kein Thema mehr. Mit einem gemeinsamen Datenkatalog greift jeder auf die gleiche Weise auf die Daten zu, indem er einfach den Namen des Datensatzes kennt. Der große Vorteil dabei ist, dass die manuelle Freigabe von Daten entfällt und die Konsistenz im gesamten Team gewährleistet ist. Um zum Beispiel auf die vorverarbeiteten Daten eines Kollegen zuzugreifen, müssen Sie nur den Namen des Datensatzes kennen. Das Gleiche gilt für Artefakte, wie z.B. trainierte Modelle. Der Datenkatalog nimmt Ihnen die Mühe der gemeinsamen Nutzung von Daten ab und sorgt dafür, dass jeder auf die Daten auf die gleiche Weise zugreift. Dies ist vor allem ein großer Vorteil für Teammitglieder, die mit cloudbasierten Arbeitsabläufen weniger vertraut sind. Sie müssen sich nicht mit allen Ins und Outs Ihres Cloud-Speichers vertraut machen, sondern nur den Namen des Datensatzes kennen.
Schnelle und einfache Erkundung mit dem Notizbuch
Bei einem produktionsreifen Data-Science-Projekt ist die Reproduzierbarkeit ein wichtiger Aspekt. Um dies zu erreichen, werden Pipelines oft auf Cloud-Computing-Plattformen wie AzureML oder SageMaker ausgeführt. Während dies für die Gewährleistung der Reproduzierbarkeit großartig ist, kann es eine Herausforderung sein, eine schnelle, einmalige Analyse in einem Notebook durchzuführen. Der Zugriff auf vorverarbeitete Daten und trainierte Modelle ist zum Beispiel nicht immer einfach. Mit einem gemeinsamen Datenkatalog wird dies jedoch viel einfacher. Die Zwischendaten und Artefakte werden im Datenkatalog registriert, so dass sie leicht zugänglich sind. Wenn Sie einen Notebook-Server mit
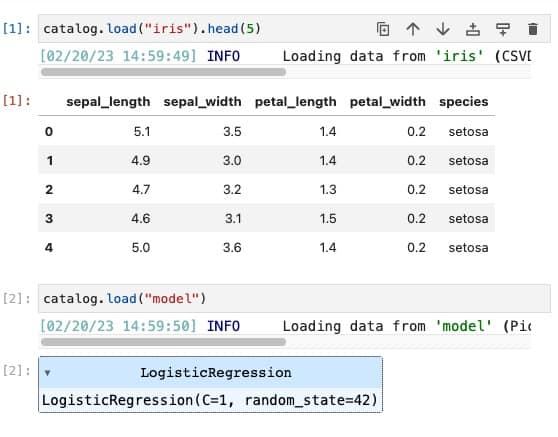
Der große Vorteil dabei ist, dass Sie schnell eine einmalige Analyse durchführen können, was Ihre Debugging- und Analysegeschwindigkeit erheblich steigern kann.
Pipeline wird einfacher zu testen und zu pflegen
Die meisten Pipelineschritte sind in der Regel mit allen möglichen Arten von IO-Code gefüllt. Bei Kedro-Pipelineschritten ist dies nicht der Fall, da der Datenkatalog die gesamte IO-Logik übernimmt. Der große Vorteil dabei ist, dass Sie sich auf das Schreiben einer normalen Python-Funktion konzentrieren können, die eine Eingabe entgegennimmt und eine Ausgabe zurückgibt. Der Datenkatalog kann dann dafür sorgen, dass die Eingaben bereitgestellt und die Ausgaben gespeichert werden. Dieser Ansatz ermöglicht es Ihnen, reine Funktionen zu erstellen, die einfacher zu testen und zu pflegen sind. Wenn Ihre Funktion beispielsweise einen Pandas DataFrame als Eingabe erhält, können Sie sie schnell einem Unit-Test unterziehen, indem Sie einen Dummy-DataFrame bereitstellen. Sie müssen sich nicht mehr um die Abstraktion oder das Mocking Ihres IO-Codes kümmern, was den Testprozess vereinfacht. Dies verbessert nicht nur die Wartbarkeit Ihrer Pipelineschritte, sondern erleichtert auch den Einstieg in das Testen. So können Sie sicherstellen, dass Ihre Pipelineschritte wie erwartet funktionieren und im Laufe der Zeit wartbar bleiben.
Fazit
Bis jetzt hat mich der Datenkatalog von Kedro sehr beeindruckt. Er ist ein leistungsstarkes Tool, das Ihren Data-Science-Workflow erheblich verbessern kann. Es ist wichtig zu wissen, dass der Datenkatalog aufgrund seiner speziellen Repository-Einrichtung nur innerhalb eines Kedro-Projekts verwendet werden kann. Leider ist Kedro ein wenig gewöhnungsbedürftig. Die Vorteile der Verwendung von Kedro sind es jedoch wert, dass Sie es für Ihr Projekt in Betracht ziehen. Wenn Sie die Verwendung von Kedro erlernen möchten, finden Sie bei uns einige Projektvorlagen und Tutorials, die Ihnen den Einstieg erleichtern.
Verfasst von
Jordi Smit




Contact